


高健:Python办公自动化——Pandas和Openpyxl强强联合,联手打造批量处理Excel绝佳武器!


恭喜你,发现了宝藏!
一、业务描述
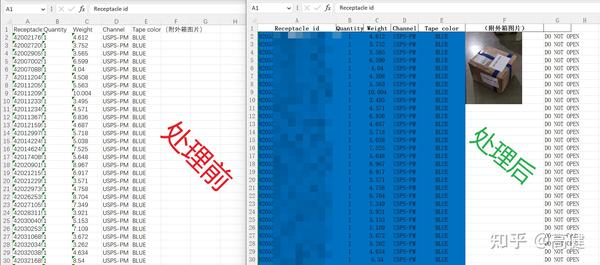
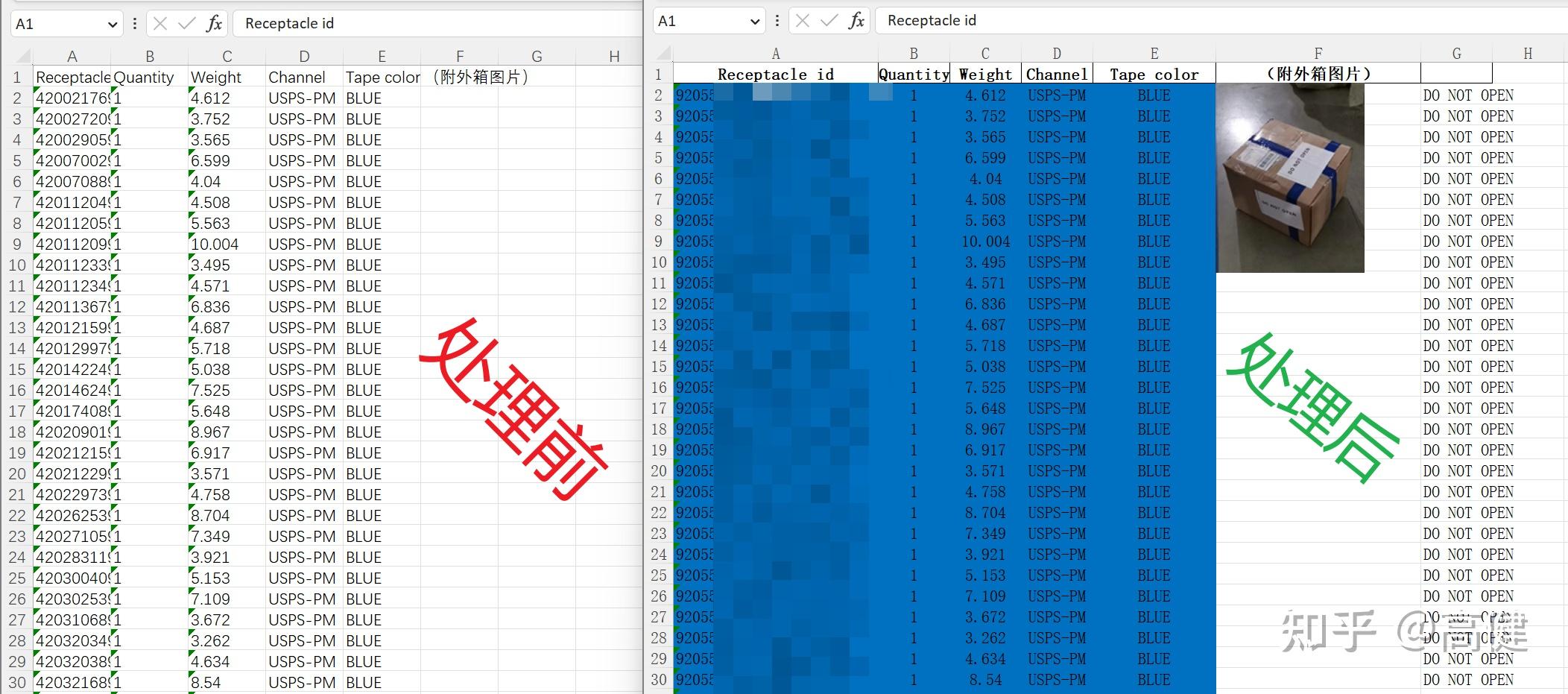
从快递平台导出原始Excel文件,再根据Excel中的信息,进行数值填充、格式优化、颜色填充、插入包装图片。
二、需求描述
A列:Receptacle id(唛头/袋号):长度为30个字符的,从右向左保留22个字符;非30个字符的保留原数据;数据验证,包含两个“-”的为合法数据,未包含两个“-”的为非法数据,设置红色单元格底色,提示人工辅助审核。
B列:Quantity(大件数):转换为数字格式,居中显示
C列:Weight(毛重):转换为数字格式,居中显示
D列:Channel(渠道):居中显示
E列:Tape color(胶带颜色):居中显示
F列:(外箱图片):
-
①.E列【胶带颜色】为“BLUE”且A列长度为22个字符的,使用图片:Blue_22.png
-
②.E列【胶带颜色】为“BLUE”且A列长度为非22个字符的,使用图片:Blue_not22.png
-
③.E列【胶带颜色】为“BLACK”的,使用图片:Black.png
-
④.E列【胶带颜色】为“GREEN”的,使用图片:Green.png
-
⑤.E列【胶带颜色】为“WHITE”的,使用图片:White.png
G列:A列长度为22个字符的,G列为“DO NOT OPEN”;A列为非22个字符的,G列为空
合计行:删除此行信息


想想,如果不用代码,人工可以实现吗?
三、技术选型
看完业务,很好理解。人工处理,也太好实现了,只要会打字,会按delete, 会改单元格背景颜色,会插入图片,任何一个刚接触Excel的人,都能在短时间内快速昨晚。可每天要是处理10多个甚至更多这样的Excel文件,那就很上头了。
在当今的信息社会,数字化已经渗透到生活的方方面面。在职场环境中,我们通常需要处理大量的数据和信息。做表,也是打工人在职场中高频且普遍的环节。只是随着要处理的表越来越多,传统的人工处理方式已经无法满足现在的工作需求,效率低下且容易出错。此时,办公自动化技术宛如一位握有利剑的战士,一剑断开那缠绕、束缚着我们的铁链,让我们留出更多的时间,去做更值得做到事。
Python中的Pandas和Openpyxl库,为我们处理Excel文件提供了强大的工具。
- Pandas: 这个库在数据操纵和分析方面表现优秀。它提供了从各种文件格式(包括Excel)中读取数据的函数。Pandas在过滤数据、汇总数据、处理缺失值和执行其他数据转换任务方面,特别有用。Pandas的数据帧对象,使用起来快速方便,且功能十分强大。
- Openpyxl: 这个库也允许我们直接处理Excel文件:从中读取、写入、修改数据。Pandas快,但Pandas做不了的事,让Openpyxl来做,例如单元格注释、填充背景色、填充图片和其他格式特性。
这种典型的用办公自动化的场景,可以结合Pandas+Openpyxl两个库的特性,取各自的长处,用Pandas读取和输出Excel文件,用Openpyxl填充格式。
四、代码处理思路
虽然业务需求看似繁杂,但其实整体的流程设计非常清晰。
首先,我们从数据输入和输出的两个端点入手,即读取和输出Excel文件。这是任何办公自动化任务的通用步骤,始终以输入和输出为起始点,无疑是最佳的策略。
接下来,我们将焦点转向核心部分。先着手处理数据,然后再关注样式的调整。一般来说,对于数据处理的需求,会多于样式处理的需求。
经过分析,发现一共四步,读Excel文件,处理数据,输出Excel文件,处理输出Excel文件的样式。
流程固定下来之后,我们就可以用面向对象的风格,对这四步分别进行模块化处理,这样以后当需求发生变动,或有类似的需求出现时,就可以更方便的进行修改。
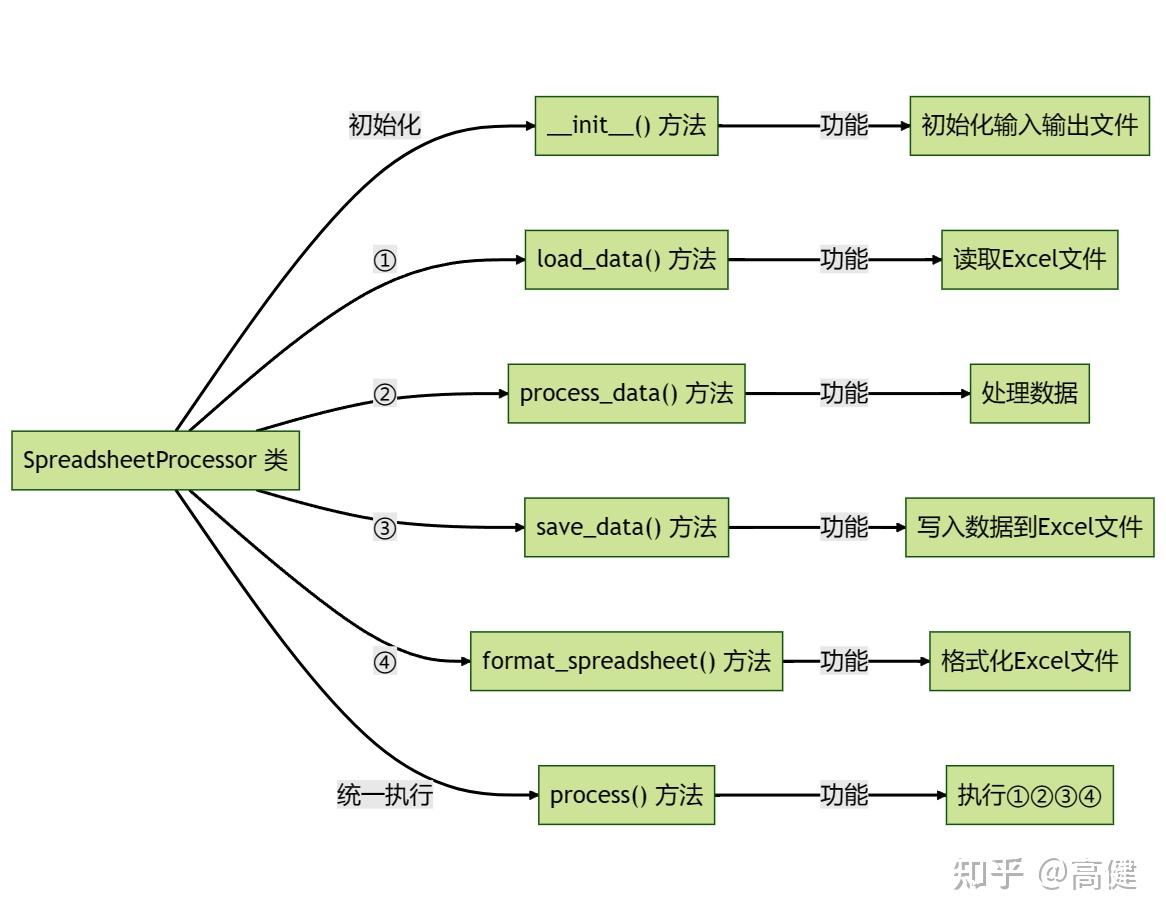
因此,定义一个的类,分别写四个方法,最后再写一个方法,按顺序执行这四步,用于处理Excel表格。
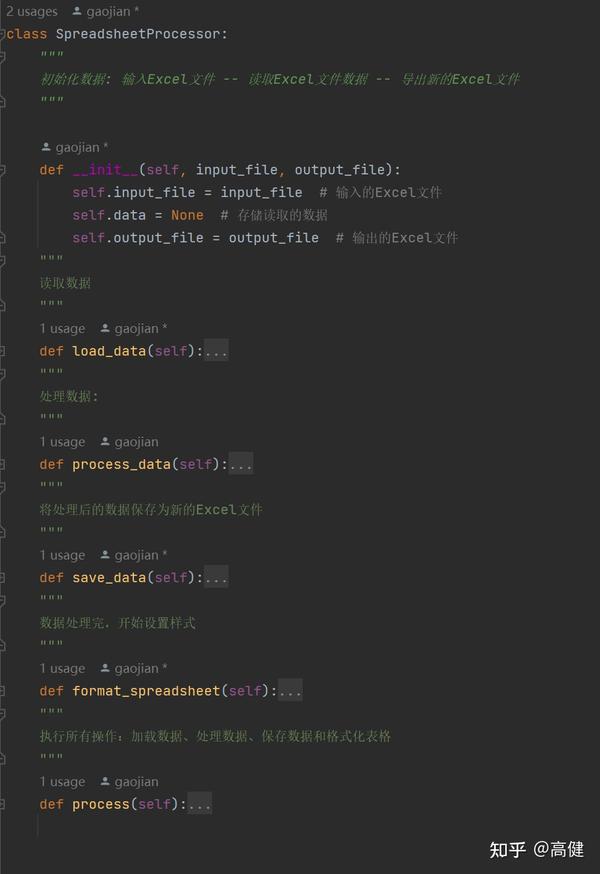

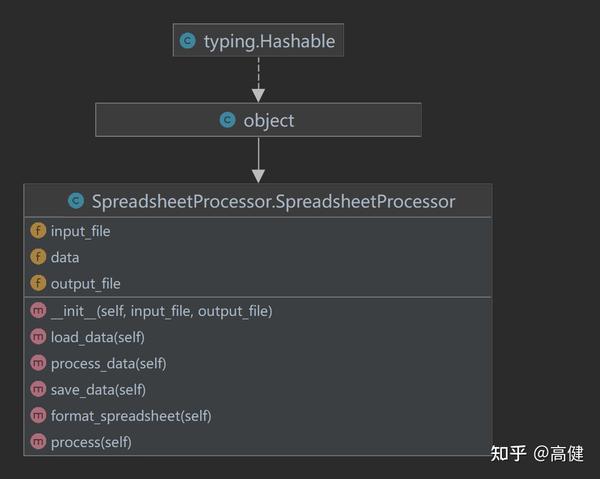
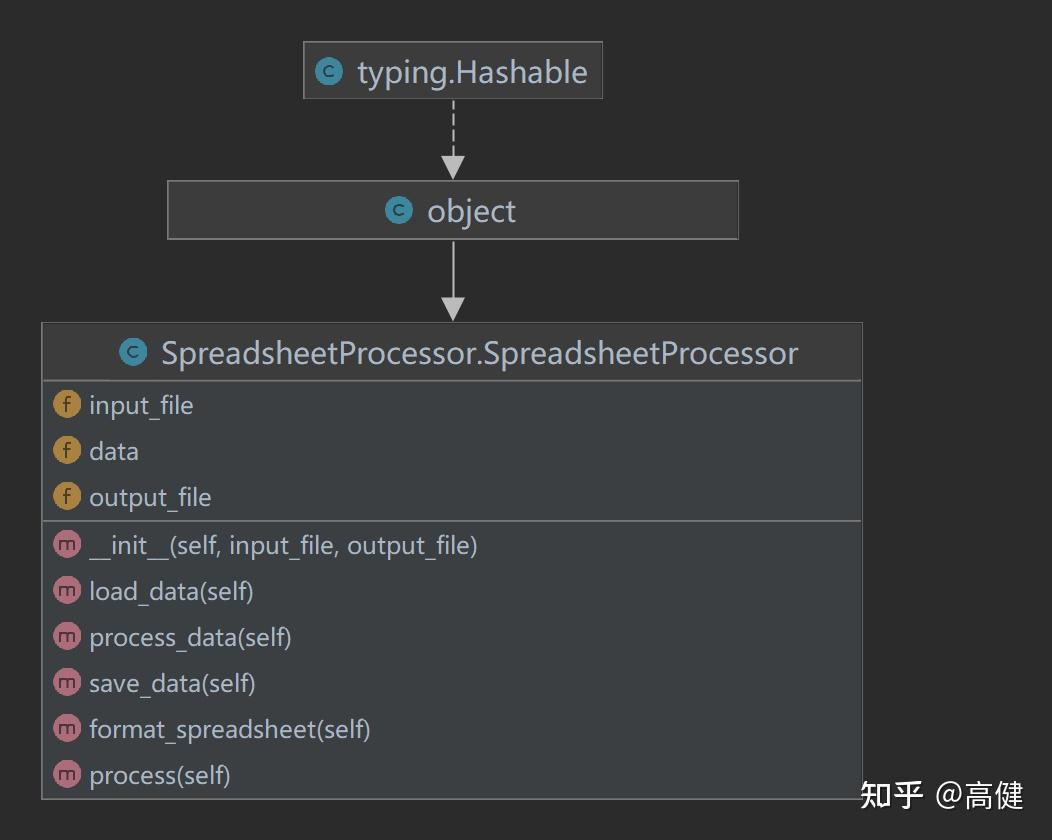
这里要对类,先做一个鸟瞰:
SpreadsheetProcessor
类解析
SpreadsheetProcessor
类是我们创建的一个自定义类,负责读Excel文件,处理数据,输出Excel文件,处理样式。
在这个类中,我们把思路注意转换为方法,包括加载数据、处理数据、输出Excel文件、处理样式。通过这个类,我们可以轻松地完成对Excel文件的处理。
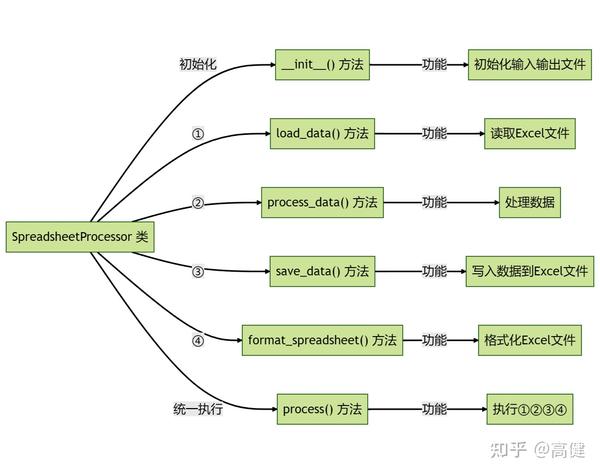
该类的主要方法:
-
__init__(self, input_file, output_file):类的构造函数,负责初始化输入和输出的Excel文件路径。 -
load_data(self):利用pandas的read_excel方法,读取Excel文件内容。 -
process_data(self):对读取的数据进行预处理,包括删除不需要的行,对特定列的值进行处理,以及将某些列的数据类型进行转换。 -
save_data(self):将处理后的数据保存为新的Excel文件。 -
format_spreadsheet(self):利用openpyxl库,对新的Excel文件进行样式设置,如设置单元格的颜色、添加图片等。 -
process(self):将上述方法整合在一起,实现一键完成所有操作。
图片看起来,会更清晰些(使用mermaid绘制)。
在进行类和方法的命名时,我们必须遵循规范。严格的规则不容违反,而具体的规范会根据公司的要求或个人的习惯进行调整,关键是要保证命名清晰易懂,避免产生歧义。对于开发者来说,常常翻阅字典以寻找恰当的命名,是个好习惯。根据词典释义,这里我就把该类命名为:SpreadsheetProcessor。
五、类的内部详细解读
划分好流程后,开始对方法进行逐一编写。
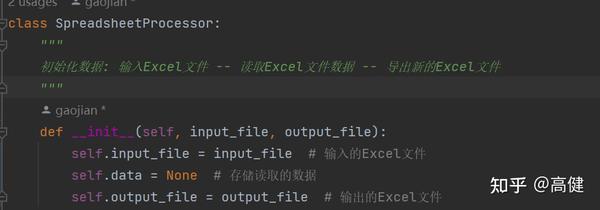
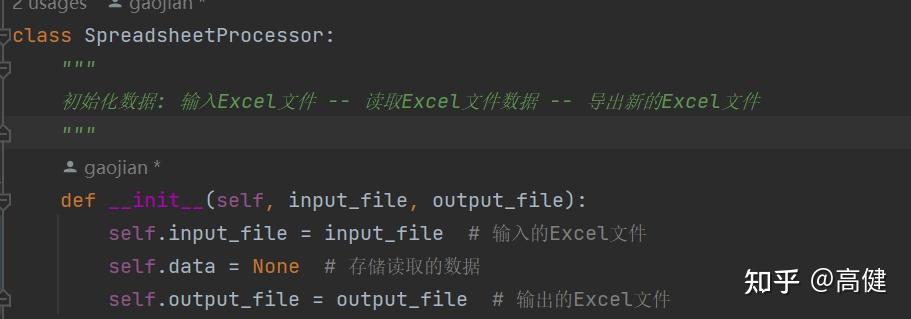
⓪构造函数(易):
"SpreadsheetProcessor类的
__init__
方法,是它的构造方法,在创建类的实例时,自动执行。
该方法接受两个参数:输入文件名
input_file
和输出文件名
output_file
。
这两个参数被保存为类实例的属性,后续在数据读取、处理和写入过程中都会用到。
同时,这个方法也初始化了一个名为
self.data
的属性,用来存储我们从原始的Excel文件中读取的数据。
①读取Excel数据(易):


SpreadsheetProcessor 类的
load_data
方法,该方法只有一行代码,但是很重要。负责从输入的Excel文件中读取数据。
这个方法会首先调用 pandas 库的
read_excel
函数,将输入文件的路径作为参数。
read_excel
函数会将Excel文件转换为一个 pandas 的 DataFrame 对象。
然后,这个方法将读取的数据赋值给
self.data
属性,使得我们可以在类的其他方法中,使用这个属性来访问和处理数据。
②处理数据(易):
“洗菜!”
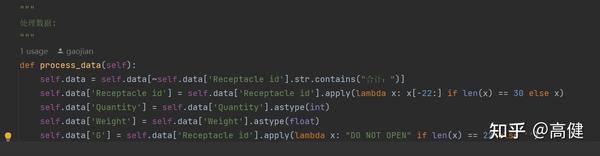
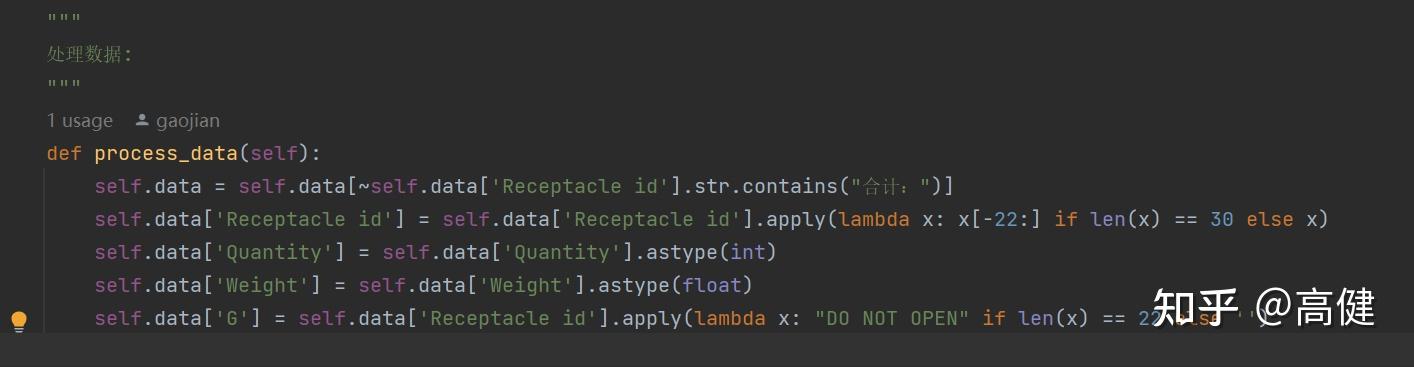
SpreadsheetProcessor 类的
process_data
方法主要负责对从 Excel 文件中读取的数据进行预处理,这个函数里,用Pandas中的函数进行处理。
首先,这个方法过滤掉 'Receptacle id' 列中含有 "合计:" 的行。
这里有一个小的语法知识点。
~
:波浪号是 Python 中的按位取反操作符,当用在布尔类型的 pandas Series 上时,它表示逻辑取反,在Pandas中应用比较多,用来过滤数据。
self.data['Receptacle id'].str.contains("合计:")
返回一个布尔值的 Series,表示 'Receptacle id' 列的每个元素是否包含 "合计:"。然后,
~
操作符将这个布尔值取反,即原来是 True 的变成 False,原来是 False 的变成 True。
self.data[...]
:这是 pandas 使用布尔索引(Boolean Indexing)选取 DataFrame 中的数据的方法。在方括号中传入一个与 DataFrame 长度相同的布尔值的 Series,pandas 将返回所有对应 True 值的行。
所以
self.data[~self.data['Receptacle id'].str.contains("合计:")]
就会选取 'Receptacle id' 列的值不包含 "合计:" 的所有行。
接着,如果 'Receptacle id' 的长度为 30,那么就取它的最后 22 个字符;如果长度不是 30,那么保留原值。然后,将 'Quantity' 和 'Weight' 列的数据类型分别转换为整数和浮点数。


这里要将业务语言转换成代码语言,看看那些是对数据处理,那些是对格式处理,把数字格式转成Python代码中具体的数据类型。


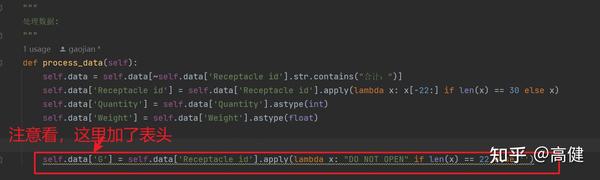
最后,如果 'Receptacle id' 的长度为 22,那么 'G' 列的值设置为 "DO NOT OPEN";否则,设置为空字符串。
这样,我们就得到了处理后,适合后续操作的数据。
菜洗干净了,就可以下锅了。
③保存数据(易)
“下锅!”
当我们的数据处理完成之后,下一步就是将这些数据保存起来。
SpreadsheetProcessor 类的
save_data
函数,在这段代码中,用来保存清洗好的数据。
输入和输出(I/O),是一对好兄弟,该方法依旧只有一行。


在 Python 中,我们可以使用 pandas 提供的
to_excel
函数轻松地将数据保存为Excel文件。
self.data
是我们之前处理过的数据,
self.output_file
是我们要保存文件的路径。
index=False
, 表示我们在保存文件时不包括索引列。这样,我们就能够将处理后的数据保存为一个新的 Excel 文件了。
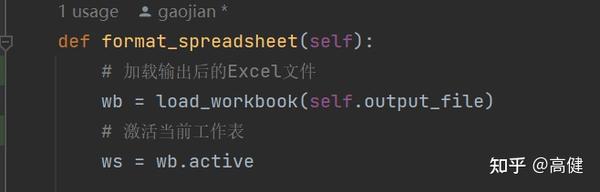
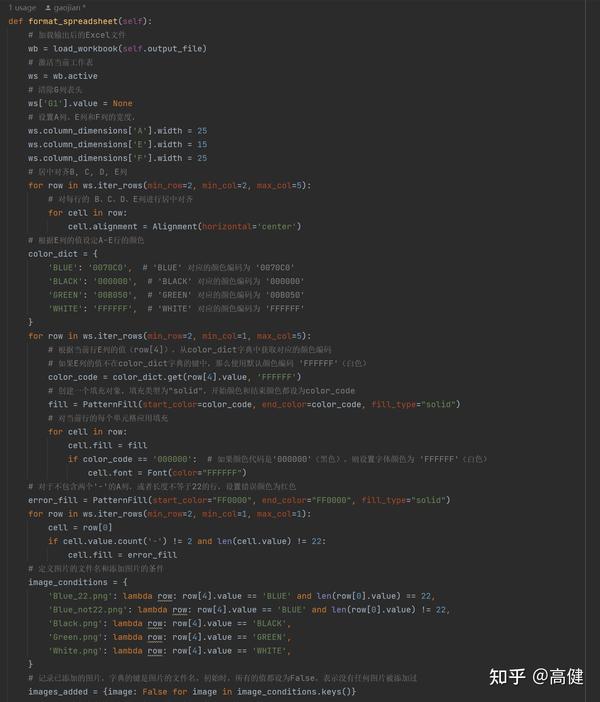
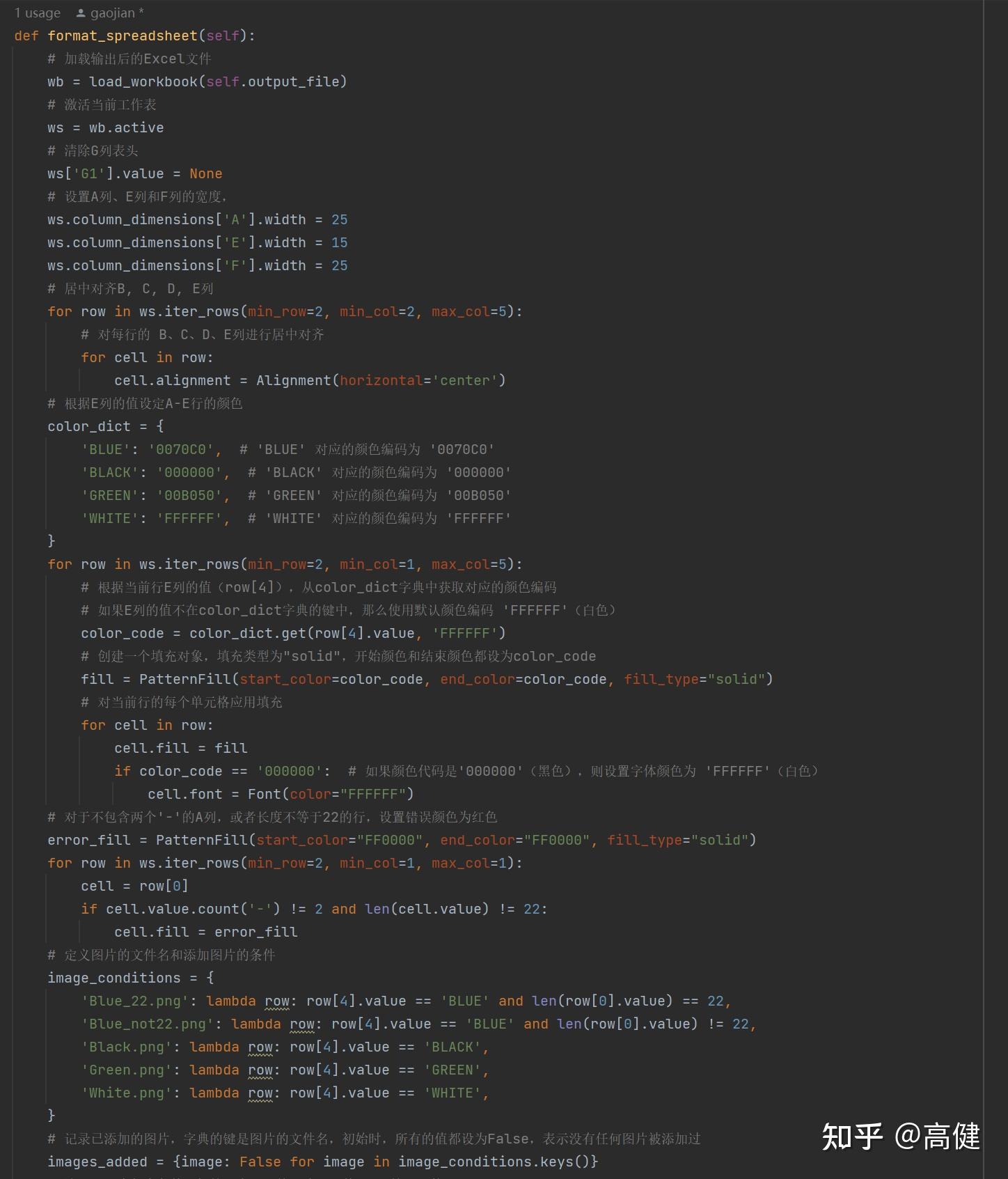
④处理样式(重头戏):
SpreadsheetProcessor 类的
format_spreadsheet
函数,该函数要使用openpyxl进行处理。它的作用主要是对生成的 Excel 文件进行格式化处理,包括设置列宽,居中对齐某些列,根据某一列的值设置行的颜色,对于不符合要求的单元格设置错误颜色,以及在符合条件的行中添加图片。
首先,我们加载了生成的 Excel 文件,并激活了当前工作表,这是Openpyxl最常见的读取数据的方式。

然后,我们清除了 G 列表头的值,并设置了 A 列、E 列和 F 列的宽度。这一步需求上没写,但是作为开发, 我们要看到用户看不到的。原本的表,G列是没有表头的。因为Pandas在G列写“DO NOT OPEN”时,必须写上表头,所以在这一步,要把当时加上的表头去掉。
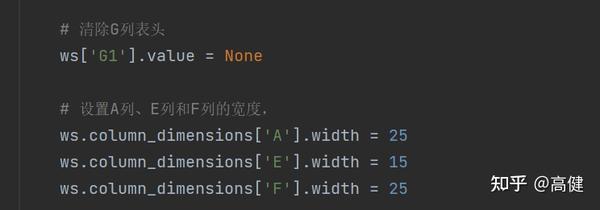
设置列的宽度,是为了用户体验,让A 列、E 列和 F 列的数据显示全。
在进行了这些基础设置之后,我们进一步将 B、C、D、E 列的值进行了居中对齐,并根据 E 列胶带颜色的值,设定整行的颜色。
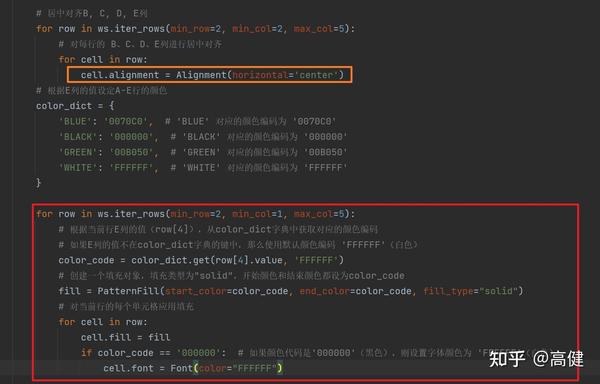
这段代码主要完成了两个功能,一是设置 Excel 文件的 B、C、D、E 列的对齐方式,二是根据 E 列的值来设定 A-E 行的颜色。
第一,
ws.iter_rows(min_row=2, min_col=2, max_col=5)
用于遍历工作表 ws 中的每一行,其中参数
min_row=2, min_col=2, max_col=5
表示从第2行开始,第2列(即 B 列)到第5列(即 E 列)。然后,通过循环
for cell in row
,遍历这些行中的每一个单元格。在每个单元格中,都将
Alignment(horizontal='center')
赋值给
cell.alignment
,这样就设置了单元格的对齐方式为居中。
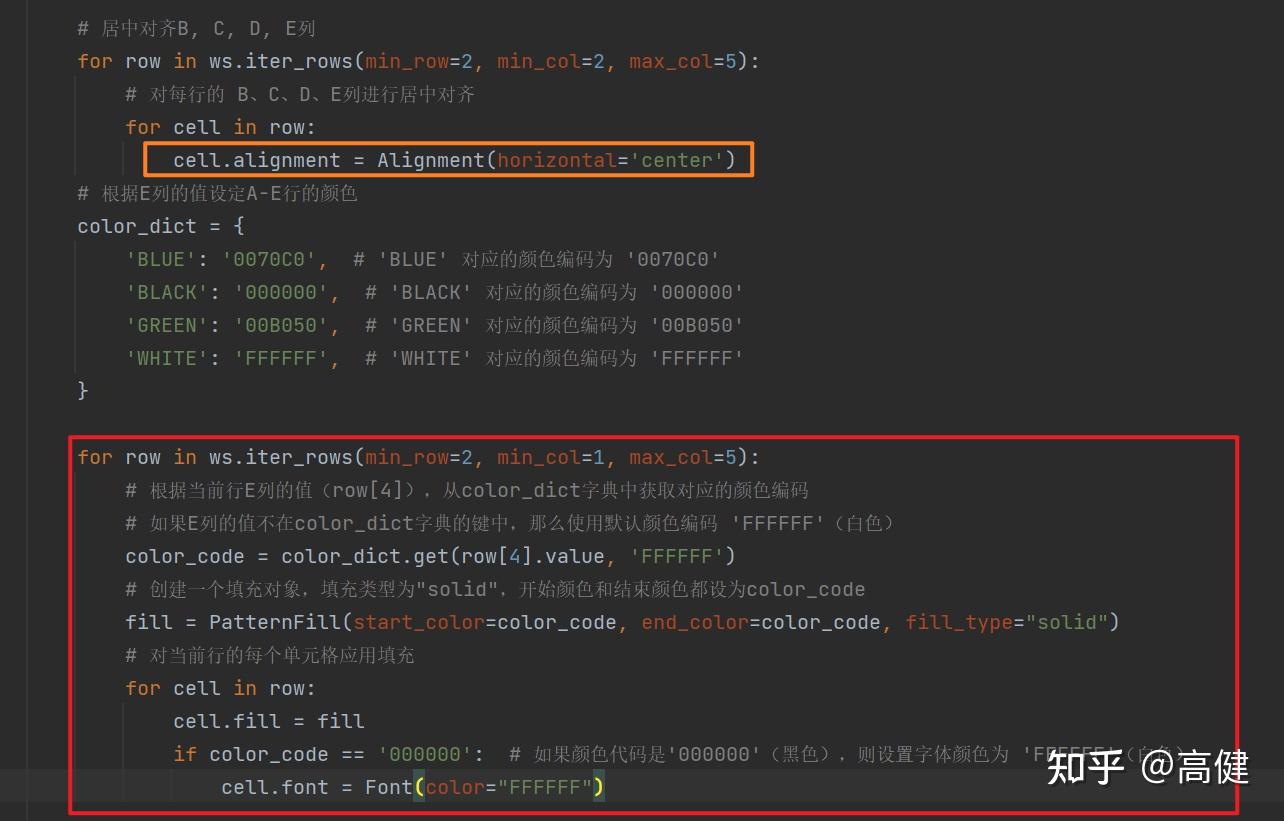
第二,是设定 A-E 行的颜色。
首先,定义一个字典
color_dict
,它的键是颜色的名称(例如 'BLUE'、'BLACK'等),值是对应的业务人员提供的RGB颜色编码,注意,这里不需要加#。
接着,使用
ws.iter_rows(min_row=2, min_col=1, max_col=5)
遍历从第二行开始,第1列(即 A 列)到第5列(即 E 列)的每一行。在遍历的过程中,根据 E 列的值(即
row[4].value
),从
color_dict
中获取对应的颜色编码。如果 E 列的值不在
color_dict
的键中,那么使用默认颜色编码 'FFFFFF'(白色)。
然后,创建了一个填充对象
fill
,填充类型为"solid",开始颜色和结束颜色都设为
color_code
。接着,在每一行中的每个单元格中应用这个填充。如果
color_code
为 '000000'(即黑色),则设置单元格的字体颜色为 'FFFFFF'(即白色)。
这是 Python 语言以及 openpyxl 库的基本语法和用法,也是在处理 Excel 文件时常用的技巧。
接下来,我们对于不包含两个'-'的A列,或者长度不等于22的行,设置错误颜色为红色。




语法上,这里我们使用openpyxl的PatternFill类,用于设置 Excel 单元格的填充样式。该类的实例化对象可以赋给单元格的
fill
属性,从而改变该单元格的填充样式。
在
PatternFill
中,我们定义了以下参数:
-
start_color:填充的起始颜色。这里是 "FF0000",表示红色。 -
end_color:填充的结束颜色。如果填充样式需要渐变,那么结束颜色可以与起始颜色不同。这里同样是 "FF0000",也表示红色。 -
fill_type:填充类型。这里是 "solid",表示纯色填充,也就是说,填充的颜色在单元格中是均匀的,没有渐变和图案。
这段代码
error_fill = PatternFill(start_color="FF0000", end_color="FF0000", fill_type="solid")
,创建了一个
PatternFill
对象
error_fill
,该对象表示纯色红色填充。然后,可以将
error_fill
赋给某个单元格的
fill
属性,使该单元格显示红色填充。
如
cell.fill = error_fill
这行代码就是把定义好的
error_fill
赋值给
cell.fill
,即把该单元格填充成红色
最后,我们根据设定的条件,在符合条件的行的 F 列中添加了图片,并保存了工作簿。


填充图片的代码实现,逻辑类似于填充颜色,都要先创建一个字典,前面是值(图片),后面是添加值(图片)的条件。
只不过这里图片是只插入一次。
这个逻辑,和梦开始的地方--LeetCode第一题--两数之和的实现逻辑,是很相似的。两者都使用了哈希表(字典)来跟踪某些元素是否满足某种条件,然后我们根据这个条件来做出相应的操作。这种策略在编程中很常见,通过空间换时间,使用哈希表,快速查询某个元素是否存在。看来,刷算法题 ,还是有些用的。
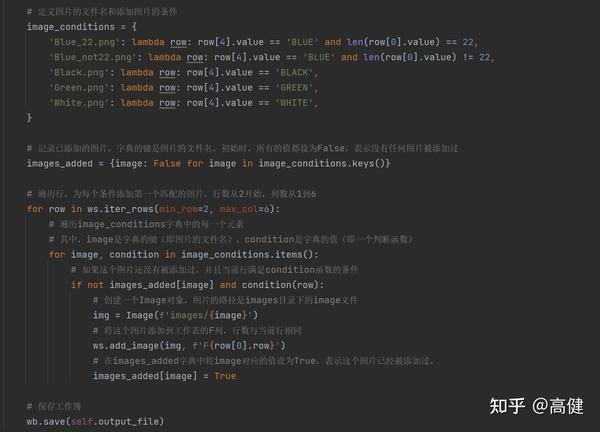
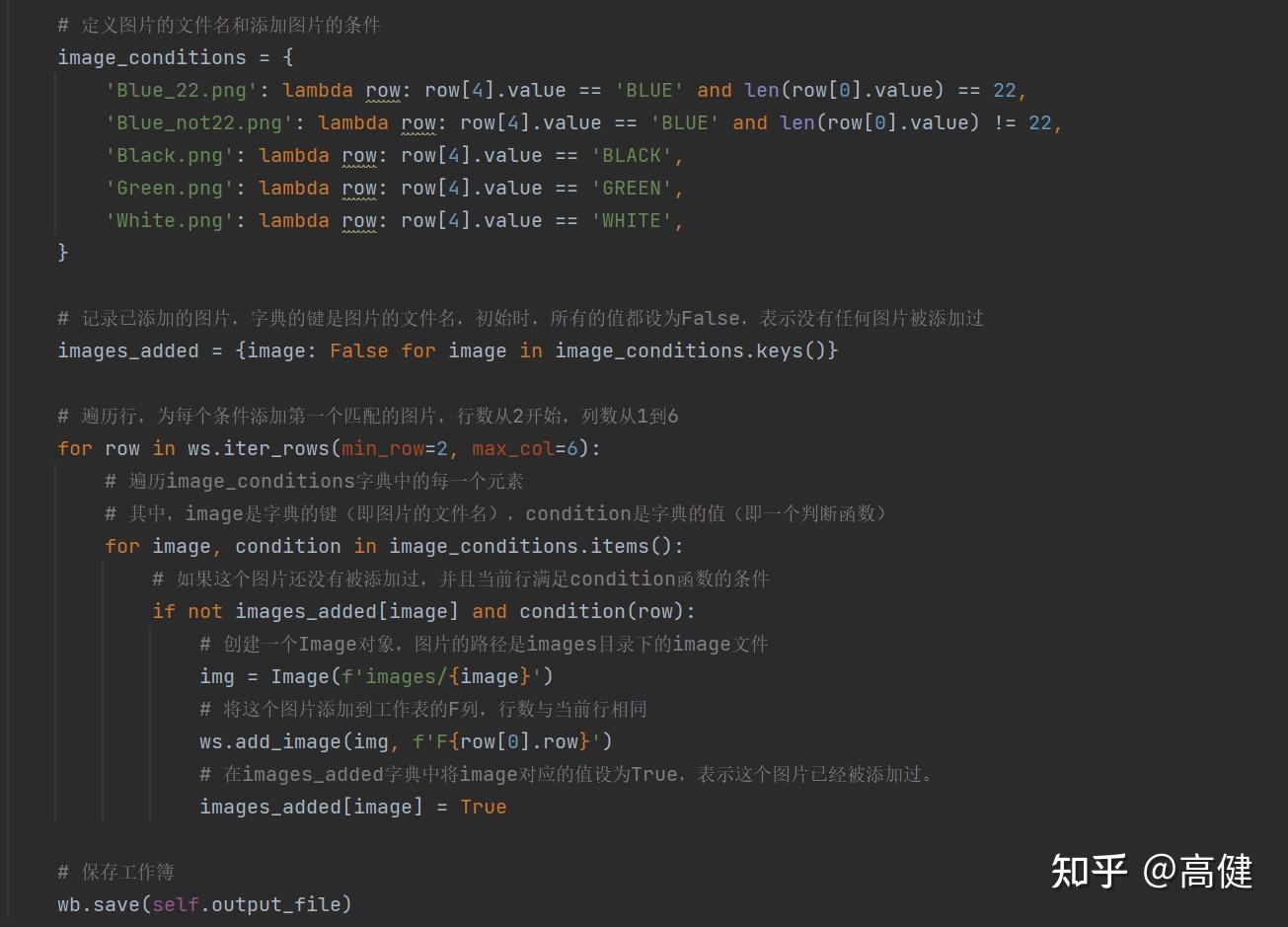
在这里,我们使用了
openpyxl
库的
iter_rows
、
add_image
和
save
方法来操作 Excel 工作表。
如下:
-
ws.iter_rows(min_row=2, max_col=6):这个方法用于遍历工作表中的行,min_row参数指定开始的行数,max_col参数指定结束的列数。
-
ws.add_image(img, f'F{row[0].row}'):这个方法用于将图片添加到工作表的指定位置,第一个参数是Image对象,第二个参数是图片的位置。
-
wb.save(self.output_file):这个方法用于保存工作簿,所有对工作表的修改才能生效。
这里的核心操作是插入图片,是openpyxl的Image,其用来表示一个图像文件,我们通过add_image方法,把这个图像对象插入到Excel工作表中。
到这里,设置样式的处理逻辑,就写完了,看着挺长的,其实逻辑并不复杂。
这个代码的颗粒度,还是挺粗的,这个方法干的事挺多,包括:
-
加载和激活工作簿
-
修改列的宽度
-
设置单元格的对齐方式
-
根据规则改变单元格的颜色
-
根据规则添加图片
这种写法看个人的代码风格了,对于这种情况,我平常的习惯是将其中一些逻辑,再拆分或抽象为多个的单独的小函数,例如
set_column_widths
、
align_cells
、
color_cells_based_on_value
和
add_images_based_on_conditions
。每个函数只做一件小事,这样会提高代码的可读性和可维护性,也可以使代码更易于测试。这里为了不让文章琐碎,我就不拆了。
⑤依次执行(易)
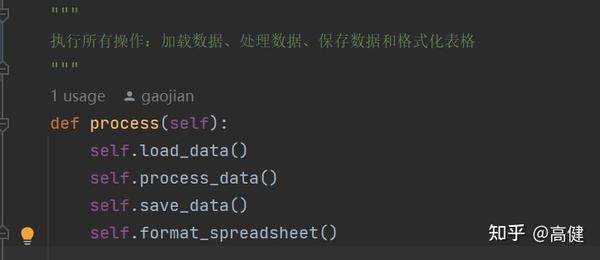
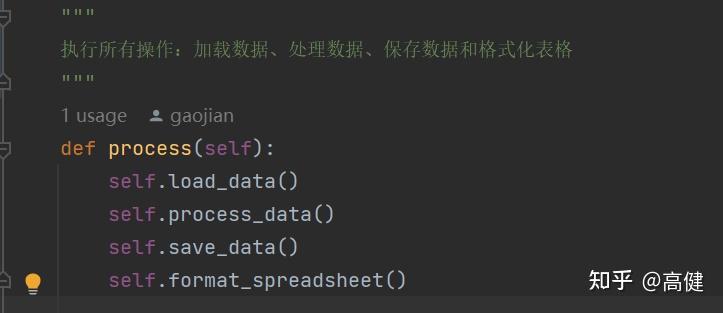
SpreadsheetProcessor 类的
process
函数,清晰地描述了数据处理的四个主要步骤:
第一,它调用
self.load_data()
来加载需要处理的数据。
第二,数据加载完成后,函数将调用
self.process_data()
来处理数据。
第三,
self.save_data()
被调用来保存处理后的数据。
最后,函数使用
self.format_spreadsheet()
来对结果数据进行格式处理,这调整单元格的大小、颜色或者添加图片等操作。
六、在主函数中进行调用
在主函数中,就比较简单了,一句话,调用就完事了。
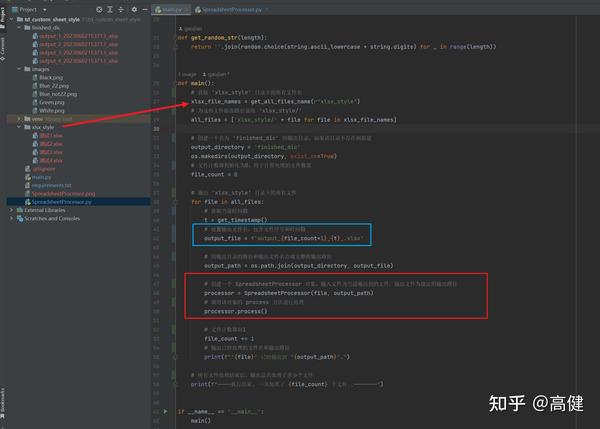
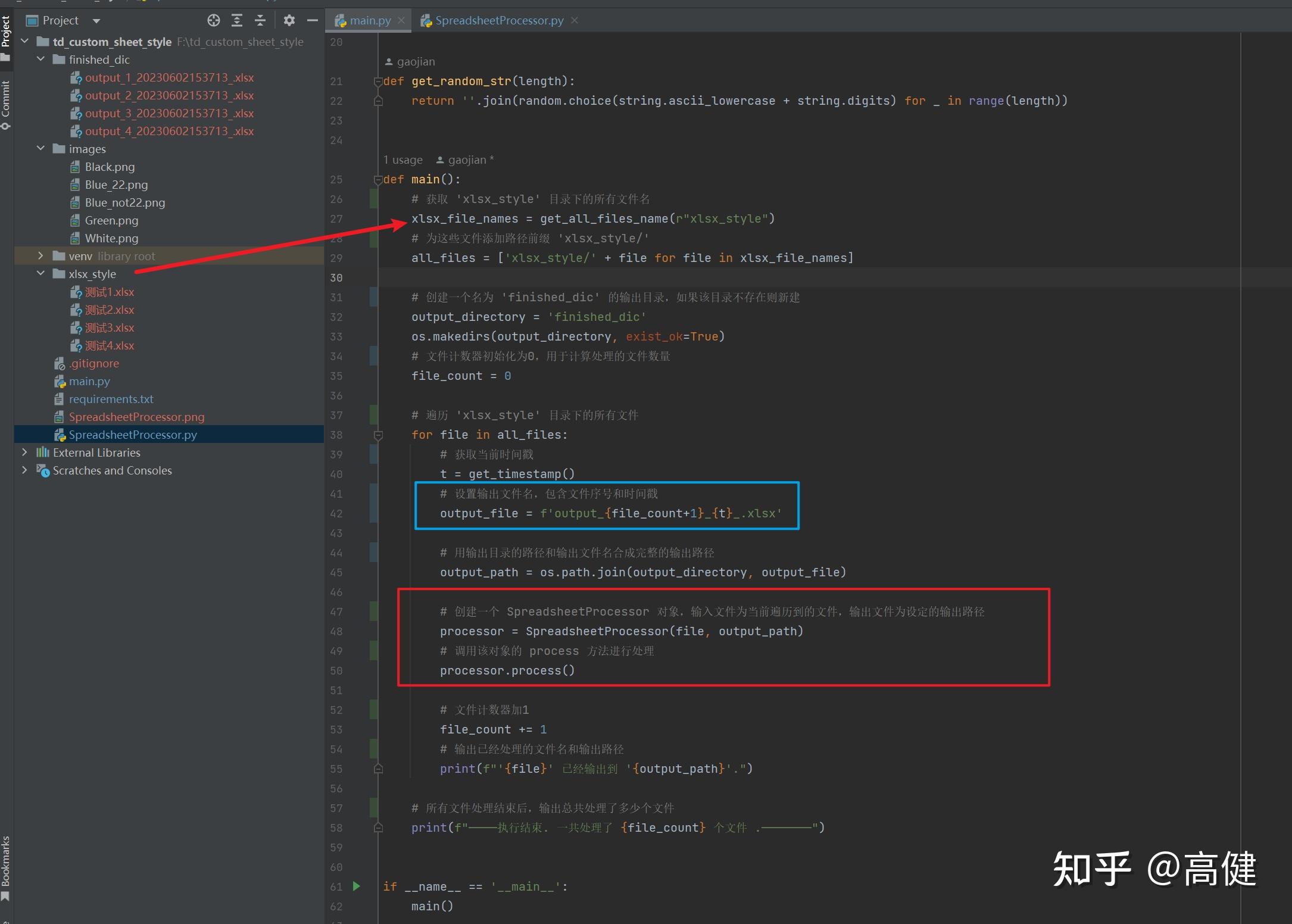
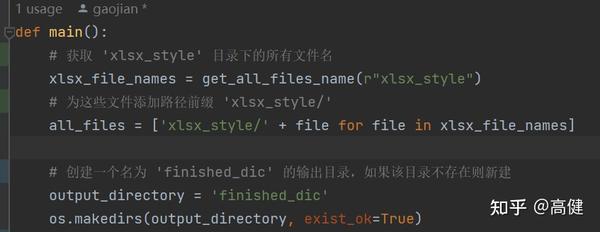
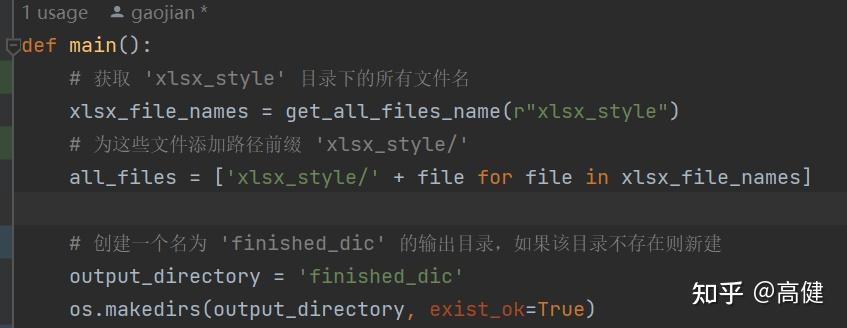
首先,函数通过调用
get_all_files_name(r"xlsx_style")
,这个辅助函数是单独写的。
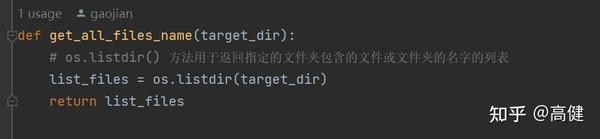

用来获取 'xlsx_style' 文件夹下的所有文件名。
然后,通过添加文件路径前缀 'xlsx_style/',拼接一个完整路径的文件列表
all_files
。
接下来,函数设定了输出文件的目录为 'finished_dic',并通过
os.makedirs(output_directory, exist_ok=True)
来保证该目录存在。如果 'finished_dic' 目录不存在,该函数将自动创建它。
随后,函数开始遍历 'xlsx_style' 文件夹下的所有文件。对于每一个文件,函数首先获取当前时间戳,然后生成一个包含文件序号和时间戳的输出文件名。在设定了输出文件的路径之后,函数创建了一个
SpreadsheetProcessor
对象,并调用其
process()
方法进行文件处理。


文件处理完成后,函数将文件计数器加一,然后输出一条消息,提示用户当前文件已被成功处理并保存到指定的路径。最后,在所有文件都处理完毕后,函数输出一个消息表示处理任务已经完成,并显示总共处理了多少个文件。
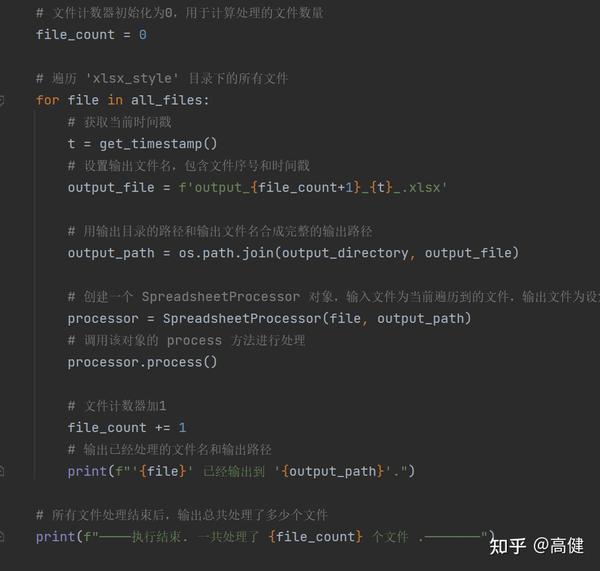
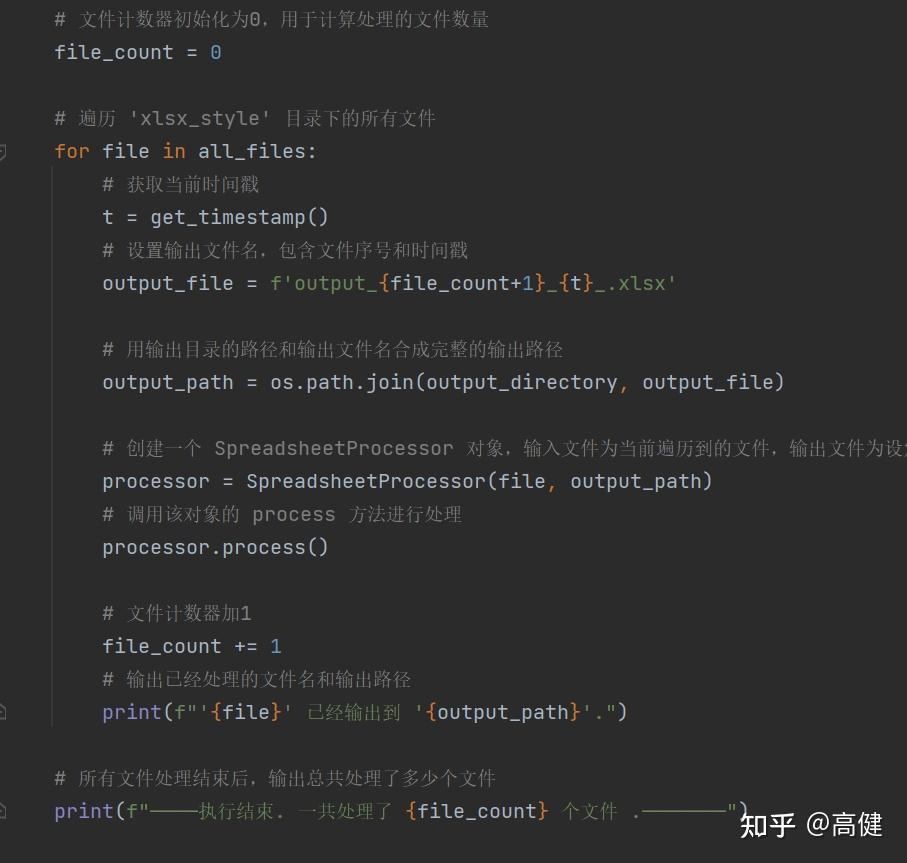
这里输出文件的名称,有两点需要注意的地方,一是加时间戳,让文件名带有时间信息,方便排序,方便测试。
第二,是加随机字符串或序号,程序执行的速度很快,如果只有时间戳,可能会一秒钟处理多个文件,导致文件覆盖。随机字符串可以解决这个问题,但是可读性不佳,所以我这里是用了file_count这个变量记录执行文件的数量,放到文件名中间。
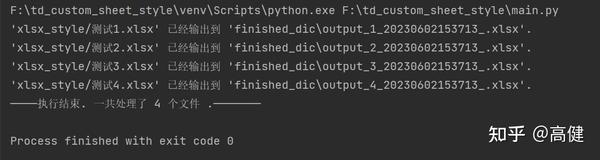
这个main函数,是一个典型的批量文件处理函数,它通过自动遍历文件夹、生成输出文件名和路径、创建文件处理对象以及调用处理方法,实现了对大量文件的高效处理。
main() 函数开始了,这篇文章结束了。
七、总结
通过Python的办公自动化,我们可以轻松地处理Excel文件,大大提高工作效率,减轻人工负担。
虽然这个例子中只是进行了一些基本的数据处理和样式设置,我尽可能用详细的注释、通俗的语言,一行不差的代码,展示整个程序的全貌以及我制作的思路。通过Python的丰富库,我们可以进行更复杂的数据处理和分析,以及更丰富的样式设置,实现更多的办公自动化需求。
Python办公自动化不仅可以用于处理Excel文件,也可以用于处理Word、PDF等其他类型的文件,更可以用于邮件发送、网络爬虫、数据分析等多种任务。希望通过这篇文章,读者可以了解到Python办公自动化的强大能力,开始学习并使用Python,用科技来解放双手和大脑,把时间留给风花雪月,留给更有价值的事。
补充代码中用到的几个封装好的小函数:
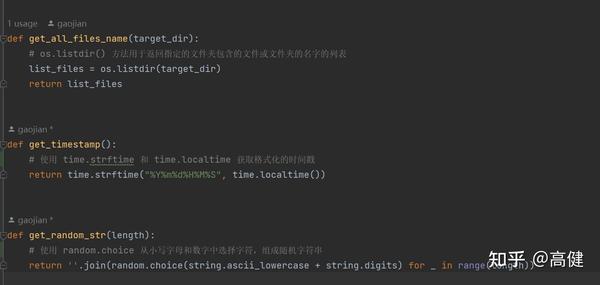
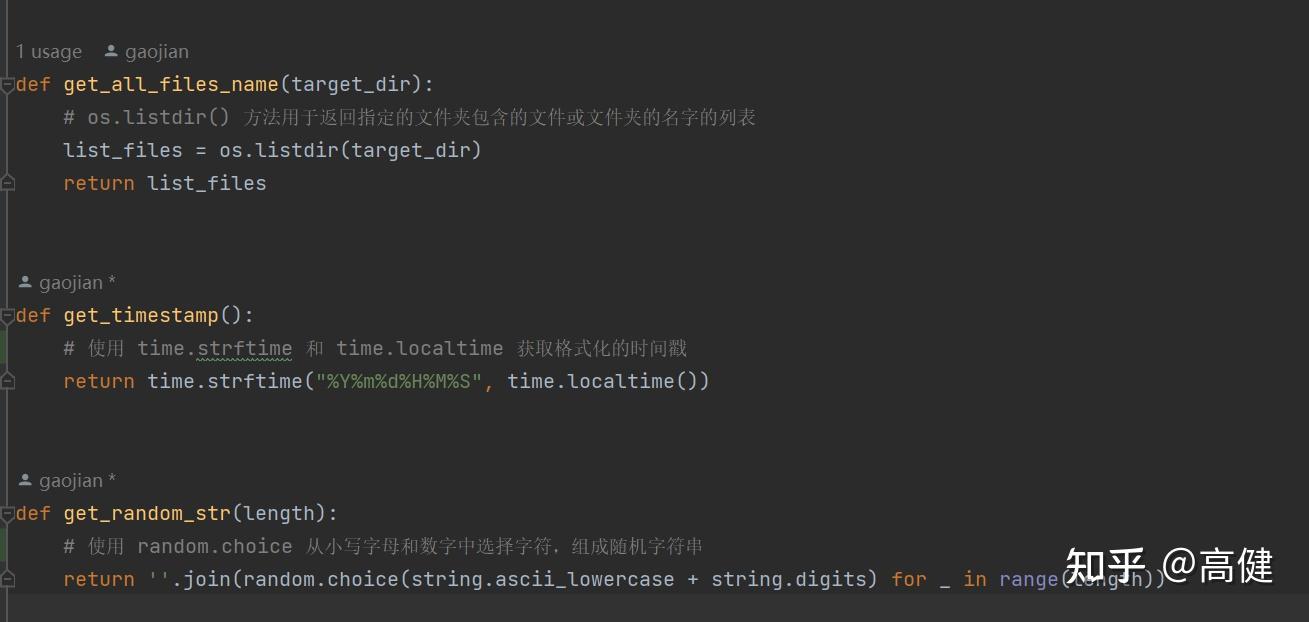
这些函数比较通用,适用于各种项目中,比如说文件名后面要加时间或随机字符串,主要用于生成唯一文件名和日志记录等场景。以避免出现因为处理速度时间过快,导致多个文件用了一个名字,最终被覆盖的情况。之前给人修Bug,报销单上传了多张,但后台却只生成了一张报销单,其原因就是其时间戳打的精读不足。
