


Kaggle房价预测(二)-特征工程

Part Ⅱ 特征工程
Reference
本文所参考的Kernel:
1. Comprehensive data exploration with Python by Pedro Marcelino :探索性数据分析对我很有启发作用
2. A study on Regression applied to the Ames dataset by Julien Cohen-Solal :分别利用了岭回归、lasso、ElasticNet方法进行回归。比较了不同方法的效用。
2.1 回顾
上一章主要对数据进行了基本的描述,估计了影响SalePrice的主要的变量('OverallQuality','OverallQual','GrLivArea','YearBuilt'),并对他们与SalePrice制作散点图。通过相关系数图(热力图)及缩放热力图识别重点变量,将重点变量与SalePrice画散点图。
本章涉及 空缺值处理 、 特征工程 以及 特征转换 。原数据给了81个特征,好的数据清洗及数据改造能很大程度上影响最后的预测结果。
2.2 空缺值处理
本文空缺值处理部分主要对空缺值进行填充,首先会通过计算 空缺值率 的方法来进行描述性统计,之后根据统计结果针对具有空缺值的变量逐一进行填充,本文特征的特性导致填充的方式主要有以下几种:
(1) NA为None,
(2) NA为0,
(3) NA为本该特征出现频率最高的类型。
将数据集中唯一编码删除。将样本数据集和预测数据集合并,并删掉y变量“SalePrice",以便后续处理。
train.drop("Id", axis = 1, inplace = True)
y_train = train.SalePrice.values
all_data = pd.concat((train, test)).reset_index(drop=True)
all_data.drop(['SalePrice'], axis=1, inplace=True)
print("all_data size is : {}".format(all_data.shape))all_data size is : (2915, 80)
看看数据集中空缺值的情况,
total = train.isnull().sum().sort_values(ascending=False)
percent = (train.isnull().sum()/train.isnull().count()).sort_values(
ascending=False)
missing_data = pd.concat([total, percent], axis=1, keys=['Total','Percent'])
missing_data.head(20)
Total Percent
PoolQC 1453 0.995
MiscFeature 1406 0.963
Alley 1369 0.938
Fence 1179 0.808
FireplaceQu 690 0.473
LotFrontage 259 0.177
GarageCond 81 0.055
GarageType 81 0.055
GarageYrBlt 81 0.055
GarageFinish 81 0.055
GarageQual 81 0.055
BsmtExposure 38 0.026
BsmtFinType2 38 0.026
BsmtFinType1 37 0.025
BsmtCond 37 0.025
BsmtQual 37 0.025
MasVnrArea 8 0.005
MasVnrType 8 0.005
Electrical 1 0.001
Utilities 0 0.000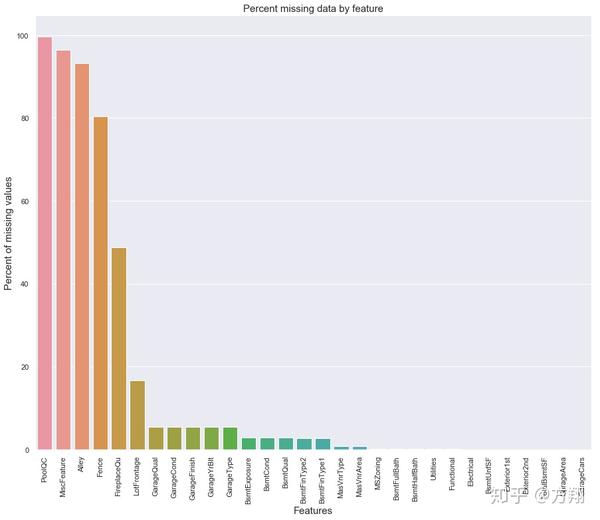
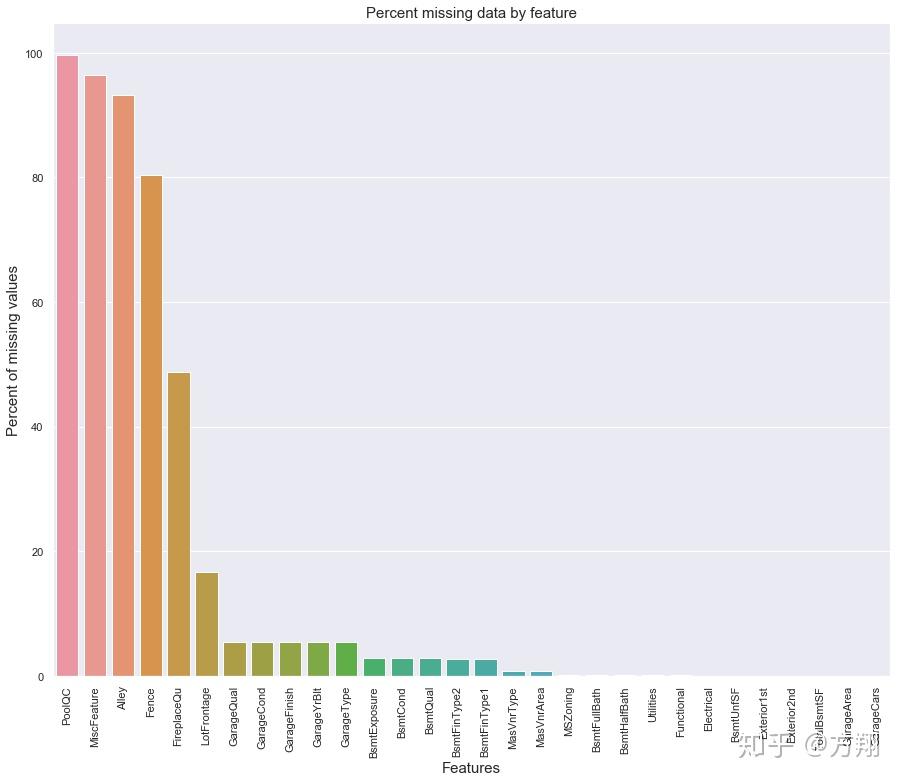
接下来就到了数据缺失值填充阶段了,这里以缺失率前5的变量为例,
PoolQC : 游泳池,可以理解老美也不是所有人能住游泳池的,大概也只有1%的房子有,那么这剩下的99%本文用"None"填充。
all_data["PoolQC"] = all_data["PoolQC"].fillna("None")MiscFeature、Alley、Fence、FireplaceQu等 : 和PoolQC一样。而有一些如面积类的变量,NA表示为0,如GarageArea。
all_data["MiscFeature"] = all_data["MiscFeature"].fillna("None")
all_data["Alley"] = all_data["Alley"].fillna("None")
all_data["Fence"] = all_data["Fence"].fillna("None")
all_data["FireplaceQu"] = all_data["FireplaceQu"].fillna("None")
for col in ('GarageYrBlt', 'GarageArea', 'GarageCars'):
all_data[col] = all_data[col].fillna(0)
for col in ('BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF','TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath'):
all_data[col] = all_data[col].fillna(0)填充NA是有一定规律的,除非数据说明中有明确的解释NA的含义,否则一般将数值型数据中的NA填充为0,类别型数据的NA填充为None。缺失率图有一些数据只有个别的缺失值,比如Electrical,可以将其填充为该列数据中出现次数最多的字符。
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
2.3 特别的特征工程
有一些特征呈现出无规则的标签,可以通过LabelEncoder()来进行有序的数字标签化。
cols = ('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass', 'OverallCond',
'YrSold', 'MoSold')
for c in cols:
lbl = LabelEncoder()
lbl.fit(list(all_data[c].values))
all_data[c] = lbl.transform(list(all_data[c].values))处理后的对比
all_data.FireplaceQu
Out[9]:
0 NaN
1 TA
2 TA
3 Gd
4 TA
5 NaN
6 Gd
7 TA
8 TA
9 TA
10 NaN
all_data.FireplaceQu
Out[11]:
0 5
1 4
2 4
3 2
4 4
5 5
6 2
7 4
8 4
9 4
10 5
2.4 特征的组合
本系列一通过热力系数图识别出了一些重要的变量,一些变量可以进行组合。
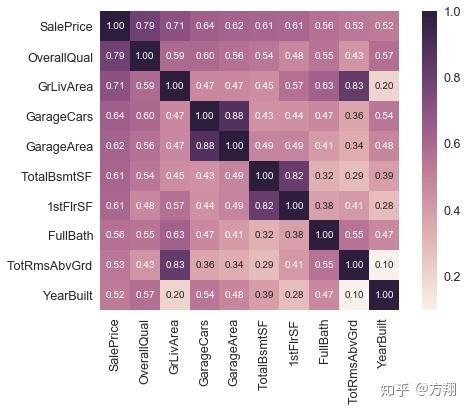
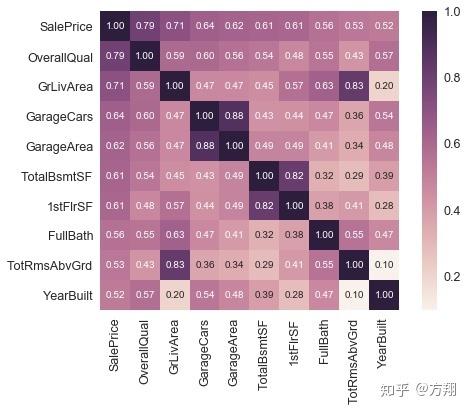
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']
2.5 特征对数化、标准化及虚拟变量
对数画处理的目标是使那写不完全具有正态分布的特征更符合正态分布,特征的正态性对回归模型的拟合效果起到非常重要的作用。
对数化
对数转换,不仅可以使特征正态化,而且也可以防止outliers对变量的影响。
批量处理,对偏度大于0.75的特征统一进行Box Cox 转换。
skewed_feats = all_data[numeric_feats].apply(lambda x: skew(x.dropna())).sort_values(ascending=False)
print("\nSkew in numerical features: \n")
skewness = pd.DataFrame({'Skew' :skewed_feats})
skewness.head(10)