在某些场景我们可能需要识别出图片中的文字,为了高效而准确的识别文字,我们可以使用百度云的OCR来进行识别(部分功能可免费使用)。
官网文档地址:
百度云OCR文字识别
地址:
账号申请、登录
(百度网盘等账号皆可)
进入“控制台”,点击右上角个人头像进行实名认证(具体操作可根据文档指引,非常简单)
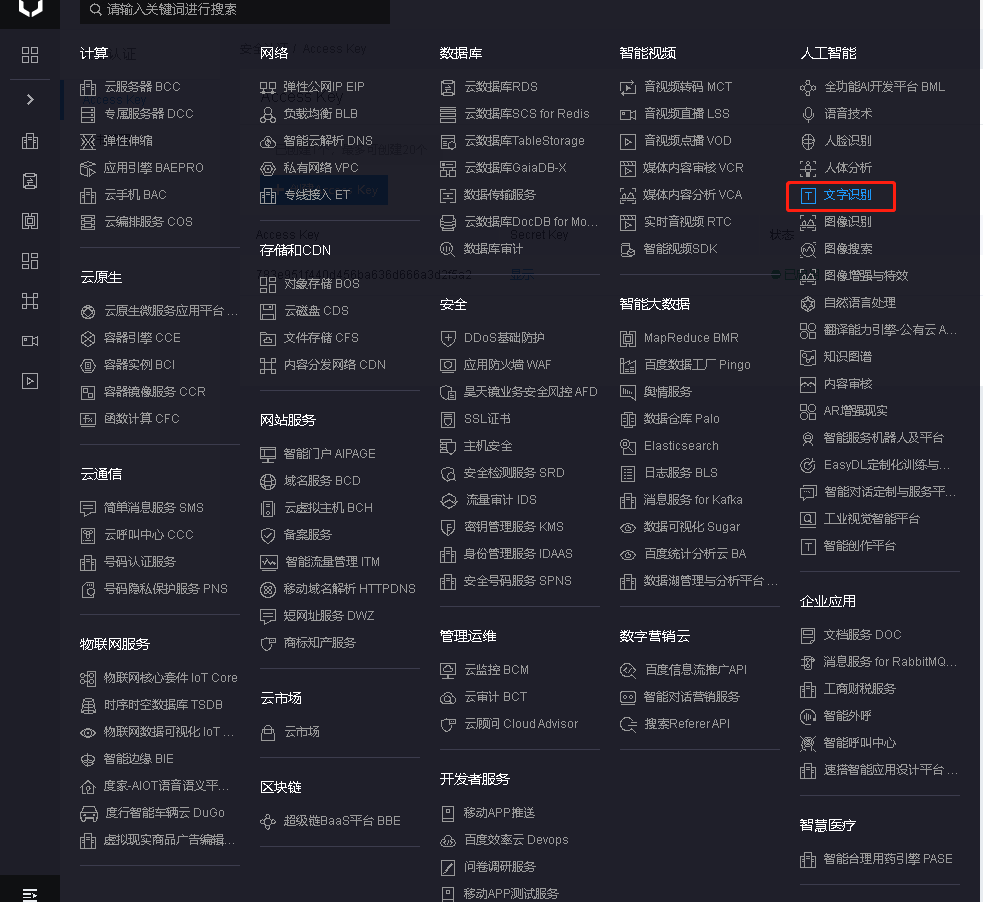
1、选择文字识别
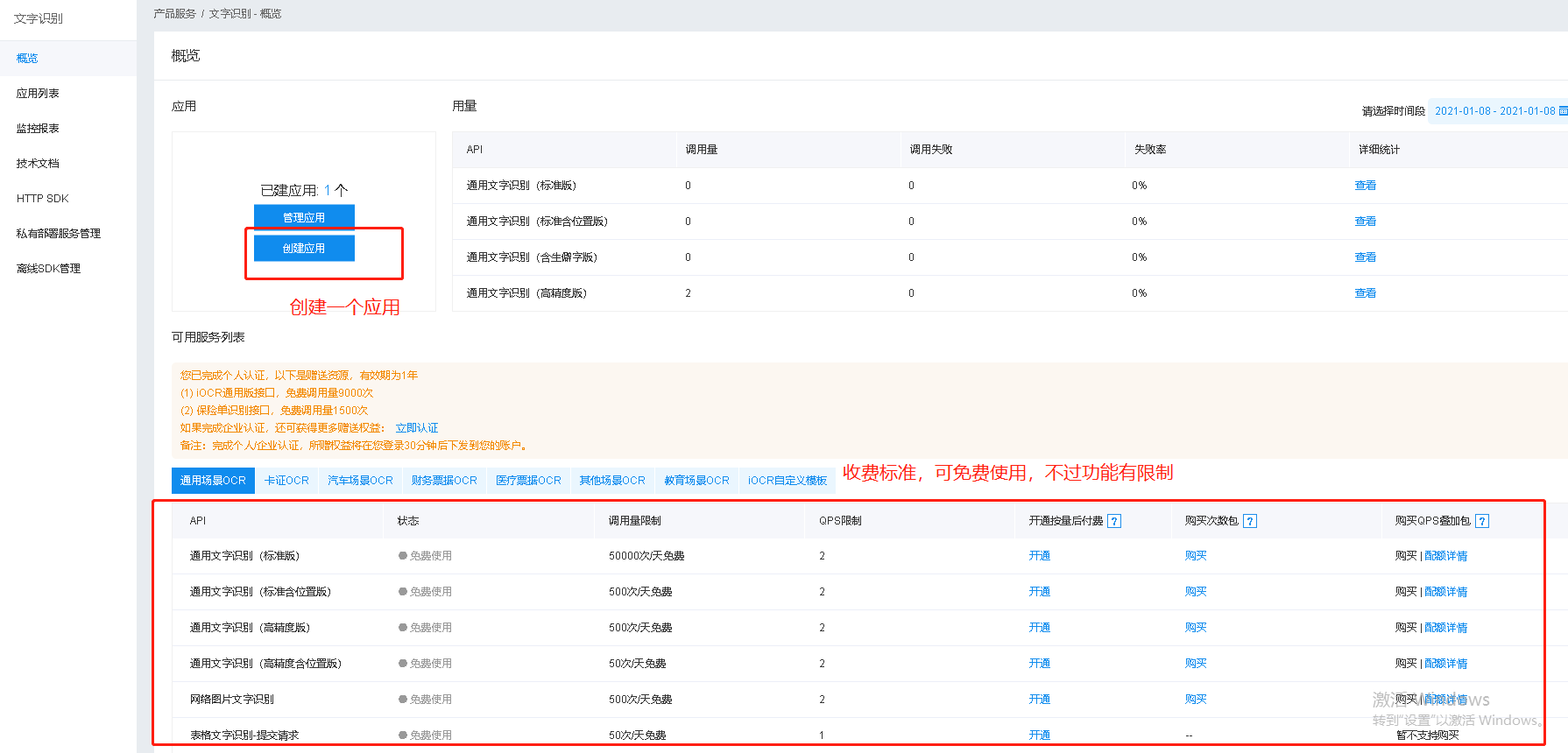
2、应用管理
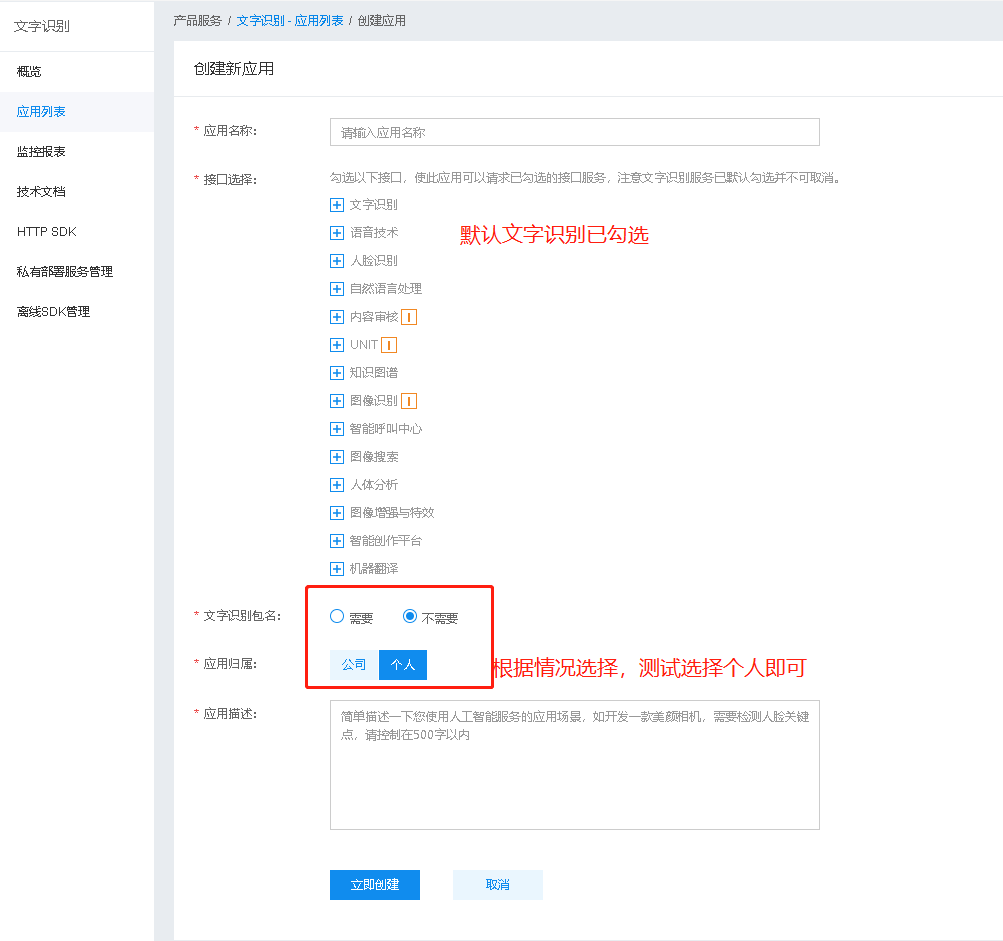
3、创建应用
4、复制API Key和Secret Key

至此,我们就拿到了API Key和Secret Key
文档地址:
获取access_token文档
* 获取token类
public
class
AuthService
{
* 获取权限token
* @return 返回示例:
* "access_token": "24.460da4889caad24cccdb1fea17221975.2592000.1491995545.282335-1234567",
* "expires_in": 2592000
public
static
String
getAuth
(
)
{
String clientId
=
"百度云应用的AK"
;
String clientSecret
=
"百度云应用的SK"
;
return
getAuth
(
clientId
,
clientSecret
)
;
* 获取API访问token
* 该token有一定的有效期,需要自行管理,当失效时需重新获取.
* @param ak - 百度云官网获取的 API Key
* @param sk - 百度云官网获取的 Securet Key
* @return assess_token 示例:
* "24.460da4889caad24cccdb1fea17221975.2592000.1491995545.282335-1234567"
public
static
String
getAuth
(
String ak
,
String sk
)
{
String authHost
=
"https://aip.baidubce.com/oauth/2.0/token?"
;
String getAccessTokenUrl
=
authHost
+
"grant_type=client_credentials"
+
"&client_id="
+
ak
+
"&client_secret="
+
sk
;
try
{
URL realUrl
=
new
URL
(
getAccessTokenUrl
)
;
HttpURLConnection connection
=
(
HttpURLConnection
)
realUrl
.
openConnection
(
)
;
connection
.
setRequestMethod
(
"GET"
)
;
connection
.
connect
(
)
;
Map
<
String
,
List
<
String
>
>
map
=
connection
.
getHeaderFields
(
)
;
for
(
String key
:
map
.
keySet
(
)
)
{
System
.
err
.
println
(
key
+
"--->"
+
map
.
get
(
key
)
)
;
BufferedReader in
=
new
BufferedReader
(
new
InputStreamReader
(
connection
.
getInputStream
(
)
)
)
;
String result
=
""
;
String line
;
while
(
(
line
=
in
.
readLine
(
)
)
!=
null
)
{
result
+=
line
;
* 返回结果示例
System
.
err
.
println
(
"result:"
+
result
)
;
JSONObject jsonObject
=
new
JSONObject
(
result
)
;
String access_token
=
jsonObject
.
getString
(
"access_token"
)
;
return
access_token
;
}
catch
(
Exception
e
)
{
System
.
err
.
printf
(
"获取token失败!"
)
;
e
.
printStackTrace
(
System
.
err
)
;
return
null
;
准备工作完毕,进入识别流程
1、去百度找一张带水印的文字图片,测试识别效果

2、程序识别
文档地址:
通用文字识别(高精度版)
* 重要提示代码中所需工具类
* FileUtil,Base64Util,HttpUtil,GsonUtils请从
* https://ai.baidu.com/file/658A35ABAB2D404FBF903F64D47C1F72
* https://ai.baidu.com/file/C8D81F3301E24D2892968F09AE1AD6E2
* https://ai.baidu.com/file/544D677F5D4E4F17B4122FBD60DB82B3
* https://ai.baidu.com/file/470B3ACCA3FE43788B5A963BF0B625F3
public
static
String
accurateBasic
(
)
{
String url
=
"https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic"
;
try
{
String filePath
=
"F:\\study\\src\\main\\resources\\static\\img\\水印文字.jpg"
;
byte
[
]
imgData
=
FileUtil
.
readFileByBytes
(
filePath
)
;
String imgStr
=
Base64Util
.
encode
(
imgData
)
;
String imgParam
=
URLEncoder
.
encode
(
imgStr
,
"UTF-8"
)
;
String param
=
"image="
+
imgParam
;
String accessToken
=
"24.8a39f0c435cbecbfeb8b85f85f301a91.2592000.1612680267.282335-235xxxxx"
;
String result
=
HttpUtil
.
post
(
url
,
accessToken
,
param
)
;
System
.
out
.
println
(
result
)
;
return
result
;
}
catch
(
Exception
e
)
{
e
.
printStackTrace
(
)
;
return
null
;
识别结果:
{"log_id": 3370872560323950059, "words_result_num": 20, "words_result": [{"words": "论徐则臣小说的神秘主义叙事"}, {"words": "⊙周文中国海洋大学文学与新闻传播学院,山东青岛266100"}, {"words": "摘要:细读徐则臣的小说,神秘的气息四处弥漫。小说中丰富的民间神秘文化是对传统志怪文化的接续然而其神"}, {"words": "秘背后所透视出的对灵魂的焦、对现代人性的考问,是明显溢出对所调神仙怪的猎奇或膜拜本土文学资源"}, {"words": "后是现代人的生存体验设造迷宫,设置陌生人和省略空缺等形式形成的神秘主义救事示出对先锋小说采用的现"}, {"words": "代主义形式的借鉴,而其始终不忘对社会现实生活的幕写与观照,又显现出对为神秘而神秘的尽情于语言和形式游"}, {"words": "戏的先锋主义的反拨可以说徐则臣的神秘主义叙事是融合了中国传统文学的题材和西方现代主义文学的形式"}, {"words": "蕴,它既是对标榜为现实主义的日渐平庸化的圈于琐日常生活的文学的抵抗也是于下破碎了的充满不确"}, {"words": "定性的现实的把握,是徐则臣所独有的对当下纯文学道路的探索"}, {"words": "关键词徐则臣小说神秘主义传统现代"}, {"words": "从2002年第一次公开发表短篇小说《忆秦娥到006年第一部小说集《鸭子是怎样飞上天的》出版,再到如今"}, {"words": "《路撒冷》这部历时六年的长篇巨作的出版,徐则臣作为新世纪以来备受关注的70后代表作家,显示出了旺盛的"}, {"words": "创作力。与此同时,评论界对其作品的解读也随着他创作的不断丰富与日俱增。纵观对徐则臣小说的评论,“京漂"}, {"words": "和“花街”系列的人物形象塑造、理想主义精神故乡叙事等是主要聚焦点,而对于显示徐则臣小说另一面向的“谜"}, {"words": "团”系列却未给予充分的关注。至于何为“谜团”系列这其实是一个比较昧不明的分类“在题材上它们或属于"}, {"words": "京漂,或属于故乡但又似乎都心不在焉”,这一系列小说的特点在于沉溺形而上的思索,具有浓郁的神秘主义"}, {"words": "息。而细读徐则臣的小说创作,我们会发现这种神秘主义气息实际上处处可见:身份背景不明或具有灵异能力的人"}, {"words": "物,神秘而恐怖的意象,曲折离奇的情节这些共同构成了徐则臣小说神秘主义叙事的特点神秘主义作为新时期"}, {"words": "文学的重要审美思潮,既植根于源远流长的中国传统的神秘文化,又接受了西方现代主义的滋养那徐则臣在面对"}, {"words": "地在微度且和主的的如由的地租"}]}
上传结果与原文基本一致,识别效果还是非常好的。官网还有很多识别方式,有兴趣的朋友可以尝试。
与第二条基本时一样的,只是从本地图片识别到了上传图片识别
<!DOCTYPE html>
<html lang="zh" xmlns:th="http://www.thymeleaf.org" >
<meta charset="UTF-8">
<title>Title</title>
</head>
<form th:action="@{/img}" method="post" enctype="multipart/form-data">
<p>ahdsfljkahsfodiahsoi</p>
<input type="file" name="file">
<input type="submit" value="submit">
</form>
</body>
</html>
@Controller
public class OcrController {
@GetMapping("/img")
public String getImage() {
return "imgtest";
@PostMapping("/img")
@ResponseBody
public void getIm(MultipartFile file) throws IOException {
AccurateBasic.accurateBasic(file.getBytes());
public static String accurateBasic(byte[] imgData) {
String url = "https://aip.baidubce.com/rest/2.0/ocr/v1/accurate_basic";
try {
String imgStr = Base64Util.encode(imgData);
String imgParam = URLEncoder.encode(imgStr, "UTF-8");
String param = "image=" + imgParam;
String accessToken = "24.8a39f0c435cbecbfeb8b85f85f301a91.2592000.1612680267.282335-235xxxxx";
String result = HttpUtil.post(url, accessToken, param);
System.out.println(result);
return result;
} catch (Exception e) {
e.printStackTrace();
return null;
识别结果与第二条基本一致,从上传到识别完毕大概4-5秒,识别度和速度非常不错了。
此处只是简单举例,更多功能可自行了解。
title: 使用百度云OCR识别文字date: 2021/01/11 21:22:30categories:后端tags:其他技术序言 在某些场景我们可能需要识别出图片中的文字,为了高效而准确的识别文字,我们可以使用百度云的OCR来进行识别(部分功能可免费使用)。官网文档地址:百度云OCR文字识别1、准备工作1.1 百度账号申请地址:账号申请、登录(百度网盘等账号皆可)1.2 账号实名认证 进入“控制台”,点击右上角个人头像进行实名认证(具体操作可根据文档指引,非常.
上篇《Java
使用 Tess4J 实现图片
识别文字》一文中虽然图片可以
识别中文,但是达不到预期的效果,所以今天抽出时间来整理记录一下关于
百度云OCR,相对于Tess4J来说,
识别度还可以
注册
百度AI的账号,具体参照http://ai.baidu.com/docs#/Begin/top获取密钥
1、下载java
文字识别SDKhttps://ai.baidu.com/sdk#
ocr
前言:之前配置好Android Studio后,一直在参与课程的两个项目,未能及时更新。今天验收好,跟大家分享一下其中我负责的相机相册调用以及实现文字识别的部分。
项目环境:
1、Android Studio 4.1.1
2、华为Nova 3e (安卓9)以及 华为 P20(安卓10)
3、百度智能云-文字识别OCR-通用文字识别(高精度版)
一、调用手机相机/相册
注意有些部分是文字识别的方法(已注明),如果不需要文字识别功能,则不需要其代码。
1.activity_main.xml和
各大厂现在已经开始进行技术变现,BAT三巨头的云服务都已经开始兜售,直接搜索每个官网就能看到一大堆各种花里胡哨的技术供你使用。像阿里的免费使用一个月,或者百度的免费使用多少次,总的来说,论新人上手,还是百度做的引导比较好。下面简述如何用百度云构建一个表格OCR软件,利用python。
不多说,自己上百度云官网,注册帐号。注意找到图像识别模块,建立一个新的应用。内容随便填,这里需要的是其AppID、API Key、Secret Key三个码。如图:
百度这边给了很多示例,并且把接口的参数
https://ai.baidu.com/tech/imagerecognition/general
腾讯
OCR体验地址:
https://cloud.tencent.com/act/event/
ocrdemo
测试结果是:腾讯的效果要比
百度的好
腾讯云目前(2020年2月16日)额度是:
每个接口 1,000次/月免费,有6个
文字识别的接口,一共是6,000次/月
百度接口调用之前写过文章
Python编程:通过
百度文字识别提取表格数据
使用步骤
1、注册账号: https://cloud.tencent.com/
2、开通服务:https://console.


