


千万奖金大赛,大湾区《路测3D检测》冠亚军技术方案分享

路侧3D感知赛题
大赛介绍
粤港澳大湾区国际算法算例大赛首页:
http://
106.75.138.120/
赛题官网
https://www.
cvmart.net/race/10350/b
ase
“路测3D检测”赛题AB榜排行榜链接:
https://www.
cvmart.net/race/10350/r
ank
冠亚军技术方案分享
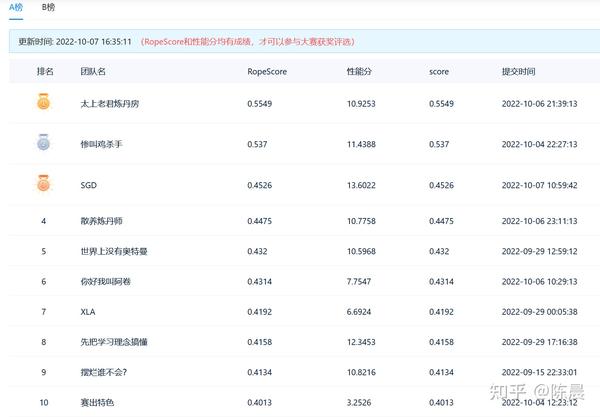
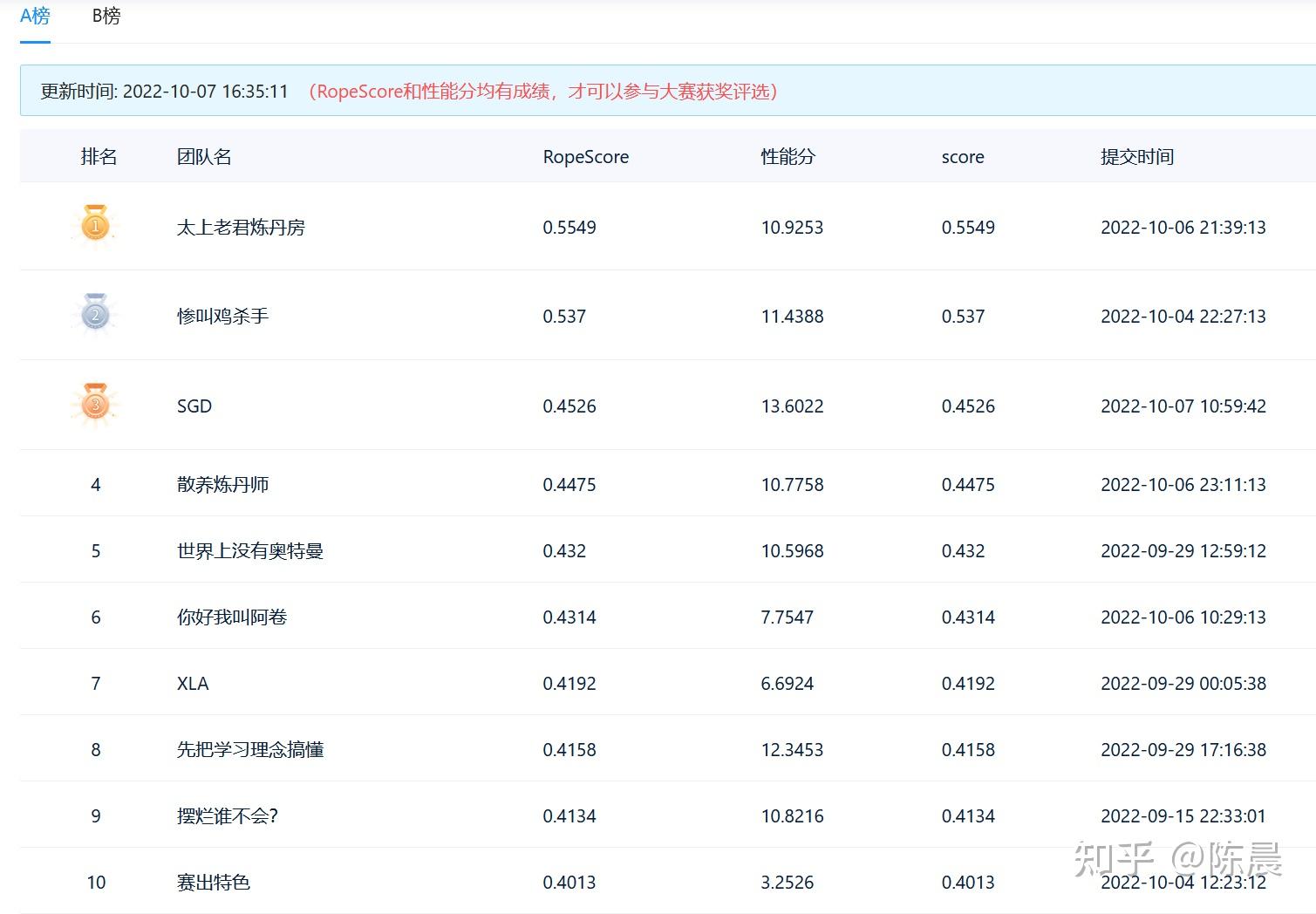
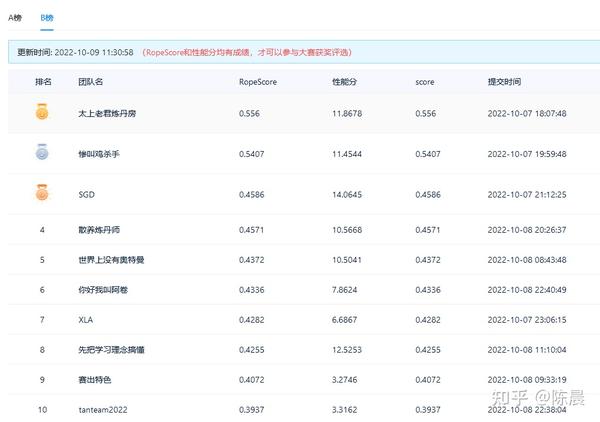
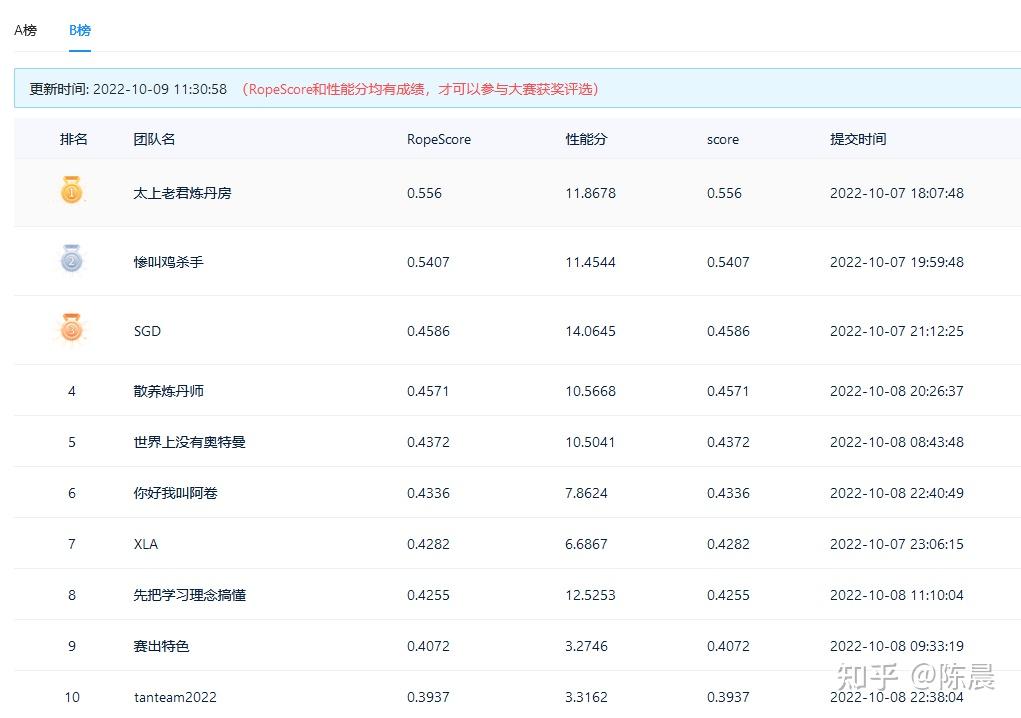
首先明确,我们派出的【太上老君炼丹房】【惨叫鸡杀手队伍】两套方案完全不同,一个是基于改进版YOLO7五个head的anchor base 方案, 一个是基于改进版monodle34的anchor free方案,这两套方案以几乎碾压的成绩夺取初赛冠亚军,拉开第三名10个点,如下图,且两套方案完全能复现,这两套3D检测方案,在2D和3D目标检测领域极具学习参考价值,现拿出来与大家分享,等官方给出合理说法公平解决后,我们会将代码方案进行开源。
由于初赛冠亚军被坐庄选手团队举报,又被主办方取消成绩无法进入决赛。我们经过调查取证挖出惊人内幕,劲爆黑幕链接如下:
冠军:太上老君队伍技术分享
Step1:赛题解读
官网赛题描述:
https://www.
cvmart.net/race/10350/d
es
数据集:为repo3D数据集
https://www.
cvmart.net/race/10350/d
ataset
(官网展示不可下载)
https://
thudair.baai.ac.cn/logi
n
(可下载)
赛题任务:预测道路目标3Dbox, 标注类别有9类,需要对应合并预测为4类(小车、大车、行人、非机动车)如下图所示


Step2:数据集分析
repo3D数据集目录结构


repo3D的label字段


Step3:数据预处理
首先拿到数据后先对标签进行转换,把所有相机坐标系下的label转换成像素坐标系下,所有的训练都是在像素坐标系下进行迭代
世界坐标系,相机坐标系,图像坐标系,像素坐标系之间的转换关系如下:
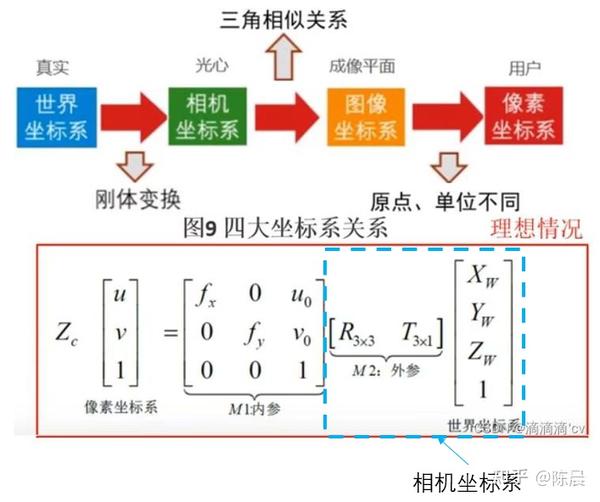
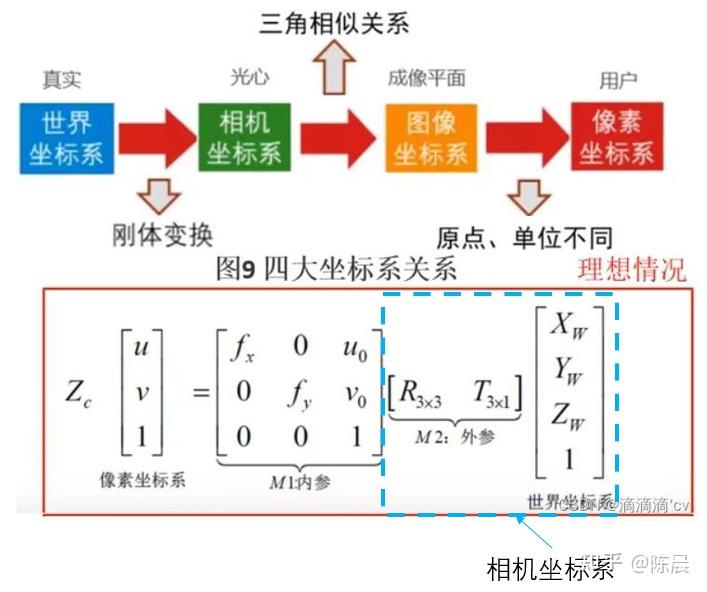
此外在可视化数据的时候,发现数据集中世界坐标系的Z轴,居然方向有的向上有的向下
可能原因:部分相机对应的世界坐标系的Z轴方向不一致,如图所示


解决办法:
1、先根据内外参矩阵计算出像素坐标系下的几何中心
2、判断像素坐标系下的地面中心和几何中心的大小,如果地面中心y值小于几何中心y值,则进行翻转操作
可视化数据分析时,还发现原始的yolov7 三个头的anchor 并不能完全覆盖,数据种的超大目标车辆,于是对网络进行改进从原来的下采样64倍,改进为128倍,并且输出head从原来的3个改为5个,具体的细节见step5网络模型。
最终dataset 处理后返回的内容如下:
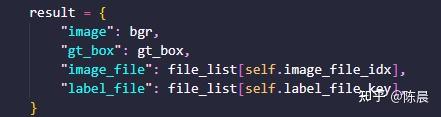
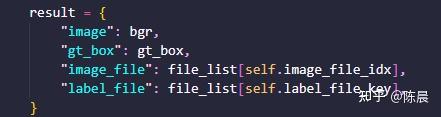
Step4:数据增强
太上老君队伍,最初的方案也是引入的mosaic 增强,最后发现效果并不好,经过实验发现进行中心点偏移反而效果更好,且不再需要分两个阶段训练, 具体如下:


Step5:网络模型
太上老君炼丹房 方案的网络结构如下,基础模块例如Focus模块ELANBlock模块 sppcspc模块,upconvblock可参考yolo7开源代码,整体网络图如下,每一层我们都增加了详细的shape信息,相信算法工程师,根据下图结构基本上可以完成网络复现。
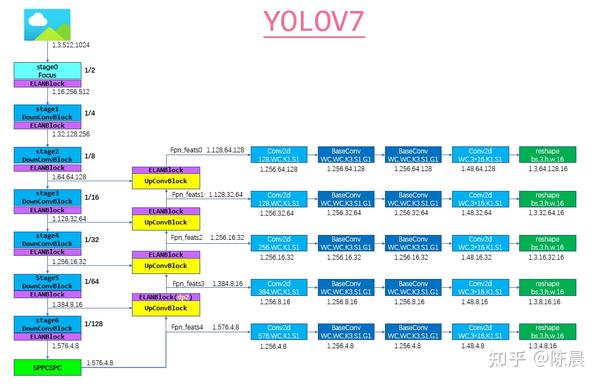
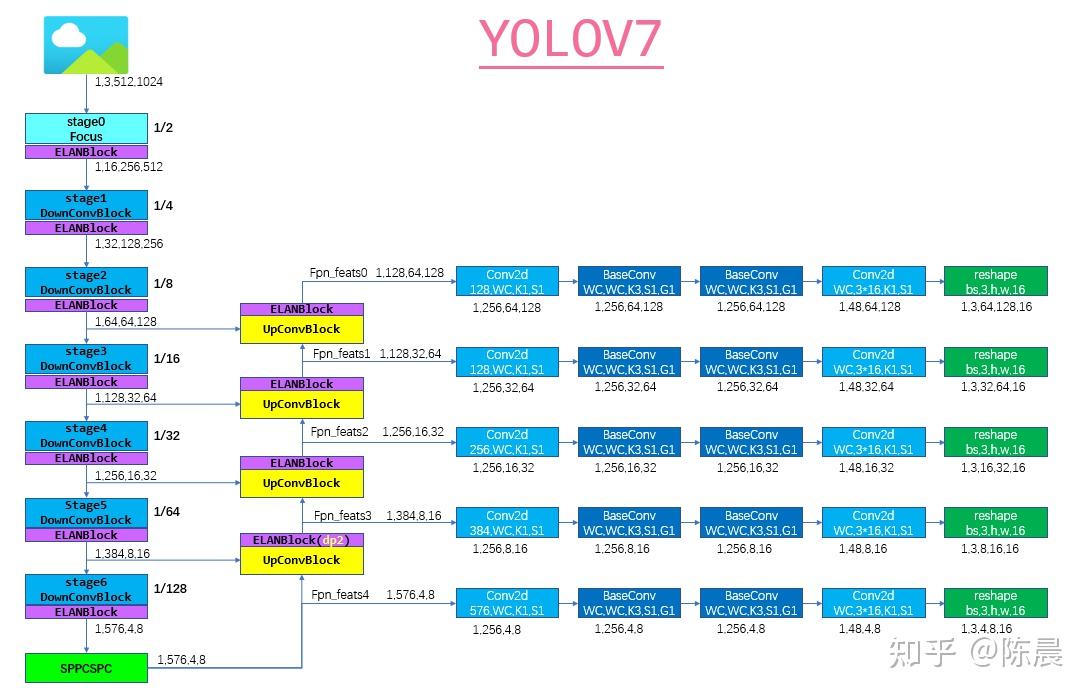
下面是网络核心模块
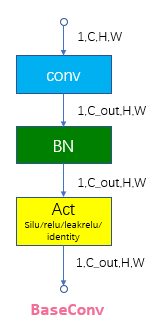
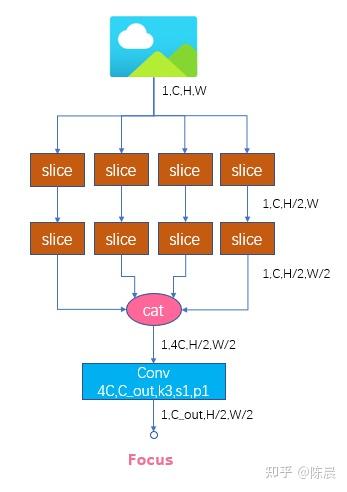
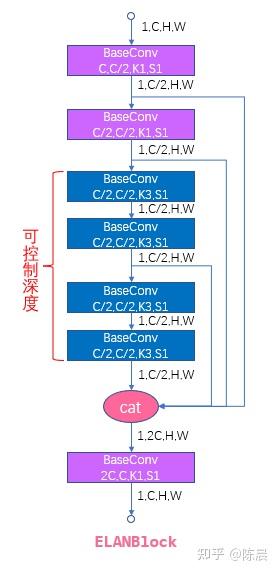
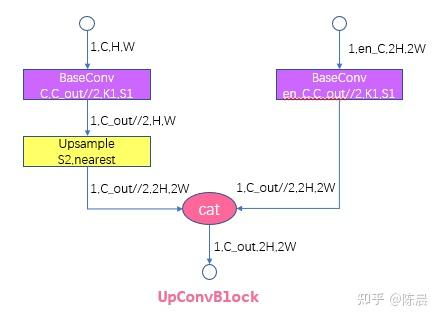
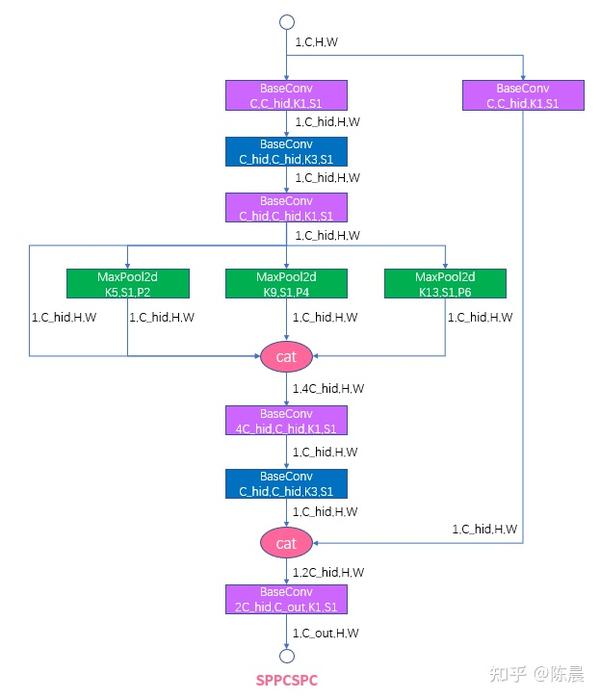
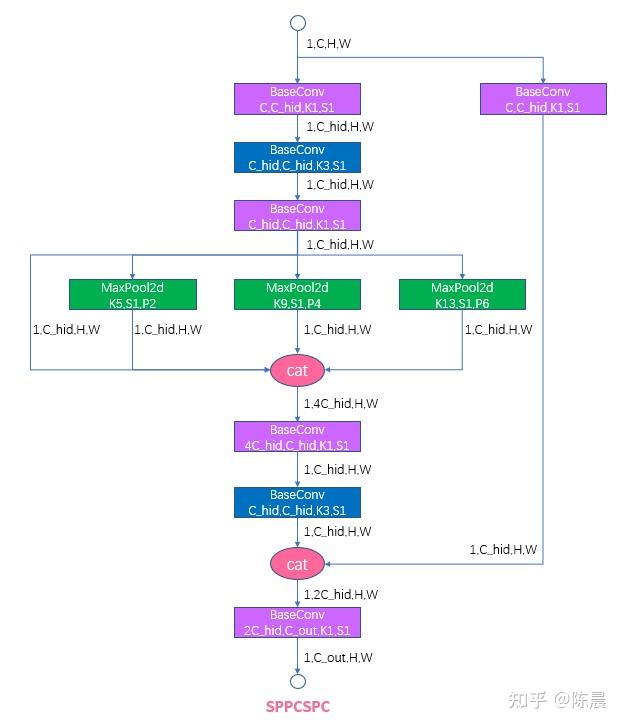
为什么我们要设计为5个head?
最初的方案,我们是使用的3个head 进行实验发现,大车的AP总是很低,分析后发现有些图片大车图片甚至占据了1/2的图片面积,而64倍下采样的感受和配上3个head的anchor 存在局限,导致对超大目标检测不好,于是我们修改网络继续加深到128倍下采样,并且head 我们从原来的3个头增加到5个如下:
Step6:损失设计
Yolo7多尺度损失采用如下方案:
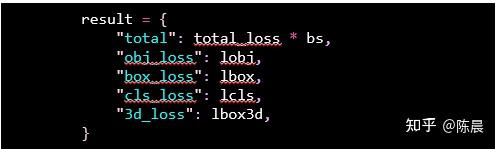
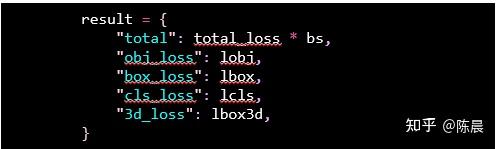
Total 是总损失和
obj_loss 使用 nn.BCEWithLogitsLoss
box_loss 使用
CIoU
cls_loss 使用 nn.BCEWithLogitsLoss
3d_loss 使用 F.smooth_l1_loss
此外我们在每个head处增加了权重平衡
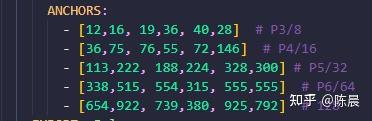
BALANCE: [2.0, 1.5, 1.0, 0.95, 0.85 ] 每层anchor objectness 每个head的目标权重
WEIGHT: [ 0.5, 0.7, 0.75, 0.065] 分别对应lbox, lobj, lcls, lbox3d的损失权重
损失的不同能很大程度上反映出方案的区别,可以与惨叫鸡的损失方案对比,这两个方案的建模方式是完全不一样的。
Step7:训练策略


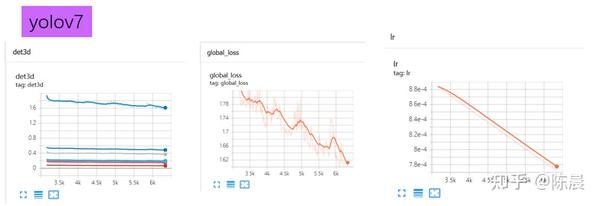
训练过程中的损失曲线如下
亚军:惨叫鸡杀手队伍技术分享
Step1:赛题解读
见太上老君方案,是对赛题的介绍,不做重复
Step2:数据集分析
见太上老君方案,是对数据集的介绍,不做重复
Step3:数据预处理
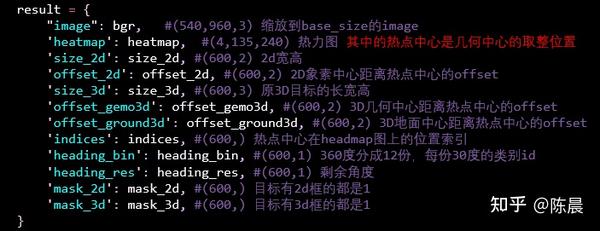
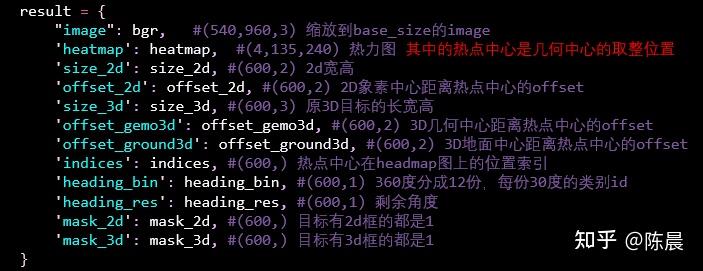
惨叫鸡队伍的方案需要多labels进行重生成,我们在dataset中进行转换实现,也用到了坐标系转换,具体可参考上文太上老君数据预处理内容。最后dataset 迭代返回的结果如下:
Step4:数据增强
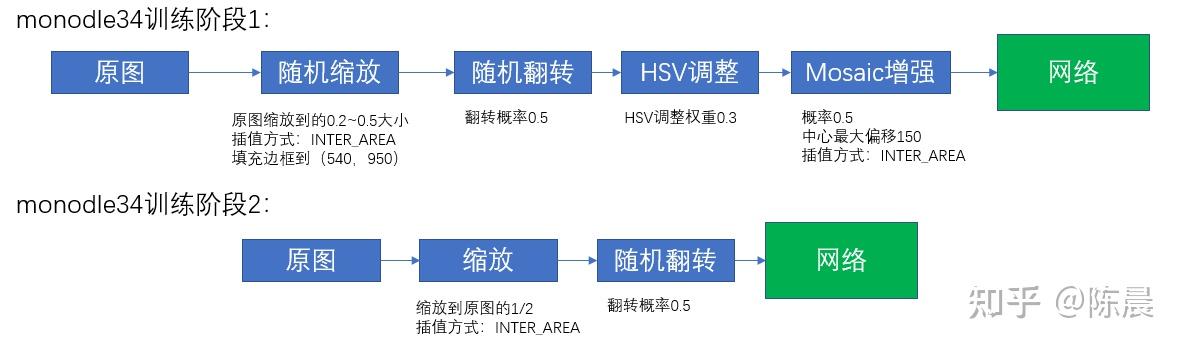
惨叫鸡数据增强部分如下图所示,由于我们的训练分为两个阶段,每个阶段的增强方式不同,第一个阶段引入了mosaic增强,这样经过时间就算是训练到了60个epoch 还能继续出现长点,避免过拟合。


第二个阶段我们又去掉了mosaic增强进行finetuning


Step5:网络模型
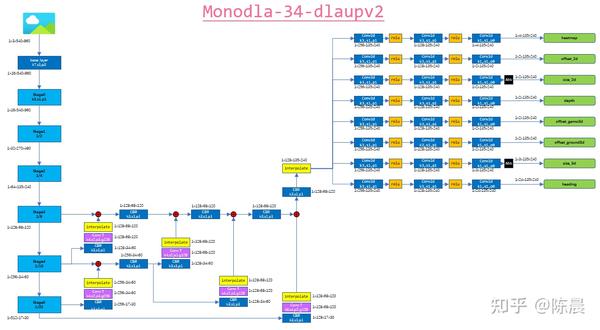
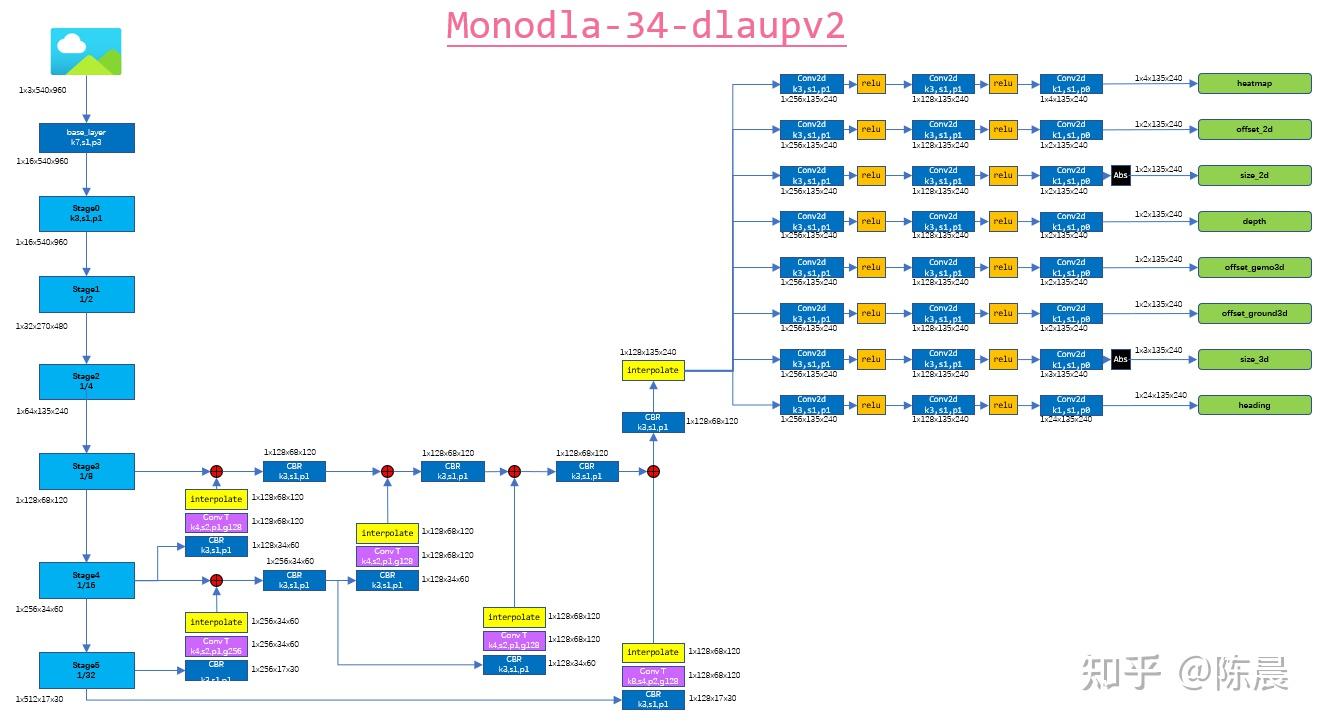
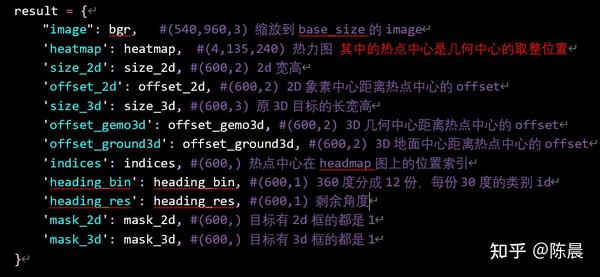
惨叫鸡杀手 使用的是monodla34 anchor free的方案,网络结构如下,每一层我们都增加了详细的shape信息,方便大家复现,backbone部分进行32倍下采样,然后neck部分待用复杂的dlaupv2的融合方式,进行充分融合,然后再上采样到输入图片的1/4大小送给head, head 部分根据建模设计了8个head,分别对应下图的result结果。

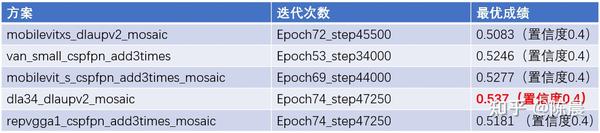
其实惨叫鸡队伍,先后进行了五套方案的实验,如下图所示,全部的方案得分都在0.50分以上,依然拉开第三名至少5个点左右的差距。
五套方案head没有变,修改了网络的backbone 和neck,我们尝试了基于transformer 的mobilevit的两个方案, 还尝试了重参数化思想的repvgg网络,又尝试了超越ConvNeXt和transformer的VAN(visual Attention Network)这些backbone 都是当下非常热门和sota的backbone,
此外neck部分我们也做了不同的尝试,改进cspfpn进行上采样三次融合,最终实验得出dla34_dlaupv2反而是最好的方案,我们做了思考,为什么transformer没发挥出效果,主要原因可能是极市平台的GPU太差,显存非常小,限制了batchsize,一个bachsize只能4个样本,虽然我们使用了梯度累计的方案,但是transformer 仍无法发挥出来潜力。
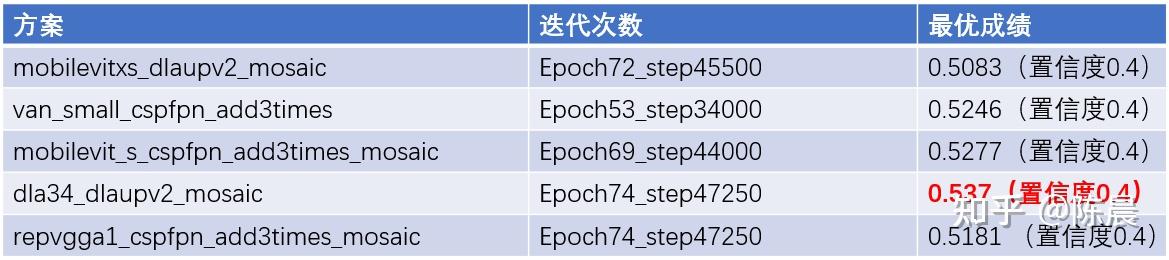
下图是五套方案的训练历史,由于极市平台的算力非常差,所以训练完一个方案至少需要8天时间. 而我们付出了如此的努力且没有任何违规的情况下主办方,恶意取消我们的成绩,给出的理由极其荒谬。


Step6:损失设计
Monodle34 anchor free 方案的损失如下
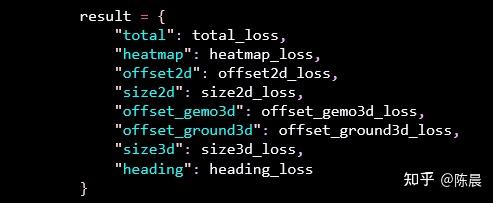
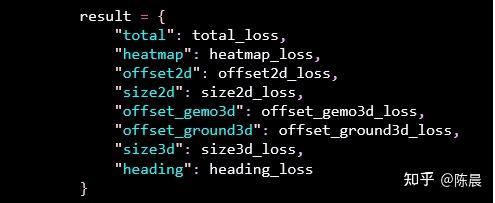
Total 是总损失和
Heatmap 使用 Negloss
Offset_2d 使用 L1loss
Size_2d 使用 L1loss
offset_gemo3d 使用L1loss
offset_ground3d使用L1loss
size_3d 使用 AwareL1loss (使用了加权更均衡一些)
Heading 使用(分类损失CE + 回归损失L1loss)
损失的不同能能很大程度上反映出方案的区别,可以看出惨叫鸡与太上老君的建模方式是完全不一样的
Step7:训练策略
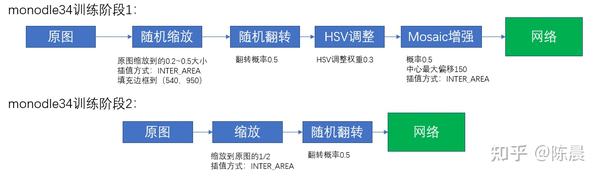
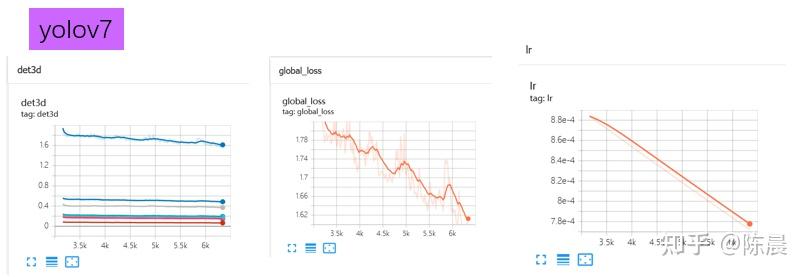
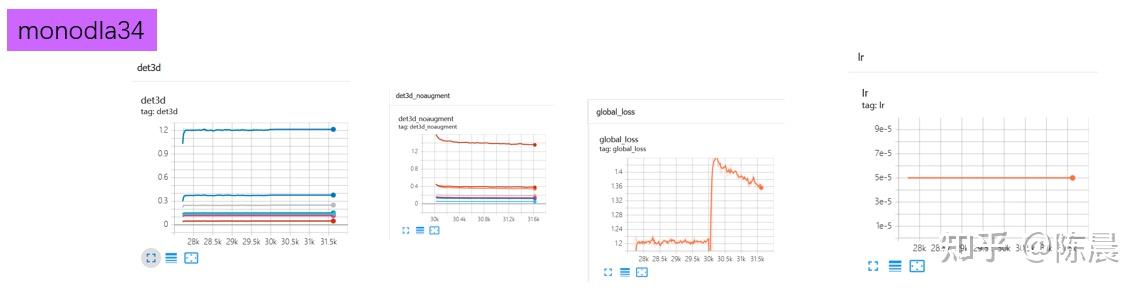
训练过程中的损失曲线如下,可以发现global loss突然上升了,这是因为自动进入到了训练阶段2,撤掉了mosaic数据增强,训练的数据突然有了较大的变化,loss进行了跳变,这是正常现象。

总结
希望以上两种方案能给算法工程师们带来些启发,关注大赛内幕请看下面链接。请持续关注文章,代码即将开源!
