

汇总简析:GAN和扩散模型生成训练数据

1、X-Paste: Revisit Copy-Paste at Scale with CLIP and StableDiffusion
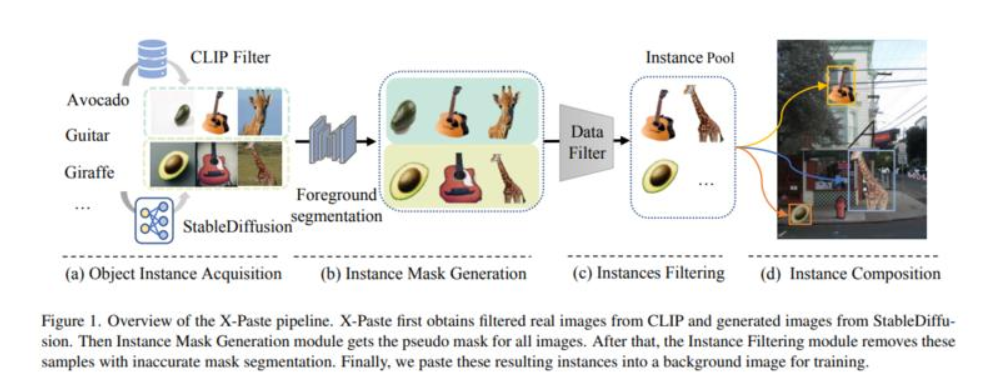
- “复制-粘贴”是一种简单有效的数据增强策略,例如分割。通过将对象实例随机粘贴到新的背景图像上,它可以创建新的训练数据,并提高效果,尤其是对于稀有对象类别。尽管,复制难以扩展多样性。
- 基于零样本识别模型(例如CLIP)和Text2Image模型(例如Stablediffusion),本文重新思考复制这种增广手段。本文首次证明,使用Text2Image模型生成图像或零样本识别模型来过滤不同对象类别的爬取到的噪声图像,是一种真正可扩展的方法。
- 设计了一个被称为“ X-Paste”的数据采集和处理框架,并在其上进行了系统的研究。在LVIS数据集上,X-Paste以Swin-L为骨干对强基线Centernet2 取得了非常不错的改进。
2、GENERATIVE ADVERSARIAL NETWORKS FOR ANONYMOUS ACNEIC FACE DATASET GENERATION
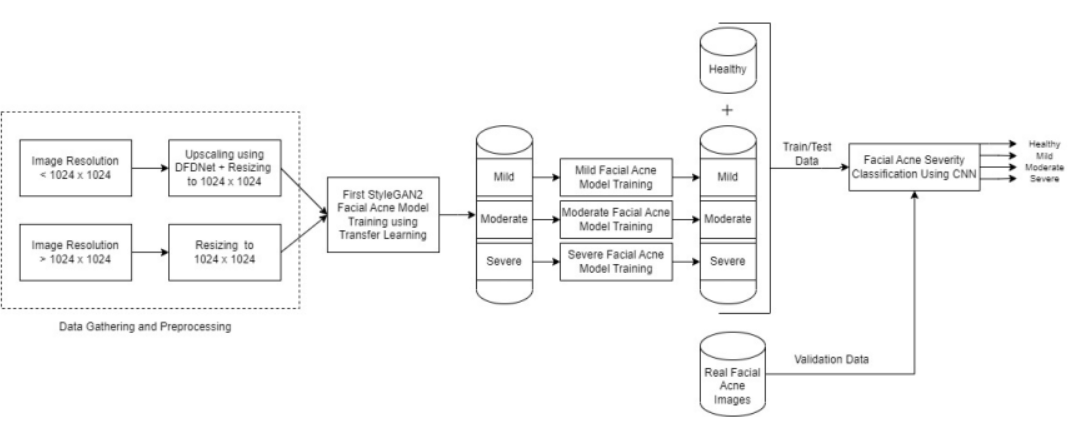
- 众所周知,如果用于训练过程和测试过程的数据集满足某些特定的要求,任何分类模型的性能都是有效的。换句话说,数据集规模越大、越均衡、越有代表性,人们就越能相信所提出的模型的有效性,从而也就越能相信所获得的结果。不幸的是,大型数据集在生物医学应用中通常无法公开使用,特别是在处理病理性人脸图像的应用中。这种担忧使得基于深度学习的方法难以部署,也难以复制或验证一些已发表的结果。
- 这篇论文提出一种有效的方法来生成一个真实的匿名合成人脸数据集,该数据集具有对应于三个严重级别(即轻度、中度和严重)的痤疮疾病属性。因此,考虑了一种特定层次的基于stylegan的算法。为了评估所提方案的性能,考虑了一个基于cnn的分类系统,使用生成的合成痤疮人脸图像进行训练,并使用真实的人脸图像进行测试。表明使用InceptionResNetv2实现了97.6%的准确性。因此,这项工作允许科学界将生成的合成数据集用于任何数据处理应用程序,而不受法律或伦理方面的限制。此外,该方法还可以扩展到其他需要生成合成医学图像的应用。
3、DOES AN ENSEMBLE OF GANS LEAD TO BETTER PERFORMANCE WHEN TRAINING SEGMENTATION NETWORKS WITH SYNTHETIC IMAGES?
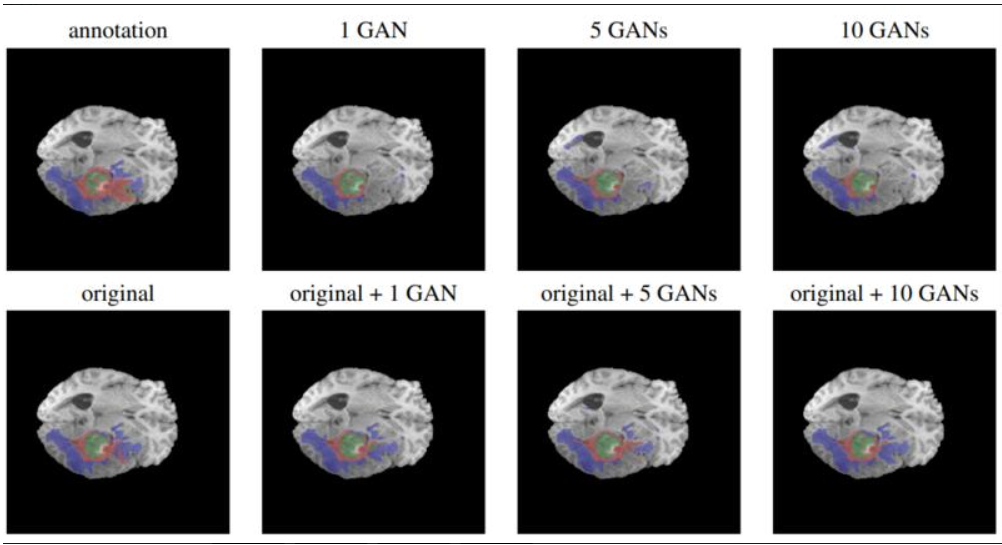
- 训练分割网络需要带标注的大型数据集。在医学成像中,创建这样的数据集通常是困难的、耗时的和昂贵的,与其他研究人员共享这些数据集也可能是困难的。如今,不同的人工智能模型可以生成非常逼真的合成图像。
- 然而,最近的研究表明,使用合成图像训练深度网络的性能往往比使用真实图像差。在这里,演示了使用来自10个GAN的合成图像和标签,而不是来自单个GAN,将真实测试图像上的Dice分数提高了4.7%到14.0%。
4、How to Boost Face Recognition with StyleGAN?
- 最先进的人脸识别系统需要大量标记的训练数据。鉴于人脸识别应用中的隐私优先级,数据仅限于名人网络爬虫,这些数据存在种族分布倾斜和身份数量有限等问题。另一方面,行业中的自监督进展激发了相关技术对人脸识别的适应研究。最流行的实用技巧之一是通过从高分辨率高保真模型(例如 StyleGAN-like)中抽取的样本来扩充数据集,同时保留身份。
- 本文展示了一种基于微调 StyleGAN 编码器的简单方法可以改进最先进的人脸识别,并且与合成人脸身份的训练相比表现更好。还收集了具有可控种族构成的大规模未标记数据集——AfricanFaceSet-5M(500 万张不同人的图像)和 AsianFaceSet-3M(300 万张图片) 对每个人进行预训练可以提高对各自种族(以及其他种族)的识别,同时结合所有未标记的数据集会导致最大的性能提升。自监督策略在标记训练数据量有限的情况下最有用,这对于更量身定制的人脸识别任务和面临隐私问题时可能是有益的。基于标准 RFW 数据集和新的大规模 RB-WebFace 基准提供评估。
- https://github.com/seva100/stylegan-for-facerec
5、Synthetic Data Supervised Salient Object Detection
- 尽管基于深度学习的显著目标检测 (deep salient object detection, SOD) 取得了不错进展,但SOD 模型非常需要数据,需要大规模的像素级标注。
- 本文提出一种新的 SOD 方法,即SODGAN,它可以生成无限的高质量图像掩码对,只需要少量标记数据,这些合成对可以代替人工标记的 DUTS-TR 来训练任何-现成的 SOD 模型。贡献有三:
1)提出的扩散嵌入网络可以解决流形不匹配问题,并且易于生成潜码,与 ImageNet 潜在空间更好地匹配。
2)提出的few-shot显著性掩模生成器第一次可以用少量标记数据合成无限精确的图像显著性掩模。
3)提出的质量感知判别器可以从嘈杂的合成数据池中选择高质量的合成图像掩模对,提高合成数据的质量。
- SODGAN 首次使用从生成模型的合成数据来处理 SOD,这为 SOD 开辟了新的研究范式。大量实验结果表明,在合成数据上训练的模型可以达到在 DUTS-TR 上训练的模型的 98.4% F-measure。此外,方法在半监督方法中实现了新的 SOTA 性能,甚至优于几种全监督 SOTA 方法。
- https://github.com/wuzhenyubuaa/SODGAN
6、A Scene-Text Synthesis Engine Achieved Through Learning from Decomposed Real-World Data
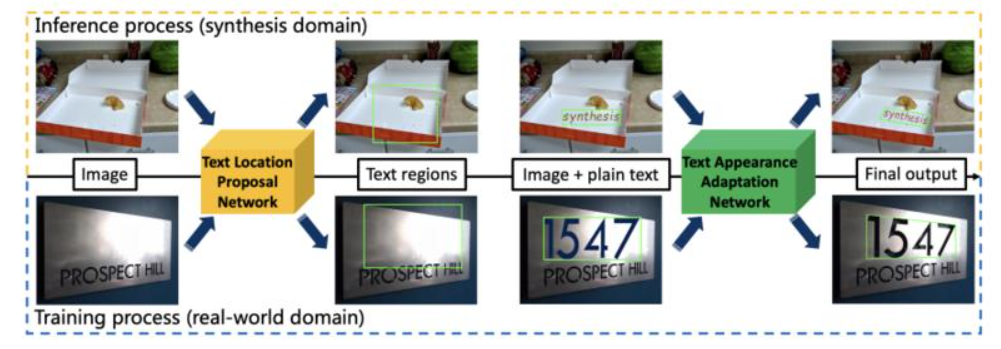
- 场景文本图像合成技术,在背景场景图像上自然组合文本实例,对于训练深度神经网络非常有吸引力,因为它们可以提供准确和全面的标注信息。先前的研究已经探索了基于从现实世界观察得出的规则在二维和三维表面上生成合成文本图像。其中一些研究提出从学习中生成场景文本图像;然而,由于缺乏合适的训练数据集,已经探索了无监督框架以从现有的现实世界数据中学习,这可能不会产生稳健的性能。
- 为了缓解这种困境并促进基于学习的场景文本合成的研究,提出 DecompST,一个使用公共基准的真实世界数据集,具有三种类型的注释:四边形级 BBoxes、笔划级文本掩码和文本擦除图像。使用 DecompST 数据集,提出了一个图像合成引擎,该引擎包括一个文本位置提议网络(TLPNet)和一个文本外观适应网络(TAANet)。TLPNet 首先预测适合文本嵌入的区域。TAANet 然后根据背景的上下文自适应地改变文本实例的几何形状和颜色。实验验证了所提出的为场景文本检测器生成预训练数据的方法的有效性。
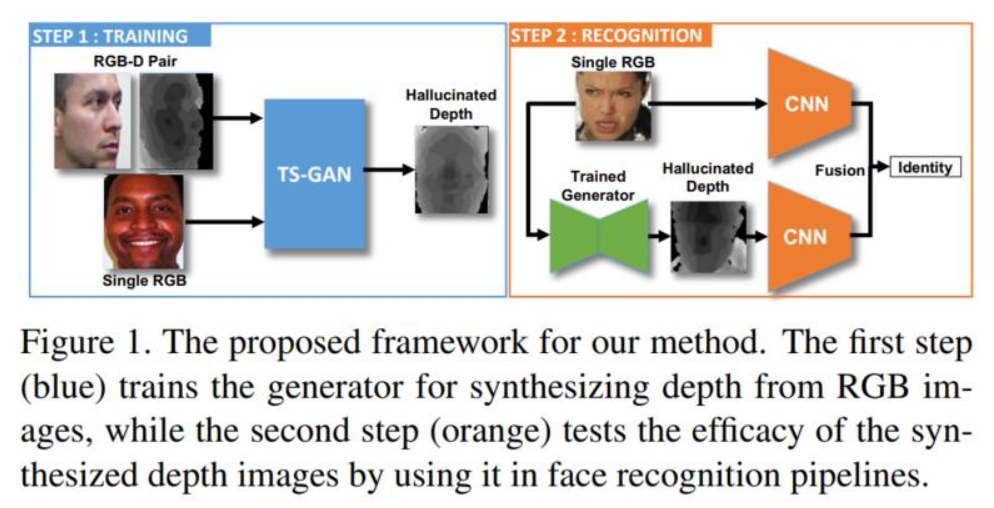
7、Teacher-Student Adversarial Depth Hallucination to Improve Face Recognition
- 提出“师生生成对抗网络 (TS-GAN, Teacher-Student Generative Adversarial Network) ”从单个 RGB 图像生成深度图像,以提高人脸识别系统的性能。为泛化到未知的数据集,设计教师模块和学生模块。
- 教师本身由一个生成器和一个判别器组成,以监督的方式学习输入 RGB 和对应的深度图像之间的潜在映射。
- 学生由两个生成器(一个与教师共享)和一个判别器组成,它从没有可用配对深度信息的新 RGB 数据中学习,以提高泛化能力。然后可以在运行时使用经过充分训练的共享生成器从 RGB 中产生虚拟的深度信息,以用于人脸识别等下游应用。
- 人脸识别实验表明,与单一 RGB 模态相比,性能提高 +1.2%、+2.6% 和 +2.6%( IIITD、EURECOM 和LFW 数据集)。
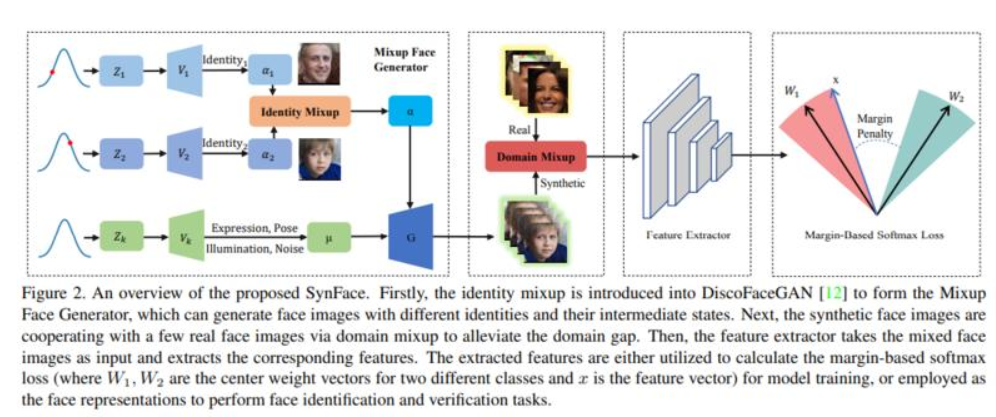
8、SynFace: Face Recognition with Synthetic Data
随着最近深度神经网络的成功,人脸识别取得了显著进展。但收集用于人脸识别的大规模真实世界训练数据具有挑战性,尤其是由于标签噪声和隐私问题。同时,现有的人脸识别数据集通常是从网络图像中收集的,缺乏对属性(例如姿势和表情)的详细注释,因此对不同属性对人脸识别的影响研究很少。
本文使用合成人脸图像(即 SynFace)解决人脸识别中的上述问题。具体来说,探讨使用合成和真实人脸图像训练的最先进的人脸识别模型之间的性能差距。然后,分析性能差距背后的根本原因,例如,较差的类内变化以及合成和真实人脸图像之间的域差距。受此启发,设计了具有身份混合 (IM) 和域混合 (DM) 的 SynFace,以缩小上述性能差距,展示了合成数据在人脸识别方面的巨大潜力。
此外,通过可控的人脸合成模型,可以轻松管理合成人脸的不同因素,包括姿势、表情、光照、身份数量和每个身份的样本。因此,还对合成人脸图像进行了系统的实证分析,以提供一些关于如何有效利用合成数据进行人脸识别的见解。
9、BigDatasetGAN: Synthesizing ImageNet with Pixel-wise Annotations
- 像在图像分割里,对图像每个像素进行标注非常耗时且成本不菲。最近,DatasetGAN(论文Datasetgan: Efficient labeled data factory with minimal human effort)展示了一种方法:通过利用少部分标签而基于 GAN 生成图像,达到生成大型标注数据集的效果。本文将 DatasetGAN 扩展到 ImageNet 那种极具类别多样性规模的应用上。
- 在 ImageNet 上训练的类条件生成模型 BigGAN 得到图像样本,并为所有 1k 个类中每个类仅人工标注 5 张图像。通过在 BigGAN 之上训练有效的特征分割架构,将 BigGAN 变成标注数据集生成器。也进一步表明,VQGAN 可以类似地用作数据集生成器。
- 通过广泛的消融研究,展示了利用生成的大型数据集在像素级任务上训练不同的监督和自监督骨干模型方面取得的进步。此外证明了使用合成的数据集进行预训练可以改进几个下游数据集的标准 ImageNet 预训练,例如 PASCAL-VOC、MS-COCO、Cityscapes 和胸部 X 射线,以及任务(检测,分割)。
- https://nv-tlabs.github.io/big-datasetgan/
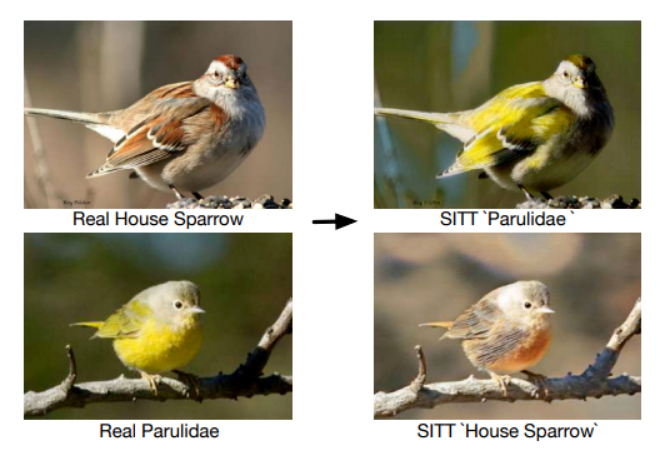
10、Single Image Texture Translation for Data Augmentation
- 图像生成的迅猛发展使人们可以通过学习源域和目标域之间的映射来完成图像转换任务。很多方法通过在各种数据集上训练模型来学习数据分布,其生成结果也主要以主观方式评估。
- 关于研究其潜在用途,比如用于图像分类识别的语义图像转换方法探索较少。本文探索使用 Single Image Texture Translation (SITT)单图纹理转换去做数据增强。
- 首先提出一种纹理转换的轻量级模型,基于源纹理的单一输入,可以完成快速训练和测试。实验表明SITT在长尾和少样本图像分类识别任务中进行数据增强后,可以提高识别效果。
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读