

【R语言】优雅的循环迭代:purrr包


用 R 写 循环 从低到高有三种境界:手动 for 循环,apply 函数族,purrr 包泛函式编程。
补充一点, 关于purrr 与 apply 族 :purrr 提供了更多的一致性、规范性和便利性,更容易记住和使用。速度来说,apply 族稍微快可以忽略不计的一丢丢。
本篇来谈一谈用 purrr 包优雅地做循环迭代。
先总述一下 purrr 包做泛函式循环迭代的核心思想,以及将要介绍的常用操作:
循环迭代, 就是将一个函数依次应用(映射)到序列的每一个元素上。
- map():依次应用一元函数到一个序列的每个元素上,基本等同 lapply()
- map2():依次应用二元函数到两个序列的每对元素上
- pmap():应用多元函数到多个序列的每组元素上,可以实现对数据框逐行迭代
- map 系列默认返回列表型,可根据想要的返回类型添加后缀:_int, _dbl, _lgl, _chr, _df, 甚至可以接着对返回的数据框df做行/列合并:_dfr, _dfc
- 如果只想要函数依次作用的过程,而不需要返回结果,改用 walk 系列即可
- 所应用的函数,有 purrr公式风格简写(匿名函数),支持一元,二元,多元函数
- purrr 包中的其它有用函数
下面结合实例具体展开。
先加载包:
library(tidyverse)一. 预备知识
- 几个必要的概念
(1) 序列 :姑且这么叫吧,即可根据位置或名字进行索引的数据结构,包括
- 原子向量 (各个值都是同类型的,包括 6 种类型:logical、integer、double、character、complex、raw,其中 integer 和 double 也统称为numeric)
- 列表 (各个值是不同类型的)
所谓循环迭代,就是依次在序列上做相同的操作。
(2) 泛函式编程: 函数的函数称为泛函,在编程中表示函数作用在函数上,或者说函数包含其它函数作为参数。
循环迭代,本质上就是将一个函数依次应用(映射)到序列的每一个元素上。表示出来不就是泛函式:map(x, f)
(3) 管道 :管道可以将数据从一个函数传给另一个函数,从而用若干函数构成的管道就能依次变换你的数据。例如:
x %>% f() %>% g() # 等同于 g(f(x))使用管道的好处是:提高程序可读性,避免引入不必要的中间变量。
对该管道示例应该这样理解:
依次对数据进行若干操作:先对 x 进行 f 操作, 接着对结果进行 g 操作
注: 数据经过管道默认传递给函数的第一个参数(表现为省略);若在非第一个参数处使用该数据,用 "." 代替,这使得管道作用更加强大和灵活。
2. 循环迭代返回类型的控制
map 系列函数都有后缀形式,以决定循环迭代之后返回的数据类型,这是 purrr 比 apply函数族更先进和便利的一大优势。常用后缀如下:
- map_chr(.x, .f): 返回字符型向量
- map_lgl(.x, .f): 返回逻辑型向量
- map_dbl(.x, .f): 返回实数型向量
- map_int(.x, .f): 返回整数型向量
- map_dfr(.x, .f): 返回数据框列表,再 bind_rows 按行合并为一个数据框
- map_dfc(.x, .f): 返回数据框列表,再 bind_cols 按列合并为一个数据框
3. purrr 风格公式(匿名函数)
在序列上做循环迭代(应用函数),经常需要自定义函数,但有些简单的函数也用 function 定义一番,毕竟是麻烦和啰嗦。所以,purrr 包提供了对 purrr 风格公式(匿名函数)的支持。
熟悉其它语言的匿名函数的话,很自然地就能习惯。
前面说了,purrr 包实现迭代循环是用 map(x, f),f 是要应用的函数,想用匿名函数来写它,它要应用在序列 x 上,就是要和序列 x 相关联,那么就限定用序列参数名关联好了,即 将该 序列参数名 作为匿名函数的参数使用 :
- 一元函数:序列参数是 .x
比如,f(x) = x^2 + 1, 其 purrr 风格公式(匿名函数)就写为:~ .x ^ 2 + 1
- 二元函数:序列参数是 .x, .y
比如,f(x, y) = x^2 - 3 y, 其 purrr 风格公式(匿名函数)就写为:~ .x ^ 2 - 3 * .y
- 多元函数:序列参数是 ..1, ..2, ..3, 等
比如,f(x, y, z) = ln(x + y + z), 其 purrr 风格公式(匿名函数)就写为:~ log(..1 + ..2 + ..3)
注 :所有序列参数,可以用 ... 代替,比如,sum(..1, ..2, ..3) 同 sum(...)
二. map(): 依次应用一元函数到一个序列的每个元素上
map(.x, .f, ...)
map_*(.x, .f, ...)其中,.x 为序列
.f 为要应用的一元函数,或 purrr 风格公式(匿名函数)
... 可设置函数 .f 的其它参数
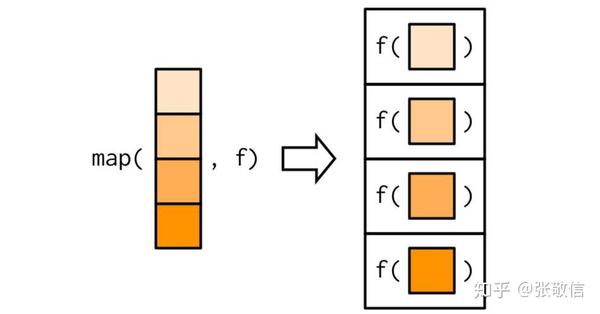
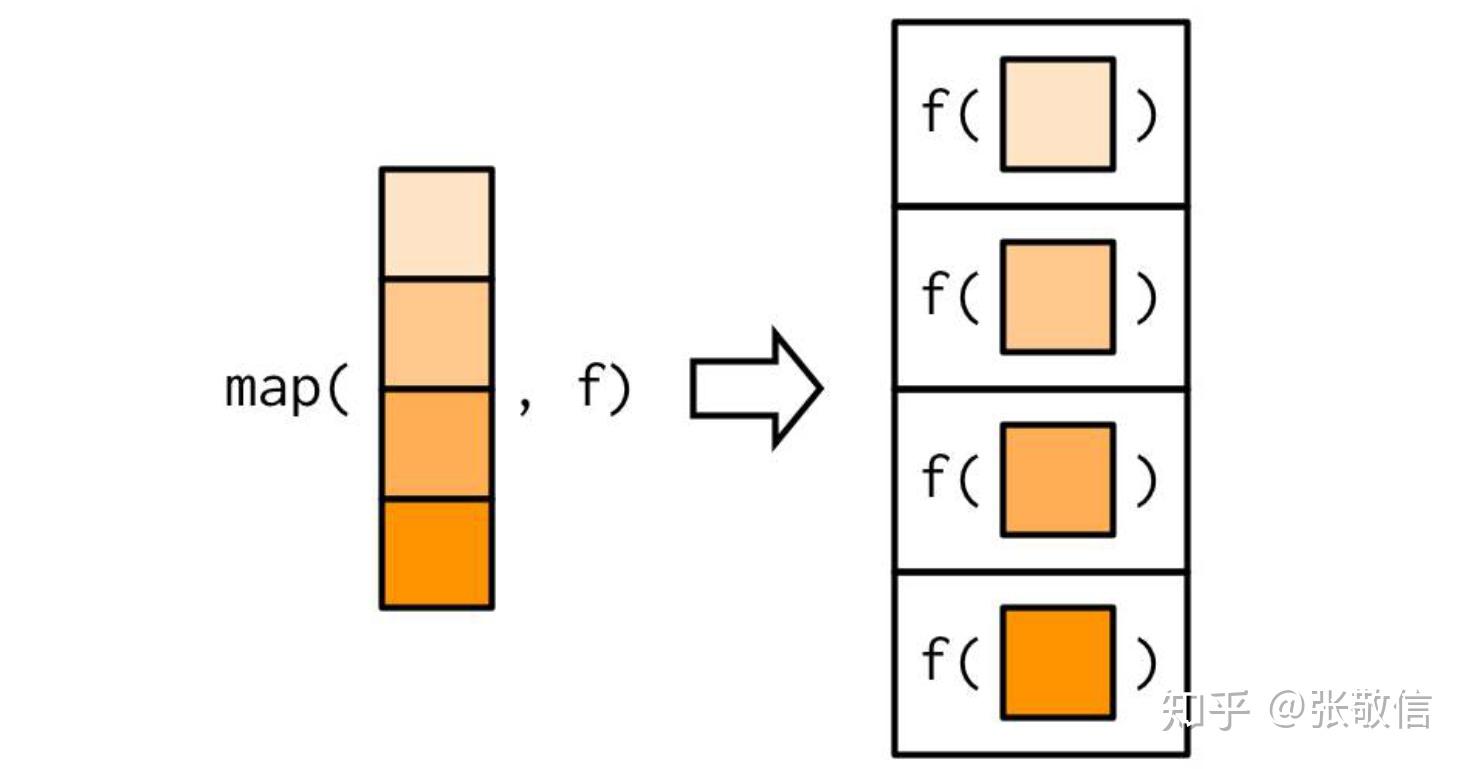
例1 计算 iris 前4列,每列的均值
即依次将 mean() 函数,应用到第1列,第2列,...
df = iris[, 1:4]
map(df, mean)
说明 :df 是数据框(特殊的列表),作为序列其元素依次是:df[[1]], df[[2]], ...... 所以,map(df, mean) 相当于依次计算:mean(df[[1]]), mean(df[[2]]), ......
可见,返回结果是相同的数值,所以更好的做法是,控制返回结果为数值向量,只需:
map_dbl(df, mean)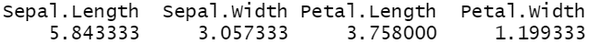

mean()函数还有其它参数,如 na.rm,若上述计算过程需要设置忽略缺失值,只需:
map_dbl(df, mean, na.rm = TRUE) # 因为数据不含NA, 故结果同上(略)purrr风格公式写法:
map_dbl(df, ~mean(.x, na.rm = TRUE)) # 结果同上(略)例2 批量读取数据文件并合并(列名相同)
files = list.files("datas/", pattern = "xlsx", full.names = TRUE)
df = map_dfr(files, read_xlsx) # 批量读取+按行堆叠合并说明: files 获取 datas 文件夹下所有 .xlsx 文件的路径,若嵌套只需设置参数 recursive = TRUR;
map_dfr(files, read_xlsx) 依次将 read_xlsx() 函数应用到各个文件路径上,即依次读取数据,返回结果是数据框,同时“r”表示再做按行合并,一步到位。若需要设置 read_xlsx() 的其它参数,只需在后面设置即可。
例3 批量建模。
根据分类变量对数据进行分组,对每组分别建模,再提取模型信息:
df = mtcars %>%
select(mpg, cyl, wt)
df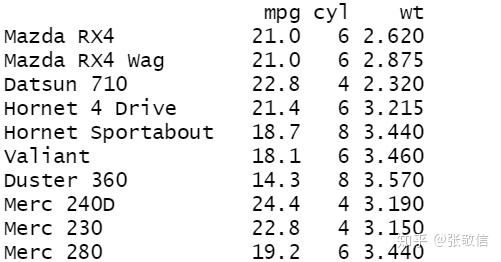
df = df %>%
group_nest(cyl) # 嵌套数据框(列表列)
df
df$data[[1]]
df = df %>%
mutate(model = map(data, ~ lm(mpg ~ wt, data = .x)), # 分组建模
pred = map(model, predict)) # 计算每个样本的预测值
df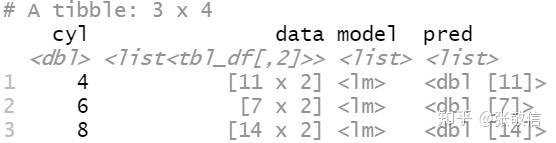

df$model %>%
map(summary) %>%
map_dbl("r.squared") # 用列表的元素名做 map 相当于提取该元素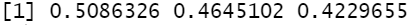
df$model %>%
map(broom::tidy) # 模型参数信息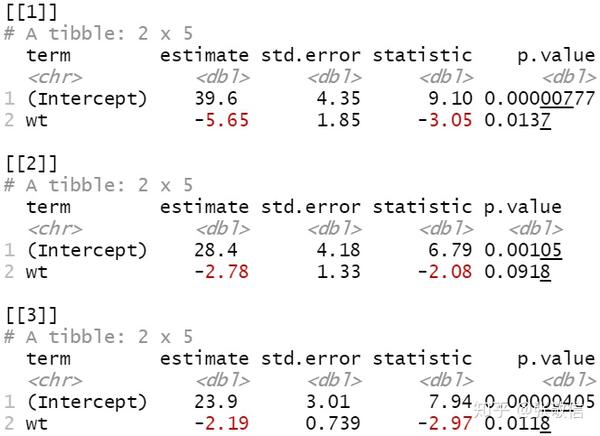

df$model %>%
map(broom::glance) # 模型评估信息

df %>%
unnest(c(data, pred)) # 解除嵌套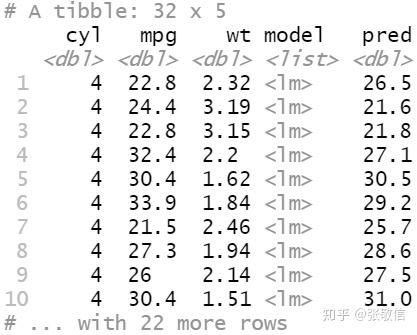
注: 有了 map() 函数,对于自定义一元函数只接受标量,比如 f(x), 想要让它支持接受向量作为输入,根本不需要改造原函数,只需:
map_*(xs, f) # xs表示若干个x构成的向量三. map2(): 依次应用二元函数到两个序列的每对元素上
map2(.x, .y .f, ...)
map2_*(.x, .y, .f, ...)其中,.x 为序列1
.y 为序列2
.f 为要应用的二元函数,或 purrr 风格公式(匿名函数)
... 可设置函数 .f 的其它参数
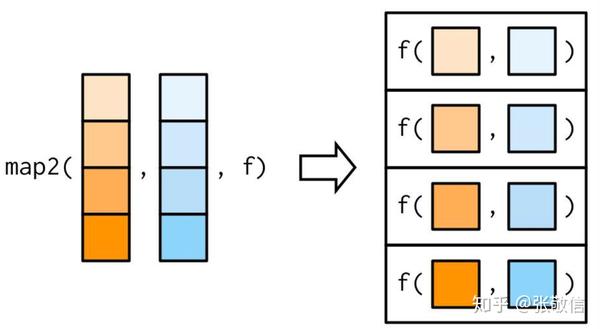
例4 根据身高、体重数据计算BMI指数
height = c(1.58, 1.76, 1.64)
weight = c(52, 73, 68)
cal_BMI = function(h, w) w / h^2 # 定义计算BMI的函数
map2_dbl(height, weight, cal_BMI)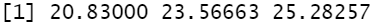
说明: 序列1其元素为:height[[1]], height[[2]], ......
序列2其元素为:weight[[1]], weight[[2]], ......
所以,map2_dbl(height, weight, cal_BMI) 相当于依次计算:
cal_BMI(height[[1]], weight[[1]]), cal_BMI(height[[2]], weight[[2]]), ......
更简洁的purrr风格公式写法(省了自定义函数):
map2_dbl(height, weight, ~ .y / .x^2) # 结果同上(略)数据若是在数据框中,也同样使用:
df = tibble(height = height, weight = weight)
df %>%
mutate(bmi = map2_dbl(height, weight, cal_BMI)) 
purrr 风格公式写法(省了自定义函数):
df %>%
mutate(bmi = map2_dbl(height, weight, ~ .y / .x^2))四. pmap(): 应用多元函数到多个序列的每组元素上,可以实现对数据框逐行迭代
我最先学习 pmap() 是在 Hadley 的《R for Data Science》,讲到将(多元)函数应用到更多序列上,多个序列是多个列表的形式。
这个理解就一直很模糊,用着也不顺手。最近,我突然醍醐灌顶:
多个序列得长度相同,长度相同的列表,不就是数据框吗!那么所谓的多元迭代不就是依次在数据框的每一行上迭代吗!!
理解到这一点(抛弃列表,不影响使用)后,豁然开朗,再使用 pmap() 时也不再模糊和难用。
pmap(.l, .f, ...)
pmap_*(.l, .f, ...)其中,.l 为数据框,
.f 为要应用的多元函数
... 可设置函数 .f 的其它参数
注 :.f 是几元函数,对应数据框 .l 有几列,.f 将依次在数据框 .l 的每一行上进行迭代。
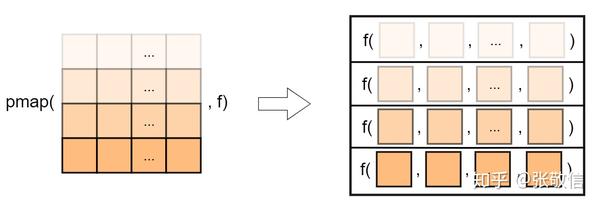

注 :前两个示意图引用别人的,这个图是我现做的。
例5 分别生成不同数量不同均值、标准差的正态分布随机数。
df <- tibble(
n = c(1,3,5),
mean = c(5,10,-3),
sd = c(1,5,10)
df
set.seed(123)
pmap(df, rnorm)

说明 :这里的 rnorm(n, mean, sd) 是三元函数,pmap(df, rnorm) 相当于将三元函数 rnorm() 依次应用到数据框 df 的每一行上,即依次执行:
rnorm(1, 5, 1), rnorm(3, 10, 5), rnorm(5, -3, 10)
特别注意 ,这里 df 中的列名,必须与 rnorm() 函数的参数名相同(列序随便)。若要避免这种局限,可以使用 purrr 风格公式写法:
names(df) = c("n", "m", "s")
df
set.seed(123)
pmap(df, ~ rnorm(..1, ..2, ..3)) # 结果同上(略), 或者简写为
pmap(df, ~ rnorm(...))例6 对数据框逐行操作。
dplyr 包中提供了 rowwise() 将数据框“行化”,可以实现按行操作数据(速度较慢)。
pmap_*() 是另一种行化操作数据框的办法。
df = crossing(x = 0.3, y = 1:3, z = 1:3)
df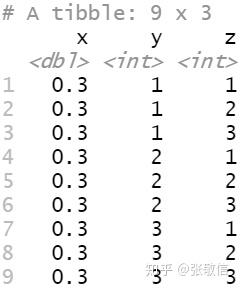
下面计算3个新列:第1列占第2,3列之和的比例、计算三列的平均值、将三列合并到一起用"-"间隔。
df %>%
mutate(r = pmap_dbl(., ~ ..1 / (..2 + ..3)),
m = pmap_dbl(., ~ mean(c(...))),
a = pmap_chr(., str_c, sep = "-"))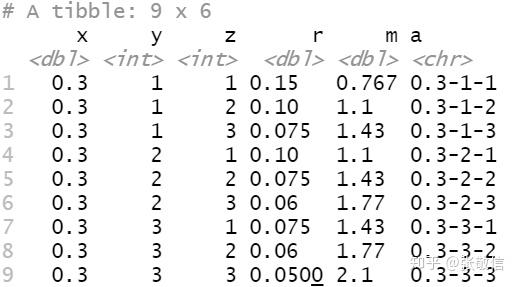

注: 将多个函数依次应用到序列,可以用 invoke_map_*(.f, .x, ...) 系列,相当于依次执行:
.f[[1]](.x, ...)
.f[[2]](.x, ...)
......
五. walk 系列:将函数依次作用到序列上,不返回结果
有些批量操作是没有或不关心返回结果的,例如批量保存到文件:save(), write_csv() 等。
这就需要:
walk(.l, .f, ...)
walk2(.l, .f, ...)
pwalk(.l, .f, ...)
例7 将 mpg 按 manufacturer 分组,每个 manufacturer 的数据分别保存为单独数据文件。
df = mpg %>%
group_nest(manufacturer) 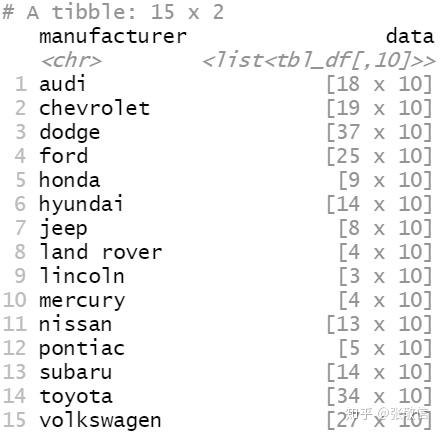

df %>%
pwalk(
~ write_csv(..2, paste0("datas/", ..1, ".csv"))
)
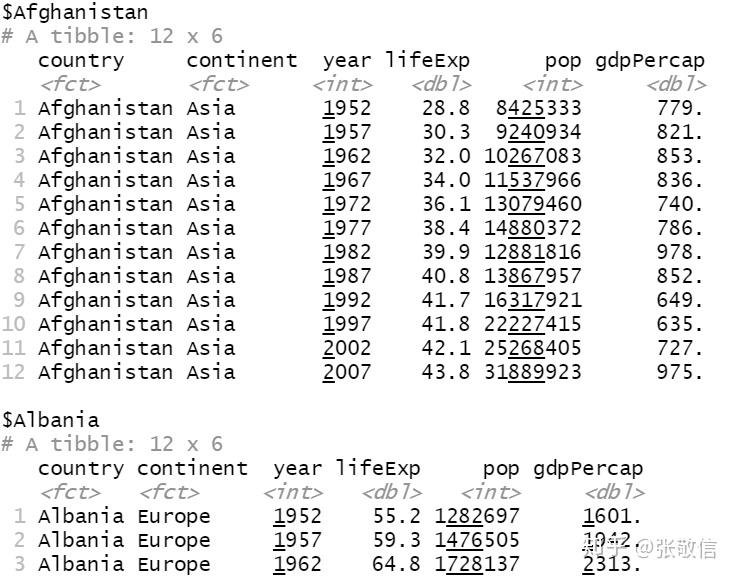
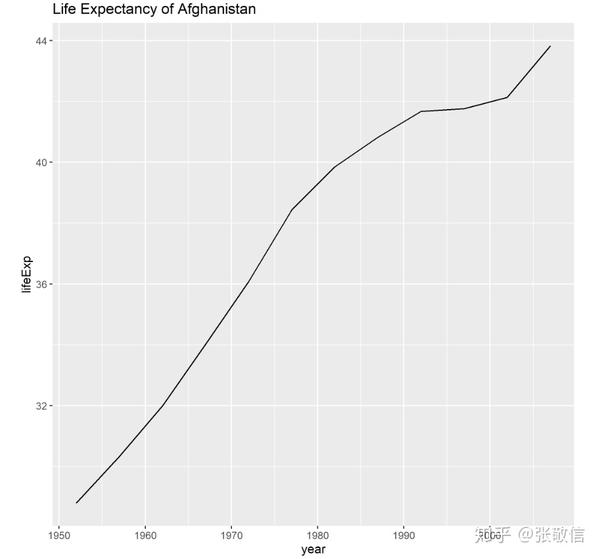
例8 选择前10个国家的数据,绘制预期寿命随年份变化的图,并分别保存为图形文件。
df = repurrrsive::gap_split[1:10]
df # 部分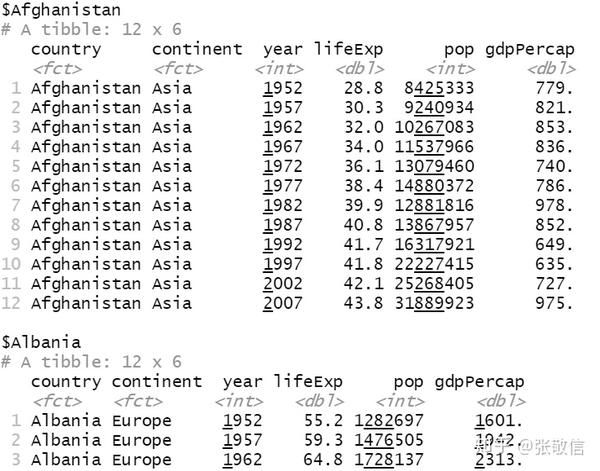
walk(df,
~ ggsave(paste0("datas/", .x$country[1], ".png"),
ggplot(.x, aes(year, lifeExp)) +
geom_line() +
ggtitle(paste("Life Expectancy of", .x$country[1]))
)

六. 其它有用函数
- reduce()
函数 reduce() 可先对序列前两个元素应用函数,再对结果与第3个元素应用函数,再对结果与第4个元素应用函数,……直到所有的元都被“reduced”。例如,
reduce(1:100, sum)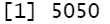
例9 批量数据连接。
dplyr 包提供了六种常用的数据连接:left_join(), right_join(), full_join(), inner_join(), semi_join(), anti_join().
但是这些连接都只支持两个数据表做连接。如果连接多个数据表呢?用 reduce() 就能实现。
比如,datas 文件夹下有3个xlsx文件:

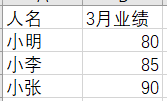
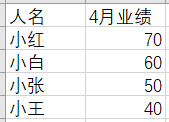
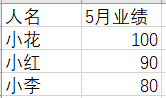
注意,3个数据表中的人名是有重复的,所以不能简单按行堆叠。
实际上,这是将所有信息都合并到一起,即做全连接。又因为是多表依次做连接,再结合 reduce() 就能实现。
files = list.files("datas/", pattern = "xlsx", full.names = TRUE)
df = map(files, readxl::read_xlsx) %>%
reduce(full_join, by = "人名") # 读入并依次做全连接