


【CVPR 2023】由点到面:高泛化的流形对抗攻击,从对抗样本到对抗流形

都说对抗攻击已经做的没法做了,这次我们挖了一个新的“坑”,欢迎大家入坑。
从“点攻击“到“高泛化的流形攻击“,论文的题目如下。


论文代码: https:// github.com/tokaka22/GMA A
【对抗攻击要做什么】对抗攻击要解决的问题就是在图像上做一些不影响视觉感知的改变,但是能使得神经网络的输出的结果完全错误。因此,对抗攻击的目的有二:1、在图像上设计不影响视觉感知的改变;2、使得神经网络分类出错。例如,对邻家小姑娘的图片(原图)做一些些改变,人眼看上去还是这位小姑娘(被改变后图片,对抗样本,所在域为对抗域),但人脸识别系统把她和男明星莱昂纳多的图片识别为同一个人(被攻击的图片,目标图,所在域为目标域)。
【我们要做什么】我们对传统的对抗攻击模式提出了两方面的改进,提出了一种新的攻击范式。
1、Motivation
既然有两方面的改进,我们的动机自然也有两方面。
(1)针对目标域。先前的工作在设计对抗样本时,仅仅依赖于识别模型和莱昂纳多的某一张特定的图片,我们发现这样设计出来的对抗样本再去攻击小李子其他的照片时,攻击性能大幅变差了。这很有可能是因为这样设计出来的对抗样本特别适用于那张特定的图,其中的对抗因素都是为那张特定的图特质的,或者说对抗因素过度的关注于这张特定图中与身份无关的内容,例如表情、光线、环境,而没有很好的去攻击小李子这个身份的特征。
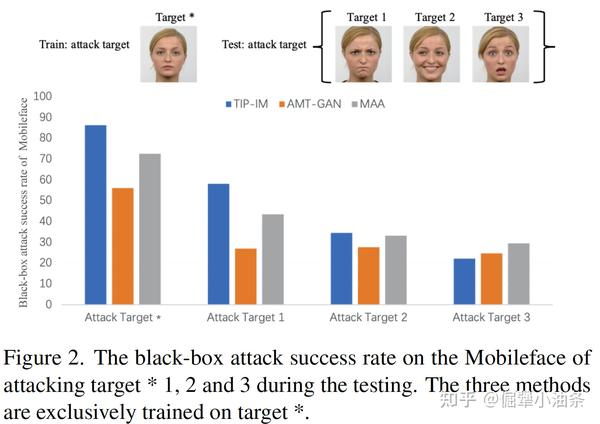
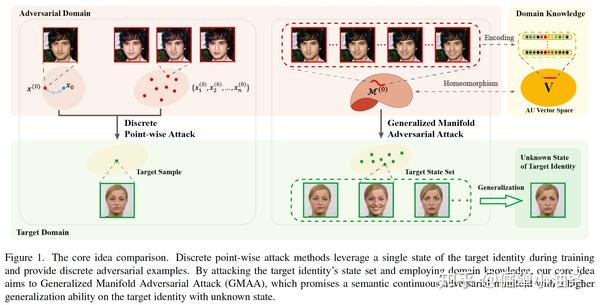
一个自然的想法就是,我们在设计对抗样本的时候不仅仅依赖于小李子的某一张照片了,而是依赖于小李子的一堆照片,即 在训练对抗样本时攻击目标身份的状态集合 。这个状态集合可以包含目标身份不同表情啊、光照啊、甚至不同年纪的照片啊。这样训练出来的对抗样本对与目标身份来说是具有 高泛化性的对抗样本。
(2)针对对抗域。先前的工作都是寻找一个或者几个对抗样本,对抗样本其实相当于神经网络的漏洞,在高维空间中找到了一个两个,或者好多个离散的漏洞,在我们看来是远远不够的,因为一个对抗样本的出现,可能意味着它所在的那一片区域对于神经网络而言都是脆弱的。我们也知道离散的点测度始终是0,用数学上的话说,找到再多这样离散的点,都是平凡的。因此,我们希望在高维样本空间中 找到一个对抗流形 ,在这个流形上的每一个点都是对抗样本。
结合(1)和(2),我们想要提出的对抗攻击新范式就呼之欲出了, 用一个对抗流形攻击目标的状态集合 ,这种新范式命名为GMAA( G eneralized M anifold A dversarial A ttack)。
在论文的后面除了GMAA,还会遇到MAA,MAA表示用对抗流形攻击目标的特定一张照片,即仅仅在对抗域上做了改进。还会遇到G-XXXX,表示把攻击状态集合这个setting加到了方法XXXX上,看看这种setting的通用性。
2、Method
这种新范式提出来后,我们给出了一个实例化的方法,当然除了我们这个方法,肯定还有很多别的方法可以套这个范式。
针对(1)中说的攻击状态集合,我们选择了表情状态,考虑到表情是人脸最普适的一种状态,人脸识别系统也应该对表情有较好的泛化能力。因此我们在训练对抗样本时,要求被训练的对抗样本攻击目标身份的表情状态集合。
针对(2)中说的寻找对抗流形,这里我们需要考虑的点就稍微多了一些。首先我们想实现的是在一个流形上采样出来的点都是对抗样本,并且呢,在连续采样的时候,采样出来的对抗样本也在某种形式上是连续的。其次,我们已经引入了表情状态空间,能不能做到在目标域和对抗域的统一。最终,我们想实现的具体样子就是,对于一个干净的样本,我们希望找到这个干净样本的一个对抗流形,在这个对抗流形上采样出来的都是这个干净样本的对抗样本,都能对目标状态集合有攻击性,在流形上连续的采样,采样出来的对抗样本的表情会连续的变化。
总的来说呢,我们找到了干净样本的表情对抗流形,用这个表情对抗流形攻击目标的状态集合,因此这个表情对抗流形还是高泛化的对抗流形。
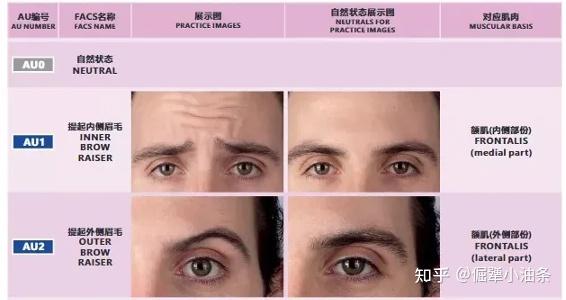
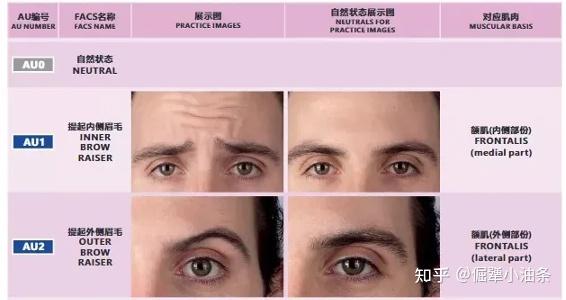
具体实现方案,就是引入了表情编辑的领域知识Facial Action Coding System (FACS),FACS是一种面部表情编码系统,它将面部分为不同的肌肉单元,其中AU向量中的每个元素都对应了一个肌肉单元,向量元素值的大小表示了对应单元的肌肉活跃程度,从而编码表情状态。例如下图中,AU向量中的第一个元素AU1表示了提起内侧眉毛的程度。我们建立与AU空间一一对应的对抗流形,可以用改变AU值的方式,在对抗流形上采样对抗样本,连续地改变AU值,就可以生成表情连续变化的对抗样本了。
这样的对抗流形还是语义连续的,因为在上面连续的采样,表情(语义信息)是连续变化的。我们给出了连续对抗流形和语义连续对抗流形的具体定义。


并且从数学上详细地证明了我们找到的对抗流形与AU向量空间同胚,从而说明我们找到的是一个连续的对抗流形。
PS:为啥要多加一个语义连续的对抗流形呢。是因为如果以后有用这个范式做了扰动连续的对抗流形,那就不符合语义连续了仅仅符合定义1,所以在这里多写了一个定义,算是为以后的工作做一个细分吧。
3、Performance
实验部分详细的看论文和支持材料吧,黑盒攻击成功率、攻击api的结果、可视化、表情对攻击成功率的影响、攻击状态集泛化性提高的消融实验、状态集合中图片数量对泛化性的影响、一些组件的消融实验、攻击合成状态集的结果....
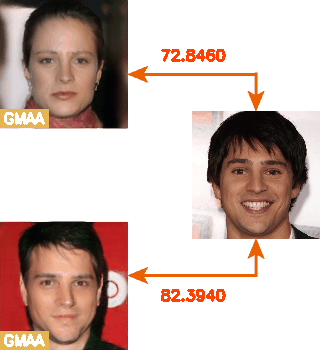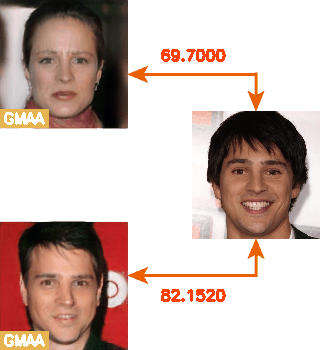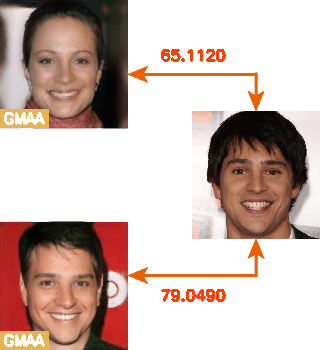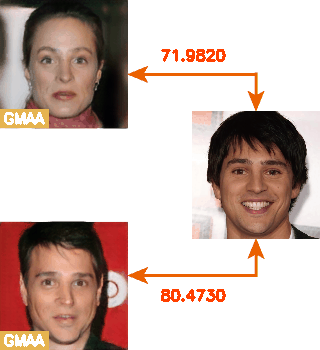
这里就放一个动图吧~右边不动的是目标图、左边是采样出来的对抗样本,数字是Face++相似度。
最后放一点点小感想吧。在22年9月开始做这个工作,说顺利确实2个月就做完了,说不顺利又有太多的艰辛,各种返工熬夜,长痘变丑,心力交瘁,共一第二是陪伴我8年的男朋友,被我push得喊了好多次放弃,又一起相互鼓励熬过了特别特别艰辛的两个月,夫妻档没什么好避讳的,一个好的合伙人可遇不可求,问心无愧就行。
作者list上的每一位同学老师都给予了特别大的帮助,实在是太幸运了。还有一位当时远程实习的老师和他所在的组要感谢,引领我了解了这个领域。