Prometheus还提供了下列内置的聚合操作符,
这些操作符
作用域瞬时向量
。可以
将瞬时表达式返回的样本数据进行聚合
,形成
一个新的时间序列
。
聚合运算符从标签维度进行聚合,这些运算符在一个时间内对多个序列进行聚合
使用聚合操作的语法如下:
<aggr-op>([parameter,] <vector expression>) [without|by (<label list>)]
其中只有
count_values
,
quantile
,
topk
,
bottomk
支持参数(parameter)。
without用于从计算结果中移除列举的标签,而保留其它标签。by则正好相反,结果向量中只保留列出的标签,其余标签则移除。
通过without和by可以按照样本的问题对数据进行聚合。
sum(http_requests_total) without (instance)
sum(http_requests_total) by (code,handler,job,method)
如果只需要计算
整个应用的HTTP请求总量
,可以直接使用表达式:
sum(http_requests_total)
我们知道 Prometheus 的时间序列数据是多维数据模型,我们经常就有根据
各个维度进行汇总
的需求。
基于标签聚合
-
request_duration_seconds_count 就是一共有多少个请求
-
request_duration_seconds_sum 是总的延迟时间,就是所有请求一共花了多长时间
例如我们想知道我们的
demo 服务每秒处理的请求数
,那么可以
将单个的速率相加
就可以。
sum(rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
可以得到如下所示的结果:
但是我们可以看到绘制出来的图形没有保留任何标签维度,一般来说可能我们希望保留一些维度,例如,我们可能更希望计算每个 instance 和 path 的变化率,但并不关心单个 method 或者 status 的结果,这个时候我们可以在 sum() 聚合器中添加一个 without() 的修饰符:
sum without(method, status) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
上面的查询语句相当于用 by() 修饰符来保留需要的标签的取反操作:by()类似于SQL语句里面的group by,这里是根据什么去做聚合。
sum by(instance, path, job) (rate(demo_api_request_duration_seconds_count{job="demo"}[5m]))
 现在得到的 sum 结果是就是按照
现在得到的 sum 结果是就是按照 instance、path、job 来进行分组去聚合的了:
最后同理apiserver也是一样的
sum by(verb)(rate(apiserver_request_duration_seconds_count[5m]))
这里的分组概念和 SQL 语句中的分组去聚合就非常类似了。
除了 sum() 之外,Prometheus 还支持下面的这些聚合器/聚合函数:(如果不加上by进行分组,那么计算的是整个时间序列的值,只是一个值而已,没有标签维度)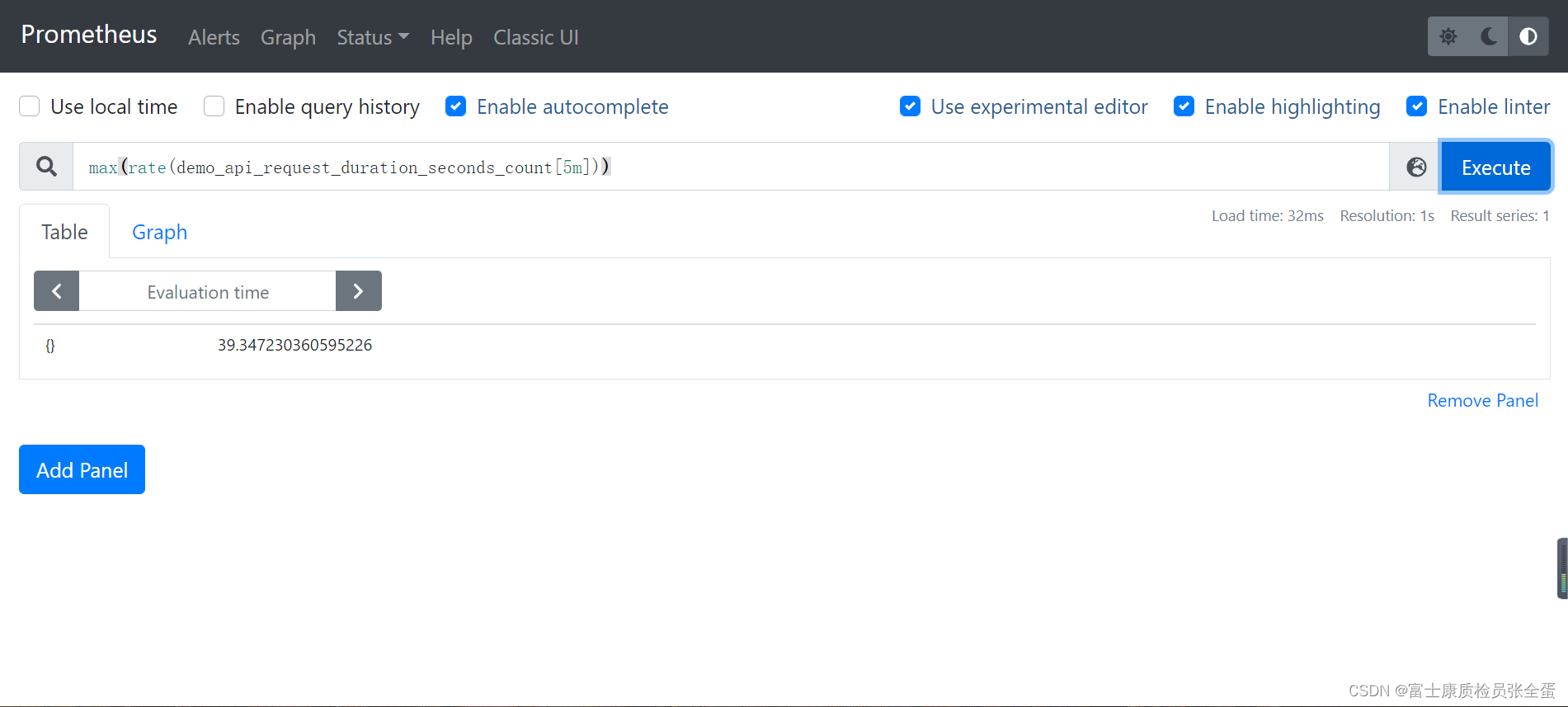
sum():对聚合分组中的所有值进行求和min():获取一个聚合分组中最小值max():获取一个聚合分组中最大值avg():计算聚合分组中所有值的平均值stddev():计算聚合分组中所有数值的标准差stdvar():计算聚合分组中所有数值的标准方差count():计算聚合分组中所有序列的总数 计算序列的总数,要和sum取分开count_values():计算具有相同样本值的元素数量bottomk(k, ...):计算按样本值计算的最小的 k 个元素topk(k,...):计算最大的 k 个元素的样本值quantile(φ,...):计算维度上的 φ-分位数(0≤φ≤1)group(...):只是按标签分组,并将样本值设为 1。
1.按 job 分组聚合,计算我们正在监控的所有进程的总内存使用量(process_resident_memory_bytes 指标):
sum by(job) (process_resident_memory_bytes)
 2.计算 指标有多少不同的 CPU 模式:
2.计算 指标有多少不同的 CPU 模式:
count (group by(mode) (demo_cpu_usage_seconds_total))
3.计算每个 job 任务和指标名称的时间序列数量:
count by (job, __name__) ({__name__ != ""})
每个指标里面都有_name_
基于时间聚合(Gauge类型)
前面我们已经学习了如何使用 sum()、avg() 和相关的聚合运算符从标签维度进行聚合,这些运算符在一个时间内对多个序列进行聚合,但是有时候我们可能想在每个序列中按时间进行聚合,例如,使尖锐的曲线更平滑,或深入了解一个序列在一段时间内的最大值。
为了基于时间来计算这些聚合,PromQL 提供了一些与标签聚合运算符类似的函数,但是在这些函数名前面附加了 _over_time()
<aggregation>_over_time()
下面的函数列表允许传入一个区间向量,它们会聚合每个时间序列的范围,并返回一个瞬时向量:
avg_over_time(range-vector):区间向量内每个指标的平均值。min_over_time(range-vector):区间向量内每个指标的最小值。max_over_time(range-vector):区间向量内每个指标的最大值。sum_over_time(range-vector):区间向量内每个指标的求和。count_over_time(range-vector):区间向量内每个指标的样本数据个数。quantile_over_time(scalar, range-vector):区间向量内每个指标的样本数据值分位数。stddev_over_time(range-vector):区间向量内每个指标的总体标准差。stdvar_over_time(range-vector):区间向量内每个指标的总体标准方差。
[info] 注意
即使区间向量内的值分布不均匀,它们在聚合时的权重也是相同的。
例如,我们查询 demo 实例中使用的 goroutine 的原始数量,可以使用查询语句 go_goroutines{job="demo"},这会产生一些尖锐的峰值图:
我们可以通过对图中的每一个点来计算 10 分钟内的 goroutines 数量进行平均来使图形更加平滑:
他要算十分钟之内的平均值,其实就是将这些值全部加起来求平均。
 可以看到计算的平均值
可以看到计算的平均值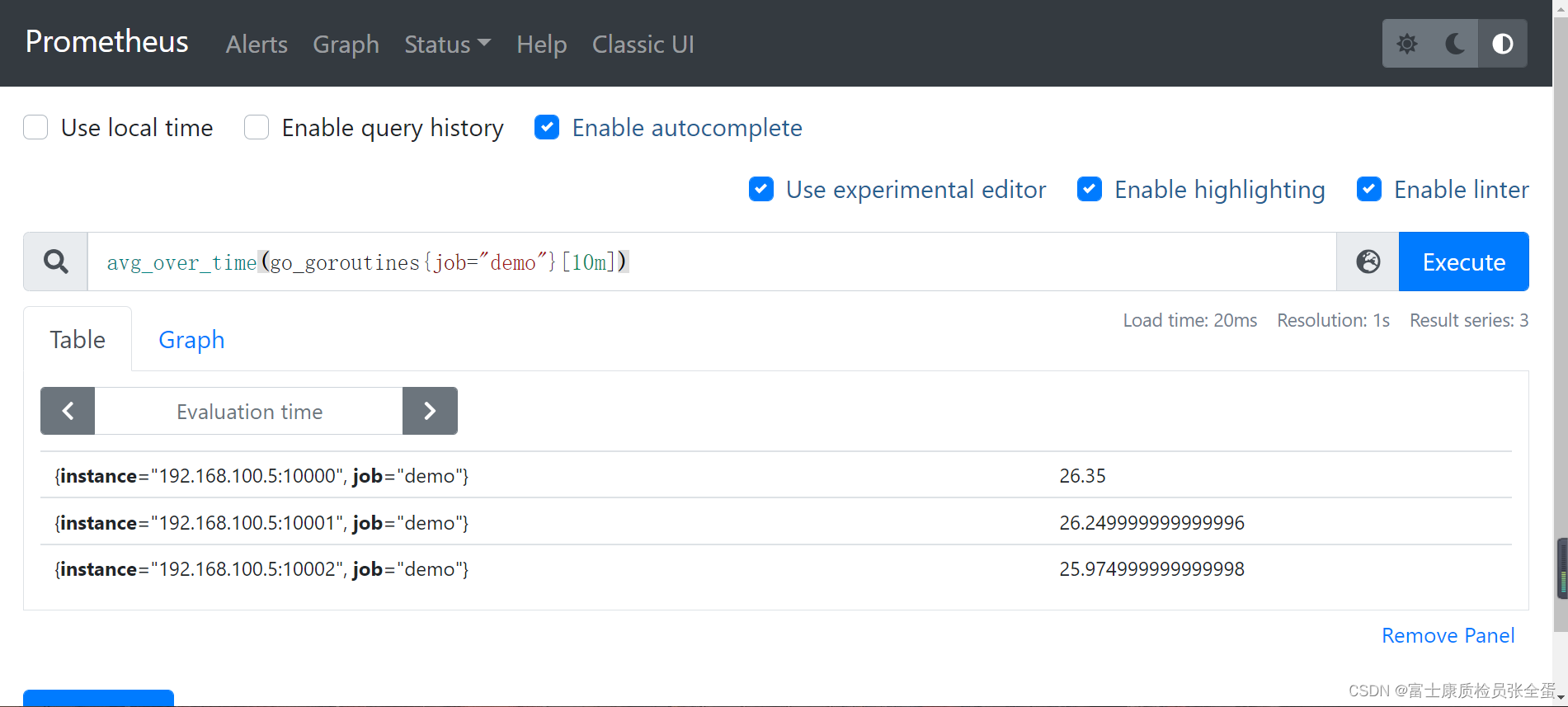
avg_over_time(go_goroutines{job="demo"}[10m])
这个查询结果生成的图表看起来就平滑很多了:
比如要查询 1 小时内内存的使用率则可以用下面的查询语句:
100 * (1 - ((avg_over_time(node_memory_MemFree_bytes[1h]) + avg_over_time(node_memory_Cached_bytes[1h]) + avg_over_time(node_memory_Buffers_bytes[1h])) / avg_over_time(node_memory_MemTotal_bytes[1h])))
上面所有的 _over_time() 函数都需要一个范围向量作为输入(比如[5m]),通常情况下只能由一个区间向量选择器来产生,比如 my_metric[5m]。但是如果现在我们想使用例如 max_over_time() 函数来找出过去一天中 demo 服务的最大请求率应该怎么办呢?
请求率 rate 并不是一个我们可以直接选择时间的原始值,而是一个计算后得到的值,比如:
rate(demo_api_request_duration_seconds_count{job="demo"}[5m])
如果我们直接将表达式传入 max_over_time() 并附加一天的持续时间查询的话就会产生错误:
# ERROR!
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"}[5m]
)[1d]
实际上 Prometheus 是支持子查询的,它允许我们首先以指定的步长在一段时间内执行内部查询,然后根据子查询的结果计算外部查询。子查询的表示方式类似于区间向量的持续时间,但需要冒号后添加了一个额外的步长参数:[<duration>:<resolution>]。
这样我们可以重写上面的查询语句,告诉 Prometheus 在一天的范围内评估内部表达式,步长分辨率为 15s:
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"}[5m]
)[1d:15s] # 在1天内明确地评估内部查询,步长为15秒
也可以省略冒号后的步长,在这种情况下,Prometheus 会使用配置的全局 evaluation_interval 参数进行评估内部表达式:
max_over_time(
rate(
demo_api_request_duration_seconds_count{job="demo"}[5m]
)[1d:]
这样就可以得到过去一天中 demo 服务最大的 5 分钟请求率,不过冒号仍然是需要的,以明确表示运行子查询。子查询还允许添加一个偏移修饰符 offset 来对内部查询进行时间偏移,类似于瞬时和区间向量选择器。
但是也需要注意长时间计算子查询代价也是非常昂贵的,我们可以使用记录规则(后续会讲解)预先记录中间的表达式,而不是每次运行外部查询时都实时计算它。
- 输出过去一小时内 demo 服务的最大 95 分位数延迟值(1 分钟内平均),按 path 划分:
max_over_time(
histogram_quantile(0.95, sum by(le, path) (
rate(demo_api_request_duration_seconds_bucket[1m])
)[1h:]
一、PromQL 基本使用
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言,语言表现力非常丰富,内置函数很多,在日常数据可视化以及rule 告警中都会使用到它。
在页面 http://localhost:9090/graph 中,输入下面的查询语句,查看结果,例如:
http_requests_to...
PromQL(Prometheus Query Language)是Prometheus 提供的函数式查询语言,可以查询实时数据和聚合时间序列的数据。在数据可视化和编写告警规则中使用。瞬时向量(Instant-Vector) - 一组时间序列,包含相同时间戳的单个样本;例如:可以通过向 {} 里附加一组标签来进一步过滤:完全匹配和正则匹配区间向量(Range-Vector) - 一组时间序列,包含每个时间序列随时间变化的数据点范围,例如:在过去5分钟内指标名称为http_requests_total的所有时
这种方式的问题很明显,以系统 API 调用的平均响应时间为例:如果大多数 API 请求都维持在 100ms 的响应时间范围内,而个别请求的响应时间需要 5s,那么就会导致某些 Web 页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。例如,假设 http 请求响应时间的样本的 9 分位数(quantile=0.9)的上边界为 0.01,即表示小于等于 0.01 的样本值的数量占总体样本值的 90%bucket 可以理解为是对数据指标值域的一个划分,划分的依据应该基于数据值的分布。
指标是用来衡量性能、消耗、效率和许多其他软件属性随时间的变化趋势。它们允许工程师通过警报和仪表盘来监控一系列测量值的演变(如CPU或内存使用量、请求持续时间、延迟等)。指标在IT监控领域有着悠久的历史,并被工程师广泛使用,与日志和链路追踪一起被用来检测系统是否有不符合预期的表现。在其最基本的形式中,一个指标数据点是由以下三个部分构成:一个指标名称收集该数据点的时间戳一个由数字表示的测量值在过去的十...
1.1 SQL中的分组查询
SQL查询中,通GROUP BY语名实现分组查询。GROUP BY子句要和聚合函数配合使用才能完成分组查询,在SELECT查询的字段中,如果没有使用聚合函数就必须出现在ORDER BY子句中。分组查询后,查询结果为一个或多个列分组后的结果集。
GROUP BY语法
SELECT 列名, 聚合函数(列名)
FROM 表名
WHERE 列名 operator value
GROUP BY 列名
[HAVING 条件表达式] [WITH ROLLUP]
在以上语句中:
聚合函数 – 分组查询通常要与聚合函数一起使用,聚合函
当我们刚开始学Oracle时,见到group by,常常会来个三连问:为什么要用group by?group by应该怎么用?为什么写了group by运行时会提示“不是单组分组函数;不符合group by语法”?面对这些问题,我都胆战心惊了(怎么可能)。接下来我将把group by的心经要诀传授给你们,是不是很激动鸭,那就拿起你们的小本本记下来吧(收藏点赞+关注哦)。
何为group by
group by即分组
如何用group by
group by语法:
在select语句的一般格式中就有group by语句,group
by语句一般放在where语句的后面,若有having子句,则放
CPU 使用率的计算方法
翻了几篇 Prometheus 的 PromQL 查询 cpu 使用率的文章,说得都不是特别透,结合一篇英文文章终于搞明白了怎么计算这个指标。
cpu 模式
一颗 cpu 要通过分时复用的方式运行于不同的模式中,可以类比为让不同的人使用 cpu,张三使一会儿,李四使一会儿。这些模式可以用 top 命令查看,包括:
us:用户进程使用cpu的时间
sy:内核进程使用cpu...

