一维卷积常用在序列模型、
自然语言处理
领域;
-
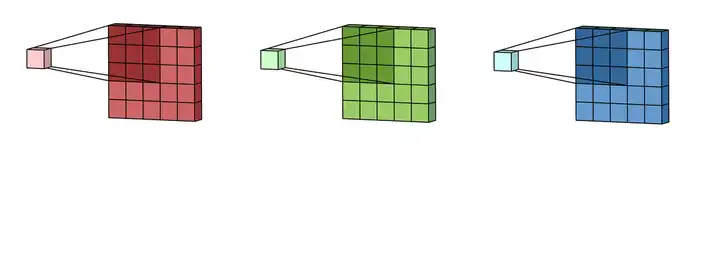
图中的输入的数据维度为8,过滤器的维度为5。与二维卷积类似,卷积后输出的数据维度为8−5+1=4。
-
如果过滤器数量仍为1,输入数据的channel数量变为16,即输入数据维度为8×16。这里channel的概念相当于自然语言处理中的embedding,而该输入数据代表8个单词,其中每个单词的词向量维度大小为16。在这种情况下,过滤器的维度由55变为5×16,最终输出的数据维度仍为4。
-
如果过滤器数量为n,那么输出的数据维度就变为4×n。
-
一维卷积常用于序列模型,自然语言处理领域。
2 二维卷积神经网络(2D-
CNN
)
二维卷积常用在
计算机视觉
、图像处理领域(在视频的处理中,是对每一帧图像分别利用CNN来进行识别,没有考虑时间维度的信息);
2.1 单通道
-
图中的输入的数据维度为14×14,过滤器大小为5×5,二者做卷积,输出的数据维度为10×10(14−5+1=10)。。
-
上述内容可以说channel的数量为1。如果将二维卷积中输入的channel的数量变为3,即输入的数据维度变为(14×14×3)。由于卷积操作中过滤器的channel数量必须与输入数据的channel数量
相同
,过滤器大小也变为5×5×3。在卷积的过程中,过滤器与数据在channel方向分别卷积,之后将卷积后的数值相加,即执行10×10次3个数值相加的操作,最终输出的数据维度为10×10。
-
以上都是在过滤器数量为1的情况下所进行的讨论。如果将过滤器的数量增加至16,即16个大小为10×10×3的过滤器,最终输出的数据维度就变为10×10×16。可以理解为分别执行每个过滤器的卷积操作,最后将每个卷积的输出在第三个维度(channel 维度)上进行拼接。
-
二维卷积常用于计算机视觉、图像处理领域。
2.2 多通道
多通道卷积。每个卷积核都应用于上一层的输入通道,以生成一个输出通道。 所有输出通道组合在一起组成输出层。如下图所示:
动图:
https://pica.zhimg.com/50/v2-9b822c07062fed010d0fecbac56c3763_720w.webp?source=1940ef5c
输入层为
 的矩阵(即为三通道)。滤波器为
的矩阵(即为三通道)。滤波器为
 的矩阵(即含有3个卷积核)。首先滤波器中的每个卷积核分别应用于输入层的三个通道。执行上次卷积计算,输出3个
的矩阵(即含有3个卷积核)。首先滤波器中的每个卷积核分别应用于输入层的三个通道。执行上次卷积计算,输出3个
 的通道。
的通道。
https://pica.zhimg.com/50/v2-fa76727d15dfaa1f81c4eab712b4e866_720w.jpg?source=1940ef5c
然后对这三通道相加即进行矩阵加法,得到一个
 的单通道。这个通道就是在输入层(
)应用单个滤波器(
)的结果。
的单通道。这个通道就是在输入层(
)应用单个滤波器(
)的结果。
同样地,以上过程可以更为统一地看成一个3D的滤波器对输入层进行处理。其中输入层和滤波器有着相同的深度,即
输入层的通道数量
与
滤波器中卷积核数量
相同。3D滤波器即只需要在输入层(如图像)的
2个维度高和宽
滑动(这也是为什么3D滤波器用于处理3D矩阵时,该运算过程称为2D卷积的原因)。在每个滑动位置,执行乘法和加法运算得到一个运算结果(单个数字)。在下面的例子中,滑动在
 的输入层(为任意值),最后得到的输出层仅含一个输出通道。
的输入层(为任意值),最后得到的输出层仅含一个输出通道。
进一步地,我们就能非常轻易地理解如何在不同深度的层(Layer)进行转换。假设输入层有
 个通道,而输出层需要得到
个通道,而输出层需要得到
 个通道。只需要将
个过滤器对输入层进行处理,而每一个过滤器有
个卷积核。每个过滤器提供一个输出通道。完成该过程将得到
个通道组成输出层。
个通道。只需要将
个过滤器对输入层进行处理,而每一个过滤器有
个卷积核。每个过滤器提供一个输出通道。完成该过程将得到
个通道组成输出层。
以彩色图像RGB为例(一个过滤器):

图是对一个3通道的图片做卷积操作,卷积核的大小为 3 × 3 ,卷积核的数目为3,此时
过滤器
指的就是这三个卷积核的集合,维度是 3 × 3 × 3 ,前面的 3 × 3 指的是卷积核的高度(H)和宽度(W),后面的那个 3 指的是卷积核的数目(通道数)。
上面的操作是对三个通道分别做卷积操作,然后将卷积的结果相加,最后输出一个特征图。
即: 一个过滤器就对应一个特征图。
2.3
2D卷积的计算
-
输入层:

-
超参数:
-
过滤器个数:

-
过滤器中卷积核维度:

-
滑动步长(Stride):

-
填充值(Padding):

-
输出层:

其中输出层和输入层之间的参数关系为,
参数量为:

3 三维卷积
3.1 3D卷积
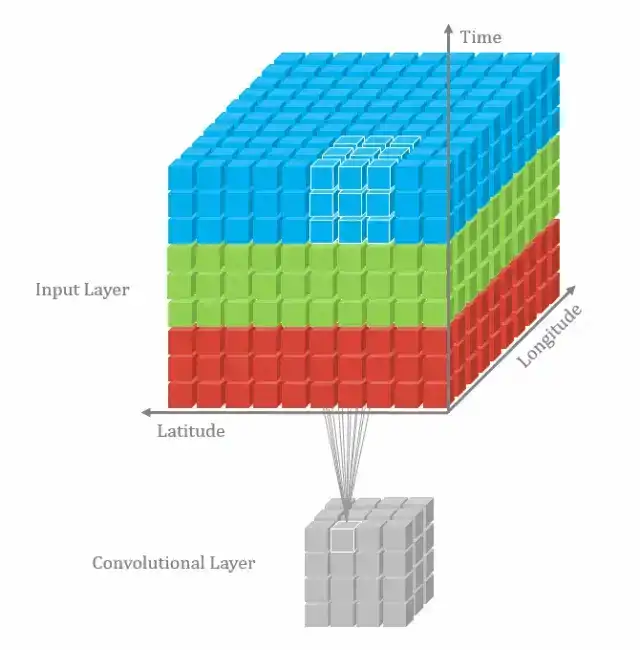
在上一个插图中,可以看出,这实际上是在完成3D卷积。但通常意义上,仍然称之为深度学习 的2D卷积。因为将滤波器深度和输入层深度相同,3D滤波器仅在2个维度上移动(例如图像的高度和宽度),得到的结果为单通道。
通过将2D卷积的推广,在3D卷积定义为滤波器的深度小于输入层的深度(即卷积核的个数小于输入层通道数),故3D滤波器需要在三个维度上滑动(输入层的长、宽、高)。在滤波器滑动的每个位置执行一次卷积操作,得到一个数值。当滤波器滑过整个3D空间,输出的结构也是3D的。
2D卷积和3D卷积的主要区别为滤波器滑动的空间维度。3D卷积的优势在于描述3D空间中的 对象关系。3D关系在某一些应用中十分重要,如3D对象的分割以及医学图像的重构等。
https://pic1.zhimg.com/50/v2-e7e31e6b4a86e54dc07e61a8144ce6dc_720w.webp?source=1940ef5c
3D卷积操作如图所示,同样分为单通道和多通道:
-
对于单通道输入,与2D卷积不同之处在于,输入图像多了一个深度(depth)维度,卷积核也多了一个
 维度,因此3D卷积核的尺寸为
维度,因此3D卷积核的尺寸为
 ,每次滑窗与
,每次滑窗与
 窗口内的值进行相关操作,得到输出3D图像中的一个值。
窗口内的值进行相关操作,得到输出3D图像中的一个值。
-
对于多通道输入,则与2D卷积的操作一样,每次滑窗与3个channels上的
窗口内的所有值进行相关操作,得到输出3D图像中的一个值。
这里采用代数的方式对三维卷积进行介绍,具体思想与一维卷积、二维卷积相同。
-
假设输入数据的大小为a1×a2×a3,channel数为c,过滤器大小为f,即过滤器维度为f×f×f×c(一般不写channel的维度),
过滤器数量为n
。
-
基于上述情况,三维卷积最终的输出为(a1−f+1)×(a2−f+1)×(a3−f+1)×n。该公式对于一维卷积、二维卷积仍然有效,只有去掉不相干的输入数据维度就行。
-
三维卷积常用于医学领域(CT影响),视频处理领域(检测动作及人物行为)。
3.2
3D卷积的计算
-
输入层:

-
超参数:
-
过滤器个数:
-
过滤器中卷积核维度:

-
滑动步长(Stride):
-
填充值(Padding):
-
输出层:

其中输出层和输入层之间的参数关系为,
参数量为:

4 如何理解卷积神经网络中的通道(channel)
在
卷积神经网络
中我们通常需要输入
in_channels
和
out_channels
,即输入
通道
数和输出通道数,它们代表什么意思呢?
核心观点:
-
对于最初输入图片样本的通道数
in_channels
取决于
图片的类型
,如果是彩色的,即RGB类型,这时候通道数固定为3,如果是灰色的,通道数为1。
-
卷积完成之后,输出的通道数
out_channels
取决于
过滤器的数量
。从这个方向理解,这里的
out_channels
设置的就是过滤器的数目。
-
对于第二层或者更多层的卷积,此时的
in_channels
就是上一层的
out_channels
,
out_channels
还是取决于过滤器数目。
在第2条用的是过滤器,而不是
卷积核
。
4.1 多通道
对于第1点和过滤器示例可以参考下图:

这里输入通道数是3,每个通道都需要跟一个卷积核做卷积运算,然后将结果相加得到一个特征图的输出,这里有4个过滤器,因此得到4个特征图的输出,输出通道数为4。
单个特征图的计算可看下图:
4.2 单通道
输入是灰色图片,输入通道数是1,卷积核有3个,做三次卷积操作,生成3个特征图,输出通道数为3。
单通道特征图的计算为:
这里可能会有人有疑惑为什么图片的类型是RGB的,它的通道数就是3呢?
这里要从计算机如何识别图片来考虑。在人眼中看到的图片是五颜六色,对于计算机来说就只是数字。那么计算机如何分辨图片颜色呢?——RGB。所有颜色都可以用这三种颜色来表示,因此我们只需要三个数字就可以表示一种颜色。
计算机要表示整张图片,就是用数字去表示整张图片的所有像素,但是每个像素需要三个数值来表示,于是就有了图片的3通道。每个通道分别表示RGB三种颜色。
最初的通道数是3,但是有的
神经网络
通道数目多达100多个,怎么理解呢?
我们依然可以类比RGB通道,对于
多通道
我们可以看做是颜色表示的更抽象版本,每一个通道都表示图像某一方面的信息。
卷积神经网络中二维卷积核与三维卷积核有什么区别? - 知乎
卷积神经网络(CNN)之一维卷积、二维卷积、三维卷积详解 - 程序员大本营
输入是7帧的灰度图。
对input 进行编码。
池化:只对空间维度进行池化。
卷积核是3*3*3,第一个3表示时间维度,后面两个表示空间维度
1一维卷积神经网络(1D-CNN) 一维卷积常用在序列模型、自然语言处理领域; 假设输入数据维度为8,filter维度为5,不加padding时,输出维度为4;如果filter的数量为16,那么输出数据的shape就是;2 二维卷积神经网络(2D-CNN) 二维卷积常用在计算机视觉、图像处理领域(在视频的处理中,是对每一帧图像分别利用CNN来进行识别,没有考虑时间维度的信息);输入是7帧的灰度图。...
内容来自:C3D的论文
应用于一个图像的2D卷积将输出一个图像,施加在多个图像上的2D卷积(将它们视为不同的通道)也输出一个图像。因此,2D ConvNets在每次卷积运算之后就会丢失输入信号的时间信息。
只有3D卷积才能保留输入信号的时间信息,从而产生输出卷。相同的现象适用于2D和3D池化。
在项目
中
用到了conv3但是对其背后的原理还有一些模糊的地方,conv2d与多通道的conv2d的
区别
在哪里?conv3d的思想理论是什么?对此进行探究和记录......
首先要明确多通道的2d卷积和3d卷积是不一样的,3d是可以在通道
中
移动的,2d不可以
学习了一段时间神经网络,也基于pytorch
1.1 2D卷积
你好! 这是你第一次使用 Markdown编辑器 所展示的欢迎页。如果你想学习如何使用Markdown编辑器, 可以仔细阅读这篇文章,了解一下Markdown的基本语法知识。
我们对Markdown编辑器进行了一些功能拓展与语法支持,除了标准的Markdown编辑器功能,我们增加了如下几点新功能,帮助你用它写博客:
全新的界面设计 ,将会带来全新的写作体验;
在创作
中
心设置你喜爱的代码高亮样式,Markdown 将代码片显示选择的高


{kind=link}
{kind=link}
{kind=link}