

多说一点重定位
关于GOT / PLT的问题,我想下面这份回答和里面的引文讲的足够详细了,我就不赘述了。
Linux动态链接为什么要用PLT和GOT表? - ivan lam的回答 - 知乎
Linux动态链接为什么要用PLT和GOT表?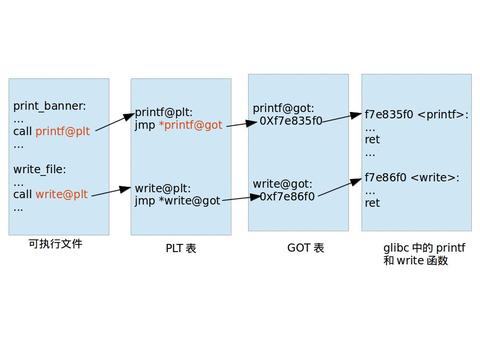
不过里面只提了动态库函数symbol的在被调用时的延迟定位,没有提全局变量&函数&字符串等的地址是如何获取的:假如我试图获取一个动态库函数的函数指针,我并不像调用函数那样会执行一个函数,怎么去进行懒加载呢?
回答是如果你编译的是地址无关代码,则不存在这样的懒加载方法。。只能在可执行文件或者动态库初始化时对他们进行重定位,访问时通过间接引用来获得他们的地址。
编译命令:gcc t2.c -g -O2 -Wall -fPIC
dump结果:
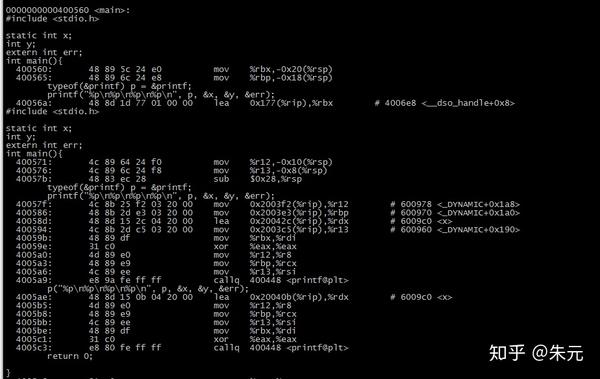
(源码已经在dump内容中)
%rdi 对应 "%p\n%p\n%p\n%p\n"
%rsi 对应 p
%rdx 对应&x
%rcx 对应&y
%r8 对应 &err
上图我们分析了全局字符串(字面量),static变量,全局变量,和非当前模块编译下的全局变量地址的获取方式。
可以得到以下几个在-fPIC 地址无关编译选项被启用下的结论:
- static 变量的和全局字符串(字面量)的地址可以直接取址。
- 全局量的地址都得通过间接取址。
- 2中的地址在main函数执行之前进行初始化。
我们可以通过地址断点来看看这些“存放全局变量的地址的地址”是什么时候被初始化的。
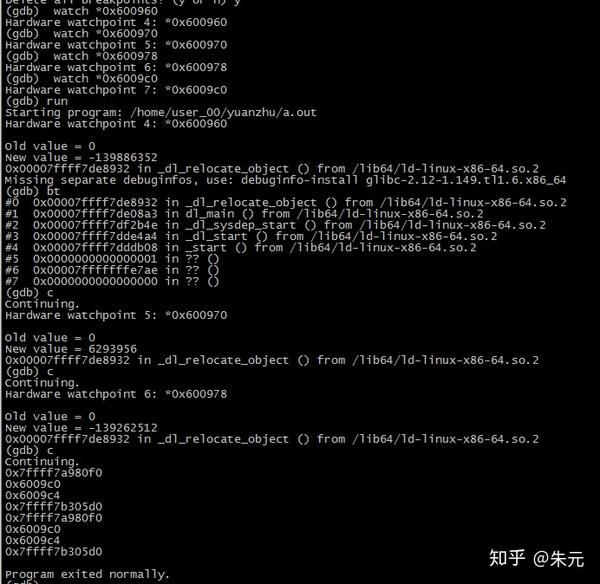
可以看到我们虽然编译的是可执行文件而不是动态库,但由于我们启用了-fPIC, 所以依然会使用类似动态库的方法来“初始化时重定位”可执行文件里的全局变量符号。当前模块内编译和链接的符号与外部定义的符号err(实际上我们根本都没链接这个符号)并无区别。
而且从打印出来的地址上,我们注意到,我们通过&printf获取到的printf函数地址直接就是printf的真实地址(0x7ffff7a980f0),而不是printf@plt的地址(这个结论在没有-fPIC的时候不成立)。这也提醒了我们 -O2选项在此种情况下做了 负优化 : 我们注意到那行
p("%p\n%p\n%p\n%p\n", p, &x, &y, &err);
4005ae: 48 8d 15 0b 04 20 00 lea 0x20040b(%rip),%rdx # 6009c0 <x>
4005b5: 4d 89 e0 mov %r12,%r8
4005b8: 48 89 e9 mov %rbp,%rcx
4005bb: 4c 89 ee mov %r13,%rsi
4005be: 48 89 df mov %rbx,%rdi
4005c1: 31 c0 xor %eax,%eax
4005c3: e8 80 fe ff ff callq 400448 <printf@plt>
此时p已经是真实的printf地址,但是编译器依然认为:间接call效率不如直接call,于是把我们的p换成了printf@plt。。殊不知printf@plt 内部依然还会进行一次间接跳转 跳转去0x7ffff7a980f0也就是p的值头上。。无论从指令数量还是跳转次数上都吃了亏,跳转预测准确性也没占便宜。

(注意printf的GOT条目并不是开始的 “存放全局变量的地址的地址” 0x600998 != 0X600960, 这完全是2条独立而并行的寻址路线)
注意链接器其实知道链接对象中包含了对printf的函数指针取值,已经有一个地址存放了这个函数指针,并且在模块加载时就会立即被初始化,所以链接器可以修改printf@plt 的实现 把
jmpq *0x20054a(%rip)
改为
jmpq *0x200512(%rip)
其中0x200697 = 0x40059b+0x2003c5-0x40044e
从而避免在第一次调用printf@plt 激发懒加载(其实都已经加载好了嘛)。
当然 如果链接器能够更有些侵略性,可以直接把连接对象中的所有
callq 0x400448 <printf@plt>
改成
callq *0x10203040(%rip) 其中0x10203040 是0x40059b+0x2003c5-$rip
这样就直接调用,避免2次跳转。不过x64后者比前者指令多了1个字节,,我也没发现可以省掉这1个字节的法子...需要整体调整一下函数后面的任何指令中的$rip远跳转偏移量了。