

MySQL实战-基础篇(架构/日志/事务)

一、基础架构
1、简介:MySQL=Server层+存储引擎
(1) Server层 :连接器+查询缓存+分析器+优化器+执行器。涵盖大多数核心服务功能、所有内置函数(日期/时间/数学/加密函数)、所有跨存储引擎的功能(存储过程/触发器/视图)。
(2) 存储引擎 :插件式,支持InnoDB、MyISAM和Memory等。负责数据的存储和提取。从MySQL5.5.5版本开始,默认引擎是InnoDB。用户可以在create table时,使用engine=memory指定使用Memory引擎。 多个存储引擎共有一个Server层 。
2、详解:一条SQL查询语句的流程
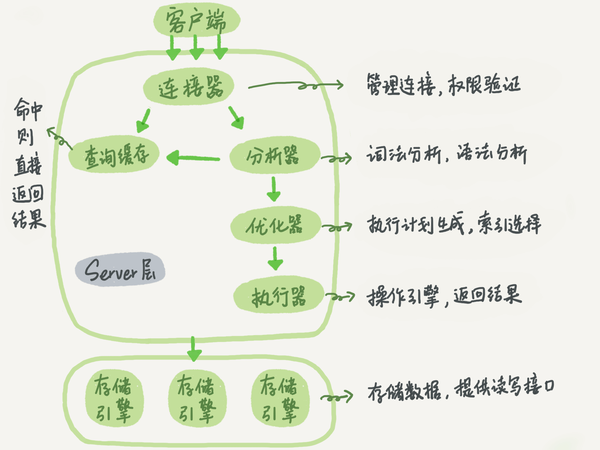
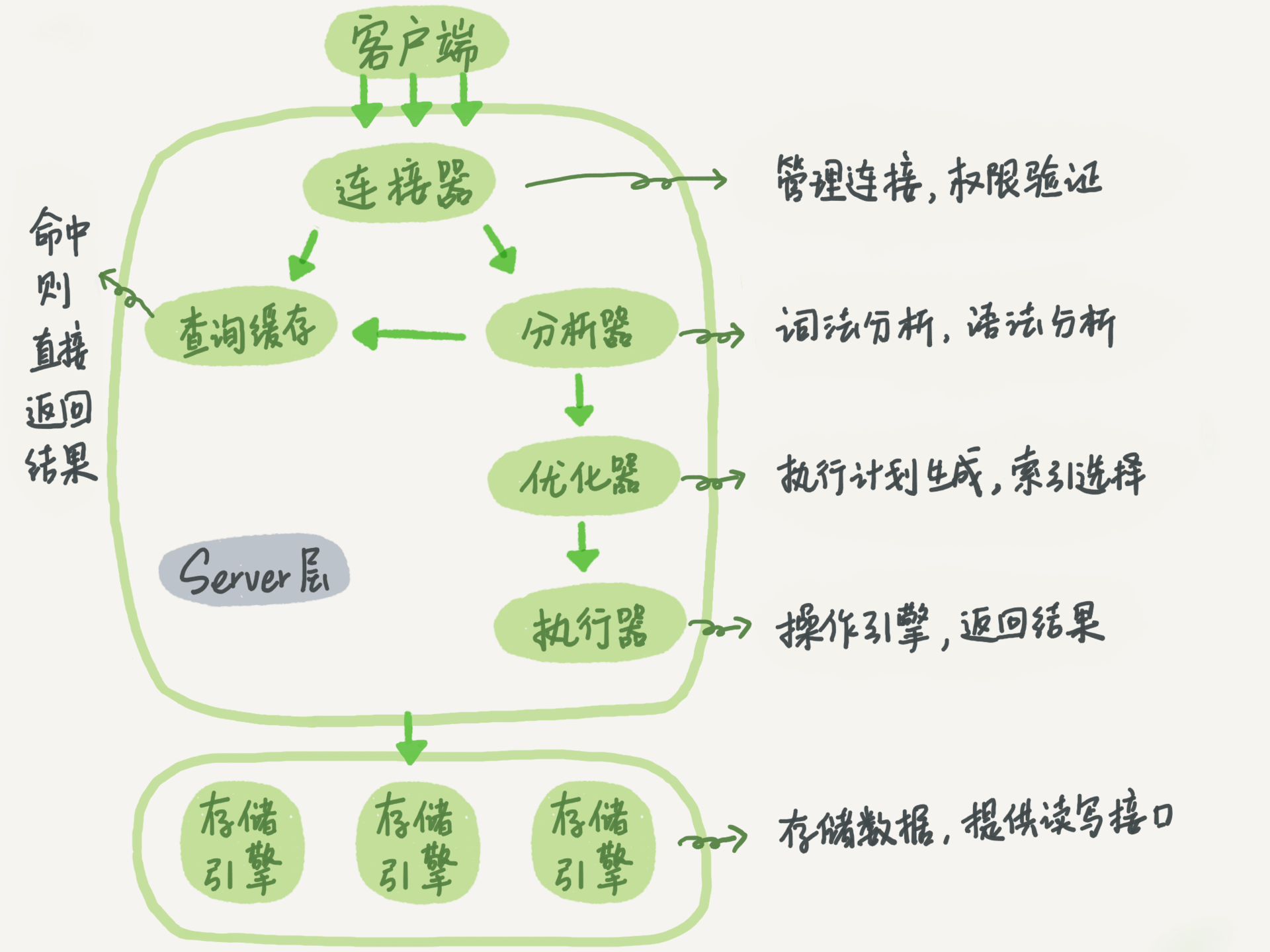
(1)连接器
负责跟客户端建立连接、获取权限、维持和管理连接。 当在mysql -h -u -p输入账号密码后,连接器开始对用户身份鉴权。当认证通过,连接器会读取权限表授权,连接上的权限就固定了。后期只要连接不断,权限就不变,除非建立新的连接。
当连接建立后,可以使用show processlist查询。Command=Sleep表示一个空闲连接,当空闲时间太长,连接器会主动断开,默认为8小时,由参数wait_timeout控制。当客户端在一条已经断开的连接上查询时,会收到Lost connection的MySQL错误,需要主动重连。
SQL执行过程中使用的内存管理在连接对象中,只有当连接释放后内存才会释放。因此当连接数过多时,MySQL占用内存太大,OOM后异常重启。为了解决该问题,有2种解决方案:定期断开长链接/大查询后主动断开连接、使用mysql_reset_connection重置连接资源,该过程不需要重连。
(2)查询缓存
建立连接后,开始执行select查询。当MySQL拿到一个查询请求后,会首先检查最近是否执行过该语句,如果k-v缓存命中,将直接返回缓存结果。其中,key是查询语句,value是查询结果。
当业务使用较多的静态表时,查询缓存效率很高。但如果在查询表的同时还会不断的有更新操作,查询缓存命中率极低,因为只要对表有任何更新,这张表上的所有查询缓存都将被清空。正因为如此,MySQL 8.0版本将该功能全部删除。
(3)分析器
如果没有命中缓存,MySQL需要对SQL语句进行词法分析和语法分析。 包括,识别关键词、判断语法生成一颗解析树。同时,MySQL还会进一步检查解析树的合法性,比如判断表是否存在,列是否存在等。当语句存在任何错误时,提示会出现在第一个错误位置。
(4)优化器
如果语法正确,MySQL会确定语句的执行方案。 包括,当表中有多个索引时,决定使用哪个索引;语句需要连表时,决定表的连接顺序。当出现逻辑结果相同的执行方案时,因为执行效率不同,优化器会选择“它认为最优”的方案。
(5)执行器
执行方案确定后,MySQL开始执行语句。 包括,判断对表的权限判断、根据表的存储引擎类型,使用它提供的接口完成查询。
权限判断在执行阶段的原因是,SQL语句要操作的表不只是字面上的那些,经常需要在执行过程中才能确定,比如触发器。
引擎接口查询是(以select * from T where ID=10为例)。 如果ID字段没有索引 ,执行器首先调用接口“取表T的第一行“并判断ID是否等于10,接着调用“取下一行”重复判断逻辑直至最后一行,最后将满足条件的结果返回客户端。如果ID字段有索引,调用的接口是“取满足条件的第一行”和“取满足条件的下一行”。
在数据库的慢查询日志中,有一个 rows_examined字段 ,表示一条SQL语句在执行过程中扫描的行数, 该值是执行器每次调用引擎接口获取的数据行累加的 。因为执行器调用接口获取一行数据时,rows_examined+1,但引擎内部可能扫描了多行,所以 引擎扫描行数和rows_examined并不完全相同 。
二、日志系统:一条SQL更新语句的流程
MySQL更新流程与查询流程类似,但它还涉及到2个MySQL的核心概念,即redo log和binlog。为了解决MySQL更新语句的效率问题,避免每条语句都要先“读取磁盘文件->找到数据记录->更新磁盘文件“,在设计上使用WAL(Write-Ahead Logging)技术,即先写日志(记上一笔操作),再写磁盘(找到并更新磁盘文件)。
1、区别
(1)redo log是InnoDB引擎特有的,支持crash-safe,而binlog是Server层实现的,所有引擎都可以使用,只有归档能力;
(2)redo log是物理日志,记录的是“对某个数据页的具体修改”,binlog是逻辑日志,记录的是一条更新语句的原始逻辑,比如SQL语句本身;
(3)redo log是循环写,空间固定会用完,binlog是追加写,会不断的切换新的日志文件,不会覆盖。
2、redo log
redo log是存储引擎InnoDB特有的日志 。在一条记录需要更新时,InnoDB会将记录先写到redo log,接着更新内存,最后再在 合适的时机 将操作记录更新到磁盘。其中,“合适的时机”包括MySQL空闲和redo log被写满。前者很容易理解,后者是因为InnoDB的redo log是固定大小的,比如配置一组4个文件,每个文件的大小是1GB,那么4个redo log文件构成一个环,总共记录4GB的操作。
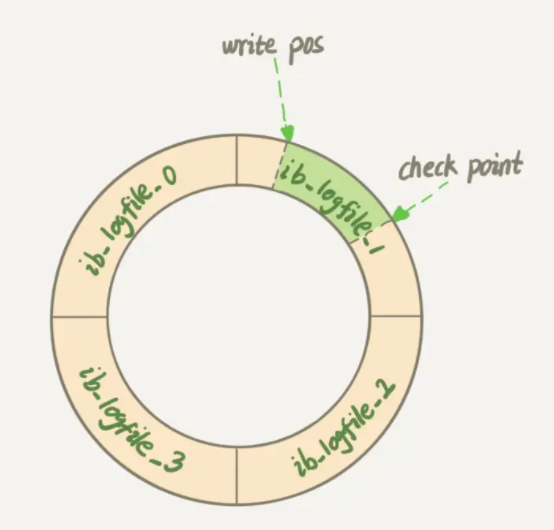
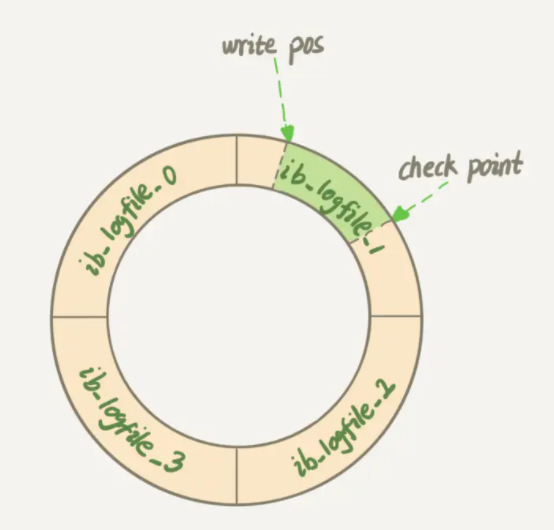
check point和write pos类似循环队列中的head和tail。向write pos处不断写入数据,当与check point相遇时,表示redo log被写满,需要把check point推进一下并写入磁盘文件。即,write pos和check point中间的位置就表示用来记录新操作的空闲位置。
因为redo log也已经被持久化到磁盘,即使MySQL发生异常重启,之前提交的记录也不会丢失,即 crash-safe 。
在具体实现中,redo log记录的是数据页的改动,并不是数据页本身。因此,正常运行的实例在内存中的数据页被修改后,跟磁盘上的同一页不一致,被称作“脏页”。当最终数据落盘时,“脏页”落盘,与redo log无关。但在崩溃恢复的场景中,“脏页丢失”后,InnoDB将磁盘数据再入内存,再使用redo log更新内存内容,复原“脏页”。
当一个事务包含多条更新语句时,在更新数据的过程中,redo log都需要存储,但在事务commit前又不能写到磁盘redo log文件中。此时,需要一块redo log buffer,专门缓存redo log,直至事务执行commit语句。
3、binlog
(1)归档能力
binlog的归档能力,即误操作后的恢复能力。如果以“让MySQL可以恢复到半个月内任意一秒的状态”为目标。 首先需要至少半个月一次的做定期整库备份 ,具体频率取决于业务的重要性(天/周/半月)。其次, 保存至少半个月内完整的binlog数据 。
因此,如果误删数据后,不用先急着跑路:
①先找到最近一次的全量备份恢复到临时库;
②再定位到该备份最后时间点时binlog的具体位置;
③在临时库上重放所有binlog至误删操作前的时刻;
④按需将误删的数据恢复至线上库。
(2)两阶段提交流程
一条更新语句,主要包含6个步骤:
①执行器调用引擎接口获取数据行;
②引擎查缓存或加载磁盘文件,返回数据;
③执行器拿到数据,执行更新语句,调用引擎接口写入新数据;
④引擎更新内存数据,记录redo log,告知执行器执行成功,随时可以提交事务。此时 redo log处于prepare状态 ;
⑤执行器收到引擎返回, 生成该操作的binlog并写入磁盘 ;
⑥执行器调用引擎的提交事务接口,引擎 将redo log置为commit状态 ,更新完成。
(3)反证两阶段必要性
因为redo log和binlog是独立的逻辑。如果不用两阶段提交,一条更新语句可能存在2种情况:
① 先写完redo log后写binlog :若写完redo log后崩溃,重启后因为redo log的crash-safe,本次数据完成更新。但binlog丢失,利用定期备份+binlog恢复的临时库将 丢失 这次更新。临时库与原库数据不一致。
② 先写binlog后写redo log :若写完binlog后崩溃,因为redo log丢失,重启后本次更新无效。但binlog已归档,利用定期备份+binlog恢复的临时库将 多出 这次更新。临时库与原库数据不一致。
因为现实生活中不仅仅是误删数据才需要利用binlog恢复临时库,在搭建备库增加系统读能力的扩容时,同样需要利用binlog重建临时库,此时上述的2点不一致也将造成线上主从数据库的不一致。
(4)正证两阶段正确性
①redo log prepare前崩溃:未发生任何写,重启后无影响。
②redo log prepare后,binlog写入前崩溃:redo log prepare完整,但binlog未写,重启后无影响。
③binlog写后,redo log commit前崩溃:redo log prepare完整, 若binlog也完整 ,重启后将直接提交事务。否则,回滚事务。
④redo log commit后崩溃:两阶段写成功,重启后无影响。
(5)正确性的补充要点
①redo log和binlog通过共有的XID字段关联。崩溃恢复时,如果redo log commit完成直接提交。如果redo log只有prepare,就用redo log XID去验证同一XID binlog的完整性。
②如果binlog是statement格式,最后会有commit标识。如果是raw格式,最后会有一个XID event。同时,因为落地磁盘的binlog可能会在中间出错,5.6.2版本后新增一个checksum,验证一句日志内容的正确性。
③Server层的binlog写完后,会被从库或备份库使用。因此,只要binlog完整,主库重启后也必须要提交事务,即使redo log尚未commit。
(6)正证两阶段必要性
①redo log先写完,再写binlog:如果redo log写完后崩溃,意味着重启后要回滚已经完成的redo log,可能覆盖掉别的事务的更新,导致数据错误。如果不能回滚,主库更新,从库丢失binlog更新,数据不一致。
②binlog先写完,再写redo log:如果binlog写完后崩溃,主库丢失更新,从库同步binlog更新,数据不一致。
③只写binlog:即,更新内存->写binlog->提交事务,但因为 binlog没有能力恢复数据页 ,原理上也不支持崩溃恢复。比如,连续执行update c+1两次,且在第2次执行时写完binlog后,提交事务前崩溃。若此时数据未刷盘,内存丢失。重启后,因为第1次是已完成事务,只有未完成的第2次update c+1会被主库重放,但从库却同步了2条binlog,导致数据不一致。
④只写redo log:即,关掉binlog。redo log是循环写,不能进行历史数据归档和基于归档数据的上层应用。
4、参数
(1)Innodb_flush_log_at_trx_commit=1: 每次事务的redo log都直接持久化到磁盘。建议设置为1,保证MySQL异常重启后数据不丢失。
(2)sync_binlog=1: 每次事务的binlog都直接持久化到磁盘。建议设置为1,保证MySQL异常重启后binlog不丢失。
三、事务隔离
MySQL的事务是在存储引擎层面支持的,并不是所有引擎都支持事务,比如MyISAM。所以,支持事务的InnoDB取代MyISAM就是必然趋势。
1、隔离性与隔离级别
“隔离性”是数据库ACID中的I,当多个事务同时执行时,可能会出现脏读、不可重复读、幻读等问题,因此又延伸出“隔离级别”的概念。但是,隔离级别越高,数据库效率越低,通常业务还需要找到一个适合的平衡点。SQL标准的事务隔离级别包括:
(1)读未提交:一个事务还未提交,它做的变更就能被其他事务看到。(事务)
(2)读提交:一个事务提交后,它做的变更才能被其他事务看到。
(3)可重复度:一个事务在执行过程中看到的数据,总是跟启动时看到的数据时一致的。简单但不严格地说,即使别的数据有更新提交,在该事务进行过程中,读到的也是跟启动时相同的数据。
(4)串行化:顾名思义。对同一行数据,写加写锁,读加读锁。读写冲突时,只能等待锁释放。
2、举例说明


(1)读未提交:虽然事务B的更新尚未提交,但事务A的V1=V2=V3=2。
(2)读提交:事务B的更新在提交后才能被A看到,因此V1=2,V2=V3=2。
(3)可重复读:事务A在执行期间,看到的数据应该是前后一致的,而与事务B是否有已提交的更新无关。所以V1=V2=1,V3=2。
(4)串行化:事务A首先开启读事务,当事务B要执行更新操作时,锁冲突等待A提交。之后,事务A的V3会等待事务B提交。因此V1=V2=1,V3=2。
事实上,数据库通过创建“视图”的方式来实现“隔离级别” 。数据访问时以“视图”中看到的数据为准,尽量减少锁冲突。比如,“可重复读”在事务启动时创建视图,整个事务期间共有同一视图。“读已提交“是在每个SQL语句开始执行时创建视图,“读未提交”不会创建任何视图,都以最新数据为准。而“串行化”则之间使用锁来避免并发访问。
不同的数据库使用不同的默认隔离级别,比如Oracle使用“读提交”,MySQL使用“可重复读”。因此,从Oracle迁移至MySQL的应用要修改“transaction-isolation”参数为READ_COMMITTED。
3、事务隔离的实现
以“可重复读”为例,每条记录在更新时都会记录一条回滚操作。即,当前最新值可以通过回滚操作,得到前一个状态的值。这种行为导致同一条记录在数据库中存在多个版本,也被称作“多版本并发控制(MVCC)”
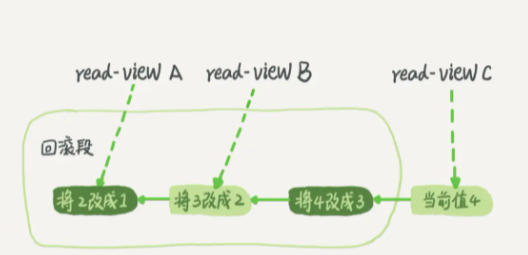
虽然数据当前最新值是4,但不同时刻启动的事务会有不同的“read-view”。对read-view A来说,当它查看数据时,获取的是由最新值4回滚三次后的结果1,即使这时有其他事务正在将A改成5,也不会和read-view A/B/C有任何冲突。
当数据库发现,当前没有任何事务的read-view用到某条回滚日志时,才会将它删除。这就是尽量避免使用“长事务”的原因之一。因为长事务在提交前,必须保留可能用到的回滚日志,占用大量空间。
因为”set autocommit=0”会关闭该线程的自动提交,当执行select语句时,只要不主动执行commit、rollback或断开连接,事务就不会提交,导致意外的长事务。所以,最佳实践建议总是使用“set autocommit=1”和显式begin+commit/rollback的方式启动事务。另外,可以通过information_schema库的innodb_trx表查询长事务。比如:“select * from information_schema.innodb_trx where TIME_TO_SEC(timediff(now(),trx_started))>60”查询持续时间超过60s的事务。
四、参考文章
1,极客时间:MySQL实战45讲 — 林晓斌:(基础篇1-3讲)

