


Socrates: The New SQL Server in the Cloud

这篇paper综述性的介绍了Microsoft在azure云上最新的DBaaS产品,用来作为具有更好扩展性和弹性的SQL DB,也称为SQL DB Hyperscale. 这个产品其实和AWS的Aurora,阿里云的PolarDB属于一类,都是基于计算存储分离的,云原生的,面向TP业务的关系型数据库,其要解决的问题也是类似的:通过利用云上的基础设施,增加数据库系统的扩展性和可用性,同时具有更好的弹性,在节省成本的同时带来更优的性能。
介绍
Azure云上已经有了大量的SQL DB部署,个人理解就等同于我们的RDS,但是基于SQL Server来提供数据库服务,而在运维这些实例的过程中,azure也遇到了很多痛点或者说客户的需求:
- 更高的可用性
- 更大的数据容量 (100+ TB)
- 更好的性能
- 更大的弹性,可以根据workload情况扩大/缩小实例,从而实现"pay-as-you-go"这种灵活的成本模型
而传统的azure云上的DBaaS是无法满足这个要求的,其形态是一种叫做HADR的架构:
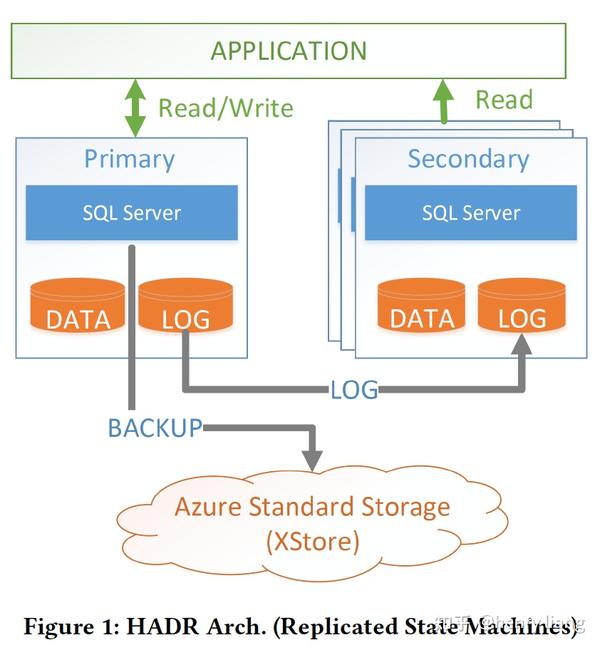
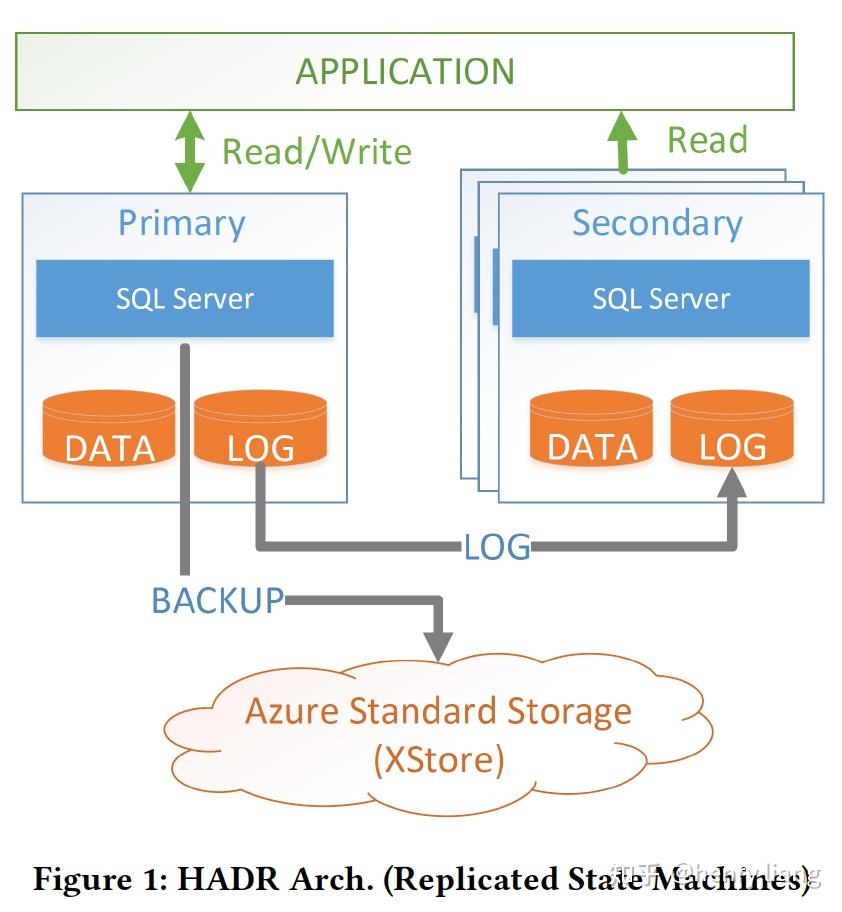
可以看到,这和AWS/阿里云上的RDS服务基本一致,通过主从间log shipping来实现状态一致,从而达到高可用的效果,然后通过周期性备份到远程的大型存储服务中(这里是XStore)来实现备份/恢复。为了达到高可用和持久化,SQL DB采用了1主3从的复制拓扑。
这个架构在azure上已经非常成熟,被广泛使用,但其存在各种类型的短板:
- 每个节点均保存一份全量的数据,因此数据容量将受到单机存储能力的限制。极端情况下,一个超大事务可能打爆本地磁盘导致不得不升配或迁移。
- 一些关键的操作(Backup/Restore/拉起新节点)的成本或时间,和数据的体量成正比,即使是crash recovery,也和undo的数据量成正比,如果有未提交的大事务,这个时间也不受控。正是基于这些原因,SQL DB限制了存储容量 < 4TB
- 弹性能力较差,这也是由于每个节点绑定了大量的数据。
为了解决这些问题,从而满足扩展性、可用性、弹性和高性能的要求,azure也采用了目前最为流行的计算/存储分离的架构,从内部拆解数据库的组件到多个层次中,各个层次作为单独的服务,各自独立的实现扩展 + 高可用。而相对于Aurora/PolarDB的storage layer,socrates还单独把log这个关键组件拆解了出来,形成了一个高性能的log服务。这样就形成了3层:
compute -> log -> storage
把log和storage拆开,实际上实现了durability和availability分离的效果,对于像RDS这样基于log shipping的DBaaS来说,他的durability和availability是耦合在一起的,当log在多副本间落盘,就同时实现了持久化+高可用。但本质上,这2个属性是可以通过不同的机制来分别保证的,原则上,只要日志持久化了,就已经实现了durability,和多个从节点并不直接相关,而多个从节点的更大意义是快速failover,保证availability。
通过这种组件的拆解和功能的分离,socrates实现了上面提到的用户的多方面需求:
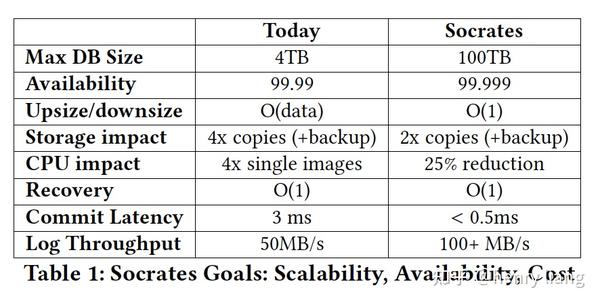
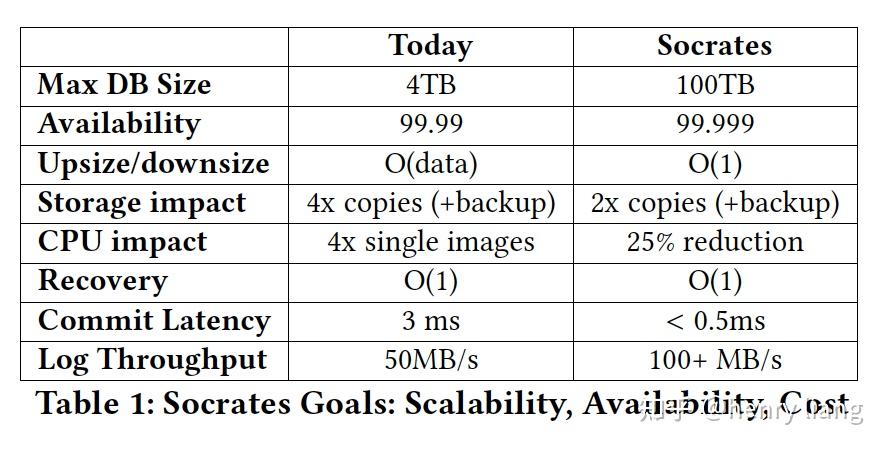
从上图可以看到,无论在支持的数据容量上,可用性上,成本上(storage/cpu),还是性能上(latency/throughput),socrates都更有优势。
可复用的基础组件
Microsoft在SQL Server上已经有了几十年的技术积累,而socrates作为云上数据库也是期望尽可能复用云上已有的基础设施,微软总的技术宗旨还是尽量避免重复造轮子,这从他们各种DB产品在技术栈上的复用性就可以看出来。在具体介绍socrates之前,paper先给出了一些对于socrates比较重要的“轮子”:
- Page version store
在HADR架构下,SQL Server的多版本数据都是保存在一个叫做version store的一个本地临时存储空间中,并定期做响应的清理,其具体机制(逻辑?物理?N2O ? O2N ?)不太清楚希望有大神可以介绍下,不过在socrates下,这个version store变为了shared-disk模式,这样所有计算节点都可以共享的访问多版本数据。
- Accelerated database recovery
简称ADR,是一种加速crash recovery的机制,在ADR之前,SQL Server使用的是经典的ARIES恢复模式,走analyze -> redo -> undo的3遍流程,可以看到,一旦有未提交的大事务,undo的负担还是很重的,而且时间不受控,恢复时间越长,可用性自然也越差,但ADR利用了共享的version store的能力,即使实例crash了,version store中仍然保留着原来的老版本数据,在恢复时在某些情况下直接获取这些老版本数据,避免了undo的过程,使得恢复变成了 analyze -> redo的2遍流程,而redo的多少取决于checkpoint interval,这样恢复时间就受控了。
- Resilient bufferpool extension
SQL Server在2012年实现了一个功能,可以把buffer pool的内容spill到本地SSD文件中,从而扩展了bp的容量限制。socrates扩展了这个特性,使bp可以变为resilient的,也就是crash后,可以recovery回来,这个功能称为RBPEX,相当于增加了buffer pool的存储层级,这样当实例重启recovery时,由于local SSD上仍然有buffer pool的内容,可以快速从本地加载,预热buffer pool,而不需要从远程存储拉取数据,而且本地SSD cache中数据更接近crash之前的最后数据状态,需要apply update的也会更少,加速了恢复流程。
从实现上,RBPEX使用了Hekaton内存引擎,将bp作为一张 内存表 来使用,因此其持久化/恢复可以复用Hekaton的能力,看起来原理并不复杂,但bp是一个性能十分关键的组件,因此可以想见工程上有许多要攻克的难点。
- RBIO
为了能让计算节点高效获取data,socrates扩展了传统的network layer protocol,增加了Remote block I/O(RBIO)这个协议,提供透明的基于version获取page,自动选择副本,自动容错等能力。
- Snapshot backup/restore
Azure云上的blob store(XStore)是log-structured的存储系统,因此其打快照/恢复的时间都是很快的,打一个snapshot只需要记录log上的最新位点即可。这是非常重要的能力,可以避免在海量数据的情况下,那种需要随数据容量线性增长的备份/恢复时间。
- I/O stack virtualization
SQL Server在底层I/O栈中,使用了FCB(file control block)这个抽象层,将底层对于不同存储介质,存储系统的I/O操作细节封装了起来,对外提供统一的接口和结构。socrates也利用了这种抽象能力,对于底层的各种存储层级,只需要提供新的FCB实现即可,这样在I/O层之上的大部分组件均不需要进行修改,最大化了代码隔离带来的好处。
Socrates设计原则
在介绍具体架构前,paper给出了一些设计原则,这些原则是在运维了大量SQL DB实例后,不断总结出来的,个人感觉这些原则比socrates本身更有价值,也正是他们促成了socrates的诞生,因此先介绍下这些设计原则:
- Local Fast storage vs. Cheap Scalable Durable storage
本地SSD具有高性能,但存储容量受限,一旦失效数据也会丢失
vs.
远程共享存储服务具有扩展性和持久性,避免了数据量增加需要做迁移的情况,但访问延迟更大
为了将2者的优势结合起来,需要采用多层级的存储模式,将本地SSD做为cache提供高性能访问,而远程storage service则作为真正的持久化存储。
- Bounded-time Operations
socrates的设计目标是更大的数据容量,但必须避免HADR架构中那种O(size-of-data)类型的操作,例如,为了实现高可用,必须能够快速拉起一个新的节点,crash recovery的速度也应尽可能快来降低MTTR(mean-time-to-recovery)。因此socrates利用了XStore的backup/restore能力和多存储层级的Xlog服务,同时结合异步加载的从节点,来实现这个能力。
- From shared-nothing to Shared-disk
HADR架构的特定是每个节点有一份本地的全量数据copy,自然存储容量受到了限制,如果把这种shared-nothing转换为shared-disk,所有计算节点可以共享相同的多版本数据,再结合上ADR机制就可以做到快速拉起实例,快速扩展只读节点。
- Low Log Latency, Separation of Log
log是事务路径上一个最主要的瓶颈点,任何事务要提交,一定需要Log持久化,如果是传统的log shipping,这种持久化也意味着同步到多个副本上。
socrates把Log实现为一个单独的服务,在服务内,log仍然是需要多副本来保证容错能力的,但由于利用了专门的服务和更高级的硬件,这里的quorum相比HADR的quorum效率要更高,因此提交的性能也更高(参看上面的对比图)。
socrates也利用了log的非对称访问特性:热的log在近期更容易被访问到,而冷的log则更少被访问到(例如回滚长时间运行的老事务),因此也建立了log的存储层级关系,将热log放在主存中,更老的则放入local cache甚至在XStore层。
单独的log服务利用了azure上先进的存储技术,而且这些技术仍在不断发展,log serivce自然可以享受这些福利而不用修改自身的处理逻辑。
- Pushdown Storage Functions
和Aurora一样,shared storage这种架构可以把一些针对数据的重要操作,如checkpoint/backup/restore/load等,offload到存储层完成,此外查询中的一些计算(scan/filter)也可以下推到存储层来释放计算节点的压力,提升整体的性能。
- Reuse Components, Tuning, Optimization
之前已经提到,SQL Server本身已经发展了非常成熟完善的技术体系和生态系统,因此系统的兼容性无论对于从SQL DB或on-premise的SQL Server向socrates迁移都是非常重要的,这也是为什么要提供 100%兼容性 的原因,socrates复用了SQL Server大量的组件,包括optimizer/runtime/security/transaction manager/log format等,这样既利用了已有技术积累又保证了兼容性。
Socrates架构
现在我们来看下socrates整体的架构,并可以和Aurora做一些对比
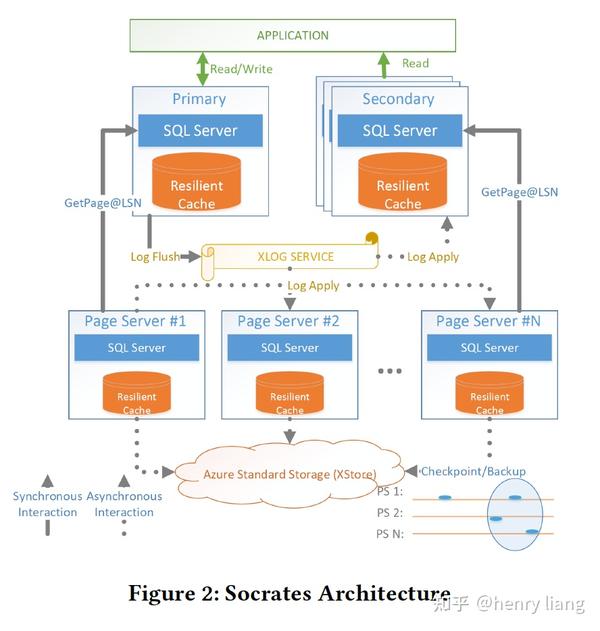
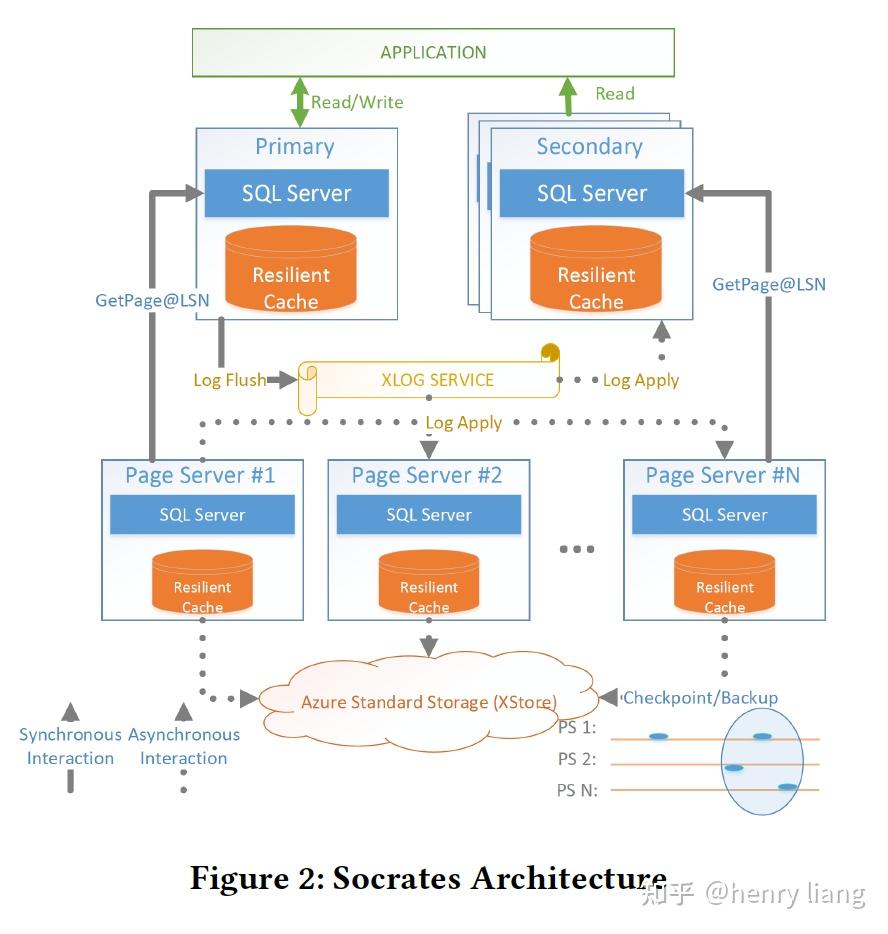
整体架构分为4层:
最上层是计算节点,和Aurora/PolarDB一样是一写多读的模式,不同的是,主节点与从节点间完全 没有交互 !!因此socrates的从节点数量理论上是不受限的。计算节点上有Resilient cache来实现对buffer pool的扩展。
第2层是独立出来的XLOG service,这个服务实现了低的提交延迟和好的存储扩展性(多层级的log存储),这与aurora的log+data耦合的方式具有本质的不同。同样只有主节点可以写入log,并通过批量方式实现低延迟+高吞吐的写入。其他读节点异步的从XLOG service中拉取log做apply。
第3层是存储层,由Page Server组成,负责存储多版本数据,其本身也是partition的,因此可以更好的扩展,这个很类似aurora底层的storage fleet,只是没有log。
Page Server具有2个作用:
- 从XLOG service拉取log进行apply,生成实际的多版本data page,并把data pages做checkpoint到XStore层,以及在XStore上创建必要的backup。
- 对计算节点提供必要的page,此外也希望能提供bulk loading/index creation/DB reorgs/page repair/table scan等贴近data的批量操作,这些操作可以利用page server的分布式特点实现充分的并行。
同计算节点一样,Page Server也利用了RBPEX来做data cache。
第4层是XStore,也就是持久化的大存储服务,它是azure上一个独立的存储服务,特点是大容量,持久化,低成本,缺点自然是延迟。个人理解这个服务和AWS S3类似。通过把Page Server与XStore分离,可以把Page Server看做是一层高速的cache(有RBPEX)。
从整体上看这个架构,其实XLOG/XStore是系统中的持久化存储,计算节点/Page Server可以看做是提供可用性的cache,即使计算节点/Page Server失效了,数据也不会丢失,因为log还在XLOG和XStore里,而data也在XStore中形成了备份。这样就实现了Duribility和Availability的分离!
虽然架构上的分层和Aurora比较类似,但从设计理念上,这种分离Aurora是没有的,因为它的log与data都存在于storage fleet中,log是系统的持久化核心,它没有放到底层的S3上,S3只负责为data打快照来方便恢复。
- XLOG Service
下图展示了最为核心的XLOG的框架:
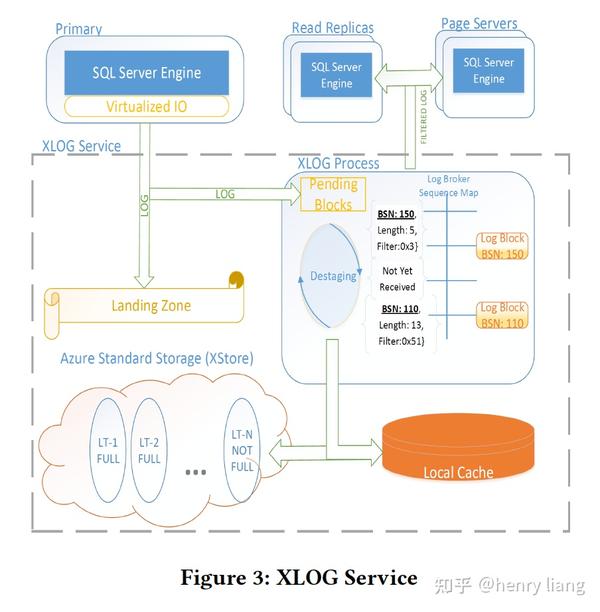
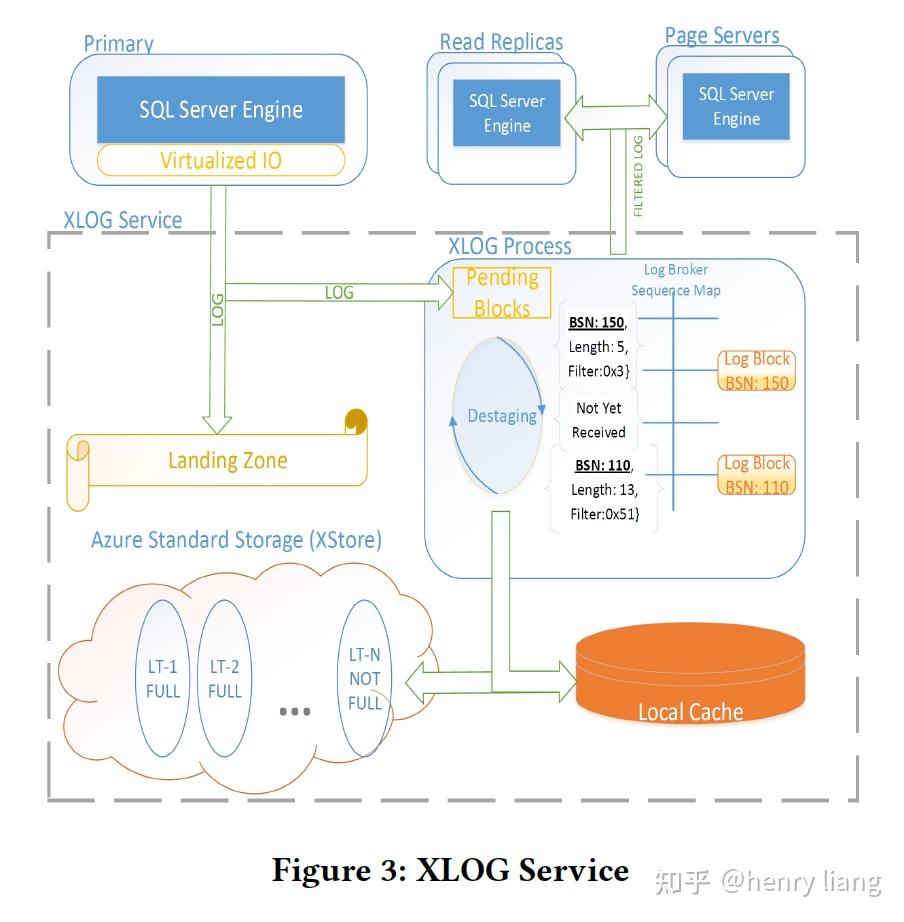
主节点将log blocks首先写入到一个叫做Landing Zone(LZ)的组件上,这是一个高速且持久化的存储服务,当前的Socrates使用了azure云上的一个叫做Premium Storage service(XIO)的服务来作为LZ,XIO本身使用了3副本。主节点是同步写log到LZ的,LZ高速但容量有限,实现为1个circular buffer,它可以保证多个log reader和log writers可以并发操作而不需要同步(咋做的??)。
在写入LZ的同时,主节点会异步将log写到XLOG内部一个process中,这种写入并不可靠,由于与“写LZ”是并发的,如果不做控制,有可能出现log还没有持久化到LZ中,就已经进入process被分发到从节点等地方,这个是违反WAL的,因此在log process中增加了一个"pending area",未被持久化到LZ的log要pending住,直到LZ告知持久化完成,才能进一步处理,这也给了在pending area内对乱序Log block进行排序整理的机会,然后log blocks会传递给Log Broker这个组件进行分发。
一旦进入Log Broker,其内部的"destaging"进程会把log写入到local SSD cache中方便快速访问,同时写入到XStore中做长期保存(LT)。这里destaging的操作要做专门的调优,因为只有log完成了destage,LZ中的old block才能被清理掉,如果LZ满了,事务的写入也就卡住了。可以看到log也形成了复杂的存储层级,但这样是有好处的:
- log被写入XStore因此不需要做周期性的backup
- 所有log要么持久化在LZ中要么持久化在LT中,LT中成本更低
- 快速的log访问通过local SSD cache来满足
- Primary Compute Node and GetPage@LSN
和Aurora不同,socrates的主节点不感知RO节点,因此更加简单,核心作用就是处理事务和生产log,和普通的SQL Server相比,区别有:
- 很多存储层的功能已经offload了(checkpoint/backup/page repair...)
- 通过FCB的抽象层向LZ写log block
- 使用了RBPEX cache来提升系统性能
- 由于不保存全量数据,因此节点本地的存储相当于热数据的cache
当数据不在local cache时,需要从Page Server集群获取,这时就需要利用RBIO的GetPage@LSN 的机制,这是一个RPC: getPage(pageId, LSN),目标是获取一个特定page,其上的内容不能比指定的LSN更老(但可以更新)。
作为Page Server想满足这个需求很容易,只需要等待log apply到目标LSN后,返回生成的page即可。
那么主节点如何知道应该读取哪个LSN呢?从原则上,单机数据库总是可以获取到最新LSN的data page,因此主节点也应该如此,而如果page在local cache中,那么它自然是最新的,只有当从cache中evict出去后,才可能失去最新性,因此socrates的主节点中维护了一个hash map,记录每个page最近一次被evict时的LSN号,这样在重新GetPage时,只要指定这个LSN就是了。
- Secondary Compute Node
从节点是异步从XLOG Service上拉取log做apply的,它不需要对log blocks做持久化,只是要建立本地数据(cache)就可以了。由于利用XLOG解耦,从节点也不需要感知主节点的存在。这和HADR/Aurora/PolarDB是非常不同的。
由于从节点也是一个cache,那么有可能在apply log时,对应的data page不在本地cache中,这时可以有2种策略来处理:
- 从Storage层获取page并apply log,这样的方式,从节点的状态会更加接近主节点,这样如果发生failover,会更快速稳定的完成恢复。
- 如果page不在cache中,说明用户查询不需要它,直接丢弃掉,这也是Aurora/PolarDB采用的模式,socrates也是如此,这样从节点更多起到了承担前端读负载的作用,而不是备节点的作用。
在RO节点上,由于log是异步apply的,这里可能会出现一些不一致的问题,例如:
在访问Btree node时,访问父节点Node P(在local cache中)的LSN是23,然后遍历到子节点C,由于C不在cache,调用GetPage(@23) 去获取,但得到的page可能是page@25,这里就形成了不一致,如果在24时,node C分裂了怎么办?
这个问题在Aurora/PolarDB中可以利用InnoDB的mini transaction解决,mini transaction把一次修改封装在内部,保证了其边界上,数据总是物理一致的。而Aurora记录了一个全局的VDL来描述这个mini transaction LSN的不断递进(在上例中,VDL就是25),当读取page时会利用这个VDL保证看到状态一致的数据。
在socrates中则采用了等待的策略,当发现这种不一致时,先等待一段时间来让apply log threads应用更多的内容(这里就是等待node P的状态更新到 = 25),然后重新做B-tree的遍历。(这里有些疑问,如果并发高不是很容易不一致??应该有某种规则)
- Page Server
之前已经提到了page server的分片和2个主要功能,由于做了分片,每个page server只需要对自己本地负责的data page所对应的log records进行apply就可以了,这样也实现了并行apply。
那么怎么知道一个log block中的log records都对应了哪些data pages呢?主节点在写入log block时,会在其中打上标记,记录都对应到哪些data partitions,这样XLOG中的Log Broker只需要根据标记做分发就可以了。
Page Server也利用了RBPEX,但与计算节点中只缓存热数据不同,page server缓存了 所有 其负责的数据在local cache中,socrates以某种连续的方式(paper中没细讲)组织这些cache pages,这样上层一次multi-page range的IO请求,只需要对应到SSD的一次实际I/O即可,这对于scan这样的操作会更高效。此外有了全量的local cache,也可以忍受暂时的XStore失效。
在做checkpoint时,page server可以批量的方式,一次IO写入大量的pages,提高到底层存储的吞吐。
在启动一个新page server时,它可以立即提供服务( 本质上只是一个cache ),其RBPEX可以通过不断提供服务+apply log的方式热起来。
- XStore for Durability and Backup/Restore
前面已经提到了XStore采用了log-structured的设计,因此backup只是打个时间戳,常量时间完成。
XStore是log + data的实际存储,它低成本高吞吐但性能不佳,因此其上设计的各种组件 + 各个存储层级,本质上都是为XStore建立高性能 + 高可用性所必须的。从某种意义上,可以把XStore看做传统数据库的disk,把计算节点/Page Server的RBPEX看做传统数据库的memory。
如果按照这个来理解,那XStore上的backup/restore/checkpoint就很容易理解了。利用全量的snapshot + 增量log,就可以完成PITR,这比HADR架构下的PITR要高效的多因为它与数据体量无关。
总结
总结前面的各种描述,socrates利用计算/存储分离,实现了它最初设定的各种设计目标(见前面描述)。其中最亮眼的就是它对于durability和availability分离的设计,也就是通过XLOG+XStore实现durability,通过计算节点+Page Server实现availability,这样就把数据库内核中的各个组件拆解开了,这样拆解的最大好处,就是各个组件可以独立做到扩展+高可用,此外可以细粒度的单独控制,以及在组件的实现中复用一些成熟的云上的基础设施,这对于一个紧耦合的数据库系统来说是不可想象的。
从理念上,感觉其设计和SingleStore (MemSQL商业版)更加类似,把计算节点作为cache,把底层大存储服务作为数据的实际落脚点,并通过不断拆解组件,在一个更细的粒度上,对每个功能模块做各种扩展性/可用性/性能/成本上的trade-off。