

如何用python 连接impala 并读数据库文件?

最近需要分析多张表特定事件发生次数的描述统计信息,一个一个写sql太麻烦,重复劳动也比较多。目前使用impala,所以尝试用python连接impala进行分析,直接调取describe方法。记录下自己整理的过程。
什么是impala以及和hive的区别参见:
https://www. zhihu.com/answer/109540 5497
1.导入impyla
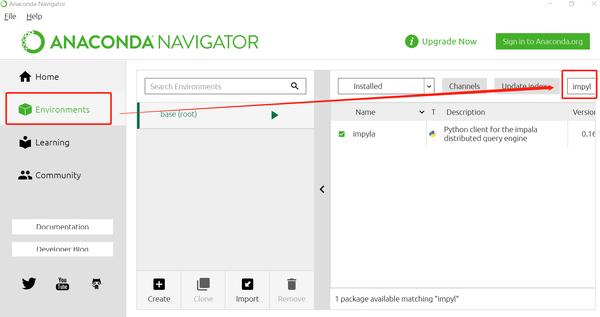

目前已经导入了,如果之前尚未导入,勾选前面的方框后,点击右下角的Apply 按钮即可。
如果导入比较慢可以换下面的方式
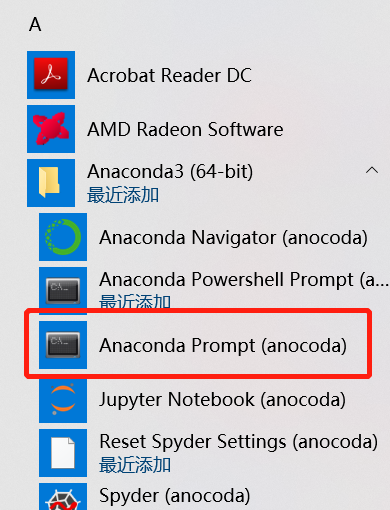
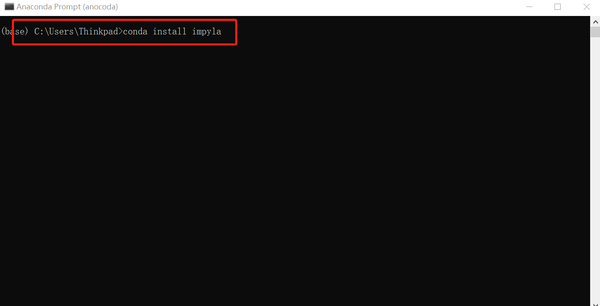
进入后输入命令 conda install impyla,注意这里impyla,不是impala。等执行结束就可以啦。
2.打开anoconda 建立连接
#导入包
from impala.dbapi import connect
#连接impala
conn=connect(host='XXX.XX.XX.XX',port=21050)
#定义一个执行者
cur=conn.cursor()
#执行语句并测试连接是否成功
cur.execute('SHOW DATABASES')
#将执行结果给fetchall并打印结果
print(cur.fetchall())
# 先关闭执行者
cur.close()
# 再关断开连接
conn.close()定义了一个函数可以完成读取并执行SQL,后期直接调用这个函数就可以完成数据读取并将sql查询结果返回。
#导入包
from impala.dbapi import connect
import pandas as pd
def sql_ext(sql):
conn=connect(XXX.XX.XX.XX',port=21050)
#定义一个执行者
cur=conn.cursor()
cur.execute(sql)
data_temp=cur.fetchall()
tempDf=pd.DataFrame(data_temp)