

4 个回答


人口出生数字能够使用算法模型预测?答案是可以的。
我们以天为单位,每天都会统计一个出生的数字作为当天的一个时间变量。这样我们的数据就有了。这种数据就可以应用 ARIMA(时间序列) 预测。
也可以应用 XGBoost ,需要先将时间序列数据集转化为监督学习问题。还需要使用一种专门的技术来评估模型,称为前向验证。


听起来很复杂,但是真正实现的话也非常容易。
对于预测来说模型变量中只要包含 时间和具体值 即可进行操作。
XGBoost 集成
XGBoost 是 Extreme Gradient Boosting 的缩写,随机梯度提升算法,也称为梯度提升机或树提升,是决策树算法的集合,是一种强大的机器学习技术,在各种具有挑战性的机器学习问题上表现良好甚至最佳。
《XGBoost: A Scalable Tree Boosting System》 2016年 Tree boosting has been shown to give state-of-the-art results on many standard classification benchmarks. 树提升已被证明可以在许多标准分类基准上提供最先进的结果。
XGBoost 提供了一种高效的随机梯度提升算法实现,并提供了一套模型超参数的访问,旨在提供对模型训练过程的控制。
《XGBoost: A Scalable Tree Boosting System》 2016年 The most important factor behind the success of XGBoost is its scalability in all scenarios. The system runs more than ten times faster than existing popular solutions on a single machine and scales to billions of examples in distributed or memory-limited settings. XGBoost 成功背后最重要的因素是其在所有场景中的可扩展性。该系统在单台机器上的运行速度比现有流行解决方案快十倍以上,并且可以在分布式或内存有限的设置中扩展到数十亿个示例。
pip 安装安装 XGBoost 库
pip install xgboost检查版本
import xgboost
print("xgboost", xgboost.__version__)
>>> xgboost 1.0.1尽管 XGBoost 库有自己的 Python API,但我们可以通过 XGBRegressor 包装器类将 XGBoost 模型与 scikit-learn API 一起使用。模型的实例可以像任何其他 scikit-learn 类一样被实例化和用于模型评估。
model = XGBRegressor()人口预测的数据准备
时间序列数据可以称为监督学习 ,给定时间序列数据集的一系列数字,我们可以重构数据,使其看起来像一个监督学习问题。可以通过使用前一个时间步作为输入变量并使用下一个时间步作为输出变量来做到这一点。


例如如下的时间序列数据
time, measure
1, 100
2, 110
3, 108
4, 115
5, 120可以通过使用前一时间步的值来预测下一时间步的值,将此时间序列数据集重构为监督学习问题。并以这种方式重新组织时间序列数据集
X, y
?, 100
100, 110
110, 108
108, 115
115, 120
120, ?时间数据列已删除,并且第一行和最后一行数据行无法用于训练模型, 这种被称为滑动窗口 ,因为输入和预期输出的窗口随着时间向前移动,为监督学习模型创建新的 样本 。
可以使用 Pandas 中的 shift() 函数自动创建时间序列问题的新框架,给定输入和输出序列的所需长度。可以让机器学习算法探索时间序列问题使用不同的框架,或许可能会产生更好的模型进行预测。
将时间序列作为具有一列或多列的 NumPy 数组时间序列,并将其转换为具有指定输入和输出数量的监督学习问题。
# 将时间序列数据集转换为有监督的学习数据集
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols = list()
# 输入序列 (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
# 预测序列 (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
# 信息汇总
agg = concat(cols, axis=1)
# 删除空值
if dropnan:
agg.dropna(inplace=True)
return agg.values我们可以使用此函数为 XGBoost 准备时间序列数据集并可以拟合和评估模型,该模型必须根据过去进行训练并预测未来。这意味着不能使用在评估期间随机化数据集的方法,如 k 折交叉验证。相反必须使用一种称为前向验证的技术。
在前向验证中,首先通过选择一个切点将数据集分为训练集和测试集,例如将除去最后 N(N≥1) 天以外的所有数据用于训练,最后 N(N≥1) 天用于测试。
重复此过程设置不同的 N 值和 k 折,可以计算误差度量进行模型的评估。
函数执行向前验证 逐步遍历测试集,调用 xgboost_forecast() 函数进行一步预测,计算误差度量并返回详细信息用于后续模型调整分析。
# 单变量数据的前向验证
def walk_forward_validation(data, n_test):
predictions = list()
# 切分数据集
train, test = train_test_split(data, n_test)
# 使用训练数据集历史信息
history = [x for x in train]
# 步进测试集中的每个时间节点
for i in range(len(test)):
# 将测试行分割为输入和输出列
testX, testy = test[i, :-1], test[i, -1]
# 根据历史拟合模型并进行预测
yhat = xgboost_forecast(history, testX)
# 在预测列表中存储预测
predictions.append(yhat)
# 将实际观察添加到下一个循环的历史中
history.append(test[i])
# 汇总结果
print('>expected=%.1f, predicted=%.1f' % (testy, yhat))
# 估计预测误差
error = mean_absolute_error(test[:, -1], predictions)
return error, test[:, 1], predictionstrain_test_split() 函数被调用到数据集分成训练集和测试集。
# 将一个单变量数据集分割成训练/测试集
def train_test_split(data, n_test):
return data[:-n_test, :], data[-n_test:, :]使用 XGBRegressor 类进行一步预测, xgboost_forecast() 将训练数据集和测试输入行作为输入,拟合模型,并进行一步预测。
# 拟合xgboost模型并进行一步预测
def xgboost_forecast(train, testX):
# 将列表转换为数组
train = asarray(train)
# 分成输入和输出列
trainX, trainy = train[:, :-1], train[:, -1]
# 拟合模型
model = XGBRegressor(objective='reg:squarederror', n_estimators=1000)
model.fit(trainX, trainy)
# 做一步预测
yhat = model.predict([testX])
return yhat[0]应用 XGBoost 预测模型
应用标准的单变量时间序列数据集进行一步预测,可以套用这个代码模板调整为多变量输入、多变量预测和多步预测。
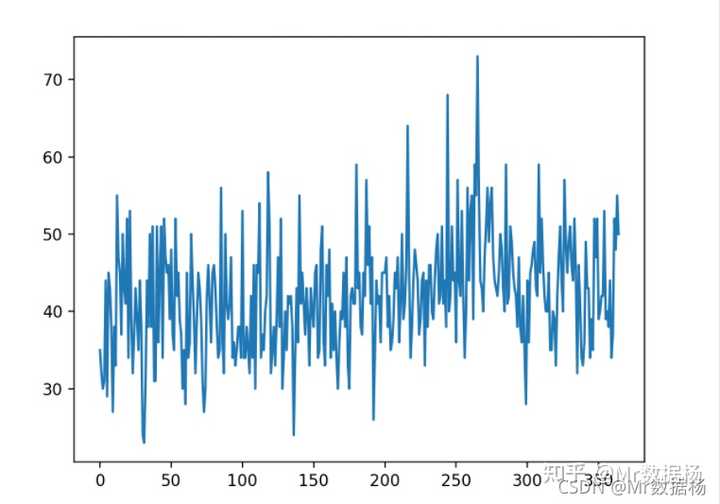
我们将使用每日女性出生数据集,即三年内的每月出生数。
数据集(daily-total-female-births.csv) 描述(daily-total-female-births.names)
数据集的前几行如下所示:
"Date","Births"
"1959-01-01",35
"1959-01-02",32
"1959-01-03",30
"1959-01-04",31
"1959-01-05",44绘制数据集
# 加载并绘制时间序列数据集
from pandas import read_csv
from matplotlib import pyplot
# 加载数据集
series = read_csv('daily-total-female-births.csv', header=0, index_col=0)
values = series.values
# 绘制数据集
pyplot.plot(values)
pyplot.show()可以看到没有明显的趋势或季节性。
在预测最后 N=12 天时,最终计算的 MAE ≈ 6.7 。暂定了一个模型评估标准,高于该基准的模型可以被认为是较好的。然后在对过去 12 天的数据进行一步预测时在数据集上评估 XGBoost 模型。
我们将仅使用前 6 个时间步作为模型和默认模型超参数的输入,除了我们将损失更改为 reg:squarederror (以避免出现警告消息)并在集成中使用 1000 棵树(避免学习样本不足的情况) )。
完整的代码示例
from numpy import asarray
from pandas import read_csv
from pandas import DataFrame
from pandas import concat
from sklearn.metrics import mean_absolute_error
from xgboost import XGBRegressor
from matplotlib import pyplot
# 将时间序列数据集转换为有监督的学习数据集
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols = list()
# 输入序列 (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
# 预测序列 (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
# 信息汇总
agg = concat(cols, axis=1)
# 删除带有空数据的行
if dropnan:
agg.dropna(inplace=True)
return agg.values
# 将一个单变量数据集分割成训练/测试集
def train_test_split(data, n_test):
return data[:-n_test, :], data[-n_test:, :]
# 拟合xgboost模型并进行一步预测
def xgboost_forecast(train, testX):
# 将列表转换为数组
train = asarray(train)
# 分成输入和输出列
trainX, trainy = train[:, :-1], train[:, -1]
# 拟合模型
model = XGBRegressor(objective='reg:squarederror', n_estimators=1000)
model.fit(trainX, trainy)
# 做一步预测
yhat = model.predict(asarray([testX]))
return yhat[0]
# 单变量数据的前向验证
def walk_forward_validation(data, n_test):
predictions = list()
# 切分数据集
train, test = train_test_split(data, n_test)
# 使用训练数据集历史信息
history = [x for x in train]
# 步进测试集中的每个时间节点
for i in range(len(test)):
# 将测试行分割为输入和输出列
testX, testy = test[i, :-1], test[i, -1]
# 根据历史拟合模型并进行预测
yhat = xgboost_forecast(history, testX)
# 在预测列表中存储预测
predictions.append(yhat)
# 将实际观察添加到下一个循环的历史中
history.append(test[i])
# 汇总结果
print('>expected=%.1f, predicted=%.1f' % (testy, yhat))
# 估计预测误差
error = mean_absolute_error(test[:, -1], predictions)
return error, test[:, -1], predictions
# 加载数据集
series = read_csv('daily-total-female-births.csv', header=0, index_col=0)
values = series.values
# 将时间序列数据转换为有监督学习
data = series_to_supervised(values, n_in=6)
mae, y, yhat = walk_forward_validation(data, 12)
print('MAE: %.3f' % mae)
# 绘制预测结果图
pyplot.plot(y, label='Expected')
pyplot.plot(yhat, label='Predicted')
pyplot.legend()
pyplot.show()运行代码会打印测试集中每个步骤的预期和预测值和所有预测值的 MAE。
注意 :结果可能会因算法或评估程序的随机性或数值精度的差异而有所不同,多次运行该示例并比较平均结果。实现了 5.9 出生 MAE ,优越于 6.7 出生 MAE 。
还可以测试不同的 XGBoost 超参数和时间步数作为输入,看看是否可以获得更好的结果,也可以下方留言分享出来。
> expected=42.0, predicted=44.5
> expected=53.0, predicted=42.5
> expected=39.0, predicted=40.3
> expected=40.0, predicted=32.5
> expected=38.0, predicted=41.1
> expected=44.0, predicted=45.3
> expected=34.0, predicted=40.2
> expected=37.0, predicted=35.0
> expected=52.0, predicted=32.5
> expected=48.0, predicted=41.4
> expected=55.0, predicted=46.6
> expected=50.0, predicted=47.2
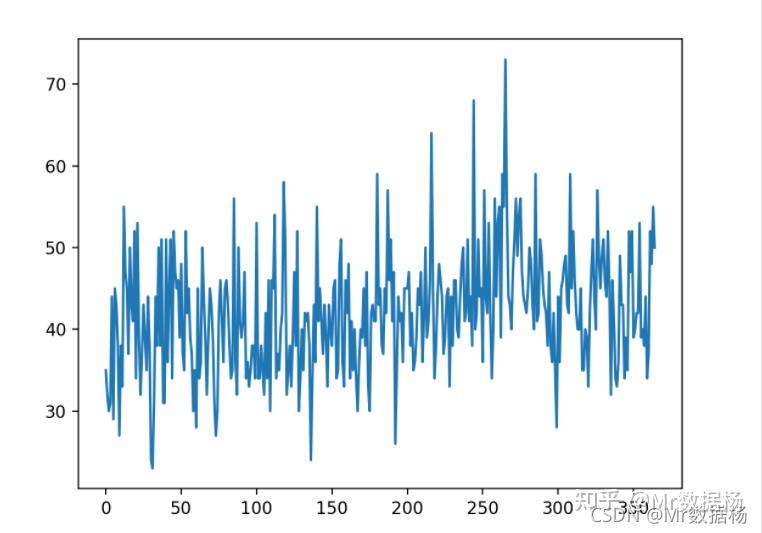
MAE: 5.957绘制折线图,比较 N=12 的的预测值和实际值。这也是模型在测试集上的表现的几何解释。
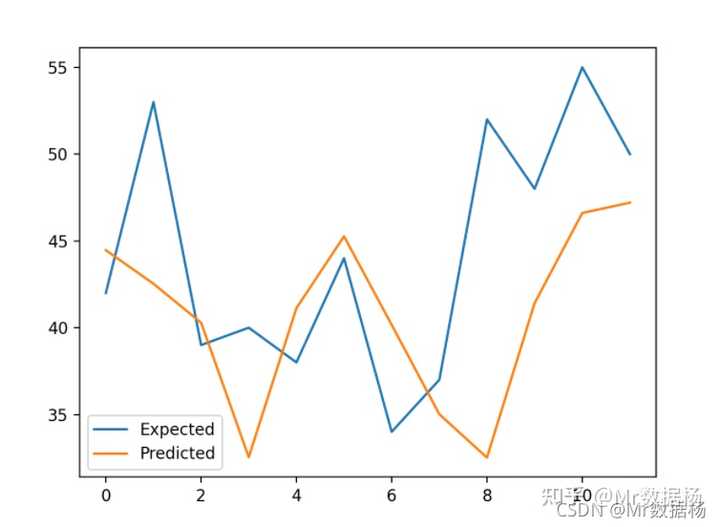
一旦选择了最终的 XGBoost 模型配置,就可以最终确定模型并用于对新数据进行预测。
这称为 样本外预测 ,例如在训练数据集之外进行预测。这与在模型评估期间进行预测相同,因为希望使用与模型用于对新数据进行预测时期望使用的相同程序来评估模型。
下面的示例演示了在所有可用数据上拟合最终 XGBoost 模型并在数据集末尾进行一步预测。
# 使用 xgboost 完成模型并预测每月出生
from numpy import asarray
from pandas import read_csv
from pandas import DataFrame
from pandas import concat
from xgboost import XGBRegressor
# 将时间序列数据集转换为有监督的学习数据集
def series_to_supervised(data, n_in=1, n_out=1, dropnan=True):
n_vars = 1 if type(data) is list else data.shape[1]
df = DataFrame(data)
cols = list()
# 输入序列 (t-n, ... t-1)
for i in range(n_in, 0, -1):
cols.append(df.shift(i))
# 预测序列 (t, t+1, ... t+n)
for i in range(0, n_out):
cols.append(df.shift(-i))
# 信息汇总
agg = concat(cols, axis=1)
# 删除带有空数据的行
if dropnan:
agg.dropna(inplace=True)
return agg.values
# 加载数据集
series = read_csv('daily-total-female-births.csv', header=0, index_col=0)
values = series.values
# 将时间序列数据转换为有监督学习
train = series_to_supervised(values, n_in=6)
# 分成输入和输出列
trainX, trainy = train[:, :-1], train[:, -1]
# 拟合模型
model = XGBRegressor(objective='reg:squarederror', n_estimators=1000)