宽为限 紧用功 功夫到 滞塞通
什么是自定义搜索?
Google自定义搜索可以为您的网站,博客或网站集合创建搜索引擎。您可以配置搜索引擎来搜索网页和图像。您可以调整排名,自定义搜索结果的外观,并邀请您的朋友或信任的用户来帮助您构建自定义搜索引擎。您甚至可以通过使用您的Google AdSense帐户从您的搜索引擎赚钱。
自定义搜索有两个主要用例 - 您可以创建仅搜索一个网站(网站搜索)内容的搜索引擎,也可以创建一个专注于多个网站的特定主题的搜索引擎。您可以使用您的专业知识来告诉自定义搜索哪些网站要搜索,优先排序或忽略。因为你很熟悉你的用户,你可以根据自己的兴趣来定制搜索引擎。
使用Google自定义搜索,您可以:
-
创建自定义搜索引擎,搜索指定的网站或网页集合
-
为您的网站启用图像搜索
-
自定义搜索结果的外观和风格,包括添加搜索即时类型的自动填充
-
将促销活动添加到搜索结果中
-
利用您网站上的结构化数据来自定义搜索结果
-
将您的搜索引擎与您的Google AdSense帐户关联起来,以便每当用户在搜索结果页上点击广告时赚取收益。
这里我们讲简单的使用
创建自己的搜索引擎
创建
https://cse.google.com/cse/create/new
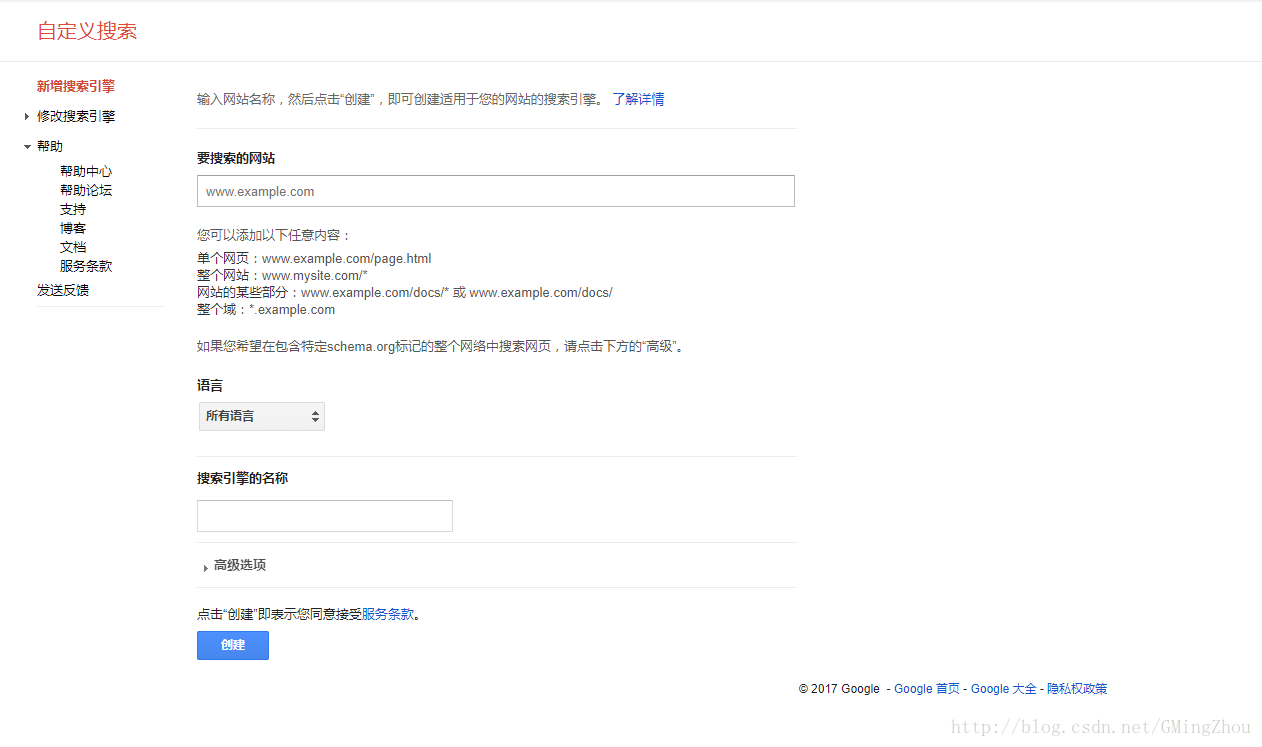
管理
https://cse.google.com/cse/all
选中创建的搜索引擎,进入即可对其自定义设置。
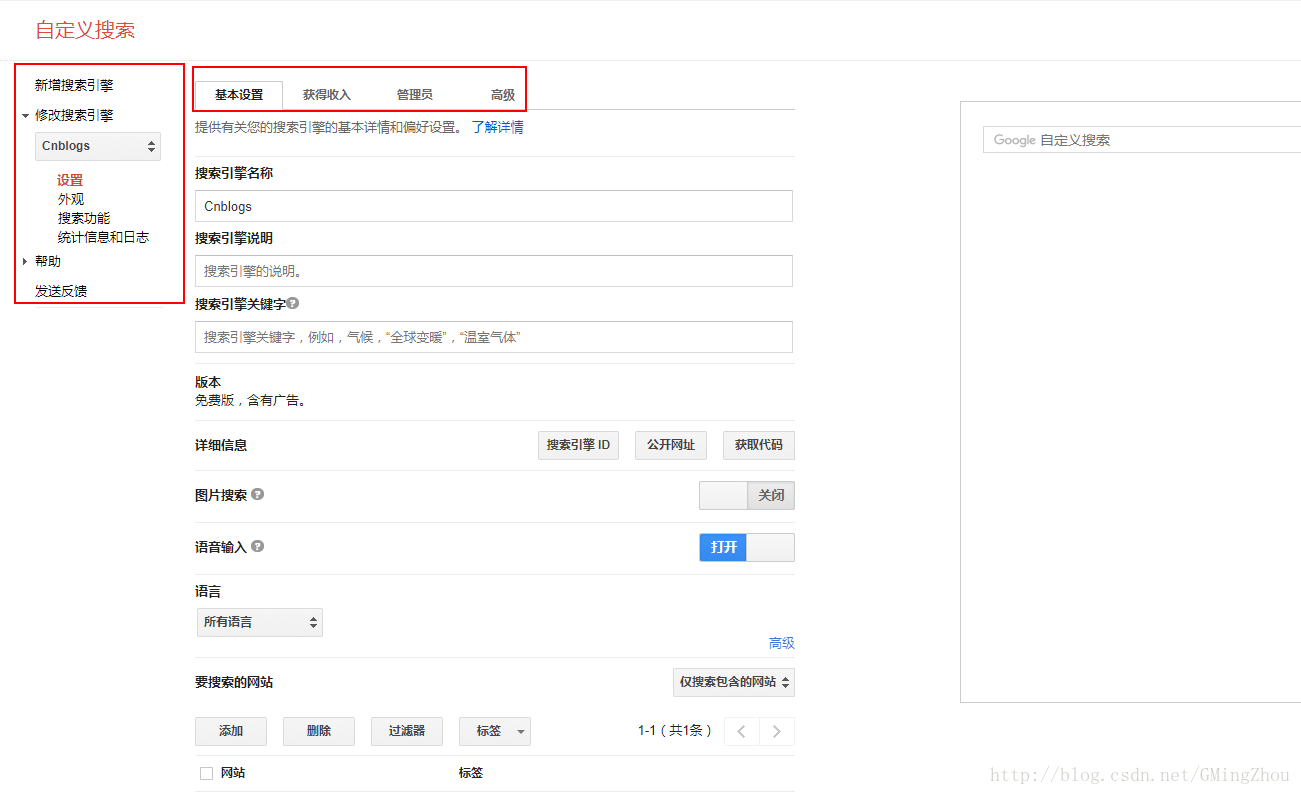
使用搜索引擎
点进搜索引擎管理界面,详细信息 点获取代码即可。
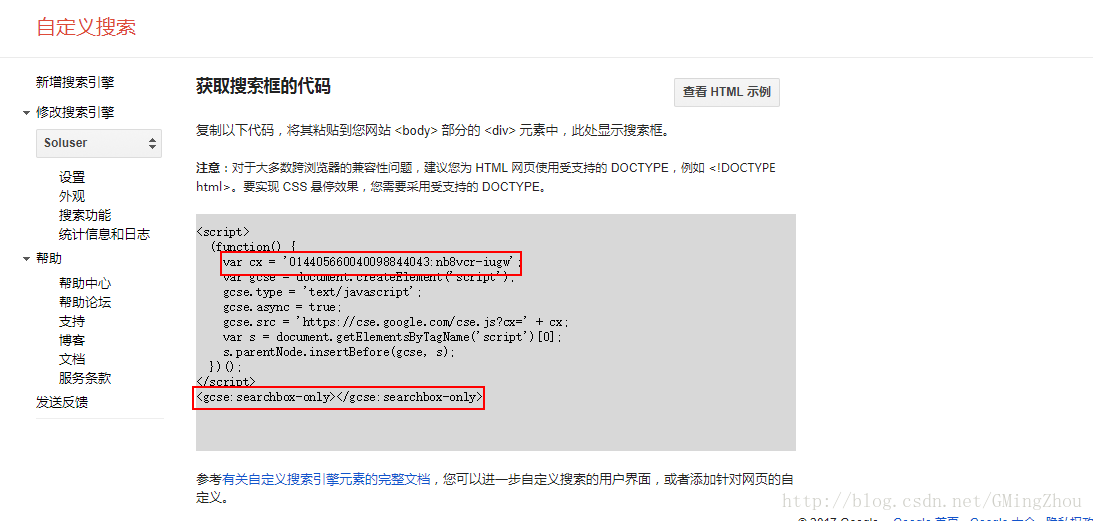
cx
是自定义搜索引擎ID
<gcse:searchresults-only>
是搜索展示方式
搜索展示方式有如下几种:
|
元素类型
|
组件
|
描述
|
|
标准
|
<gcse:search>
|
一个搜索框和搜索结果,显示在同一个
<div>
。
|
|
两列
|
<gcse:searchbox>
和
<gcse:searchresults>
|
两列布局,一侧有搜索结果,另一边是搜索框。如果您打算在网页中以两列模式插入多个元素,则可以使用该gname属性将搜索框与搜索结果块进行配对。
|
|
仅结果
|
<gcse:searchresults-only>
|
独立的搜索结果块。
|
|
谷歌托管
|
<gcse:searchbox-only>
|
独立搜索框。
|
放到自己的网站上时会发现它的样式不是很好调整,如出现下面这种情况

这里我也没专门去研究样式问题,通过多次测试发现了它搜索时url的拼接方式
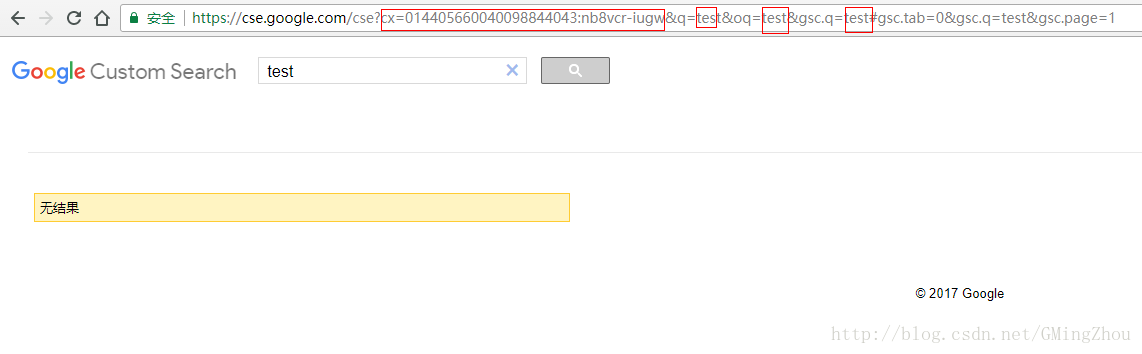
所以我们就可以按原来的页面设计只需将搜索跳转地址给拼接好替换掉就OK啦!
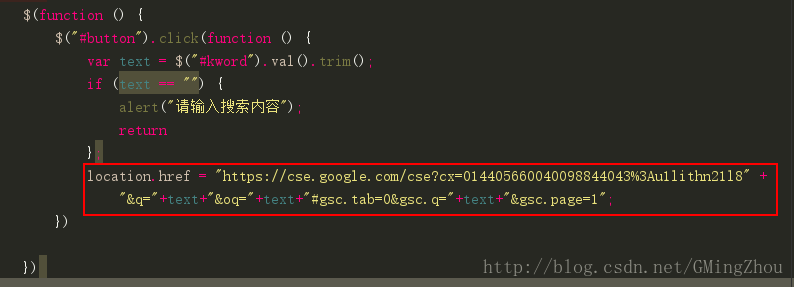
页面还是原来的配方还是原来的味道。

站在巨人的肩膀上
本篇博文参考的文章
https://developers.google.com/custom-search/
宽为限 紧用功 功夫到 滞塞通什么是自定义搜索?Google自定义搜索可以为您的网站,博客或网站集合创建搜索引擎。您可以配置搜索引擎来搜索网页和图像。您可以调整排名,自定义搜索结果的外观,并邀请您的朋友或信任的用户来帮助您构建自定义搜索引擎。您甚至可以通过使用您的Google AdSense帐户从您的搜索引擎赚钱。自定义搜索有两个主要用例 - 您可以创建仅搜索一个网站(网站搜索)内容的搜索引擎,也可
搜索能力是被绝大多数人低估的一项基本素质,绝大部分做编程技术相关的朋友应该都知道如何使用
Google
,但是并不知道如何
利用
它的潜力。其实不管是
Google
还是 百度,会搜索的人一样都可以查找到需要的东西,不会搜索的人用什么都不好使。下面介绍一些
Google
常用的搜索技巧以及搜索快捷方式,可以帮助你更快,更准确地找到结果。
Google
是世界上功能最强大的
搜索引擎
,它已经改变了我们查找信息的方式。
0. 使用准确的词组
将您要搜索的关键字用引号引起来,
Google
会
进行
精确的词组搜索。
在这篇文章中,我将向您展示如何使用Python构建自己的答案查找系统。基本上,这种自动化可以从图片中找到多项选择题的答案。
有一件事我们要清楚,在考试期间不可能在互联网上搜索问题,但是当考官转过身去的时候,我可以很快地拍一张照片。这是算法的第一部分。我得想办法把这个问题从图中提取出来。
似乎有很多服务可以提供文本提取工具,但是我需要某种API来解决此问题。最后,
Google
的VisionAPI...
在
进行
关键词搜索时,下载PDF文件是一个常见的需求。而Python作为一种强大的编程语言,提供了多种方法来实现这一功能。
首先,我们可以使用Python的requests库来发送HTTP请求并获取网页内容。通过使用requests库的get方法,我们可以访问
搜索引擎
或特定网站,并使用关键词
进行
搜索。然后,可以使用正则表达式来解析网页内容,找到与PDF文件相关的链接或URL。
其次,我们可以使用Python的BeautifulSoup库来解析HTML文档。通过使用BeautifulSoup库的find_all方法,我们可以找到与PDF文件相关的链接或URL。然后,可以使用Python的urllib库来下载这些PDF文件。
另外,如果我们使用专门用于爬虫的库,如Scrapy,我们可以通过编写爬虫程序自动
进行
关键词搜索和PDF文件下载。
总的来说,Python提供了很多方便的库和工具来实现关键词搜索并下载PDF文件。我们可以根据具体需求选择适合的方法,实现自动化、高效率的搜索与下载。
### 回答2:
关键词搜索和下载PDF文档是Python编程语言中常见的需求。为了实现这个功能,我们可以使用一个叫做"requests"的Python库来发送HTTP请求,并用"beautifulsoup"来解析HTML文档。
首先,我们需要安装这两个库,可以使用以下命令:
pip install requests beautifulsoup4
然后,我们可以编写一个Python脚本,首先使用requests库发送一个GET请求,将关键词作为查询参数,搜索相关的PDF文档。例如,在
Google
上搜索"关键词",并限定为PDF文档,可以使用以下URL:https://www.
google
.com/search?q=关键词+filetype:pdf
我们可以使用以下代码来发送请求并获取搜索结果页面的HTML内容:
```python
import requests
keyword = "关键词"
url = "https://www.
google
.com/search?q=" + keyword + "+filetype:pdf"
response = requests.get(url)
html_content = response.text
接下来,我们可以使用beautifulsoup库来解析HTML内容,并提取搜索结果中的PDF文档的下载链接。通常情况下,PDF文档的下载链接会包含".pdf"后缀。以下是一个简单的例子:
```python
from bs4 import BeautifulSoup
soup = BeautifulSoup(html_content, "html.parser")
pdf_links = []
for link in soup.find_all("a"):
href = link.get("href")
if href.endswith(".pdf"):
pdf_links.append(href)
print(pdf_links)
最后,我们可以使用Python的文件操作功能来下载PDF文档到本地文件夹。以下是一个简单的示例:
```python
import urllib
for link in pdf_links:
filename = link.split("/")[-1]
urllib.request.urlretrieve(link, filename)
print("已下载文件:", filename)
通过上述步骤,我们可以实现关键词搜索并下载PDF文档的功能。当然,此代码只是一个简单示例,如果要实现更复杂的功能,可能需要处理异常情况、使用代理服务器等。
### 回答3:
关键词“搜索 下载pdf python”可以理解为
利用
Python编程语言在互联网上
进行
搜索并下载PDF文件。首先,我们需要使用Python中的网络请求库,如requests库,来发送HTTP请求并获取搜索结果页面。可以使用requests库中的get()方法,并指定
搜索引擎
的URL以及相关的搜索关键词。
接下来,我们需要使用Python的HTML解析库,如BeautifulSoup库,来解析搜索结果页面的HTML结构,以便提取出PDF文件的下载链接。可以
利用
BeautifulSoup的find_all()方法来定位搜索结果中所有的链接,并通过筛选条件来找出符合PDF文件的下载链接。
一旦获取了PDF文件的下载链接,我们就可以使用Python的文件操作模块,如os和urllib库,来下载并保存这些PDF文件。可以使用urllib库中的urlretrieve()方法,并指定PDF文件的下载链接和本地保存路径,来实现PDF文件的下载过程。同时,我们还可以
利用
os库中的mkdir()方法来
创建
保存PDF文件的文件夹。
整个过程可以通过编写Python脚本来完成,并可以根据具体需求添加一些错误处理和进度显示的代码,以提高程序的稳定性和使用体验。
总之,
利用
Python编程语言可以轻松地实现关键词搜索并下载PDF文件的功能,通过网络请求、HTML解析和文件操作等模块的配合,我们可以方便地获取所需的PDF文件并保存在本地。
mybatis 引用对象属性映射错误 or could not be found for the javaType (xxx.model) : jdbcType (null) combination.
24856

