在近期的AI TIME 青年科学家——AI 2000 学者专场论坛系列报告中,来自复旦大学计算机科学学院的助理教授陈静静博士带来了题为「跨模态菜谱检索」的演讲,从「基于识别的菜谱检索」、「基于跨模态学习的菜谱检索」、「跨域食物迁移」等方面介绍了跨模态菜谱检索任务几年来的前沿研究工作,讨论了该领域未来的研究方向。(回放:https://event.baai.ac.cn/activities/346)
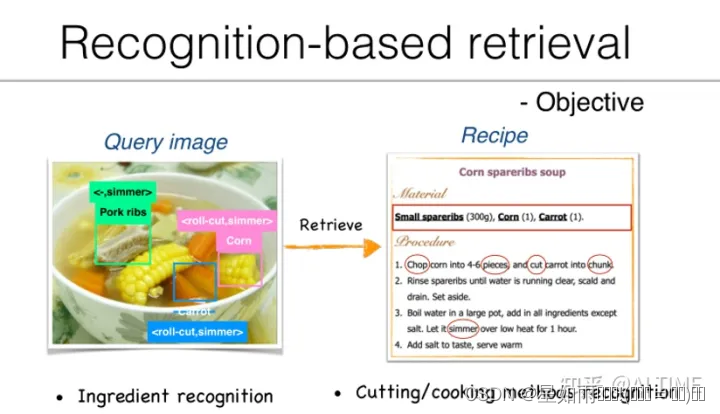
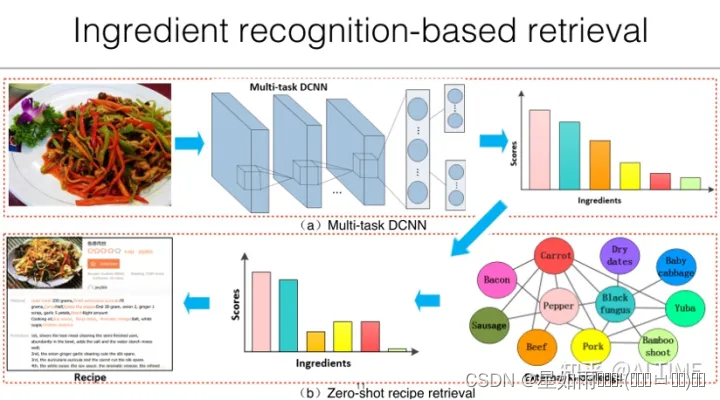
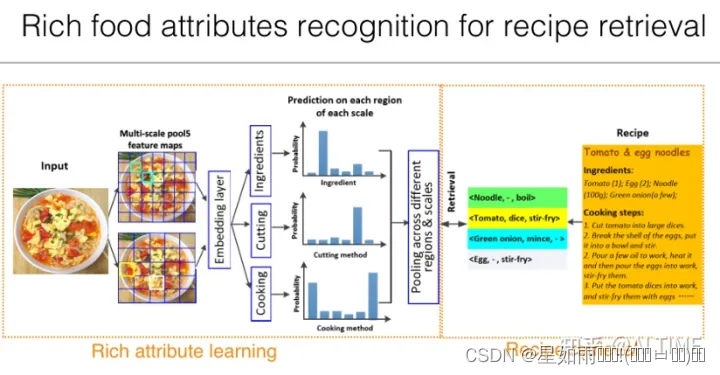
基于识别的跨模态检索依赖于大量的属性信息标注工作,需要耗费巨大的人力成本,在真实应用场景下的可行性较低。为此,研究者们提出基于跨模态学习技术进行菜谱检索。

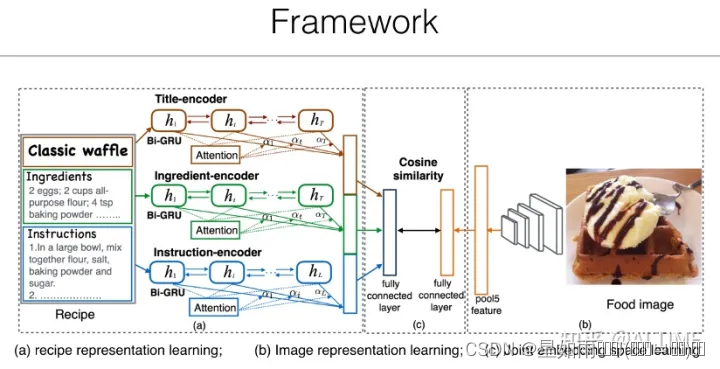
此类方法的关键之处在于学习查询图像和菜谱文本的联合子空间,我们可以在该空间中计算菜谱和图像的相似度,并基于得到的相似度对候选菜谱进行排序,进而得到最后的菜谱检索结果。一些研究者进一步使用注意力机制赋予背景区域较低权重,让模型重点关注与食材相关的区域,从而提高菜谱与图像相似度计算的准确率。同时,对于菜谱文本,我们赋予与视觉无关的句子较低的权重,理解食谱的因果效应。最后,我们利用经过上述处理的视觉和文本数据学习联合子空间。
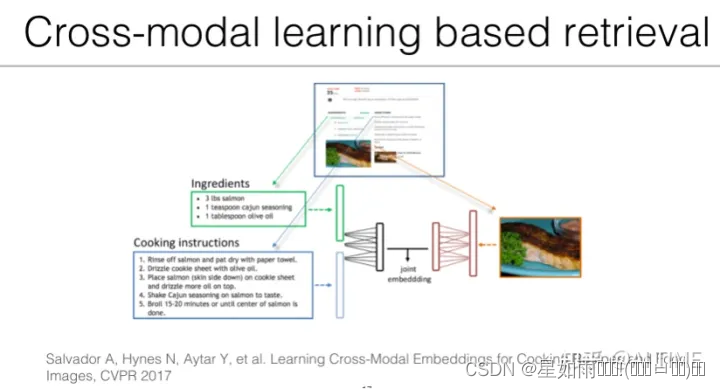
2017 年,来自 MIT 的研究人员在论文「Learning Cross-Modal Embeddings for Cooking Recipes and Food Images」中,首次利用食材原料、烹饪步骤与图像的联合子空间进行食谱检索。
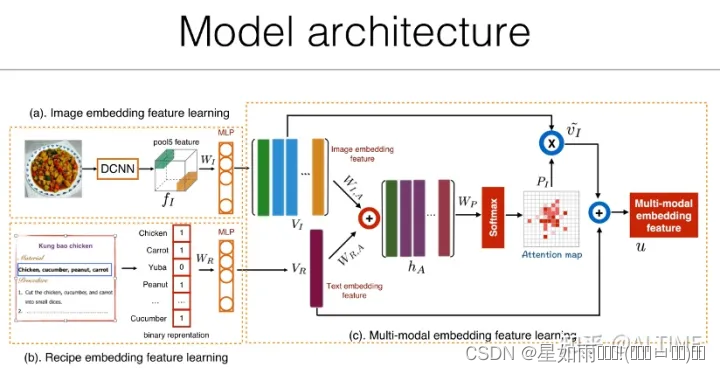
此后,一些研究者向跨模态食谱检索模型中引入了注意力机制模块。如上图所示,针对提取出图像中各区域的特征和食谱中的原料关键词,我们首先计算二者之间的相关性,重点突出于有较大概率包含原料关键词列表的视觉区域。接着,我们利用注意力图和文本嵌入特征学习多模态嵌入特征。通过计算该多模态嵌入特征与菜谱特征之间的相似度,我们就可以实现跨模态的菜谱检索。

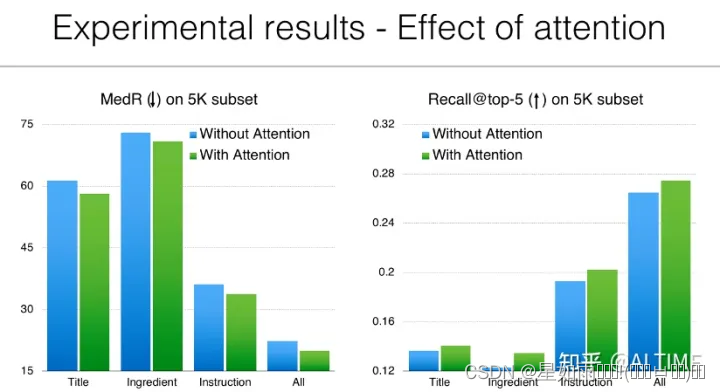
就损失函数而言,跨模态检索任务通常使用排序损失来优化模型。在构建输入三元组时,我们将查询图像作为 anchor,对菜谱采样得到正样本和负样本,通过优化使得查询图像与正样本之间的相似度大于查询图像与负样本之间的相似度。实验结果表明,通过引入注意力机制可以大幅度提升检索模型的准确率。

在 CVPR 2019 上,我们在论文「Cross-modal Recipe Retrieval with Generative Adversarial Network」中,通过使用 GAN 学习到更相容的跨模态特征,也可以通过展示根据食谱生成的图像来解释食谱检索的结果。
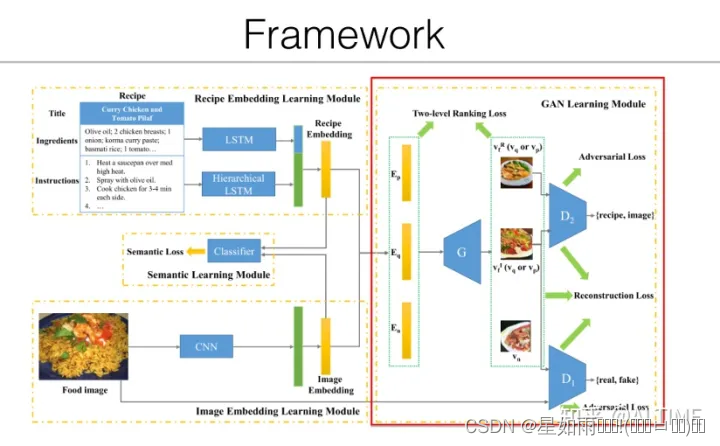
我们首先分别通过 CNN、LSTM、层次化 LSTM 提取图像、食谱标题和食材成分、烹饪说明的特征,通过语义损失函数分别优化食谱嵌入和图像嵌入。在 GAN 学习模块中,我们通过对抗损失来优化 GAN,使判别器无法区分来自于菜谱和来自图像的特征,同时通过重建损失使生成的图像与真实图像尽可能接近,最后我们使用两级排序损失使给定的食物图像和检索的菜谱尽可能相似。

实验结果如上图所示,利用联合子空间嵌入重建的图像与给定的查询图像相似度较高。本文提出的基于 GAN 的菜谱检索模型的性能在当时获得了最优的性能。
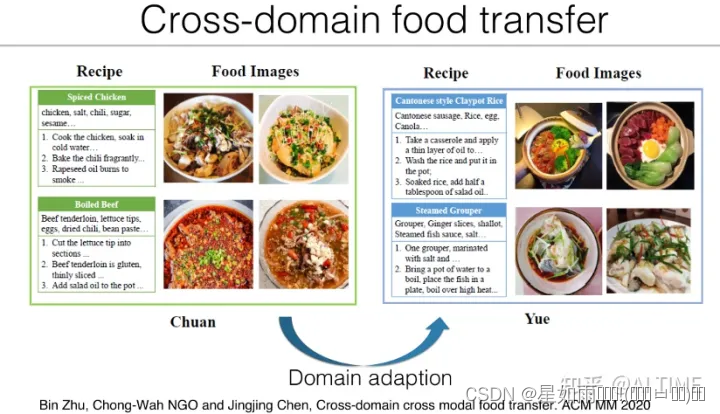
我们在 ACM MM 2020 发表的论文「Cross-domain cross modal food transfer」中讨论了跨模态菜谱检索任务下的跨域食物迁移问题。例如,将在川菜数据集上训练的模型迁移到粤菜检索任务上。
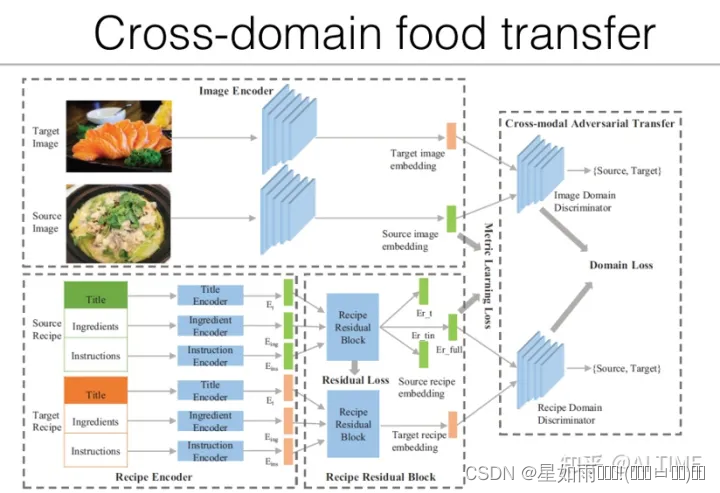
为了实现跨域食物迁移,我们采用了对抗迁移机制,引入了域判别器来判断学习到的嵌入究竟来自图像还是菜谱文本的域,从而让模型学习到与数据域无关的食物原始特征,弱化与数据域相关的特征。
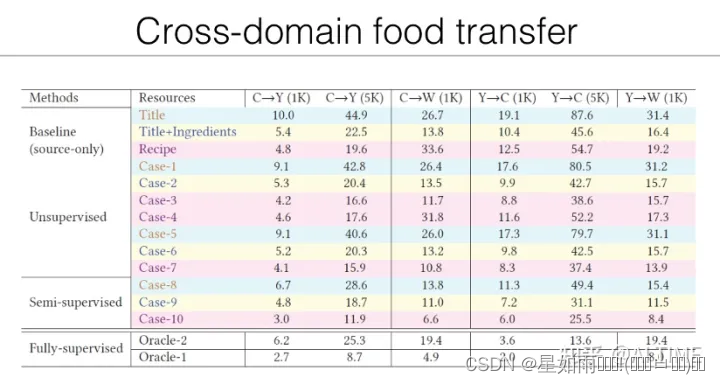
实验结果表明,相较于不存在 domain gap 的情况,跨域菜谱检索模型的性能仍然有所下降。或许可以尝试借助大规模预训练模型等新方法学习到更加通用的跨模态特征,提升跨域菜谱检索的性能。
本文介绍了基于识别的菜谱检索、基于跨模态学习的菜谱检索、跨域食物迁移等方面的相关工作。早期的基于识别的菜谱检索要求我们显式的标注食材,需要耗费大量的人力标注成本,难以处理无法在图片中观察到的食材原料和被遮挡的食材原料。基于跨模态学习的菜谱检索方法能够更好地扩展到大规模集上,需要的标注工作更少,可以得到更好的检索性能。未来,针对跨模态菜谱检索任务,我们期望进一步研究零样本的菜谱检索,使模型学习到泛化性更强的鲁棒特征,在无需在目标域上进行训练的情况下,直接将在源域上训练的模型应用于目标域。此外,我们还将尝试在菜谱数据上进行有针对性的大规模跨模态预训练。在食物计算领域中,如何有创造性地生成新的菜谱、如何根据输入菜谱生成相应的图像、如何估计食物的卡路里都是十分具有前景的研究方向。
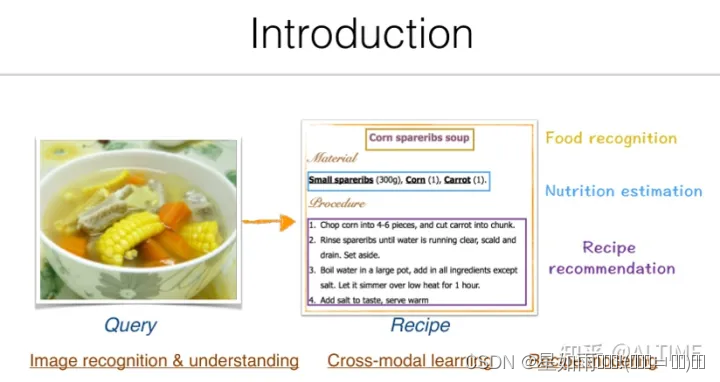
在「跨模态菜谱检索」任务中,给定一张菜品的图像作为模型的输入查询,模型需要检索出制作该菜品相应的菜谱,我们可以将该过程建模为「视觉-文本」的翻译。这项技术可以帮助我们进一步完成实物识别、营养成分估计、菜谱推荐等下游任务。从技术角度来说,「跨模态菜谱检索」任务要求我们首先识别菜品,再将输入图像与菜谱文本关联起来,并且针对结构化的菜谱文本学习高质量表征。因此,该任务涉及到图像识别与理解、跨模态学习、菜谱文本建模等研究领域。本文介绍了基于识别的菜谱检索、基于跨模态学习的菜谱检索、跨域食物迁移等方面的相关工作。
文献下载地址:CHEF: Cross-modal Hierarchical Embeddings for Food Domain Retrieval| Proceedings of the AAAI Conference on Artificial Intelligence
2021AAAI中国计算机学会CCF的A类国际学术会议
尽管有大量的多
模态
数据,例如图像-文本对,但在理解单个实体及其在这些数据实例的构建中的不同角色方面几乎没有努力。在这项工作中,我...
更新:博客文章现已发布。 有关更多信息,请访问!
例如用法,请访问此Jupyter Notebook:
Maturaarbeit 2018:这项工作利用Keras的深度卷积神经网络将图像分类为230种食物并输出匹配的食谱。 数据集包含来自chefkoch.de的> 400'000食物图像和> 300'000食谱。
几乎没有任何其他领域能像营养一样对人类福祉产生类似的影响。 每天,用户都会在社交网络上发布无数的食物图片; 从第一个自制蛋糕到顶级米其林菜肴,万一菜肴成功,您将与世界分享快乐。 事实是,无论彼此之间有多大差异,美食都会受到大家的赞赏。 个别烹饪原料的分类或对象
识别
方面的进展很少。 问题在于几乎没有公开编辑的记录。
该代码(Jupyter笔记本)提供了许多德语注释。 该过程如下所示:
1│──数据准备│└──清除数据│└──数据扩充
2│──数据分析和可视化,拆分数据(训练,有效,测试)
3│──使用简单ML模型的首次尝试│└──最近邻分类器(kNN) │└──k-均值聚类│└──支持向量机
研究图像特征检测已经有一段时间了,图像特征检测的方法很多,又加上各种算法的变形,所以难以在短时间内全面的了解,只是对主流的特征检测算法的原理进行了学习。总体来说,图像特征可以包括颜色特征、纹理特等、形状特征以及局部特征点等。其中局部特点具有很好的稳定性,不容易受外界环境的干扰,本篇文章也是对这方面知识的一个总结。
本篇文章现在(2015/1/30)只是以初稿的形式,列出了主体的框架,后面还有许多...
一、Faster-RCNN目标检测算法的介绍
Faster-RCNN 算法由于其较高的检测准确率成为主流的目标检测算法之一,相比较 YOLO系列算法,Faster-RCNN 速度方面略显不足,平均检测精度(mAP)很高,它将 region proposal
提取和 Fast-RCNN 部分融合进了一个网络模型 (区域生成网络 RPN 层)。
算法大概可以分为特征提取层,区域建议层(RPN),ROIpooling(池化)层,分类与回归四个部分。具体执行步骤如下:
(1)首先利用特征提取网络对输入进行特征提取
笔者前两年对接过一些大厂的菜品
识别
SDK,后经过大量测试,发现跟实际应用中还是存在一些差距,后来通过新的算法实现了AI
图像识别
自动化收银系统(以下简称AI收银系统)的商业产品规模化,并陆续落地了一些项目。
该AI收银系统采用C#语言开发,并基于WPF客户端应用框架,进行了一系列
图像识别
相关的技术应用,经过反复调试和测试,性能已达到最佳,能7x24小时保持正常工作状态。
菜品
识别
关键接口调用代码:
将摄像头传入的视频帧经过base64转换后发送到
识别
算法服务器,
识别
算法拿到图片后首先提取菜品特征,再
LCR食谱
检索
数据集是一个包含大量食谱信息的数据集,可以用于开发食谱
检索
系统和进行食谱相关的研究。
这个数据集中包含了各种不同类型的食谱,如早餐、午餐、晚餐、甜点等,以及各种菜系的食谱,如中餐、西餐、日餐等。每个食谱的数据项包括食谱名称、食材、调料、制作步骤等信息。
使用LCR食谱
检索
数据集可以有很多应用。首先,我们可以使用该数据集来开发一个食谱搜索引擎,用户可以根据自己的需求输入关键词,搜索符合条件的食谱。比如,用户可以输入“蔬菜沙拉”,系统将返回所有包含蔬菜沙拉的食谱。
此外,该数据集还可以用于进行食谱相关的研究。研究人员可以利用数据集中的食材和食谱信息,分析人们的饮食习惯和偏好,以及不同菜系的特点。这些研究成果有助于我们了解人们的饮食文化,并为制定健康饮食方案提供科学依据。
总之,LCR食谱
检索
数据集是一个丰富的食谱信息资源,可以在食谱
检索
系统开发和食谱研究中发挥重要作用。通过利用这个数据集,我们可以方便地搜索到适合自己口味和需求的美食。