

回归分析中多重共线性问题怎么理解?
关注者
12
被浏览
33,431
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

一、什么是多重共线性?
多重共线性是指线性回归模型中的自变量(解释变量)之间由于存在精确 相关关系 或高度相关。就是指一个自变量的变化引起另一个自变量的变化。
共线性对线性模型影响:
- 回归模型缺乏稳定性。样本的微小扰动都可能带来参数很大的变化;
- 难以区分每个解释变量的单独影响;
- 参数的方差增大;
- 变量的显著性检验失去意义;
- 影响模型的泛化误差。
二、多重共线性出现的原因
1、样本量不足。 (在某些情况下,收集更多数据可以解决共线性问题)
2、错误地使用虚拟变量。(比如,同时将男、女两个虚拟变量都放入模型,此时必定出现共线性,称为完全共线性)
3、自变量都享有共同的时间趋势
4、一个自变量是另一个的滞后,二者往往遵循一个趋势
5、由于数据收集的基础不够宽,某些自变量可能会一起变动
三、多重共线性的判别方法
1、VIF值(方差扩大因子)
VIF值代表多重共线性严重程度,用于检验模型是否呈现共线性,即解释变量间存在高度相关的关系(VIF大于10,严格为5)。若VIF出现inf,则说明VIF值无穷大,建议检查共线性。
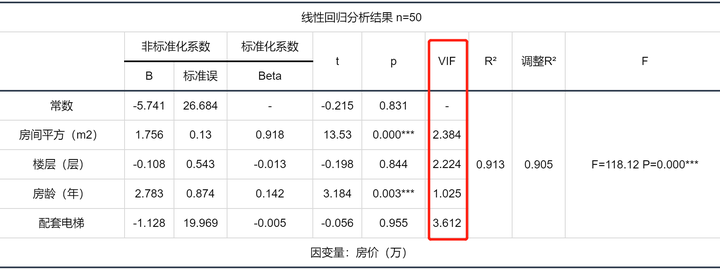
2、容差值
容差值=1/VIF ,所以容差值大于 0.1 则说明没有共线性(严格是大于 0.2 ),VIF和容差值有逻辑对应关系,两个指标 任选其一 即可。
3、相关分析
直接对自变量进行 相关分析 ,查看 相关系数和显著性 也是一种判断方法。如果一个自变量和其他自变量之间的相关系数显著,则代表可能存在多重共线性问题;但相关系数低,并不能表示不存在多重共线性
四、对共线性变量的处理
1、删除不重要的自变量
自变量之间存在共线性,说明自变量所提供的信息是重叠的,可以删除不重要的自变量减少重复信息,理由是增加模型稳定性。如果是完全共线性的当然是需要删除的,但现实中其实特征变量之间并不是完全共线性的,所以删除有可能会导致预测的信息源减少而导致预测能力下降,其实删除只是一种处理方法,当比如 A、B两个特征共线性,那么到底选择删除哪一个也有一些方法,比如通过启发式逐个把特征加入模型看模型效果。
2、增加样本量
多重共线性问题的实质是样本信息的不充分而导致模型参数的不能精确估计,因此追加样本信息是解决该问题的一条有效途径。但是,由于资料收集及调查的困难,要追加样本信息在实践中有时并不容易。
3、岭回归
如果实际研究中不想剔除掉某些自变量,可以考虑使用 岭回归 。 岭回归 是当前解决共线性问题最有效的解释办法。
岭回归是一种专用于共线性数据分析的有偏估计回归方法,实质上是一种改良的最小二乘估计法,通过放弃最小二乘法的无偏性,以损失部分信息、降低精度为代价获得回归系数更为符合实际、更可靠的回归方法,对病态数据的拟合要强于最小二乘法
4、 逐步回归法(此法最常用的,也最有效)
是一种常用的消除多重共线性、选取“最优”回归方程的方法。其做法是将逐个引入自变量,引入的条件是该自变量经F检验是显著的,每引入一个自变量后,对已选入的变量进行逐个检验,如果原来引入的变量由于后面变量的引入而变得不再显著,那么就将其剔除。引入一个变量或从回归方程中剔除一个变量,为逐步回归的一步,每一步都要进行F 检验,以确保每次引入新变量之前回归方程中只包含显著的变量。这个过程反复进行,直到既没有不显著的自变量选入回归方程,也没有显著自变量从回归方程中剔除为止。
5、主成分回归
主成分分析法作为多元统计分析的一种常用方法在处理多变量问题时具有其一定的优越性,其 降维 的优势是明显的,主成分回归方法对于一般的多重共线性问题还是适用的,尤其是对共线性较强的变量之间。当采取主成分提取了新的变量后,往往这些变量间的组内差异小而组间差异大,起到了消除共线性的问题。
发布于 2022-06-17 15:42
・IP 属地广东