


决战“云”霄 | 剖析ARM Neoverse V1与N2
对于ARM体系架构和对公事业而言,2020年可谓是非常成功的一年。这一年,ARM的“ Neoverse”系列CPU微体系结构终于开花结果,亚马逊推出了基于Neoverse架构的Graviton2,Ampere推出了Altra服务器CPU。早在2019年初,Arm就首次推出了Neoverse N1。如果说,Graviton2的Arm服务器给出的承诺您还不满意,那么,功能更强大同时尺寸更大的Altra肯定会击中您的芳心。


第一代Arm服务器在性能上具有真正的竞争力,这一点应该毫无争议,而现在,Arm终于实现了多年来孜孜以求的目标,即从x86现有厂商那里攫取了拿得出手的市场份额。
几年过去了,快进到2021年,如今在Ampere Altra等设计中采用的Neoverse N1仍然具有相当的竞争力,可以说它们击败了最新一代的AMD或Intel设计。而这种判断在几年前多少显得有些牵强。我们建议您在过去的两年中赶上这些重要的评论文章,以准确了解当今市场:


Arm公开表示,他们为Neoverse产品系列设定的主要优先目标是获得云服务市场份额,最近一个成功的案例来自于亚马逊,整个2020年亚马逊自己部署了多个AWS服务器,其中部署的主要硬件便是新的基于Arm的Graviton2,它抢占了英特尔丢掉的大部分市场份额。
展望2022年及未来
今天,我们正朝着未来以及新一代Neoverse V1和Neoverse N2产品迈进。Arm已于去年9月对新产品进行了测试,测试了新设计的一些特征,但没有披露更多有关新微体系结构的具体细节。在上个月宣布Armv9架构之后,我们现在终于可以开始研究两个新的CPU微架构以及新的CMN-700 网状网络了。
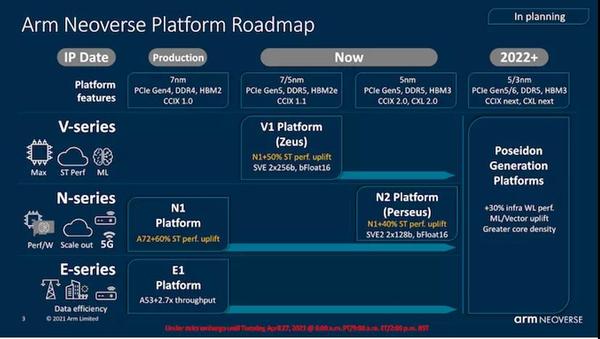
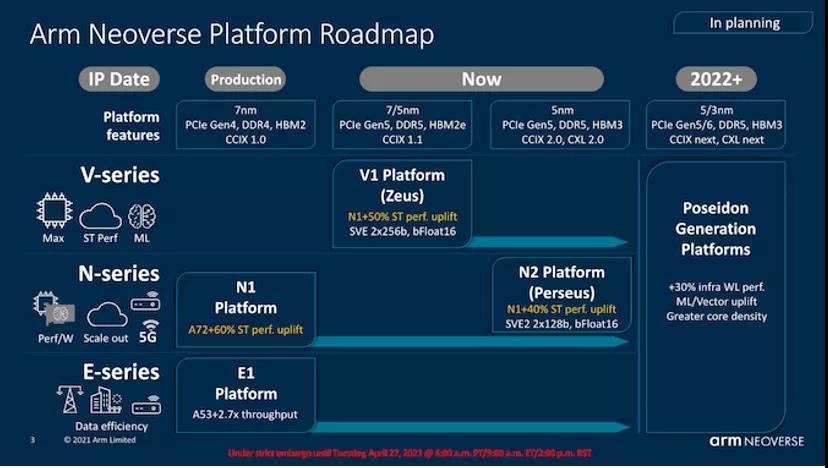
正如去年9月份所介绍的那样,这一代Neoverse CPU微体系结构的与众不同之处在于,这是两种截然不同的产品,分别针对不同的目标和细分市场。Neoverse V1是Arm开辟的一条新产品线,其目标旨在为更多类似于HPC的工作负载和面向此类市场的设计服务,而Neoverse N2则是Neoverse N1的直接继承者,面向基础设施和云端部署,其方式与N1在Graviton或Altra处理器等产品中所采用的方式相同。

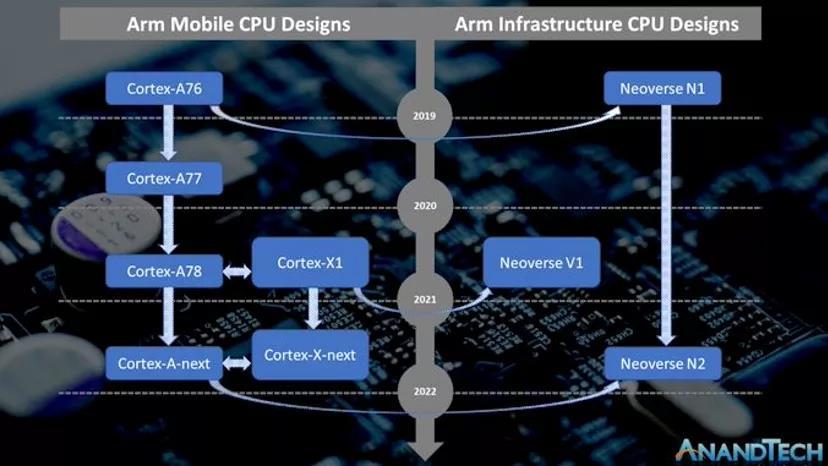
对于熟悉Arm的移动CPU微体系结构的读者来说,这两个设计之间肯定有非常大的相似之处-尽管Arm的市场营销部门似乎很奇怪地不愿意进行这种比较,这也是我制作了上面的图表以便更清楚地描述这两个设计之间相似之处的原因。
Graviton2和Altra Q处理器中的原始Neoverse N1是Cortex-A76的衍生产品,更确切的说,它和Cortex-A76是同级微体系结构,Cortex-A76已在2019年上市的骁龙855等移动SoC中使用。当然,Neoverse设计具有面向服务器的特定功能和一些变化,而这些功能和变化在移动产品中是不存在的。

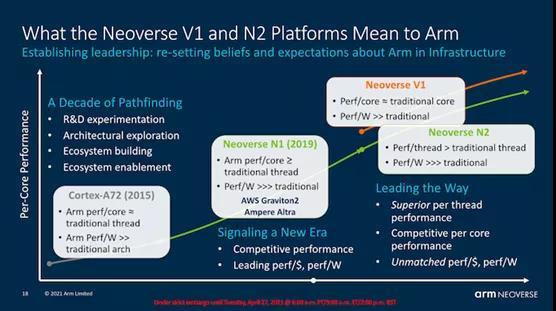
与N1与A76的联系类似,新一代V1和N2微体系结构与Cortex组合中的较新设计有关。V1与我们在今年的新型移动SoC(如Snapdragon 888或Exynos 2100)中看到的Cortex-X1有关。另一方面,Neoverse N2与即将推出的新Cortex-A微体系结构有关,我们希望在接下来的几个月中了解更多信息。在今天的整篇文章中,我们将更多地介绍V1和N2之间的这种代代相传。重要的是要记住,N2是较新的设计,尽管它针对的是不同的性能和效率点。
ARM为V1和N2设计的目标之所以有所不同,是因为该公司针对特定市场最终产品可能具有的不同优先级而进行的一种尝试,就像新的Cortex-X系列在移动设备领域主要优先考虑单核性能,而Cortex-A系列则继续专注于实现最佳的PPA。同样,V1专注于以较低的效率实现最佳的性能,并具有诸如更宽的SIMD单元(2x256b SVE)之类的功能,而N2则继续保持横向扩展的理念,即具有最佳的功率效率,同时仍通过改进一代代IPC来提高性能。
在今天的文章中,我们将深入探讨V1,N2的新微体系结构变化以及Arm的最新一代网状互连IP CMN-700,该产品有望成为下一代Arm服务器处理器的基础。
Neoverse V1微体系结构
带有SVE的X1?
从新的Neoverse V1开始,这个设计既具有一些我们熟悉其起源的一些功能,又具备我们在Arm CPU中首次看到的一些独特功能。正如引言中所指出的那样,V1出自Arm奥斯汀设计中心设计Cortex-X1的同一支团队,在区块结构方面,两个微体系结构之间存在很大的相似之处。

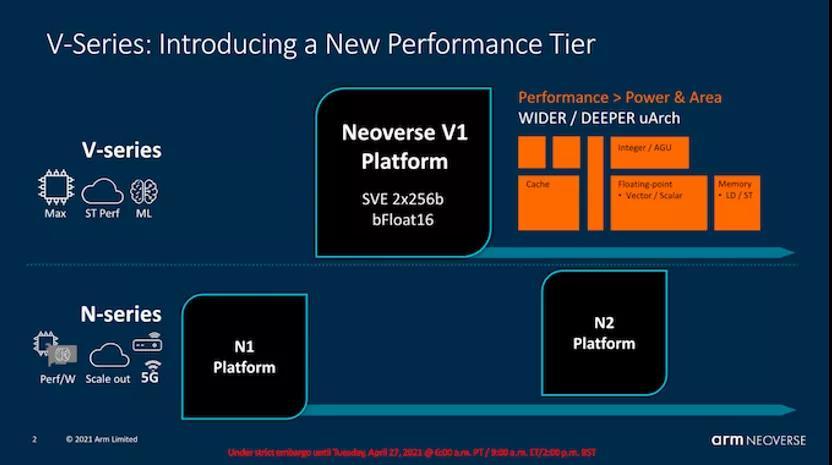
与X1(当然还有其前身N1)相比,V1最值得注意的是,它现在是一个具有SVE功能的处理器,具有两个本地256b SIMD流水线,并且还引入了仅限于服务器才具有的一些特征,例如一致性L1I缓存, bFloat16执行能力,以及一系列我们将在稍后介绍的独特特性。
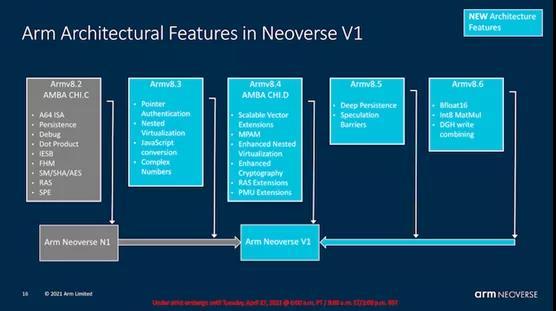

从其描述而言,Neoverse V1的体系结构特征可能是最复杂的-本质上,它采用的是v8.4基线体系结构,同时还为面向HPC的工作负载引入了v8.5和v8.6体系架构中的一些功能。鉴于我们在一个月前才谈到过Armv9,这似乎有些奇怪,但我们必须再次记住,V1是在相当一段时间之前设计的,并且客户拥有该IP已有相当长的一段时间了,有的已经研发出甚至流片了V1处理器。

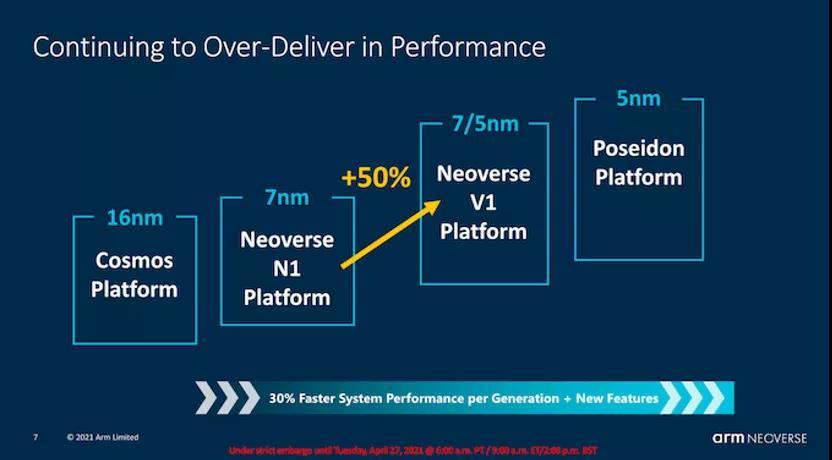
V1的最大亮点在于,它的性能相比于N1大大提高,IPC增长了 50%。性能提升惊人,但是这并不令人感到惊讶,因为该微体系结构实际上比N1提升了2代,尽管从基础架构产品的角度来看,它仅提升了一代微体系结构。


从高级流水线的角度和微体系结构的角度来看,Neoverse V1与X1非常相似。这仍然是一个非常短的流水线设计,只有11个阶段,Arm将重点放在其微体系结构的这一方面,以尽可能减少分支预测错误的代价。在从A76开始的Austin系列设计的最后几次迭代中,微体系结构的流水线设计方面一直保持相对静态,因此Arm指出,与N1相比,V1的频率能力基本上没有变化,而性能的提升完全来自于增加的IPC。


在V1中,我们可以发现在Cortex-A77和Cortex-X1世代中看到的许多前端改进,以及更大的前端分支改进,例如解耦的访存单元的带宽增加了一倍,L2 BTB更大,最多可容纳8K个条目,并重新排列和调整了较低级别的BTB的大小,与Neoverse N1相比,L0(nanoBTB)增长到96个条目,而L1 BTB(microBTB)不再保留。


与N1相比,V1还增加了一些新结构,例如引入了最多可解码3K指令的宏操作缓存。来自Mop缓存的调度带宽为8-wide,而这一代的实际指令解码器为5-wide,与X1上的相同。
与Neoverse N1相比,乱序窗口的大小实际上增加了一倍,ROB增长到256个条目。实际上,这比Arm为Cortex-X1披露的要稍大一点,ARM的Cortex-X1只披露了“ OoO窗口尺寸为224”,因此在这方面似乎与我们在X1中见到的有所不同。
在后端整数执行流水线上,该设计还引入了我们在A77世代产品上看到的许多更改,其中包括将分支执行端口加倍,以及能够执行简单指令(如加法运算)和更复杂运算(例如乘法和除法)的新型复杂ALU。
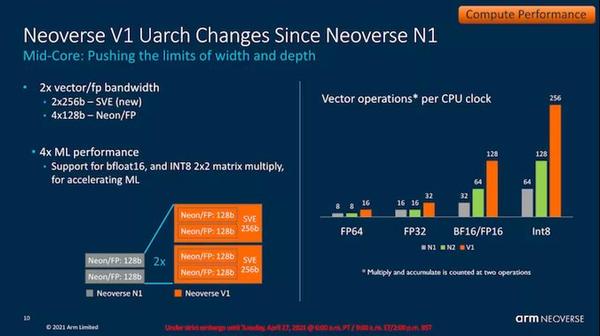

显然,新的SIMD流水线在V1上有很大的不同,因为这是Arm有史以来第一个具有SVE功能的微体系结构。该设计具有两个流水线,似乎带有两个专用调度器,它们具有针对256b宽SVE向量的本地功能。该设计与128b NEON / FP操作完全向后兼容,其中流水线实际上充当4x128b单元,这意味着在这方面,它具有与X1相同的执行宽度。
与N1相比,新设计还支持新的bFloat16和Int8数据格式,从而大大提高了内核的AI和ML推理性能。


在内存子系统方面,我们还看到,Cortex-X1上的单元数有所增加,包括2个加载/存储单元和1个加载单元,这意味着该内核每个周期最多可以加载3个负载,每个周期最多可以存储2磁。SVE向量带宽对于负载而言为每个周期2x32B,对于存储而言为每个周期32B。
该内核的数据并行性也有所改进,以提高MLP(内存级并行性)功能。
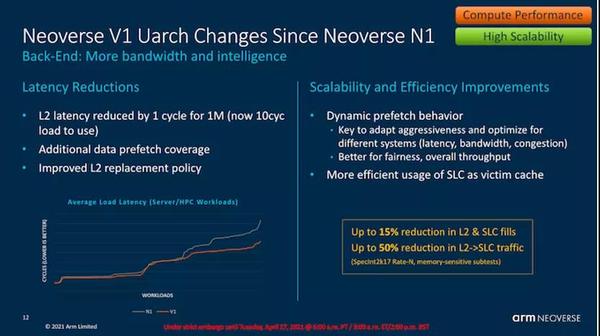
L2高速缓存也采用了与X1相似的设计,在相同的1MB大小下,它现在快了1个周期,并且存储体数量增加了一倍,以提高访问并行度。
V1的系统级延迟出现了相当大幅度的降低。除了结构上的改进外,新一代预取器也是其中的一个重要组成部分,例如引入了一种新型的时间预取器,该临时取指器可以随着时间的流逝锁定在任意访问模式上,并识别相同模式的后续迭代,并将数据提取进来。
Arm揭示了该内核具有新的动态预取行为,该行为在减少L2互连流量方面起着重要作用,这是大型内核计数系统中的一个关键指标,在该系统中,每个字节的带宽都需要实际使用,并且不能因错误推测的预取而浪费掉。
Neoverse V1微架构
平台增强
V1除了在内核微架构方面有所创新之外,新设计还包括一些新的面向系统的创新,这些创新有望帮助供应商更好地将CPU IP集成到更大规模的实现中。
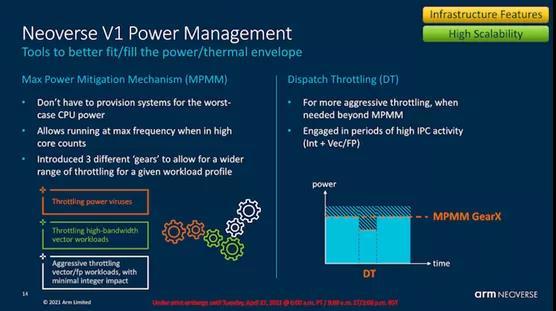
MPAM(最大功率缓解机制)是一种新的细粒度(约100个时钟周期)的电源管理机制,它承诺帮助平滑内核的耗电行为,并允许供应商实现芯片的功率传输机制,可以说是以较低的功耗要求构建的。
正如我们在对Ampere Altra的评论中所看到的那样,该芯片没有像大多数x86 CPU那样在最大TDP下频率来回波动,而是将大部分时间保持在最大频率上,而实际功耗却多次落在TDP之下(最大允许功耗)。MPAM之类的机制将在可能的情况下,通过对功率受限的内核进行更精细的调节来提高系统的平均频率。可以实现这一目标的机制还包括微体系结构层次上的一些特性,例如调度节流,其中内核减慢调度指令的速度,在执行周期长的工作负载中平滑掉了对高功率的要求,在现在有了新的更宽的2x256b SVE流水线的情况下,这个特点尤其重要。
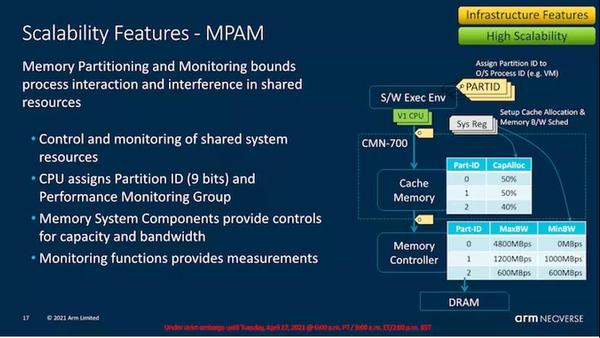
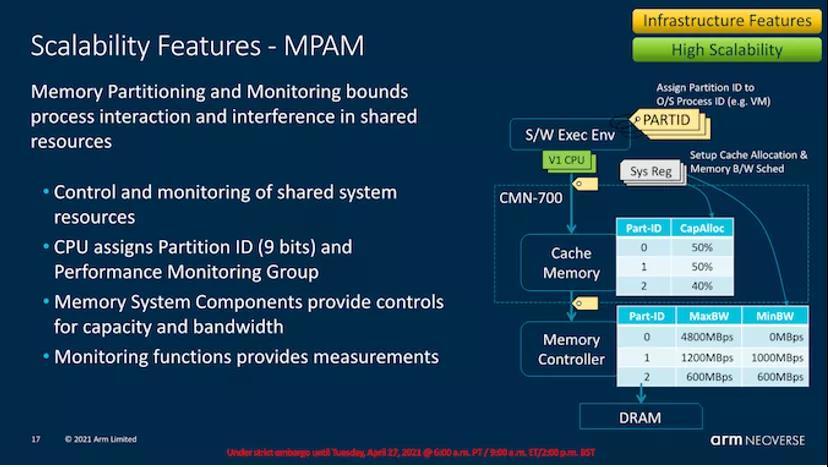
MPAM是一种在更大型的系统中帮助实现交互的另一种机制。内存分区和监视功能应该有助于提高服务质量,并减少在同一系统上部署运行多个工作负载(例如多个VM或进程)时不同进程相互干扰的副作用。这自然需要软件-硬件合作和实施,但是在云环境中应该特别有用。


CBusy或Completer Busy也是一种新的系统端机制,其中CPU内核基于反馈的方式与网状网络交互,其中CPU可以根据整体网格和系统内存负载来改变其内存预取器的主动性。这与前面提到的动态预取行为相关联,在这种情况下,可以同时兼顾两个方面:在带宽可用时更好地进行预取以提高每个内核的性能,在系统处于高负载状态的情况下进行非常保守的预取,从而避免浪费带宽和数据传输。
Neoverse N2 µArch
面向企业的首款Armv9
从以性能为导向的Neoverse V1到追求更平衡指标的Neoverse N2内核,我们看到了一种不同的内核设计方法,这有些类似于Cortex-A78对PPA的关注与X1对性能的关注两者之间的对比。
Arm在这个内核上的关键字是“平衡”–微体系结构只采用那些有助于增加IP的PPA(性能、功率、面积)等式的功能和设计的更改。相反,V1选择的是性能增强,即使这意味着功耗和面积的增加不成比例,从而降低了设计的总PPA。
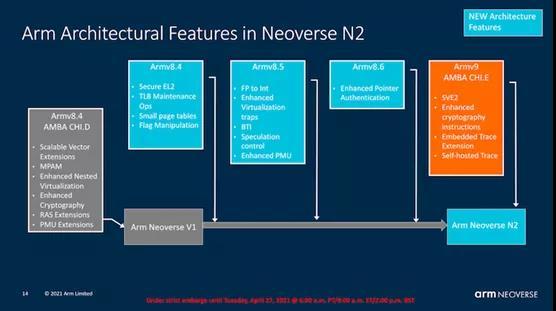
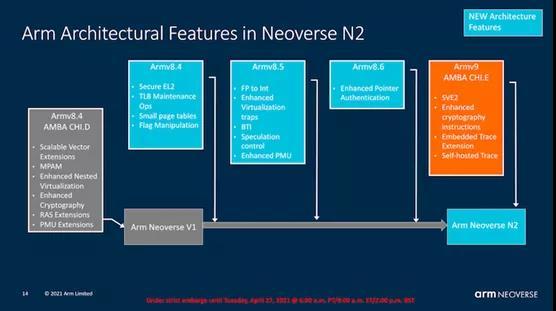
在体系结构上,N2是比V1更新的核心,并采用更高的体系结构基线作为其功能的基础。这是Arm首次公开的支持Armv9的内核,其中包括一些重要的新功能,例如SVE2。值得注意的是,尽管Arm上个月谈论了很多关于Armv9 CCA(机密计算体系结构)的信息,但Neoverse N2内核并没有新的SVE2功能,我们被告知,在将来的微体系结构设计中可以期望见到这种扩展。


与我们在V1上看到的细节相比,Arm对N2微体系结构的披露相当有限。它属于尚未公开的下一代Cortex-A78内核的兄弟系列,除了值得注意的Armv9功能和新的SVE2流水线外,我们还需要等待几个月的时间才能确切地看到它与Cortex-A78相比有何不同之处。
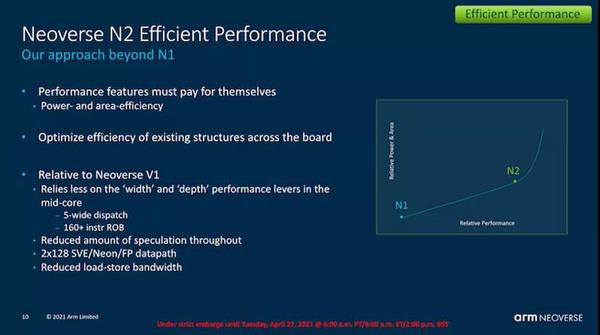

Arm确认了它是一个较窄的微体系结构-5-wide(V1中的8-wide),并且该设计具有2x128b原生SVE2和NEON流水线。


Arm指出,与Neoverse N1相比,新设计的IPC仍实现了令人印象深刻的40%的增长,考虑到我们承诺功率和面积和性能之间仅呈线性增长的事实,这实际上是非常重要的增长。


就“智能”(或更确切地说,是微体系结构创新)而言,N2是V1的超级集合,只是对块和结构大小采取了更保守的方法。
除MPMM和DT、PDP或“性能定义的功耗管理”之外,系统端功能是N2的一项新功能,该功能有望根据工作负载改变CPU的微体系结构功能,从而在不影响性能的情况下降低功耗。我想在这里,我们在谈论的是微架构功能与工作负载相关的更智能的时钟门控。