

主流的开源「富文本编辑器」都有什么缺陷?
关注者
628
被浏览
244,805
16 个回答

先占个坑……
联动一下之前我在类似问题的回答
我主要调研过两个,ProseMirror和Slate新版,之所以强调Slate新版是因为它大概47还是57还是多少版本之后就推倒重做了,基本上和原来完全不是一个东西。
首先说下我会注重从定制二次开发方面来评价,而不是开箱即用。
另外我只是对这两个项目进行了调研和写了几千行DEMO,并没有最终完成产品化,所以下面的内容可能具有一定参考价值,也可能完全没有参考价值……
以及,我这个认知还是2020年1月到2月份的,不知道现在(7月)两者有了什么变化,所以我对后续变化而造成的内容谬误概不负责(逃)
下面会从几个我比较关心的方面来对比一下优缺点
schema
ProseMirror是有schema的,所以定义好了schema以后ProseMirror可以替你实现自动化parser,但是对于结构不好的数据,parse过程中可能会丢弃大段的内容,这样以来如果你希望你的编辑器能够支持从别的编辑器里粘贴东西进来还能尽可能保持格式,就会有点头疼。
Slate是无schema的,意味着它实现简单,但容错能力就看二次开发者的normalize以及反序列化的过程下多少功夫了。如果遇到上面那种需要支持粘贴来自别的编辑器的富文本的情况,可以写各种兼容逻辑,只要舍得花功夫,堆代码量,可以有更高的上限。
这块我比较表示中立,因为各有各的好处。
光标系统
我觉得光标系统是富文本编辑器中的核心算法。
ProseMirror使用的是一个整数来“绝对定位”一个光标,它的好处是光标本身的定义是描述元素之间的“缝隙”的,这非常符合直观感受,并且在表示光标的线性移动,比如“向右移动5下”这种场景会很好实现;但是算法实现复杂,在表达“父节点”、“兄弟节点”、“第i个子节点”这些看起来很直观的操作的时候也需要一系列运算。
Slate使用的是path数组+offset来表示光标。基本上优缺点反过来,在实现基于树的变换的时候很直观也很简单,但在线性移动会比较复杂。表示“缝隙”会不那么直观,尤其是需要表示两个相邻顶级元素,比如[0]和[1]之间的“缝隙”的时候,需要一些技巧,导致算法显得不那么“洁癖”。
ProseMirror对于节点的定义比Slate更完整,比如Slate里的void元素竟然还要求返回children,简直搞笑。而ProseMirror里可以良好地定义void,以及所谓isolate。比如两个<td>之间的“缝”是不能容纳光标的,这样的逻辑,ProseMirror可以通过schema定义来描述,而在Slate里就得靠自己去normalize,不然你在Slate的<td>里按一下方向键左,它自己的光标处理逻辑可能就会给你把光标弄<td>之间的“缝”里去。
另一方面,ProseMirror对于选区的定义比Slate来得更加完整,它的“选区”可以是普通的range,也可以是node,也可以是多range(比如现在很多代码编辑器都支持多光标)。而Slate只支持单range,node selection是靠一些技巧与特殊逻辑搞出来的,多range则没有提供,这样一来,Slate是无法准确还原W3C的DOM Selection API的,而ProseMirror可以。
输入层
ProseMirror在这块的代码量远超Slate新版,可以说Slate新版的输入层就是一坨**,截止我脱坑之前(大概2月份吧)它还不能正确处理composition事件族,也就是说你用中文输入法随便一搞它就会crash。ProseMirror虽然我没有严谨的测试它各个平台,但是如果它那些实打实的代码量不是板砖的话,应该至少不会比Slate差。
ProseMirror在输入层的API丰富程度完爆Slate,比如如果你像实现选区不能跨越两个<td>,在ProseMirror里可以直接通过相关的API来阻止事件,而Slate没有,你只能等选区创建完了,再normalize回去,结果就是可能会看到选区闪烁一帧。再结合ProseMirror强大的选区定义,可以实现很多复杂的光标与选区逻辑。比如它作者自己实现的table插件,就实现了异形表格选择的逻辑(虽然大多数人来说这个需求也用不上吧)。
Slate新版由于在内核上大规模重构,感觉输入层基本是个入门水平。
二次开发难度
这个就值得一说了,首先说说对于定制开发富文本编辑器本身
最重要的是光标算法相关,ProseMirror的光标系统设计决定它的算法更复杂,尤其是因为我们平常的理解大多都是“文档 树 ”,而path + offset的光标表达方式是对树结构更友好的。所以要用ProseMirror二次开发一些自定义富文本组件是要经历不少镇痛的。另外ProseMirror的API整体体量比Slate大太多了,甚至可以说Slate简陋,然而要把ProseMirror玩转也是一个长期艰巨的事情……
另一方面是和外部业务系统开发过程的结合。
Slate新版完全拥抱了React,你可以(也只可以)完全用React来开发定制的编辑器,并且可以把React的UI生态赋能到自己的编辑器上,比方说你要做一个超链接的节点,点一下可以弹出一个框来修改它的链接,这时候AntDesign的文本框、按钮什么的,可以很容易整合进你的编辑器UI里面。
但这也有一些缺点,一方面是富文本编辑部分(可以接收光标的部分)和编辑器UI(比如内联的属性编辑框、图片尺寸缩放控制柄这类的不接收光标的部分)是混在你的React代码里的,Slate通过一些奇怪的data-slate-*属性来区分富文本和UI,实际用的时候薛薇有点恶心,需要具体写代码才能有体会;另一方面就是如果你需要基于原生DOM编程(在编辑器这种场景,其实还不少)的时候,因为React拦了一层,就没那么方便了,得到处ref什么的。
ProseMirror则正好相反,用它的时候你是首先基于原生的JS来开发富文本的部分,而如果想加UI,它给你一种叫View的东西,你可以用任何方法去实现view,最后抠一块出来,传一个contentDOM回去作为富文本部分。
这里补充说明一下我说的“富文本编辑部分”和“编辑器UI”
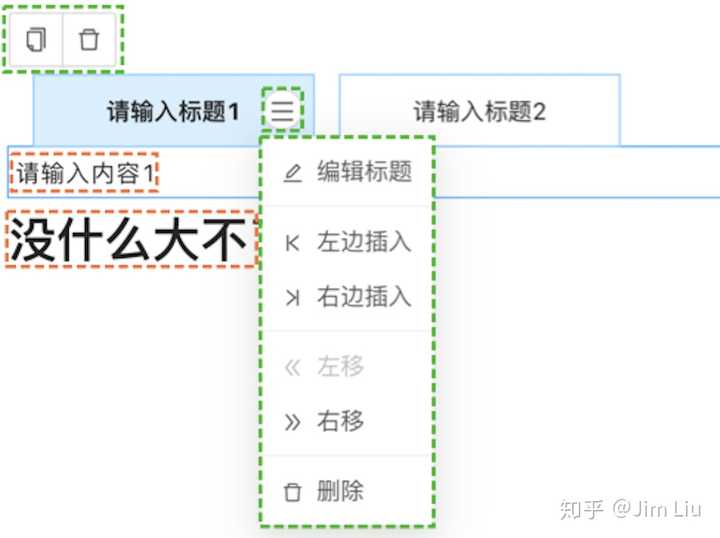
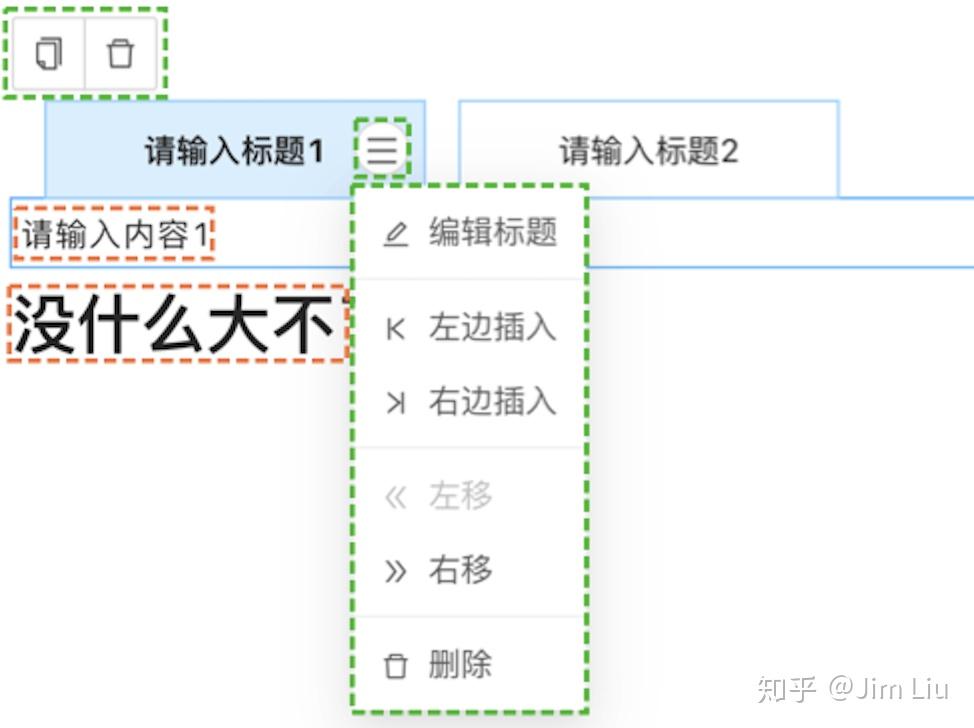
举个例子,上面的图里,是我开发的Tabs组件。橙色线框是“富文本编辑部分”,因为它们可以接收富文本编辑器的光标;绿色线框部分是“编辑器UI”,它们只在编辑模式下出现;而其它那些蓝色的部分是自定义组件的UI,它们会最终输出到文档里,具有一定的可交互行,但在编辑模式下不会接收光标。
我个人是比较赞同ProseMirror这种设计的,因为我的设计目标是最终输出的文档内容需要能不借助视图层框架能运行,那么用原生JS来实现文档内容的那些自定义组件是比较合适的。而对于UI的部分则可以用一些技巧,再去用熟悉的框架比如React/Vue来开发,比如ReactDOM.render或者Vue.$mount啥的。
但是Slate那样做也有好的一面,一方面是集成度更高,可以把整个编辑器完全当作一个React组件来使用,给他传prop,监听它的事件,就完事儿了(当然这是理想情况)。另一方面是可以借助React自身的一些SSR生态更方便地去实现SSR,而SSR对很多文档系统来说都是刚需。

这个问题比较大,我本人以前算是稍微深度的用过 Draft.js,淘宝内容平台的富文本编辑器就是我之前基于 Draft.js 封装的,然后做了一些魔改适应业务需求。我只能简单提一点 Draft.js 相关的经验和见解。
Draft.js 的硬伤在于性能和体验,根源在于它底层的设计和富文本的描述 schema。 它的架构在当时比较新颖,脱离了常用的 contenteditable 的方案,直接按照 React 的模式去做的,是通过拦截光标和键盘等操作,然后更新到内部 immutable 的 state 上面,然后在 render 出来。通过 immutable 来提升渲染性能。
因此可以在富文本编辑器里面可以渲染任意的 React 组件并且进行交互,所以问题里面所说的常见功能表格实现不了是不准确的,实际上你只要设计一个 React 表格组件和表格组件的数据格式,然后当表格数据 change 的时候,调用 Draft.js 的 API 写入到富文本 contentState 里面的 entityMap 里面,然后在渲染段写自定义组件能解析出来就可以实现的。实际上 17 年那会我就见过其他团队基于 Draft.js 开发过支持表格的 Demo,具体忘了哪个团队了。不过这只能说明 Draft.js 跟 React 生态比较贴合,实际体验相比传统实现会差一些。
为什么会差呢?首先是这个富文本协议的描述能力,比如描述一段文字中间有一个链接和内联样式:
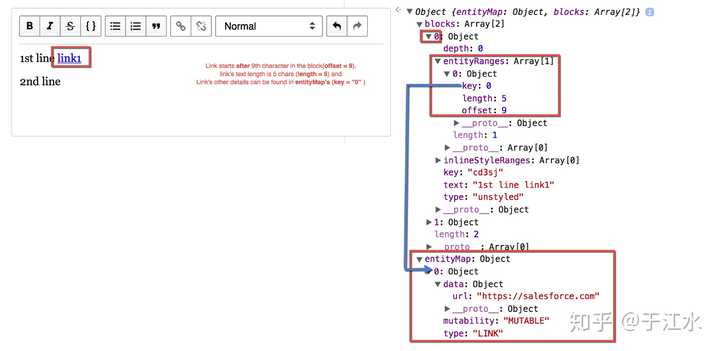
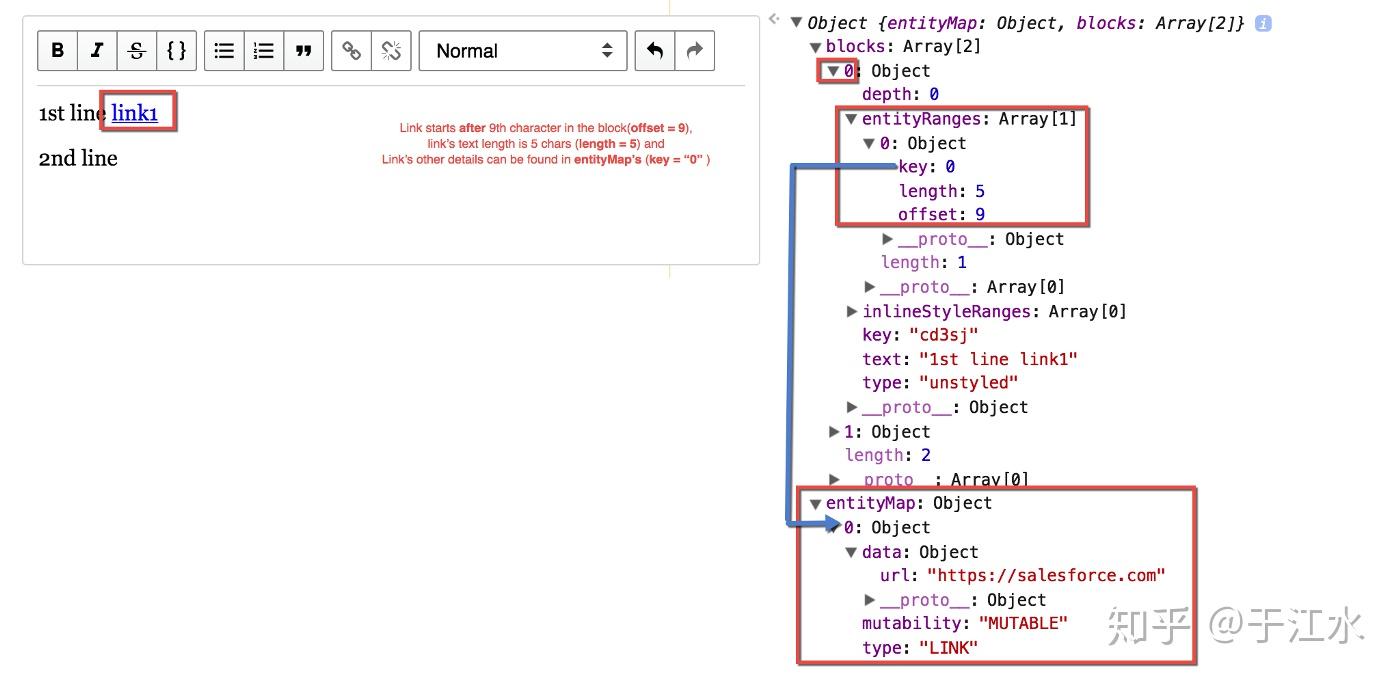
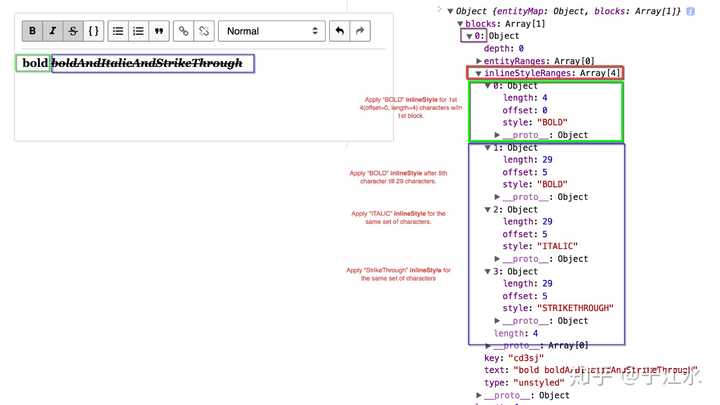
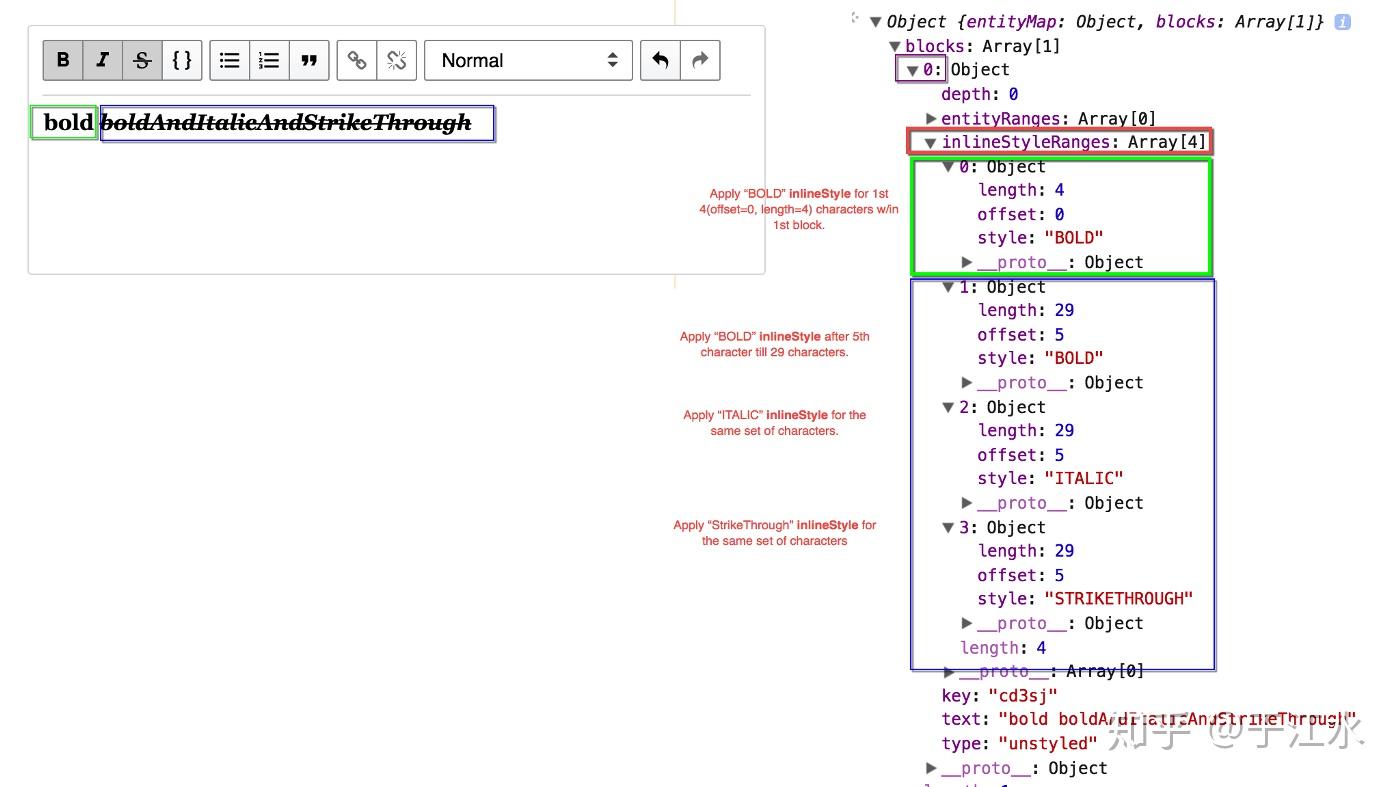
可以看出来,在 Draft.js 里面,每一行都是一个 block,每个 block 都有一个 string 的 text,然后有一个附加的 entityRanges 和 inlineStyleRanges 来对这个文本进行增强,通过 offset 和 length 可以得知对哪几个文字进行增强。比如第一张图的 link 是对第 9 个字符开始,5 个字符长度的文本进行修饰,添加了一个自定义的 object 里面是一个 url,这种 entity 是不能叠加的,但是下图的 inlineStyleRanges 里面的 offset 就是可以相互叠加的,渲染的时候就需要解析处理标签嵌套。
那么基于这个设计,我想渲染一个自定义 React 组件要怎么做呢?就需要用他们的 Atomic 的 block 来实现,其实底层实现就是将 text 变成一个空字符串,然后利用 entityRanges 将这个空字符串指向一个自定义的 entityMap 的值,然后当你写在编辑器里面渲染的组件的时候,就需要通过一个 API 来获取这个 entity 的具体数据,然后作为 props 进行渲染。
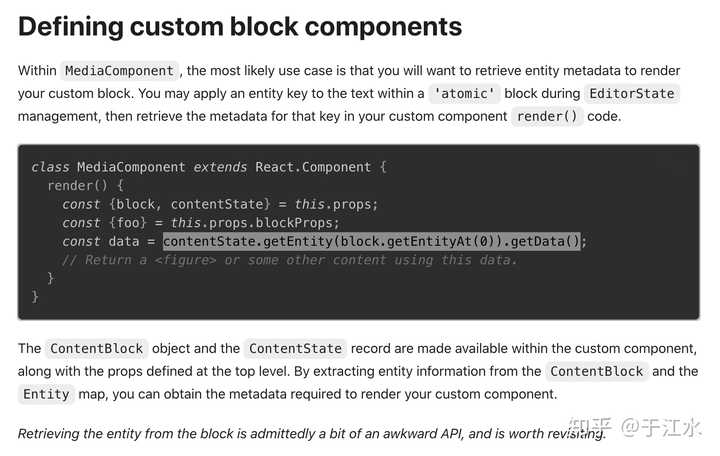
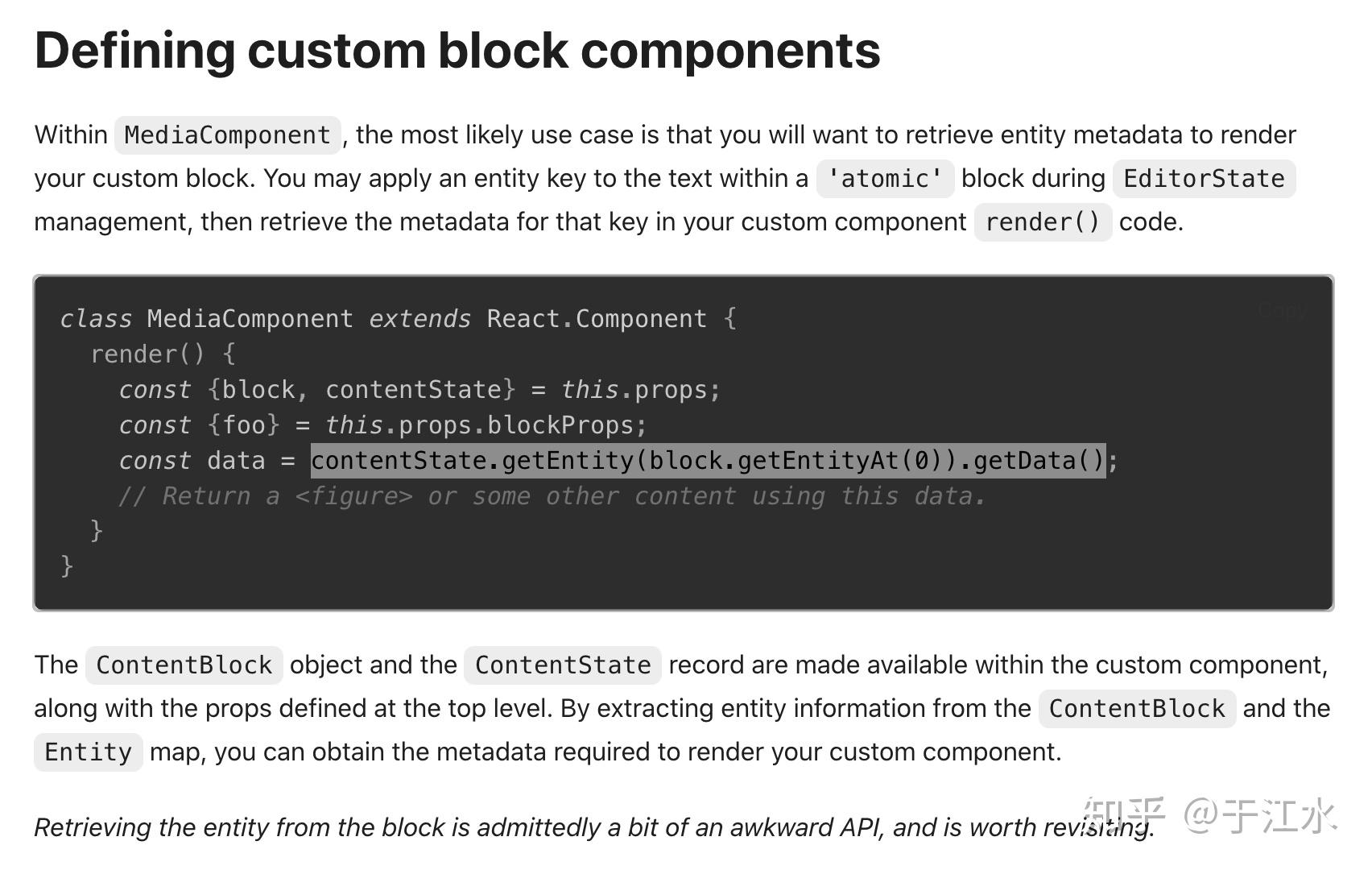
那么问题来了,如果你想要实现一个 inline 的 image 效果你怎么做呢?抱歉可能做不了,
至少在我当时封装组件的时候做不到
,因为 image 这种被定义为 block 级别的元素,block 怎么能插入 block 呢?那么我能不能退而求其次,通过常见的文字替代符号来实现呢?比如我在文本中编辑
[哈哈]
会实际渲染成小 inline 图片,但是背后底层数据是文本的
[哈哈]
。抱歉,也可能实现不了的,当时记得有尝试过,强行改变渲染字符的长度等会导致光标位置计算出问题,进而产生一系列的问题,比如选中光标,操作一下之后跳走了,因为你将几个字符实际浓缩了成一个了。还有后来忘记了什么 case 下还有 text 冲突的问题,所以官方突发奇想,用 emoji 来替代空格来做 text 区分这种“黑科技”,总之这套协议慢慢变成了限制。
基于这个协议和架构,实现中又出了一些体验性问题。 首先就是性能 ,短一点的内容还好说,但长文章性能就可以体现了,内容越长性能越差。immutable 能提升,但本身也是有大量运算,在大量突然的编辑下,粘贴复制各种操作,仍然能明显感觉到卡顿。而 contenteditable 的实现,是浏览器原生的实现,不管你内容多长多多,基本你是感觉不到有什么性能问题的,因为浏览器本身就是做富文本内容渲染的,只不过让你可以改一些内容而已,所以性能很好。还有就是 React 重新渲染的过程中一些刷新状态可能会被触发,比如知乎的编辑器编辑的时候就会闪烁。。。
其次就是光标相关。 糅合了大量自定义 block 等的内容,光标就变得很难处理了。本身就有很多兼容性或者 edge cases 没覆盖到,面对自定义 block 就更麻烦了。比如知乎的这个,两个 block 之间我根本没法选择插入光标,哪怕是鼠标点击或者键盘移动,除非我先选中一个 block 然后敲击回车,可是又有多少人知道这个操作呢? 还有我有时候选择一段文字摁下删除,结果没给我删掉,也是光标处理逻辑的问题。
之前为了提升一些用户体验,就直接调用 Draft.js 的光标相关 SelectionState 的方法(没错,光标的位置等,也全都有内部 SelectionState 来保存和控制,如果 Draft.js 重新用 JSON 数据渲染了,光标位置就会丢掉),对光标所在位置的键盘操作加了一些特殊的 hack 逻辑来优化,感觉挺乱的。
其次就是一些特殊逻辑的实现了,比如我们要求在粘贴外部文章过来的时候,需要解析出来原本的 img 标签,然后将图片下载保存到我们自己的 CDN 上,并且替换为新的 URL。怎么搞呢,当时只能把 Draft.js 内部 parse HTML 的逻辑搞出来,魔改加上我们的逻辑再塞回去实现。。。也是佩服我的脑回路。
Slate.js 也是一样的思路,但是后来者的优势借鉴了很多别的东西,对底层的描述模型改进了很多,所以我觉得合理多了,但仍然逃不了性能和体验的问题。最初语雀就是基于 Slate.js 封装的,体验一般般。后来再用新版语雀,突然发现好流畅体验上了一个台阶,各种内容类型也可以很好的兼容,看了下实现换成了 contenteditable 了。
那么 Draft.js 这类编辑器一无是处吗?当然不是。如果你的编辑器需要限制内容类型不能胡乱插入内容,并且需要存储结构化的数据而非 HTML,Draft.js 等仍然是可以选择的。因为使用 contenteditable 意味着你需要 parse 大量的 HTML 场景来控制,而且内容比较静态,难以在表面之外附加 meta 信息,你需要设计隐藏的 HTML 属性来存储而且还要验证,攻击伪造也很简单,直接查看源代码改一下提交,而 Draft.js 等的设计,天然的就解决了这个问题。
所以还是要根据业务特性来选择最佳方案,没有最好,只有更合适。淘宝内容平台当时的需求就是为了保证质量对内容形态和能力有强约束的规范,一步步放开,不同于微信公众号自定义程度很高,所以 Draft.js 还算是比较合理的选择。
其实除了现在的这些编辑器的实现,前段时间开始使用 Notion,发现他们的思路也挺有意思。也是翻看了下他们的代码了解了下,他们是将每一个元素每一块都当作一个独立的 block,然后内容部分使用一个 contenteditable 的 div 来实现更新,解析你输入的字符来做特殊处理和转换。这种实现也非常有意思,直接将富文本的复杂性降低了几个层次,尤其是对光标的处理等。当然也有致命缺陷,没法实现 inline image 这样在传统富文本编辑器天然支持的需求。但仍然是挺适合他们业务场景和受众的设计,不过对长文章性能也有点问题。关于更详细的设计, @陈天 大佬已经写过文章了,不再班门弄斧,有兴趣可以看看:
免责声明:以上经验主要来自于 17 年左右在做编辑器的时候,或许有些问题已经被 Draft.js 升级改造了,所以如果新版已经没问题了,可以评论更正,我改一下。