


XGBoost高准确率的背后知识



虽然神经网络已经成为机器学习领域的王牌,但是很多业务的落地还是很大一部分依靠传统机器学习算法模型+特征工程。传统算法里属XGBoost最为卓越。今天来了解回顾一番。
XGBoost的优势
-
正则化:
xgboost增加了正则化,减少过拟合。 -
并行处理:
xgboost可以实现并行处理,系统设计上有用于并行学习的块结构,减少排序耗时。 -
高度的灵活性:
有自定义部分,允许自定义优化目标和评价标准。 -
缺失值处理:
XGBoost内置处理缺失值的规则,很好的处理缺失值问题。 -
剪枝:
剪枝更进一步,XGBoost,不会因为出现负损失而提前停下来,而是继续分裂下去到最大深度(max_depth),然后回过头来剪枝,更注重全局。 -
内置交叉验证:
内置交叉验证,方便获取最优迭代次数,而不需要靠网格搜索探索有限值的性能。 - 同样有GBM(梯度提升树)的优秀特点
XGBoost安装:
可参考
https://
blog.csdn.net/qq_364413
93/article/details/88836344
XGBoost参数
max_depth
: int (树的最大深度)默认6
Maximum tree depth for base learners.用来防止过拟合的一种方式。
learning_rate
: float 学习率 典型值0.01-0.2
Boosting learning rate (xgb's "eta")
n_estimators
: int 学习器数量
Number of boosted trees to fit.
silent
: boolean 是否打印信息
Whether to print messages while running boosting.
objective
: string or callable 学习目标 默认reg:linear
Specify the learning task and the corresponding learning objective or a custom objective function to be used (see note below).定义需要最小化的损失函数,常用值有binary:logistic 二分类的逻辑回归,返回预测的概率(不是类别);multi:softmax 使用softmax的多分类器,返回预测的类别(不是概率),此时还需设置类别数目:num_class ;multi:softprob,返回的是每个数据属于各个类别的概率。
booster
: string 基准模型
Specify which booster to use: gbtree, gblinear or dart.有gbtree基于树模型,gbliner基于线性模型,dart 自适应模型。
nthread
: int 线程设置 默认为最大可能的线程数
Number of parallel threads used to run xgboost. (Deprecated, please use ``n_jobs``)算法自动检测最大可能线程数。
n_jobs
: int 同上
Number of parallel threads used to run xgboost. (replaces ``nthread``)
gamma
: float 指定节点分裂所需的最小的孙子是函数下降值 默认为0
Minimum loss reduction required to make a further partition on a leaf node of the tree.
min_child_weight
: int 最小晔字节点样本权重和
Minimum sum of instance weight(hessian) needed in a child.
max_delta_step
: int 默认为0 限制每个数权重改变的最大步长。
Maximum delta step we allow each tree's weight estimation to be.
subsample
: float 训练样本采样比率
Subsample ratio of the training instance.
colsample_bytree
: float 树的列数采样比例(每一列一个特征)
Subsample ratio of columns when constructing each tree.
colsample_bylevel
: float 与上同作用,分裂时用
Subsample ratio of columns for each split, in each level.
reg_alpha
: float (xgb's alpha) L1正则化
L1 regularization term on weights.
reg_lambda
: float (xgb's lambda) L2正则化
L2 regularization term on weights。
scale_pos_weight
: float默认为1 类别样本不平衡是,设置它有助于算法更快收敛
Balancing of positive and negative weights.
base_score:
The initial prediction score of all instances, global bias.
seed
: int 随机种子,调参要设置以免不同的采样对结果有影响
Random number seed. (Deprecated, please use random_state)
random_state
: int 随机种子 ,进行参数评估时用
Random number seed. (replaces seed)
missing
: float, optional 缺省值
Value in the data which needs to be present as a missing value. If None, defaults to np.nan.
XGBoost调参步骤参考
1:调整max_depth,和min_child_weight
2.:gamma
3:subsample 和colsample_bytree
4: 正则化reg_alpha
5: n_estimator
6:学习率的降低
调参利用sklearn的网格搜索更方便
GridSearchCV用于系统地遍历多种参数组合,通过交叉验证确定最佳效果参数。数据规模较大时,时间比较长,取决于运行单元的性能。
GridSearchCV常用方法及属性
grid.fit():运行网格搜索
grid.score():运行网格搜索后模型得分
grid_scores_:给出不同参数情况下的评价结果
best_params_:描述已取得最佳结果的参数的组合
best_score_:提供优化过程期间观察到的最好评分
使用简单操作如下:
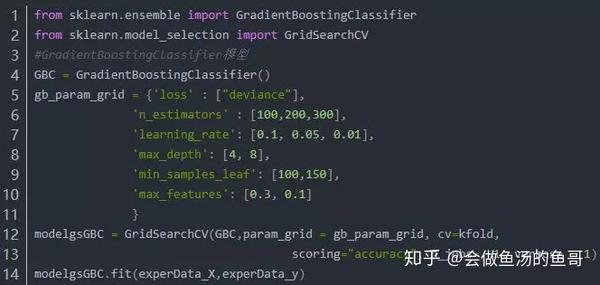
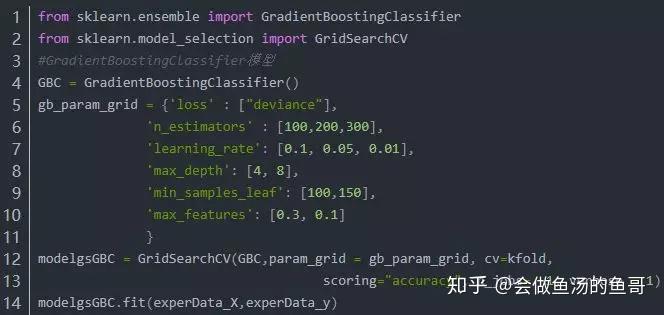
本人实操如下:
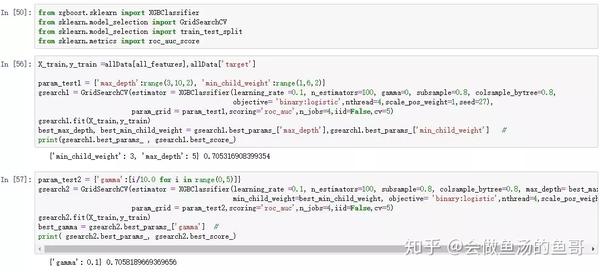
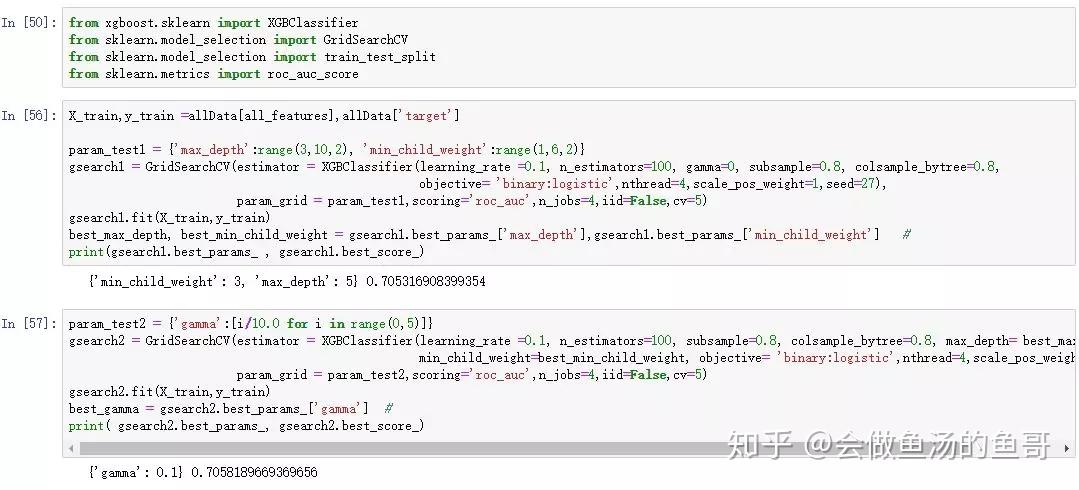
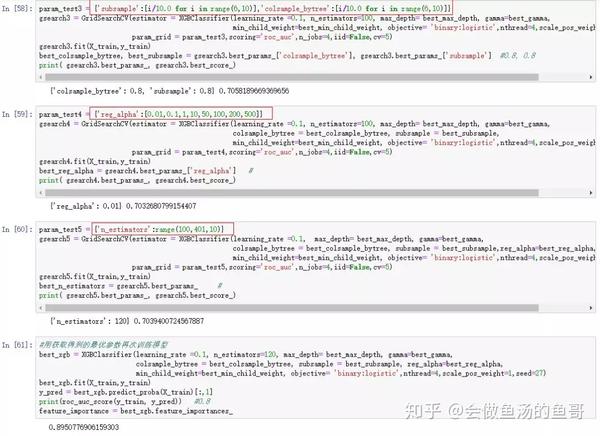
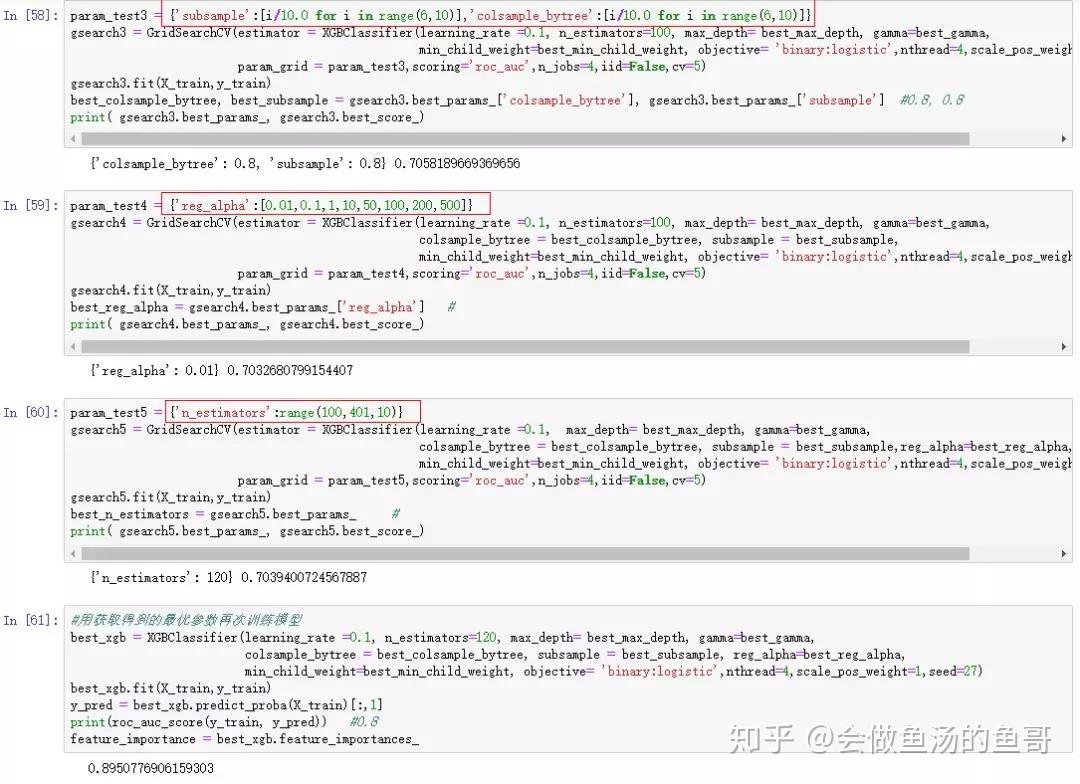
参考:
https://
blog.csdn.net/han_xiaoy
ang/article/details/52665396
阅读推荐
下载|730页 凸优化英文原版
下载|382页 PYTHON自然语言处理
下载|498页 Python基础教程第3版
下载|1001页 Python数据分析与数据化运营
下载|439页 统计学习基础-数据挖掘、推理预测
下载|271页 漫画线性代数
下载|322页 Machine Learning for Hackers
下载|215页 推荐系统实践
BAT算法工程师(机器学习)面试100题(上)
GBDT+LR算法解析及Python实现
下载|
Python刷题,你要的LeetCode答案都在这里了!
下载|吴恩达deeplearning.ai深度学习教学视频
10分钟入门TensorFlow
10分钟入门TensorFlow(2): 房价预测(Python代码篇)
比Adam,SGD更优秀的AdaBound实验对比代码
GBDT+LR算法解析及Python实现
下载|经典《深度学习-花书》《机器学习-周志华》《统计学习方法-李航》《机器学习实战》《利用Python进行数据分析》
CNN网络架构演进:从LeNet到DenseNet
比Adam,SGD更优秀的AdaBound实验对比代码
10分钟入门Keras : 两种快速模型搭建方式
2019年两会,关于AI的提案|汇总
6种机器学习中的优化算法:SGD,牛顿法,SGD-M,AdaGrad,AdaDelta,Adam
视频下载|Spark ML机器学习实战 全套
下载|182页 SQL tutorial
下载视频|人工智能推荐系统课程
用20行Python代码为《都挺好》剧照进行人脸检测
FaceNet 人脸识别模型- 彭于晏和邓超人脸像吗
中文课程!台大李宏毅机器学习公开课2019版上线
收藏:全网最大机器学习数据集,视觉、NLP、音频都在这了
