


聚类分析 - 基于TF-IDF生成词向量的K-Means Clustering

在针对于自然语言处理中,时常会需要为无标签类的特征数据通过无监督/半监督的学习方式来进行聚类分析。常见的聚类分析方法有K-Means,均值漂移,DBSCAN,GMM/EM(高斯混合最大期望),凝聚层次聚类(HAC)和图团体检测(Graph Community Detection)。(具体介绍可以参考下方链接)
这篇文章中,我会具体介绍K-Means的聚类方法以及它的实战应用。
因为原始输入的数据都是长文本类型,所以希望通过转为词向量的方式来表示文本内含的数据信息,从而可以通过比较向量间的距离去表达数据(文本)之间的相似度。而之后的聚类分析也会基于文本间的相似度来进行聚类。
首先导入相关的Python packages:
from __future__ import print_function
import re
import time
import numpy as np
import pandas as pd
import jieba
from matplotlib import pyplot as plt
from sklearn.cluster import KMeans,MiniBatchKMeans
from sklearn.feature_extraction.text import TfidfVectorizerJieba分词
首先通过Jieba的lcut()去将原文本拆成单词,这里基于停词表‘stopwords.txt’里的单词(如下图),对数据进行拆分:


# import stopWord
stopword_path = 'data/stopwords.txt' #读取停词表
stopword = []
with open(stopword_path,'r',encoding=None) as file:
for word in file.readlines():
stopword.append(word.strip())
# 文本分词
def cut_word(str):
line = re.sub(r'[a-zA-Z0-9]*','',str)
wordlist = jieba.lcut(line,cut_all=False) # 提取单词
return ' '.join([word for word in wordlist if word not in stopword
and len(word)>1]) # 空格连接
word_list = list(df['question'].apply(cut_word)) # 针对数据集里的questions进行分词提取最后会将每一行的数据(文本)以关键词的形式进行输出,将结果输出为新的list,命名为‘word_list’。
TF-IDF词向量(TfidfVectorizer)
在这个基础上,我们可以以这些关键词进行维度建立,从而从TF(Term Freqency 词频)和IDF(Inverse Document Frequency 逆文档频)来计算词向量。
# write a vectorizing function
def transform(dataset, n_features=1000):
vectorizer = TfidfVectorizer(max_df=0.7, max_features=n_features, min_df=0.01,
use_idf=True, smooth_idf=True, lowercase=False
, analyzer='word')
X = vectorizer.fit_transform(dataset)
return X, vectorizerX是转化为词向量后的原始数据。如果只是计算词频,可以将use_idf设为False。这里我们按照单词进行计算,所以analyzer是'word',而不是'char'。
K-Means模型训练
基于输出的vectorizer(词向量),我们可以放入K-Means/MiniBatchK-Means的聚类模型中,去计算向量间的欧式距离(也可以计算余弦相似值等其他距离公式)。
def train(X, vectorizer, true_k=10, minibatch=False, showLable=False):
# 使用采样数据还是原始数据训练k-means,
if minibatch:
km = MiniBatchKMeans(n_clusters=true_k, init='k-means++', n_init=1,
init_size=1000, batch_size=1000, verbose=False)
else:
km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=1,
verbose=False)
km.fit(X)
if showLable:
print("Top terms per cluster:")
order_centroids = km.cluster_centers_.argsort()[:, ::-1]
terms = vectorizer.get_feature_names()
print(vectorizer.get_stop_words())
for i in range(true_k):
print("Cluster %d:" % i, end='')
for ind in order_centroids[i, :10]:
print(' %s' % terms[ind], end='')
print()
result = list(km.predict(X)) # 输出预测结果(聚类)
print('Cluster distribution:')
print(dict([(i, result.count(i)) for i in result])) # 每一个簇的个数
return -km.score(X) 模型分数使用K-Means的一个特点在于我们大部分情况不知道K是多少(除非本身对于数据的特征有固定的分类数量),即不知道该分为几个簇。所以通常我们可以让K-Means模型在给定范围的K值区间去训练,将模型训练后的分数/结果以可视化的形式绘制出来,再做选择。
这里我将这个过程命名为k_determine( ):
#指定簇的个数k
def k_determin():
'''测试选择最优参数'''
dataset = word_list
print("%d documents" % len(dataset))
X, vectorizer = transform(dataset, n_features=500)
true_ks = []
scores = []
#中心点的个数从3到200(根据自己的数据量进行设置)
for i in range(3, 200, 1):
score = train(X, vectorizer, true_k=i) / len(dataset)
print(i, score)
true_ks.append(i)
scores.append(score)
plt.figure(figsize=(8, 4))
plt.plot(true_ks, scores, label="error", color="red", linewidth=1)
plt.xlabel("n_features") # K值
plt.ylabel("error")
plt.legend()
plt.show()
plt.savefig最后呈现的可视化结果如下:
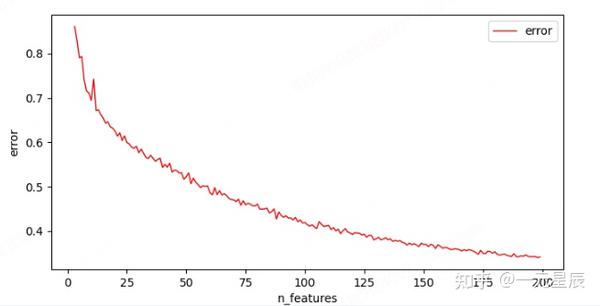
理论上我们在选择K值的时候希望特定K值前后error差别较大,且模型error逐渐平稳的(即我们常说的肘部法)。同时也可以从实际的数据量、特征类型、训练结果多个维度来进行判断和选择。
这里将K值设为100得到的训练结果比较可观:
def main():
'''在最优参数下输出聚类结果'''
dataset = word_list
X, vectorizer = transform(dataset, n_features=500)
print(vectorizer.vocabulary_)
score = train(X, vectorizer, true_k=100, showLable=True) / len(dataset)
print(score)
if __name__ == '__main__':
start=time.time()
# k_determin() #先确定k值
main()
end=time.time()
print('程序运行时间',end-start)有了聚类后的预测之后,我们可以将分类的结果以标签的形式(创建新的一列数据),增加到原数据集里,并且按照Cluster(聚类)进行排序:
# add cluster label to the dataset
def add_cluster(df_fit,df,true_k=100,n_features=500):
X, vectorizer = transform(df_fit, n_features)
km = KMeans(n_clusters=true_k, init='k-means++', max_iter=300, n_init=1,
verbose=False)
km.fit(X)
cluster_labels = km.predict(X)
df['Cluster'] = cluster_labels
add_cluster(df_fit,df,true_k=100,n_features=500)
# 查看某一簇的聚类结果(questions)
def cluster(df=df, i):
return df.loc[df.Cluster==i,'question']