


分布估计:经验分布函数、直方图、茎叶图和核密度估计

分布估计:经验分布函数、直方图、茎叶图和核密度估计
摘要:
分布估计是统计学中的重要概念,用于估计未知分布的形态和性质。本文将详细介绍四种常见的分布估计方法:经验分布函数、直方图、茎叶图和核密度估计。我们将探讨每种方法的理论背景和相关结果,并提供使用Python和R语言实现这些方法的示例代码。
1. 引言
分布估计是统计学中的基本任务之一,它涉及对未知分布进行建模和估计。通过对数据进行分布估计,我们可以了解数据的性质、形态和概率特征,从而更好地理解数据背后的统计规律和现象。在某些应用中,也将分布估计作为进一步数据分析的基础。
2. 经验分布函数
经验分布函数(Empirical Distribution Function,EDF)是一种非参数的分布估计方法。它通过对数据样本的累积分布函数进行估计来逼近未知分布函数。经验分布函数具有一致性和渐近正态性等重要性质,并可用于构建置信区间和进行假设检验。
示例代码(Python):
```python
- import numpy as np
- import matplotlib.pyplot as plt
- from scipy.stats import norm
- # 创建示例数据
- data = np.random.normal(loc=0, scale=1, size=1000)
- # 计算经验分布函数的值
- sorted_data = np.sort(data)
- n = len(data)
- ecdf = np.arange(1, n+1) / n
- # 绘制经验分布函数图形
- plt.step(sorted_data, ecdf, label='Empirical CDF')
- # 绘制真实分布函数(如果已知的话)
- # 如果已知真实分布函数cdf存在,则使用下面的代码
- true_cdf = norm.cdf(sorted_data, loc=0, scale=1)
- plt.plot(sorted_data, true_cdf, label='True CDF')
- # 添加图例、标签和标题
- plt.legend()
- plt.xlabel('Sample Values')
- plt.ylabel('Cumulative Probability')
- plt.title('Empirical CDF')
- # 显示图形
- plt.show()`
``
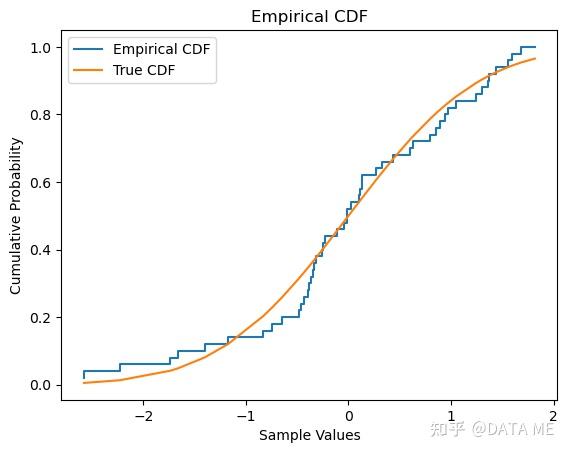
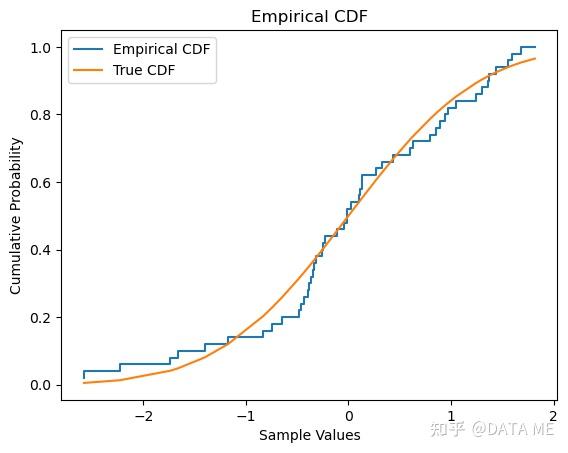
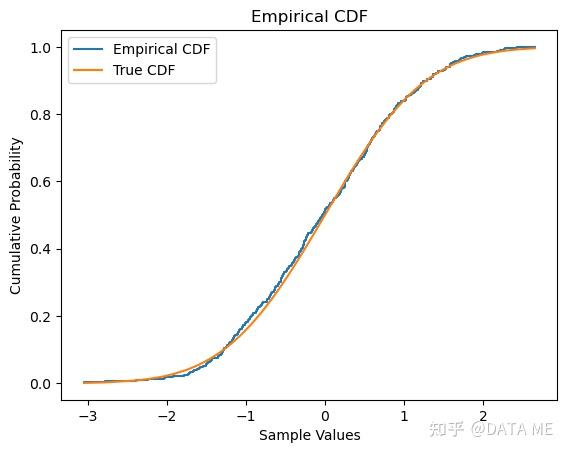
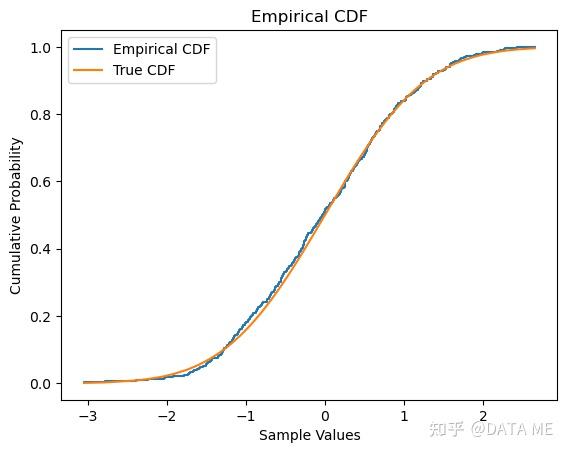
注:也可以直接用使用 statsmodels 库中的 ECDF 类构建经验分布函数。
示例代码(R):
利用经验分布函数构建置信区间的一种常用方法是基于经验分布函数的Bootstrap方法。Bootstrap方法通过从原始数据中有放回地抽样生成多个重复样本,然后对每个重复样本计算经验分布函数。通过对这些经验分布函数进行排序,可以得到置信区间。对于假设检验,可以使用经验分布函数进行一些统计量的比较。例如,可以使用Kolmogorov-Smirnov检验来比较两个样本的经验分布函数是否来自同一分布:
from scipy.stats import ks_2samp
statistic, p_value = ks_2samp(data1, data2)
相关内容今后介绍。
3. 直方图
直方图是一种常见的分布估计方法,它将数据分割为若干个区间,并计算每个区间中数据点的频数或频率。直方图提供了数据的分布情况和形态,可以用于可视化数据并发现数据的特征和异常。
示例代码(Python):
- import numpy as np
- import matplotlib.pyplot as plt
- # 示例数据
- data = np.random.normal(0, 1, 1000)
- # 绘制直方图
- plt.hist(data, bins=20, edgecolor='black')
- # 添加标签和标题
- plt.xlabel('Value')
- plt.ylabel('Frequency')
- plt.title('Histogram')
- # 显示图形
- plt.show()
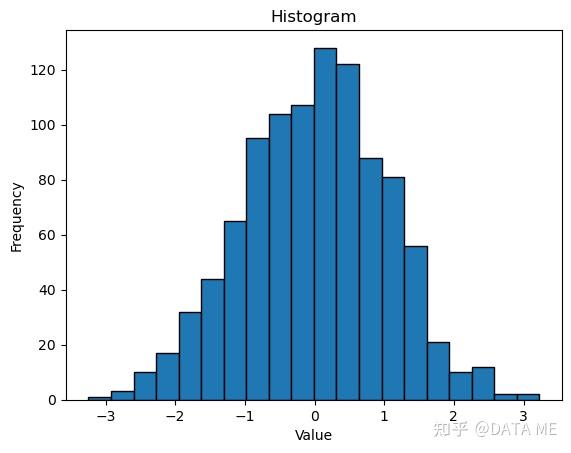
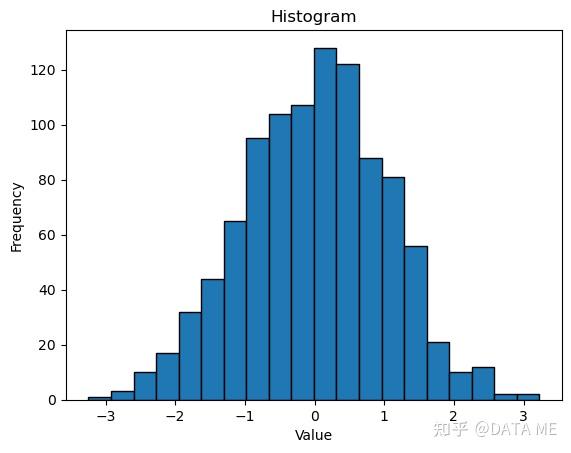
4. 茎叶图
茎叶图(stem-and-leaf plot)是一种可视化统计数据的方法,类似于直方图。它将数据按照十位和个位数的位置进行分组,并以图形方式展示数据的分布。茎叶图可以提供数据的整体分布情况以及具体数值的信息。
在茎叶图中,数据的十位数称为"茎"(stem),而个位数称为"叶"(leaf)。每个茎上的叶子表示具有相同十位数的数据值。通过在每个茎下方绘制叶子的数值,我们可以得到数据的分布情况。
茎叶图与直方图有以下几个关系:
- 数据展示方式:直方图使用矩形条形表示不同数值范围的频率或频数,而茎叶图使用数字来表示具体的数值。
- 数据精度:直方图将数据分组为不同的范围,因此损失了数据的精度。而茎叶图保留了数据的每个数值,可以提供更详细的信息。
- 数据排列:直方图将数据按照数值范围分组,并在X轴上显示范围,Y轴上显示频率或频数。茎叶图按照十位和个位数将数据分组,并在垂直轴上显示茎,水平轴上显示叶子。
- 数据可读性:直方图适用于大量数据的展示,可以快速获取数据分布的整体形态。茎叶图适用于小规模数据的展示,可以提供更详细的数值信息。窗体底端
示例代码(Python):
- import numpy as np
- import matplotlib.pyplot as plt
- # 示例数据
- data = np.random.randint(1, 100, 100)
- data=np.sort(data)
- # 提取茎和叶
- stems = np.floor(data / 10)
- leaves = data % 10
- # 构建茎叶图
- stemleaf = {}
- for stem, leaf in zip(stems, leaves):#zip将元素配对
- if stem not in stemleaf:
- stemleaf[stem] = []
- stemleaf[stem].append(leaf)
- # 排序茎叶图
- sorted_stemleaf = {stem: sorted(leaves) for stem, leaves in stemleaf.items()}
- # 输出茎叶图
- for stem, leaves in sorted_stemleaf.items():
- leaf_string = ' '.join([str(leaf) for leaf in leaves])
- print (f"{int(stem)} | {leaf_string}")
- # 绘制茎叶图
- fig, ax = plt.subplots()
- for stem, leaves in sorted_stemleaf.items():
- leaf_positions = np.full(len(leaves), int(stem))
- ax.scatter(leaf_positions, leaves, color='b', marker='o')
- ax.vlines(int(stem), np.min(leaves) - 1, np.max(leaves) + 1, color='r', linewidth=1)
- ax.set_xlabel('Stems')
- ax.set_ylabel('Leaves')
- ax.set_title('Stem-and-Leaf Plot')
- plt.show()``
结果:

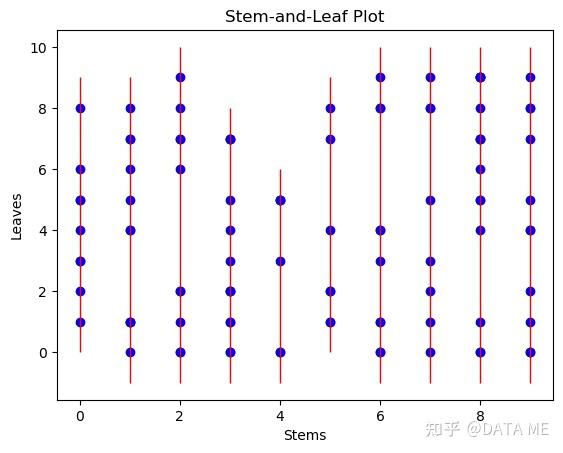
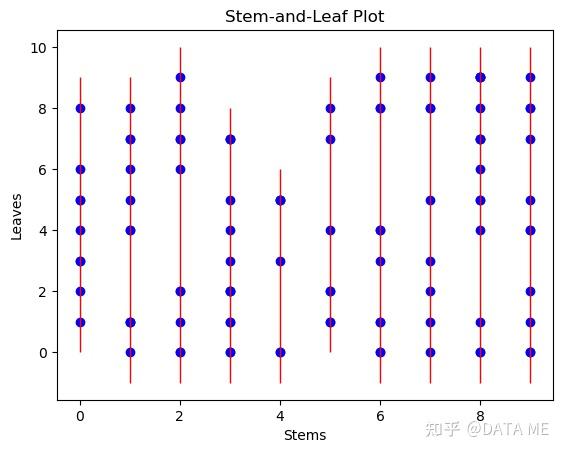
5. 核密度估计
核密度估计(Kernel Density Estimation,简称KDE)是一种非参数方法,用于估计概率密度函数(PDF)的技术。它通过将每个数据点视为一个独立的概率分布,然后将它们合并为一个平滑的连续概率密度函数。
KDE的基本思想是在每个数据点周围放置一个核函数,然后将这些核函数加和起来,形成平滑的估计概率密度函数。核函数通常是一个关于原点对称的函数,如高斯函数(也称为正态分布函数)或Epanechnikov函数等。每个核函数在其宽度(带宽)范围内有一定的贡献,而带宽决定了估计的平滑程度。较小的带宽会产生更复杂的估计,而较大的带宽会产生更平滑的估计。
KDE可视化的代码示例(使用Python和Matplotlib库)如下:
```python
- import numpy as np
- import matplotlib.pyplot as plt
- from scipy.stats import norm, gaussian_kde
- # 示例数据
- data = np.random.normal(0, 1, 1000)
- # 核密度估计
- kde = gaussian_kde(data)
- # 在一定范围内生成一组值
- x = np.linspace(min(data), max(data), 1000)
- # 估计概率密度函数
- y = kde(x)
- # 绘制核密度估计曲线
- plt.plot(x, y, label='KDE')
- # 绘制真实的概率密度函数(标准正态分布)
- plt.plot(x, norm.pdf(x, 0, 1), label='True PDF')
- # 添加标签和标题
- plt.xlabel('Value')
- plt.ylabel('Density')
- plt.title('Kernel Density Estimation')
- # 显示图例
- plt.legend()
- # 显示图形
- plt.show()
```
这段代码使用`scipy.stats`模块中的`gaussian_kde`函数进行核密度估计。然后,生成一组x值,在每个x值上计算对应的估计概率密度函数y值,并将它们绘制成曲线。同时,还绘制了真实的概率密度函数(这里以标准正态分布为例)作为对比。最后,添加标签、标题和图例,然后显示图形。
通过运行这段代码,你可以可视化核密度估计曲线,并将其与真实的概率密度函数进行比较,以便更好地理解数据的分布情况。我们可以根据需要调整代码中的数据和参数,以适应不同的数据集和分布。
```
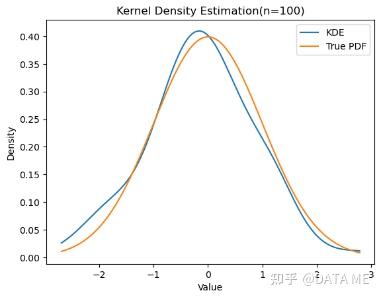
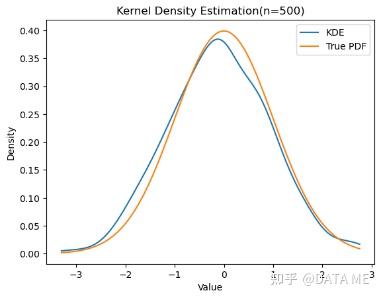
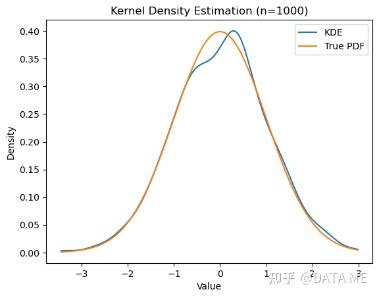
6. 其它方法
现代的方法中包括GAN(Generative adversarial nets )以及VAE (Variational auto-encoder)等方法,超出本文设定读者对象的知识储备。
7. 结论
分布估计是统计学中重要的概念和技术。本文介绍了经验分布函数、直方图、茎叶图和核密度估计这四种常见的分布估计方法,并提供了使用Python和R语言实现这些方法的示例代码。熟练掌握这些分布估计方法可以帮助我们更好地理解数据、分析数据的特征,并支持进一步的统计推断和决策。
希望这篇文章能够对您有所帮助!
