link之家
链接快照平台
- 输入网页链接,自动生成快照
- 标签化管理网页链接
相关文章推荐

|
怕考试的木耳 · 软件分享库合集链接汇总推荐_蓝奏云软件分享链 ...· 1 年前 · |
|
|
精明的日记本 · 江西省发布第三批非法集资严重失信人名单 ...· 1 年前 · |
|
|
奔放的梨子 · Creating Word ...· 2 年前 · |
|
|
奔跑的苦咖啡 · 地藏菩萨本愿经讲记(第十三卷)· 2 年前 · |
|
|
愤怒的菠萝 · 异兽魔都(林田球创作的系列漫画)_搜狗百科· 2 年前 · |

Deepfashion2数据
数据集介绍: https://github.com/switchablenorms/DeepFashion2
链接:https://pan.baidu.com/s/1f9oIMEmWc3XtTn8LJViw7A?pwd=pnex
提取码:pnex
解压密码2019Deepfashion2**
格式转到COCO (废弃章节)
废弃理由:转COCO出一个很大的json并非我目的,直接下个章节。
参考:https://github.com/Manishsinghrajput98/deepfashion2coco_to_yolo_/tree/master/deepfashion2coco_to_yolo_
下面代码有所改动,使用需要改写annos_path路径和image_path路径即可。
# -*- coding: utf-8 -*-
Created on Sun Jul 21 21:15:50 2019
@author: loktarxiao
import json
import os
import numpy as np
from PIL import Image
from tqdm import tqdm
dataset = {
"info": {},
"licenses": [],
"images": [],
"annotations": [],
"categories": []
dataset['categories'].append({
'id': 1,
'name': "short_sleeved_shirt",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184',
'185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 2,
'name': "long_sleeved_shirt",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110',
'111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 3,
'name': "short_sleeved_outwear",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36'
, '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269',
'270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 4,
'name': "long_sleeved_outwear",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195',
'196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 5,
'name': "vest",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122'
, '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 6,
'name': "sling",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47',
'48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281'
, '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 7,
'name': "shorts",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207'
, '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 8,
'name': "trousers",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133',
'134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 9,
'name': "skirt",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59',
'60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292',
'293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 10,
'name': "short_sleeved_dress",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218',
'219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 11,
'name': "long_sleeved_dress",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145'
, '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 12,
'name': "vest_dress",
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71'
, '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230', '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
dataset['categories'].append({
'id': 13,
'name': "sling_dress"
,
'supercategory': "clothes",
'keypoints': ['1', '2', '3', '4', '5', '6', '7', '8', '9', '10', '11', '12', '13', '14', '15', '16', '17', '18',
'19', '20', '21', '22', '23', '24', '25', '26', '27', '28', '29', '30', '31', '32', '33', '34', '35',
'36', '37', '38', '39', '40', '41', '42', '43', '44', '45', '46', '47', '48', '49', '50', '51', '52',
'53', '54', '55', '56', '57', '58', '59', '60', '61', '62', '63', '64', '65', '66', '67', '68', '69',
'70', '71', '72', '73', '74', '75', '76', '77', '78', '79', '80', '81', '82', '83', '84', '85', '86',
'87', '88', '89', '90', '91', '92', '93', '94', '95', '96', '97', '98', '99', '100', '101', '102',
'103', '104', '105', '106', '107', '108', '109', '110', '111', '112', '113', '114', '115', '116',
'117', '118', '119', '120', '121', '122', '123', '124', '125', '126', '127', '128', '129', '130',
'131', '132', '133', '134', '135', '136', '137', '138', '139', '140', '141', '142', '143', '144',
'145', '146', '147', '148', '149', '150', '151', '152', '153', '154', '155', '156', '157', '158',
'159', '160', '161', '162', '163', '164', '165', '166', '167', '168', '169', '170', '171', '172',
'173', '174', '175', '176', '177', '178', '179', '180', '181', '182', '183', '184', '185', '186',
'187', '188', '189', '190', '191', '192', '193', '194', '195', '196', '197', '198', '199', '200',
'201', '202', '203', '204', '205', '206', '207', '208', '209', '210', '211', '212', '213', '214',
'215', '216', '217', '218', '219', '220', '221', '222', '223', '224', '225', '226', '227', '228',
'229', '230'
, '231', '232', '233', '234', '235', '236', '237', '238', '239', '240', '241', '242',
'243', '244', '245', '246', '247', '248', '249', '250', '251', '252', '253', '254', '255', '256',
'257', '258', '259', '260', '261', '262', '263', '264', '265', '266', '267', '268', '269', '270',
'271', '272', '273', '274', '275', '276', '277', '278', '279', '280', '281', '282', '283', '284',
'285', '286', '287', '288', '289', '290', '291', '292', '293', '294'],
'skeleton': []
annos_path = r"E:\06服饰\Deepfashion2\train\train\annos"
image_path = r"E:\06服饰\Deepfashion2\train\train\image"
num_images = len(os.listdir(annos_path))
sub_index = 0 # the index of ground truth instance
for num in tqdm(range(1, num_images + 1)):
json_name = os.path.join(annos_path, str(num).zfill(6) + '.json')
image_name = os.path.join(image_path, str(num).zfill(6) + '.jpg')
if (num >= 0):
imag = Image.open(image_name)
width, height = imag.size
with open(json_name, 'r') as f:
temp = json.loads(f.read())
pair_id = temp['pair_id']
dataset['images'].append({
'coco_url': '',
'date_captured': '',
'file_name': str(num).zfill(6) + '.jpg',
'flickr_url': '',
'id': num,
'license': 0,
'width': width,
'height': height
for i in temp:
if i == 'source' or i == 'pair_id':
continue
else:
points = np.zeros(294 * 3)
sub_index = sub_index + 1
box = temp[i]['bounding_box']
w = box[2] - box[0]
h = box[3] - box[1]
x_1 = box[0]
y_1 = box[1]
bbox = [x_1, y_1, w, h]
cat = temp[i]['category_id']
style = temp[i]['style']
seg = temp[i]['segmentation']
landmarks = temp[i]['landmarks']
points_x = landmarks[0::3]
points_y = landmarks[1::3]
points_v = landmarks[2::3]
points_x = np.array(points_x)
points_y = np.array(points_y)
points_v = np.array(points_v)
if cat == 1:
for n in range(0, 25):
points[3 * n] = points_x[n]
points[3 * n + 1] = points_y[n]
points[3 * n + 2] = points_v[n]
elif cat == 2:
for n in range(25, 58):
points[3 *
n] = points_x[n - 25]
points[3 * n + 1] = points_y[n - 25]
points[3 * n + 2] = points_v[n - 25]
elif cat == 3:
for n in range(58, 89):
points[3 * n] = points_x[n - 58]
points[3 * n + 1] = points_y[n - 58]
points[3 * n + 2] = points_v[n - 58]
elif cat == 4:
for n in range(89, 128):
points[3 * n] = points_x[n - 89]
points[3 * n + 1] = points_y[n - 89]
points[3 * n + 2] = points_v[n - 89]
elif cat == 5:
for n in range(128, 143):
points[3 * n] = points_x[n - 128]
points[3 * n + 1] = points_y[n - 128]
points[3 * n + 2] = points_v[n - 128]
elif cat == 6:
for n in range(143, 158):
points[3 * n] = points_x[n - 143]
points[3 * n + 1] = points_y[n - 143]
points[3 * n + 2] = points_v[n - 143]
elif cat == 7:
for n in range(158, 168):
points[3 * n] = points_x[n - 158]
points[3 * n + 1] = points_y[n - 158]
points[3 * n + 2] = points_v[n - 158]
elif cat == 8:
for n in range(168, 182):
points[3 * n] = points_x[n - 168]
points[3 * n + 1] = points_y[n - 168]
points[3 * n + 2] = points_v[n - 168]
elif cat == 9:
for n in range(182, 190):
points[3 * n] = points_x[n - 182]
points[3 * n + 1] = points_y[n - 182]
points[3 * n + 2] = points_v[n - 182]
elif cat == 10:
for n in range(190, 219):
points[3 * n] = points_x[n - 190]
points[3 * n + 1] = points_y[n - 190]
points[3 * n + 2] = points_v[n - 190]
elif cat == 11:
for n in range(219, 256):
points[3 * n] = points_x[n - 219]
points[3 * n + 1] = points_y[n - 219]
points[3 * n + 2] = points_v[n - 219]
elif cat == 12:
for n in range(256, 275):
points[3 * n]
= points_x[n - 256]
points[3 * n + 1] = points_y[n - 256]
points[3 * n + 2] = points_v[n - 256]
elif cat == 13:
for n in range(275, 294):
points[3 * n] = points_x[n - 275]
points[3 * n + 1] = points_y[n - 275]
points[3 * n + 2] = points_v[n - 275]
num_points = len(np.where(points_v > 0)[0])
dataset['annotations'].append({
'area': w * h,
'bbox': bbox,
'category_id': cat,
'id': sub_index,
'pair_id': pair_id,
'image_id': num,
'iscrowd': 0,
'style': style,
'num_keypoints': num_points,
'keypoints': points.tolist(),
'segmentation': seg,
json_name = os.path.join(os.path.dirname(annos_path), 'result.json')
with open(json_name, 'w') as f:
json.dump(dataset, f)
把Deepfashion2的label直接转到YOLO格式
一个json里的内容,比如000001.json:
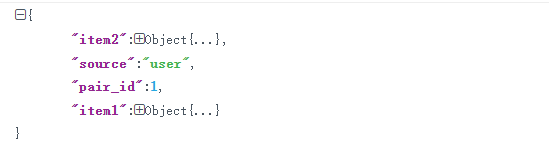
一个item是一个衣服对象。item里面就是一些标签信息:

官网解释:
source: a string, where 'shop' indicates that the image is from commercial store while 'user' indicates that the image is taken by users.
pair_id: a number. Images from the same shop and their corresponding consumer-taken images have the same pair id.
item 1
category_name: a string which indicates the category of the item.
category_id: a number which corresponds to the category name. In category_id, 1 represents short sleeve top, 2 represents long sleeve top, 3 represents short sleeve outwear, 4 represents long sleeve outwear, 5 represents vest, 6 represents sling, 7 represents shorts, 8 represents trousers, 9 represents skirt, 10 represents short sleeve dress, 11 represents long sleeve dress, 12 represents vest dress and 13 represents sling dress.
style: a number to distinguish between clothing items from images with the same pair id. Clothing items with different style numbers from images with the same pair id have different styles such as color, printing, and logo. In this way, a clothing item from shop images and a clothing item from user image are positive commercial-consumer pair if they have the same style number greater than 0 and they are from images with the same pair id.(If you are confused with style, please refer to issue#10.)
bounding_box: [x1,y1,x2,y2],where x1 and y_1 represent the upper left point coordinate of bounding box, x_2 and y_2 represent the lower right point coordinate of bounding box. (width=x2-x1;height=y2-y1)
landmarks: [x1,y1,v1,...,xn,yn,vn], where v represents the visibility: v=2 visible; v=1 occlusion; v=0 not labeled. We have different definitions of landmarks for different categories. The orders of landmark annotations are listed in figure 2.
segmentation: [[x1,y1,...xn,yn],[ ]], where [x1,y1,xn,yn] represents a polygon and a single clothing item may contain more than one polygon.
scale: a number, where 1 represents small scale, 2 represents modest scale and 3 represents large scale.
occlusion: a number, where 1 represents slight occlusion(including no occlusion), 2 represents medium occlusion and 3 represents heavy occlusion.
zoom_in: a number, where 1 represents no zoom-in, 2 represents medium zoom-in and 3 represents lagre zoom-in.
viewpoint: a number, where 1 represents no wear, 2 represents frontal viewpoint and 3 represents side or back viewpoint.
item 2
item n
翻译一下就是13个对象以category_id标识对象不同,bounding_box中存左上、右下两个点,并且category_id会有:
1 represents short sleeve top,
2 represents long sleeve top,
3 represents short sleeve outwear,
4 represents long sleeve outwear,
5 represents vest,
6 represents sling,
7 represents shorts,
8 represents trousers,
9 represents skirt,
10 represents short sleeve dress,
11 represents long sleeve dress,
12 represents vest dress,
13 represents sling dress
修改文件名和增加空文件
把image改为images名称,另外增加labels空文件。
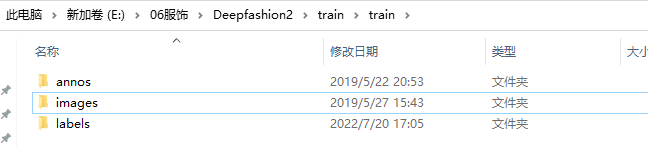
执行程序转换
下面是训练数据,val数据同样操作。有空就等,没空就把下面程序改成多进程。
# coding:utf-8
import json
import os
import os.path
from PIL import Image
from tqdm import tqdm
def listPathAllfiles(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
annos_path = r"E:\06服饰\Deepfashion2\train\train\annos" # 改成需要路径
image_path = r"E:\06服饰\Deepfashion2\train\train\images" # 改成需要路径
labels_path = r"E:\06服饰\Deepfashion2\train\train\labels" # 改成需要路径
num_images = len(os.listdir(annos_path))
for num in tqdm(range(1, num_images + 1)):
json_name = os.path.join(annos_path, str(num).zfill(6) + '.json')
image_name = os.path.join(image_path, str(num).zfill(6) + '.jpg')
txtfile = os.path.join(labels_path, str(num).zfill(6) + '.txt')
imag = Image.open(image_name)
width, height = imag.size
res = []
with open(json_name, 'r') as f:
temp = json.loads(f.read())
for i in temp:
if i == 'source' or i == 'pair_id':
continue
else:
box = temp[i]['bounding_box']
x_1 = round((box[0] + box[2]) / 2 / width, 6)
y_1 = round((box[1] + box[3]
) / 2 / height, 6)
w = round((box[2] - box[0]) / width, 6)
h = round((box[3] - box[1]) / height, 6)
category_id = int(temp[i]['category_id'] - 1)
res.append(" ".join([str(category_id), str(x_1), str(y_1), str(w), str(h)]))
open(txtfile, "w").write("\n".join(res))
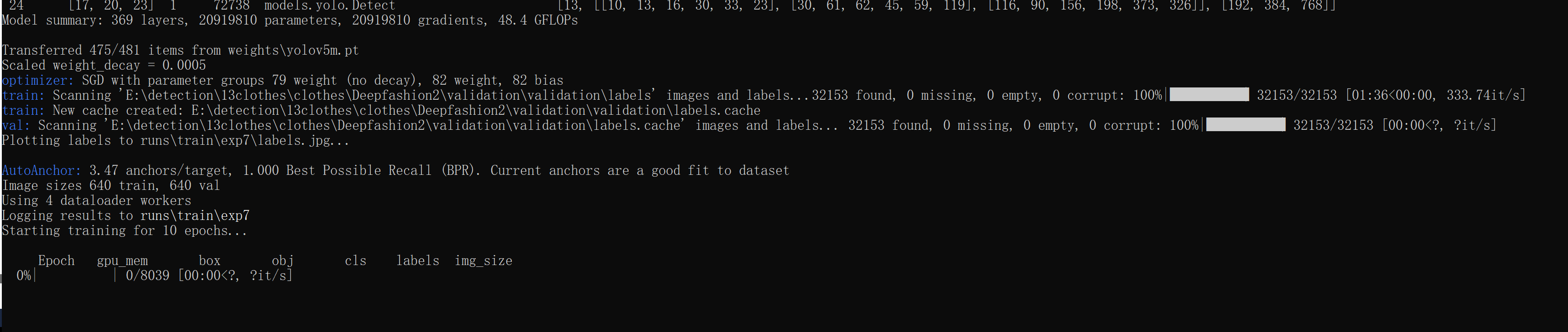
训练YOLOv5
写data yaml
换了个英文存储路径,此外注意是13个类别。
path: E:\detection\13clothes\clothes\Deepfashion2 # dataset root dir
train: validation\validation
val: validation\validation
# Classes
nc: 13 # number of classes
names: [ 'short sleeve top', 'long sleeve top','short sleeve outwear','long sleeve outwear',
'vest','sling','shorts','trousers','skirt','short sleeve dress','long sleeve dress',
'vest dress','sling dress' ] # class names
python train.py --batch-size 4 --data fashion2.yaml --img 640 --epochs 10 --weight weights/yolov5m.pt
动起来就行了:
检查yolo labels对不对
import os
import cv2
import matplotlib.pyplot as plt
import numpy as np
ASSETS_DIRECTORY = "assets"
plt.rcParams["savefig.bbox"] = "tight"
def listPathAllfiles(dirname):
result = []
for maindir, subdir, file_name_list in os.walk(dirname):
for filename in file_name_list:
apath = os.path.join(maindir, filename)
result.append(apath)
return result
if __name__ == '__main__':
labelspath = r'E:\WIIDERFACE\WIDER_VOC\train\labels'
imagespath = r'E:\WIIDERFACE\WIDER_VOC\train\images'
labelsFiles = listPathAllfiles(labelspath)
for lbf in labelsFiles:
labels = open(lbf, "r").readlines()
labels = list(map(lambda x: x.strip().split(" "), labels))
imgfileName = os.path.join(imagespath, os.path.basename(lbf)[:-4] + ".jpg")
img = cv2.imdecode(np.fromfile(imgfileName, dtype=np.uint8), 1) # img是矩阵
for lbs in labels:
lb = list(map(float, lbs))[1:]
x1 = int((lb[0] - lb[2] / 2) * img.shape[1])
y1 = int((lb[1] - lb[3] / 2) * img.shape[0])
x2 = int((lb[0] + lb[2] / 2) * img.shape[1])
y2 = int((lb[1] + lb[3] / 2) * img.shape[0])
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 0, 255), 5)
cv2.imshow("1", img)
cv2.waitKey()
cv2.destroyAllWindows()
数据集介绍:https://github.com/switchablenorms/DeepFashion2格式转到COCO (废弃章节)废弃理由:转COCO出一个很大的json并非我目的,直接下个章节。参考:https://github.com/Manishsinghrajput98/deepfashion2coco_to_yolo_/tree/master/deepfashion2coco_to_yolo_下面代码有所改动,使用需要改写路径和路径即可。把Deepfashion2的label直接转到
1、yolov5下俯视场景下车辆行人检测视觉检测,包含YOLOv5s和YOLOv5m两种训练好的visdrone数据集权重,以及PR曲线,loss曲线等等,有pyqt界面,目标类别为车辆行人等
2、pyqt界面可以检测图片、视频、调用摄像头
3、数据集和检测结果参考:https://blog.csdn.net/zhiqingAI/article/details/124230743
4、采用pytrch框架,python代码
论文标题:DeepFashion2: A Versatile Benchmark for Detection, Pose Estimation, Segmentation and Re-Identification of Clothing Images
数据集链接:https://github.com/switchablenorms/DeepFashion2
简单介绍:https://www.jiqizhixin.com/articles/2019-02-04-2
数据集下载解压
解压需要密码,不过
main idea
这篇文章提出了一个新的数据集,是在原有的数据集上进行扩充的,包含491k的images,每张图片都包含丰富的语义标注,包括 style,scale,occlusion,zooming,viewpoint,bounding box,dense landmarks and pose.pixel-level masks.pair of image.
这篇章提出了一个benchmark...
DeepFashion2数据集
DeepFashion2是一个全面的时装数据集。 它包含来自商业购物商店和消费者的13种流行服装的491K多种图像。 它总共有801K件服装,其中图像中的每一项都标有比例,遮挡,放大,视点,类别,样式,边框,密集的地标和每个像素的蒙版。还有873K商用服装。对。 数据集分为训练集(391K图像),验证集(34k图像)和测试集(67k图像)。 DeepFashion2的示例如图1所示。
图1:DeepFashion2的示例。
从(1)到(4),每一行代表具有不同变化的衣服图像。 在每一行中,我们将图像分为两组,左三列代表商业商店的衣服,而右三列代表顾客。在每组中,这三幅图像表示相对于相应变化的三个难度级别。此外,在每一行中,这两组图像中的商品均来自相同的服装标识,但来自两个不同的领域,即商业和客户,具有相同标识的商品可能具有不同的样式,例如颜色和印刷。该
数据集简介
【官方介绍】:http://mmlab.ie.cuhk.edu.hk/projects/DeepFashion.html
DeepFashion数据库,这是一个大型服装数据库,它有几个吸引人的特性:
首先,DeepFashion包含超过800,000种不同的时尚图像,从精美的商店图像到无约束的消费者照片。
其次,DeepFashion注释了丰富的服装商品信息。此数据集中的每个图像都标...
要使用YOLOv5-DeepSORT训练自己的数据集,首先需要准备好数据集。通常情况下,在准备数据集之前需要明确需要检测的物体类别和数量。然后,通过在图像中标注这些物体,并将标注结果保存在标注文件中,即可准备好数据集。
接下来,需要安装相关依赖和设置环境。YOLOv5-DeepSORT的训练需要使用PyTorch深度学习框架。此外,还需要安装相关的Python库,如numpy、pandas、opencv-python、scipy等。一些用户可能需要在自己的计算机上安装CUDA和cuDNN,以加速训练过程。
然后,需要下载YOLOv5代码并选择合适的模型进行训练。一般来说,可以选择已经在大型数据集上预训练好的模型进行微调,也可以自行训练调整模型。微调的效果往往更好,而自行训练会更加具有个性化。
接下来,需要进行数据增强,以增加数据集的大小和不同姿态的物体的训练范围。这可以通过旋转、平移、裁剪等操作来做到。
最后,需要运行训练代码,以开始训练模型。该过程通常需要数十小时或数天,具体取决于数据集大小、模型复杂度和所用硬件等多方面因素。
在训练完成后,可以对模型进行验证,以确保其性能。这可以通过跑测试集来做到,也可以在其他图像中手动测试。一旦模型达到预期的性能,就可以将其部署到实际应用程序中,并在监测和跟踪所需的场合中使用。
推荐文章
|
|
奔放的梨子 · Creating Word Application using Excel VBA: Run-time error '429': ActiveX component can't create obje 2 年前 |
|
|
奔跑的苦咖啡 · 地藏菩萨本愿经讲记(第十三卷) 2 年前 |
|
|
愤怒的菠萝 · 异兽魔都(林田球创作的系列漫画)_搜狗百科 2 年前 |