

kylin完美支持aws glue data catalog

我们现在公司所有大数据平台全部上云平台,大数据使用的aws EMR,随着数据暴增带来提数慢,提数难,很难满足数据分析师、运营人员、销售的需求,特别是我们现在商业变现部门的销售人员去客户现场进行数据演示时的即席查询。于是我们商业变现数据团队对当下OLAP框架进行选型,最终选择kylin作为我们DMP平台底层的计算引擎,但是我们在测试中发现kylin版本不支持aws glue data catalog,但是我们现在所有数据团队的元数据都是使用aws glue来进行存储,这样带来的好处在于hive、presto、spark中的建立的表可以在共享查询,使得每个主题都串联起来形成一个大的立方体,打破物理障碍。
那什么是aws glue ?
AWS Glue 是一项完全托管的 ETL(提取、转换和加载)服务,使您能够轻松而经济高效地对数据进行分类、清理和扩充,并在各种数据存储之间可靠地移动数据。AWS Glue 由一个称为 AWS Glue 数据目录的中央元数据存储库、一个自动生成代码的 ETL 引擎以及一个处理依赖项解析、作业监控和重试的灵活计划程序组成。AWS Glue 是无服务器服务,因此无需设置或管理基础设施。看着官方的解释可能比较懵懂,通俗的说我们在使用aws 的EMR,组件主要包括hadoop、spark、hive、presto等,如果没有配置使用aws glue data catalog,那么在各个数据仓库组件hive、spark、hive、presto建的数据表,在其它组件上是找不到的,也就不能使用,公司底层的数据仓库是提供给各个业务部门来进行使用,为了解决这个问题,在创建EMR时就可以使用aws glue data catalog来存储元数据,对各个组件共享数据源,对各个业务部门进行共享数据源,将各个业务部门的数据构建成一个大的数据立方体,能够快速响应公司高速发展的业务需求。
我们是怎么修改kylin的代码完成支持aws glue的?


(1) 发现问题-加载数据源时不支持aws glue data catalog
hive中配置了使用aws glue data catalog存储元数据,部署kylin后可以正常启动,但是登陆kylin web ui加载数据源时,只看到该EMR集群的hive 数据源而其他的无法看到,如图

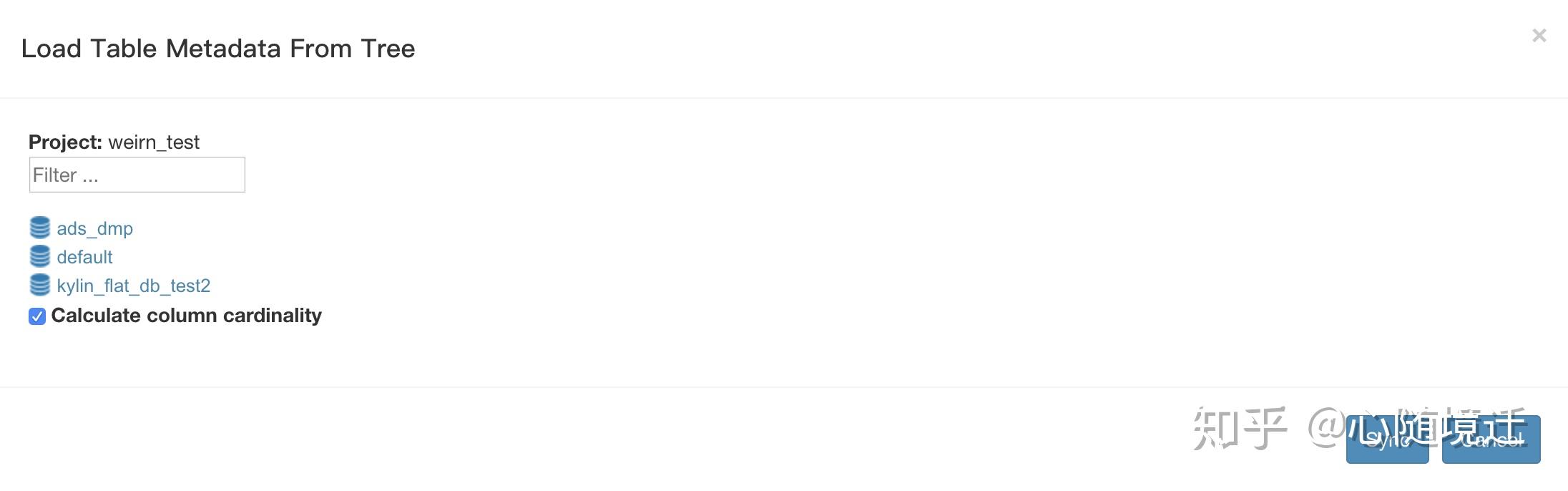
这三个数据库是该EMR集群自己的数据库,而我们整个公司的数据库远远不止这些。debug代码进去发现加载数据源时获取metastoreclient的类CLIHiveClient.java
private IMetaStoreClient getMetaStoreClient() throws Exception {
if (metaStoreClient == null) {
metaStoreClient = new HiveMetaStoreClient(hiveConf);
return metaStoreClient;
}目前只支持HiveMetaStoreClient,而没有看到任何支持AWSCatalogMetastoreClient的相关代码。
(2)发现问题-build cube报获取AWSCatalogMetastoreClient异常,debug代码发现kylin在build job 第1阶段Create Flat Table & Materialize Hive View in Lookup Tables使用hcatalog读取hive表的数据,计算后插入新的hive表。
public CubingJob build() {
logger.info("MR_V2 new job to BUILD segment " + seg);
final CubingJob result = CubingJob.createBuildJob(seg, submitter, config);
final String jobId = result.getId();
final String cuboidRootPath = getCuboidRootPath(jobId);
// Phase 1: Create Flat Table & Materialize Hive View in Lookup Tables
inputSide.addStepPhase1_CreateFlatTable(result);
// Phase 2: Build Dictionary
result.addTask(createFactDistinctColumnsStep(jobId));
if (isEnableUHCDictStep()) {
result.addTask(createBuildUHCDictStep(jobId));
result.addTask(createBuildDictionaryStep(jobId));
result.addTask(createSaveStatisticsStep(jobId));
// add materialize lookup tables if needed
LookupMaterializeContext lookupMaterializeContext = addMaterializeLookupTableSteps(result);
outputSide.addStepPhase2_BuildDictionary(result);
if (seg.getCubeDesc().isShrunkenDictFromGlobalEnabled()) {
result.addTask(createExtractDictionaryFromGlobalJob(jobId));
// Phase 3: Build Cube
addLayerCubingSteps(result, jobId, cuboidRootPath); // layer cubing, only selected algorithm will execute
addInMemCubingSteps(result, jobId, cuboidRootPath); // inmem cubing, only selected algorithm will execute
outputSide.addStepPhase3_BuildCube(result);
// Phase 4: Update Metadata & Cleanup
result.addTask(createUpdateCubeInfoAfterBuildStep(jobId, lookupMaterializeContext));
inputSide.addStepPhase4_Cleanup(result);
outputSide.addStepPhase4_Cleanup(result);
// Set the task priority if specified
result.setPriorityBasedOnPriorityOffset(priorityOffset);
result.getTasks().forEach(task -> task.setPriorityBasedOnPriorityOffset(priorityOffset));
return result;
}最后调用调用HiveMRInput.java
public void configureJob(Job job) {
try {
job.getConfiguration().addResource("hive-site.xml");
//该方法内部使用反射获取metastoreclient,如果在hive-site配置了
<property>
<name>hive.metastore.client.factory.class</name>
<value>com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory</value>
</property>
那么通过反射获取AWSGlueDataCatalogHiveClientFactory
HCatInputFormat.setInput(job, dbName, tableName);
job.setInputFormatClass(HCatInputFormat.class);
} catch (IOException e) {
throw new RuntimeException(e);
}报如下异常:
Caused by: com.google.common.util.concurrent.ExecutionError: java.lang.AbstractMethodError: com.amazonaws.glue.catalog.metastore.AWSGlueDataCatalogHiveClientFactory.createMetaStoreClient(Lorg/apache/hadoop/hive/conf/HiveConf;Lorg/apache/hadoop/hive/metastore/HiveMetaHookLoader;ZLjava/util/concurrent/ConcurrentHashMap;)Lorg/apache/hadoop/hive/metastore/IMetaStoreClient;
at com.google.common.cache.LocalCache$Segment.get(LocalCache.java:2261) ~[kylin-job-2.6.4.jar:2.6.4]
at com.google.common.cache.LocalCache.get(LocalCache.java:4000) ~[kylin-job-2.6.4.jar:2.6.4]
at com.google.common.cache.LocalCache$LocalManualCache.get(LocalCache.java:4789) ~[kylin-job-2.6.4.jar:2.6.4]
at org.apache.hive.hcatalog.common.HiveClientCache.getOrCreate(HiveClientCache.java:315) ~[hive-hcatalog-core-2.3.5-amzn-1.jar:2.3.5-amzn-1]
at org.apache.hive.hcatalog.common.HiveClientCache.get(HiveClientCache.java:277) ~[hive-hcatalog-core-2.3.5-amzn-1.jar:2.3.5-amzn-1]
at org.apache.hive.hcatalog.common.HCatUtil.getHiveMetastoreClient(HCatUtil.java:558) ~[hive-hcatalog-core-2.3.5-amzn-1.jar:2.3.5-amzn-1]
at org.apache.hive.hcatalog.mapreduce.InitializeInput.getInputJobInfo(InitializeInput.java:104) ~[hive-hcatalog-core-2.3.5-amzn-1.jar:2.3.5-amzn-1]
at org.apache.hive.hcatalog.mapreduce.InitializeInput.setInput(InitializeInput.java:88) ~[hive-hcatalog-core-2.3.5-amzn-1.jar:2.3.5-amzn-1]
at org.apache.hive.hcatalog.mapreduce.HCatInputFormat.setInput(HCatInputFormat.java:95) ~[hive-hcatalog-core-2.3.5-amzn-1.jar:2.3.5-amzn-1]
at org.apache.hive.hcatalog.mapreduce.HCatInputFormat.setInput(HCatInputFormat.java:51) ~[hive-hcatalog-core-2.3.5-amzn-1.jar:2.3.5-amzn-1]
at org.apache.kylin.source.hive.HiveMRInput$HiveTableInputFormat.configureJob(HiveMRInput.java:80) ~[kylin-source-hive-2.6.4.jar:2.6.4]
at org.apache.kylin.engine.mr.steps.FactDistinctColumnsJob.setupMapper(FactDistinctColumnsJob.java:126) ~[kylin-engine-mr-2.6.4.jar:2.6.4]