

pytorch 分布式计算 你们都遇到过哪些 坑/bug?
关注者
520
被浏览
275,185
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

该回答实时更新中。本回答的最佳食用方式是作为一些教程的补漏和检查,并且适合类似我这种啥都不懂的超级新手。
-------------2021.01.30--------------
好久不见!我又来写bug了!
进程的torch变量只能读到0号卡上,无法送到指定GPU
- 这个问题主要是我的设置方式不对,我的实现是python -m torch.distributed.launch 启动多进程,然后os.environ["CUDA_VISIBLE_DEVICES"] = os.environ["CUDA_VISIBLE_DEVICES"].split(',')[args.local_rank]
- 上面那种方式改为os.environ["CUDA_VISIBLE_DEVICES"]在shell里面提前设置,然后args.device = torch.device(args.local_rank)即可
代码运行到iter(dataloader)后没有反应了
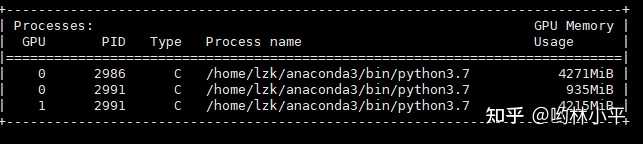
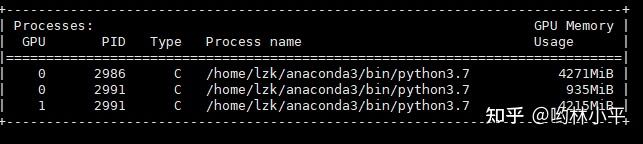
这个问题不一定具有普适性,因为我是魔改过dataloader的iter函数,所以果断ctrl+c中断,看看卡在了哪个位置:
class DDPBaseBucketSampler(torch.utils.data.distributed.DistributedSampler):
def __iter__(self):
print('dist.rank() = ' , dist.get_rank())
estimate_batch = torch.Tensor([estimate_batch]).cuda()
dist.all_reduce(estimate_batch, op=dist.ReduceOp.MIN)
estimate_batch
= int(estimate_batch.cpu().item())
print('dist.rank() = ' , dist.rank())
...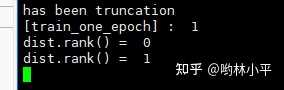
上面那行代码我是想干什么呢?当时为了排除bug的出处,我一度怀疑不同进程的iter轮数如果不一样,就会导致报错,所以我决定在不同进程之间约定一个迭代的最小步数。现在把这行代码注释掉就没有问题。
但是就在注释掉的1个小时以后,我又把她加回来了。这好吗?这不好。加回来的原因是我确实需要她。因为我跑了4个进程,其中一个进程只用循环156次,其他三个都是157次(因为继承了ddpsampler类,所以很多逻辑都不鲁棒稳健了)于是那个进程就先行退出循环,留下三个进程卡在循环里动都不动,我估计是model更新的时候同步锁导致的(谁让有个进程临阵脱逃呢?)
上面那个代码最大的问题出在:
estimate_batch = torch.Tensor([estimate_batch]).cuda()这样是没办法通信的,也导致了所有的张量都在0号卡上面
master进程的GPU负载过重
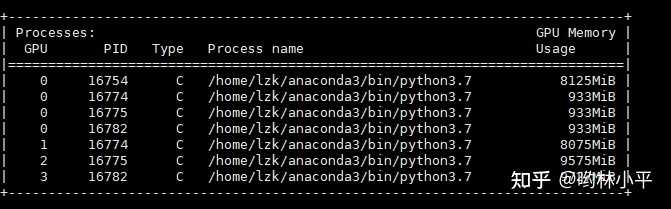
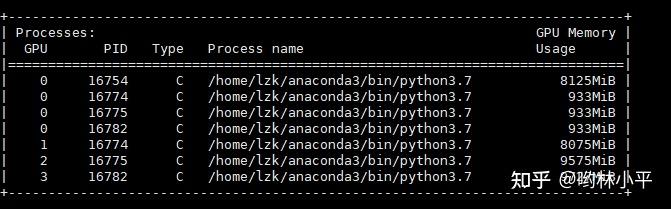
这样的坏处是达达限制了我的batch size的大小。通过师兄了解到,0号卡有四个进程是正常的,但是933MiB确实太大了。
- 然后注释掉model,注释掉batch to device,问题均存在,说明bug大概率在dataloader里面
- 再把dataset设置成100个数据,发现依然占用933MB
- 最后设置pin_memory=False,0号卡干干净净,没有任何占用了


但是为什么pin_memory就会占用很大,这个问题暂时没有搞清楚
贴一个整理的比较好的博客:
-------------2020.12.08--------------
RuntimeError: unable to open shared memory object </torch_24063_2365344576> in read-write mode
完整信息:
-- Process 1 terminated with the following error:
Traceback (most recent call last):
File "/home/lzk/anaconda3/lib/python3.7/site-packages/torch/multiprocessing/spawn.py", line 19, in _wrap
fn(i, *args)
File "/home/lzk/IJCAI2021/GraphWriter-DGL/train.py", line 278, in main
train_loss = train_one_epoch(model, train_dataloader, optimizer, args, epoch, rank, device, writer)
File "/home/lzk/IJCAI2021/GraphWriter-DGL/train.py", line 63, in train_one_epoch
for _i , batch in enumerate(dataloader):
File "/home/lzk/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 278, in __iter__
return _MultiProcessingDataLoaderIter(self)
File "/home/lzk/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py", line 682, in __init__
w.start()
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/process.py", line 112, in start
self._popen = self._Popen(self)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/context.py", line 223, in _Popen
return _default_context.get_context().Process._Popen(process_obj)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/context.py", line 284, in _Popen
return Popen(process_obj)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/popen_spawn_posix.py", line 32, in __init__
super().__init__(process_obj)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/popen_fork.py", line 20, in __init__
self._launch(process_obj)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/popen_spawn_posix.py", line 47, in _launch
reduction.dump(process_obj, fp)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/reduction.py", line 60, in dump
ForkingPickler(file, protocol).dump(obj)
File "/home/lzk/anaconda3/lib/python3.7/site-packages/torch/multiprocessing/reductions.py", line 314, in reduce_storage
metadata = storage._share_filename_()
RuntimeError: unable to open shared memory object </torch_30603_1696564530> in read-write mode用指令ulimit -a来查看当前用户的各项limit限制:
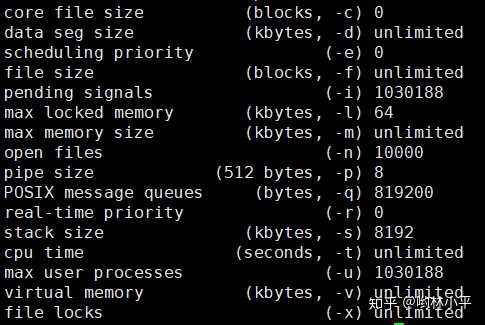
我的问题出现在dataloader,查了一番博客,主要有2种解决方式:
- 增大空间:ulimit -SHn 51200;
- 限制number_workers为0(但是杀敌一千,自损八百,这么做以后我的epoch时间慢了一倍)
- 换成小数据集就不会有这样的错误,但同样治标不治本
-------------2020.12.07--------------
pytorch ddp tensorboard多进程出现EOF Error
报错如下(发生在所有进程运行完以后,销毁进程组以前):
Traceback (most recent call last):
File "/home/lzk/anaconda3/lib/python3.7/threading.py", line 917, in _bootstrap_inner
self.run()
File "/home/lzk/anaconda3/lib/python3.7/site-packages/tensorboardX/event_file_writer.py", line 202, in run
data = self._queue.get(True, queue_wait_duration)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/queues.py", line 108, in get
res = self._recv_bytes()
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/connection.py", line 216, in recv_bytes
buf = self._recv_bytes(maxlength)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/connection.py", line 407, in _recv_bytes
buf = self._recv(4)
File "/home/lzk/anaconda3/lib/python3.7/multiprocessing/connection.py", line 383, in _recv
raise EOFError
EOFError
查看
多进程官方文档
,我发现出错的函数_recv_bytes,如果连接对象被对端关闭或者没有数据可读取,将抛出
EOFError
异常。而报错的地方又是tensorboardX,大概率是tensorboard没有及时关闭。关闭记录仪后报错消失
writer = SummaryWriter(args.save_record_dir+'/log/SummaryWriter/', comment=args.save_model)
writer.close() #我漏掉这一句。模型加载后等了很久没反应
出现在以下位置:
for _i, batch in dataloader:
...结果GPU的利用率一直都是0,但是模型1427MB确实已经装载进去了。
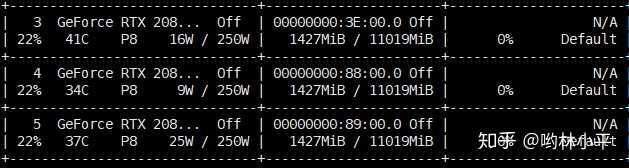
这是因为dataloader初始化(或者进程间通信?)的关系,并不是有bug,只需要等一段时间即可。
多进程如何写log,计算loss,以及tdpm的问题
实际上这个问答也是个问题,因为batch被分散到各个进程时,如果都print,界面就会很乱,我被实验室的师兄建议只在主进程print必要信息,如此一来,改动代码的时候需要做:
- 函数或者类需要新增参数rank;
- 所有print都用rank==0控制
至于tdpm都在各进程实现的结果,你会发现屏幕上的进度条,一会属于进程0,一会属于进程1;进度条的it数值也会不准:




这个问题我目前没有很好的解决办法,不过无伤大雅,而且loss如果不需要合并各个进程的话,也可以只算master的卡,并不一定要用reduce函数聚合。


-------------2020.12.01--------------
确保各进程的模型参数初始化是一致的
在整个训练过程中,模型必须启动并保持同步,这一点非常重要。 否则,您将获得不正确的渐变,并且模型将无法收敛。
def set_seed(seed):
#必须禁用模型初始化中的任何随机性。
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.set_deterministic(True)-------------2020.11.30--------------
重写sampler的小粗心
单卡情况下我的模型需要自定义Sampler,这个需求源自于
作者为了避免生成的文本时长时短造成的资源浪费或者oom(例如一个batch里面既有30个token的摘要,也有400个token的摘要,如此一pad要么对于lstm(还是加了attention,只能用lstm cell没法pad_pack的极端恶劣情况)而言过于冗长,要么轻易提高batch size就爆卡),而需要将长度接近的摘要放在一个batch里面。以上是需求。
单卡情况下,继承torch.utils.data.Sampler类,需要初始化self.data_source如下:
class HierBucketSampler(torch.utils.data.Sampler):
def __init__(self, data_source, batch_size=32):
self.data_source = data_source
self.batch_size = batch_size多卡情况时,由于此时的sampler已经变成了torch.utils.data.distributed.DistributedSampler,一开始我很自以为是的ctrl cv,后面发现程序根本跑不动,仔细查阅pytorch的文档后发现在这个分布式采样器的定义里,数据集已经不叫self.data_source而是self.dataset。如下改动后程序可以成功的run了:
class DDPHierBucketSampler(torch.utils.data.distributed.DistributedSampler):