


最近该论文又进行了一版更新,效果非常惊艳。下面的回答是截止与2022年11月14号的,已经不适用于现在的版本。
现在的结果毫无疑问是找到了面向katago的对抗样本,更妙的是他还具有可迁移性,即:攻击一个模型所得到的对抗样本也可以欺骗一个未知的模型。由于我最近事比较多,就先不讨论最新版了
结合作者团队在 https:// boardgames.stackexchange.com /questions/58127/is-adversarial-policies-beat-professional-level-go-ais-simply-wrong 上的rebuttal以及评论区中的讨论,现在我个人认为这篇文章还是有可取之处的。当然初版论文所展现的过于离谱了。后面喷论文的仅限于其第一版,也就是11月1号提交到arxiv的版本 Adversarial Policies Beat Professional-Level Go AIs ,或者说投稿ICLR的初版论文 https:// openreview.net/pdf? id=Kyz1SaAcnd
如果不夸大其词,抛弃初版论文离谱的利用pass来赢的行为而只考虑最新的结果,这篇论文的贡献如下:
他们证明了,一个还算强的围棋AI,即不使用蒙特卡洛搜索纯基于策略网络行棋的katago,会在特殊情况下犯下与其平常情况所展现出的实力极其不相符的错误。下图行至240手时,本来赢麻了的katago非常神奇的自紧一气,大龙死光。
之所以强调与其实力不相符,是因为这一步但凡学过一天围棋的都不会下出来,但仅仅只学过一天围棋的难以下过纯策略网络行棋的katago。
实际katago行棋时是策略网络结合蒙特卡洛,所以不容易犯这么明显的错误。但是策略网络毕竟是其棋感来源,所以策略网络存在这样的bug在理论上增加了katago不鲁棒的可能性,尽管实际上还难以找出他的bug。
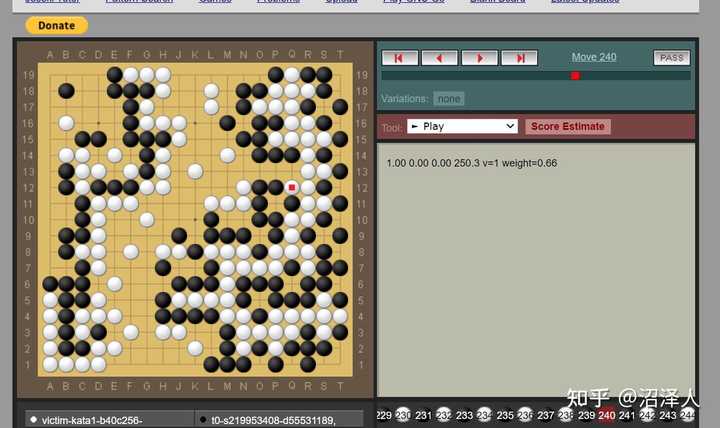

感谢 @sora 在评论区指出作者给出了另一份棋谱 Go Games, Pattern Search, Joseki Tutor, SGF Editor ,说实话这份就正常了不少。katago前期一路碾压直到240手莫名其妙来了一步正常人都不会走的自紧一气被翻盘。假如作者能把跑出这份棋谱的实验参数列清楚让人可复现的话,我觉得就是个有意义的工作了,确实揭露了katago在特殊情况下存在盲点。
不过同时评论区也指出用相同的模型参数无法复现出这份棋谱,所以还不好说。(虽然我很好奇有这样一份正常得多的结果为什么论文要放那样的两张图)
对于某些对AI半懂不懂还在那说有意义只是外行看不出来的,为什么你们就这么相信自己是内行呢?
建议先收收你们那点优越感,稍微学习一下围棋规则,或者起码随便把论文中的棋局给一个学过围棋的问问谁赢了
这论文跟对抗样本压根就不是一回事
在这把我在回答最后列的观点提前一下。真想做围棋AI的对抗程序,在想着一步登天把katago打爆之前建议先来个简单得多的task:找一个显著A方大优但AI误判为B方大优的局面,注意只要找到这个局面先不用管怎么下到这个局面来(后者难度大很多很多,虽然前者也比图像上那些欺骗图像分类模型的对抗样本要更难),我认为都是非常有价值的研究。
对抗攻击是有的,搞强化学习的对抗攻击也是有的,但这篇称不上
这篇论文利用的是判断胜负的程序的bug,先占一个角,然后往其他地方丢几粒棋子
这样一来,katago算一下胜率,觉得自己是稳赢的——至少任何一个棋手看到论文里的图片都会意识到adversary已经输定了。这个时候adversary主动提出pass来进入数子阶段,katago自然乐意数子
然后数子程序有bug,他以为adversary外面的子没死(左图黑子,右图白子),于是判定外面是双活,从而得出赢了的假象。
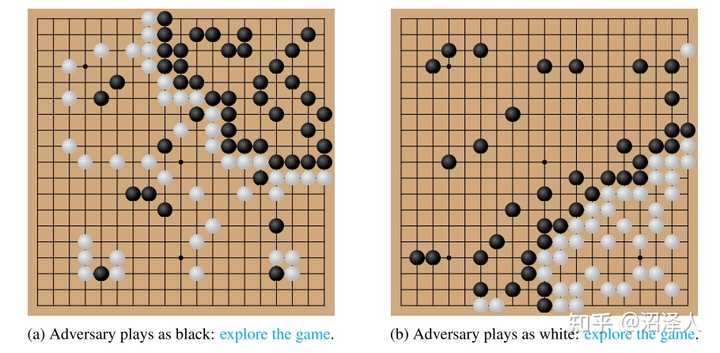

作为一个做对抗的人(虽然我做的是视觉上的对抗),我认为这实在说明不了任何事。因为做对抗要攻的得是katago的策略网络或者价值网络,而不是数子的程序。数子的程序甚至都不是基于DL的。
事实上,本文投稿的ICLR2023,已经有审稿人看出这个问题,见 Adversarial Policies Beat Professional-Level Go AIs 的审稿人6za8。最后这篇论文大概率是中不了的。
“做对抗要攻的得是katago的策略网络或者价值网络,而不是数子的程序”我这句话想强调的是,katago的核心在于如何决策下一步下哪,当然katago给出的胜率分布对职业棋手也有很大帮助(发明新定式、练习、围棋主播讲棋),可是最后的数子程序压根就不是katago的贡献。
一个极端的比喻——不会数子的围棋之神算不算一个优秀的围棋棋手?
利用AI不擅长数子来欺骗他并不能算找到了katago的bug,起码我相信任何人在看到标题的时候心目中AI的bug不是长这样的。这种击败katago的方式和断网线我感觉就是一个层次的。
找到AI的盲点对抗攻击他有真实例子吗?其实是有的,当年李世石打AlphaGo的第四局的那一挖,其实是没有棋的。但是根据后续的访谈可知,AI的价值网络对那一挖的分数产生了误判,给的胜率过低,导致蒙特卡洛时没有充分的采样次数以至于后面计算量不够而失误。我认为这就是非常标准的对抗样本,也为李世石凭人力击中了AI的盲点而深感敬佩。这部分说法来自这个视频 https://www. bilibili.com/video/BV1E p4y1D7PR?p=2
最后,有关于利用围棋规则来赢katago这一点,我也想了一个idea来分享一下:
- 选用应氏规则和Tromp-Taylor规则以外的规则比赛,需要注意到的是,这两个规则外的规则都不允许自杀,见下图维基百科


2. 我让katago 360子
3. 提出数子,或者如这篇论文一样选择pass。我pass过后,由于不能自杀,对方只能跟着pass,然后全盘死子,我成功在让katago 360子的情况下获胜。
事实上,在大多数规则下,不做第3步,老老实实让了katago 360子后下,也是稳赢的,因为一上来提对方360子就已经积累了180目的优势(大多数规则下)。
我认为这种段子一样的钻规则漏洞,和这篇论文是一个档次的,甚至还更巧妙。毕竟我这种让katago 360子的做法是严格按照大多数正规围棋规则来的,而这篇论文的做法攻得甚至还不是正规围棋规则。
那么katago使用这种不严谨的判胜负程序是否有潜在问题呢?我觉得理论上是存在的,因为这个判胜负程序是影响到了katago的训练的,进而理论上影响了katago的模型。理论上存在可能是katago训练中误以为一个输的局面是赢而导向这个局面——但实际上暂时没人发现有这种现象。如果这篇论文最终能利用这个判胜负的漏洞进一步挖掘出katago模型的漏洞,那就非常nb了,可惜没有(也不确定做不做得到)
我相信围棋AI肯定是有对抗样本的,这里的对抗样本指的意思是给定一个局面后事实上是某方显然地大优AI却误判了局势。因为训练的样本数相比围棋总状态数实在微乎其微。就好像视觉中图像的训练集相比图像域( 256^{224\times 224\times 3} )微乎其微一样。只是围棋要想进行对抗扰动比较难,不像视觉一样能轻松地加上±eps的噪声。所以我认为假如有围棋AI的对抗样本的工作,在正式击败围棋AI前,应该有一个相对容易一点的task,那就是找到一个AI对形式判断失误的局面。我认为这是对抗攻击围棋AI的必要条件,如果找不到这种判断失误的局面怎么可能对抗攻击的赢,反之即使找到了也不一定能成功下赢AI,因为这个局面不一定走得出来。但总之还是比直接对抗赢围棋AI要容易一点。