


hadoop分布式文件系统HDFS

思考和对比
如果自己来设计分布式文件系统,应该会是什么样的思路呢?
用一张图来看。
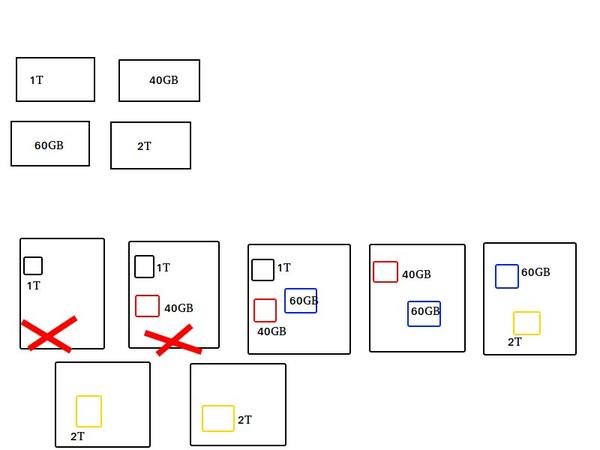
如图所示,四份文件,七台机器,多副本方式存储,每一份文件除自身外有两个副本文件储存在不同机器上,如果前两台机器挂了,那么不会影响到我们的数据。
但是这样会有很大的缺点,不管文件多大,都存储在一个node上,在进行数据处理的时候,很难进行并行处理,那什么叫并行处理呢?假设一个文件1个TB,如果不支持分割,那么意味着一次要处理1TB数据,这么大的数据量,处理起来是非常慢的!节点可能成为网路的瓶颈,很难进行大数据的处理。而且存储负载很难均衡,每个节点的利用率都非常低。
hadoop所使用的是hdfs文件处理系统,hdfs是按照每一个文件,先进行拆分,拆分成很多块,比如每个块128MB,然后每个block都存储在节点上并且以多副本进行存储,这样的话,使得数据高可用,同样的挂了一台机器,数据并不受影响,然后每个block的大小是一致的,做多的话只有128MB,这样的话,每个机器的负载均衡就会好很多,不会像上面图中节点上存在1TB这种很大的数据,从而很好保证负载均衡,并且每一个block只有128MB,我们在处理的时候可以并行处理,这样的话可以提升计算能力,不管你数据多大,都拆分为每个block大小为128MB,这就很好的提升数据处理的速度!
分布式文件系统 HDFS
hadoop实现了一分布式文件系统,hadoop distributed file system,简称hdfs。
源自google的gfs论文。发表于2003年,hdfs就是gfs的克隆版。
hdfs是非常巨大的分布式文件系统,一般我们的电脑不管是mac还是win都有文件系统,按照层级,目录,树的方式进行存储,但是对于单机版文件系统存储是有限的,如果采用分布式系统,那么文件就以分布式方式存储在系统上,如果文件系统存储空间不够,那么直接加机器到hdfs上面,就可以扩容,这样就可以满足大数据处理的要求。
hdfs可以运行在极其普通廉价的机器上,就是普通的pc机,通过这些非常普通的pc机组成分布式集群。
hdfs易扩展,就好比你存储空间不够,直接加机器,简单粗暴!
hdfs可以提供技能不错的文件存储服务,为什么这么说,因为作为廉价的普通机器,这个故障率相对还是比较高的!如果集群上面,你的文件存放在廉价机器上面,如果硬件坏掉了,那么意味着数据就掉了,那这样肯定是不行的,那hdfs是怎么做的呢?他是先把文件按照块的大小,比如140MB的数据拆分为128MB和12MB,并且以多副本的方式存放在集群的多个节点之上,那么你一台机器坏了,没关系,别的节点上的副本还是完好的,这样子的话就可以提供不错的文件存储服务。
HDFS架构图
官方介绍: HDFS has a master/slave architecture. An HDFS cluster consists of a single NameNode, a master server that manages the file system namespace and regulates access to files by clients. In addition, there are a number of DataNodes, usually one per node in the cluster, which manage storage attached to the nodes that they run on. HDFS exposes a file system namespace and allows user data to be stored in files. Internally, a file is split into one or more blocks and these blocks are stored in a set of DataNodes. The NameNode executes file system namespace operations like opening, closing, and renaming files and directories. It also determines the mapping of blocks to DataNodes. The DataNodes are responsible for serving read and write requests from the file system’s clients. The DataNodes also perform block creation, deletion, and replication upon instruction from the NameNode.
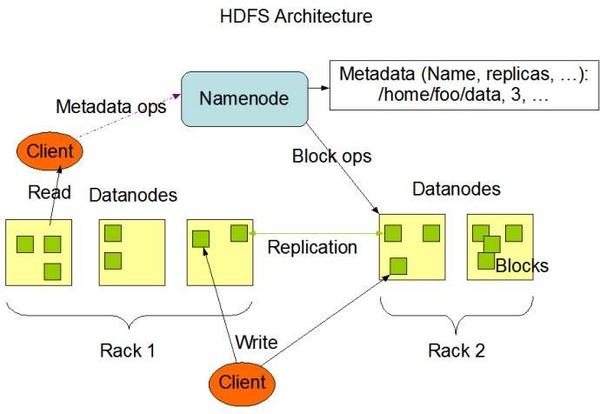
The NameNode and DataNode are pieces of software designed to run on commodity machines. These machines typically run a GNU/Linux operating system (OS). HDFS is built using the Java language; any machine that supports Java can run the NameNode or the DataNode software. Usage of the highly portable Java language means that HDFS can be deployed on a wide range of machines. A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
1个Master(NameNode/NN) + N个Slaves(DataNode/DN)(HDFS/YARN/HBase)
1个文件会被拆分成多个block
(blocksize:128MB
130MB ==> 2个block:128MB和2MB)
Master(NameNode/NN):
1、负责client请求的响应
2、负责元数据(文件的名称、副本系数、block存放的DataNode)的管理
Slaves(DataNode/DN):
1、存储用户的文件对应的数据块(block)
2、定期向NameNode发送心跳信息, 汇报本身及其所有的block信息,健康状况,这样
NameNode就知道你的情况,如果这个DN出问题,那下面有文件进来,NN就不会存
储在这个节点上了
A typical deployment has a dedicated machine that runs only the NameNode software. Each of the other machines in the cluster runs one instance of the DataNode software. The architecture does not preclude running multiple DataNodes on the same machine but in a real deployment that is rarely the case.
建议:实际生产中NN和DN部署在不同的节点上(个人学习时,可以一台机器既有NN又有DN)
HDFS副本
官方介绍: HDFS supports a traditional hierarchical file organization. A user or an application can create directories and store files inside these directories. The file system namespace hierarchy is similar to most other existing file systems; one can create and remove files, move a file from one directory to another, or rename a file.
The NameNode maintains the file system namespace. Any change to the file system namespace or its properties is recorded by the NameNode. An application can specify the number of replicas of a file that should be maintained by HDFS. The number of copies of a file is called the replication factor of that file. This information is stored by the NameNode.
HDFS is designed to reliably store very large files across machines in a large cluster. It stores each file as a sequence of blocks. The blocks of a file are replicated for fault tolerance. The block size and replication factor are configurable per file.
All blocks in a file except the last block are the same size.
An application can specify the number of replicas of a file. The replication factor can be specified at file creation time and can be changed later. Files in HDFS are write-once (except for appends and truncates) and have strictly one writer at any time.
The NameNode makes all decisions regarding replication of blocks. It periodically receives a Heartbeat and a Blockreport from each of the DataNodes in the cluster. Receipt of a Heartbeat implies that the DataNode is functioning properly. A Blockreport contains a list of all blocks on a DataNode.
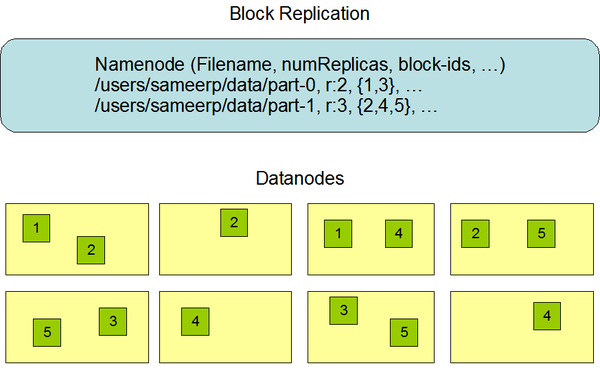
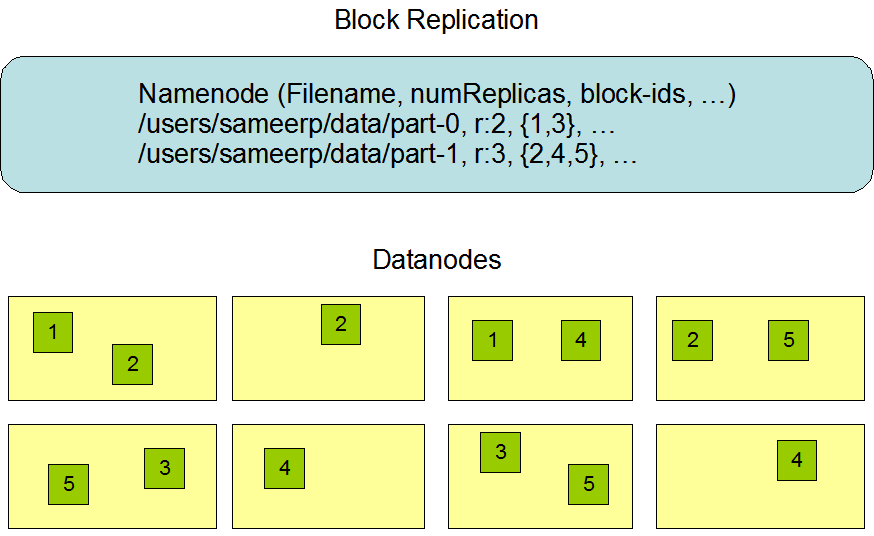
HDFS副本存放策略
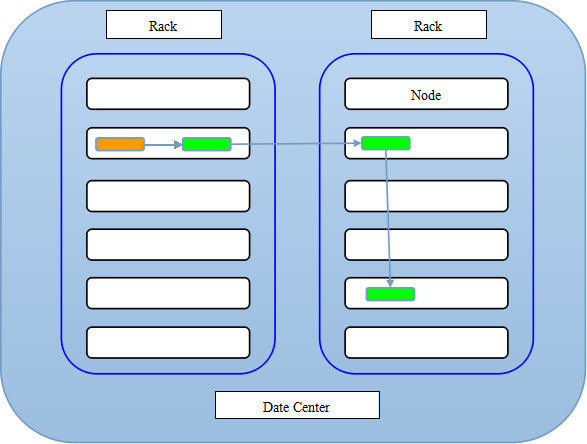
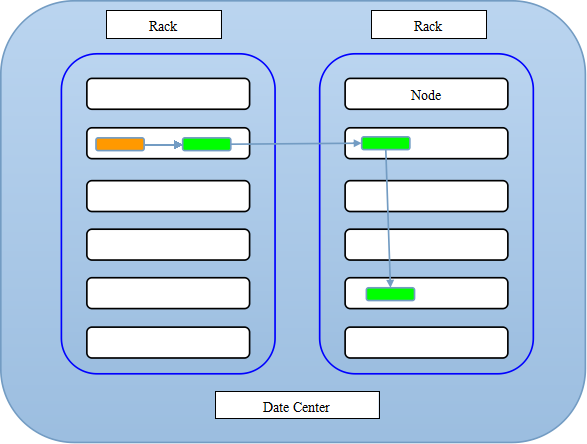
我们知道一个文件会被拆分成很多block,而每个block又会被存为多份,当然默认三份。那么每个block是怎么存放的呢?按照hdfs的策略,对于第一个副本,图中黄色表示客户端所在节点,如果在改节点上提交数据,那么第一个副本就存储在该节点上,那么第二个副本存储在另外一个机架上任意一个节点上,第三个存放在第二个副本相同机架上的不同的节点上。简而言之,第一个放在提交数据所在节点,另外两个放在与第一个副本不同机架上的不同的DN上。如果你只有一个机架,那么就随机放置在你的机架上,如果你的block数量庞大,那么就是随机放置在不同机架的不同节点上。分机架还是有好处的,一个机架坏了,另一个正常工作。至少两个以上的机架!
HDFS环境搭建(伪分布式环境)-Ubuntu
安装java
java下载网址: Java SE Development Kit 8
下载完成之后解压到你指定的目录
$ tar -zxvf jdk-7u79-linux-x64.tar.gz -C ~/你指定的目录/
查看java路径
$ echo $JAVA_HOME
/home/xxx/xxx/java-8-oracle
把路径添加至环境变量
$ sudo vim /etc/profile
在末尾加上
export JAVA_HOME=/home/xxx/xxx/java-8-oracle
export PATH=$JAVA_HOME/bin:PATH
保存退出并使其生效
$ source /etc/profile
验证java安装是否成功
$ java -version
安装ssh
$ sudo apt-get install ssh
安装好ssh以后我们需要配置一个免密码登录,因为我们的ND和DN这些进程之间是需要相互通信的,所以我们需要配置免密码登录使得他们之间的通信不需要我们手动干预,不需要熟人任何密码。
$ ssh-keygen -t rsa
输入一路回车
然后在用户目录下查看.ssh文件夹
$ ls -la
然后进入.ssh文件夹看到两个文件
id_rsa id_rsa.pub
再输入
$ cp ~/.ssh/id_rsa.pub ~/.ssh/authorized_keys
然后测试ssh,连接到本地
$ ssh localhost
无任何异常说明ssh测试成功
下载安装hadoop
使用版本:hadoop-2.6.0-cdh5.7.0
下载地址( Index of /cdh5/cdh/5 )
下载好后解压至你指定的目录
然后进入hadoop文件下的etc目录下的hadoop文件夹下,
用vim或者gedit打开hadoop-env.sh,然后找到export JAVA_HOME
把java路径设置进去(java路径:$ echo $JAVA_HOME)
我们配置的是伪分布式的环境,所以还要设置hadoop的core-site.xml和hdfs-site.xml
在core-site.xml中配置以下设置
<property>
<name>fs.defaultFS</name>
<value>hdfs://你的机器名称:8020</value>
</property>
下面的配置是因为我们默认的文件系统存储的地方是在临时文件夹下面,
而临时文件夹在linux中每次重启都会被删除的,所以我们需要添加下面的属性,
这个目录一定要设置,否则每次重启数据又没了,配置好后还要去
/home/你的用户名/你安装hadoop的目录/ 下面新建临时文件tmp(mkdir tmp)
<property>
<name>hadoop.tmp.dir</name>