

R 根据不同变量删除重复观测

医学统计/生物统计/SAS/R
写在前面:
终于要学R了,SAS和R差别还是挺大。想记录下平日里遇到的、学到的一些知识。
问题:想删除Excel中重复的行观测,比如删除名字相同的行。
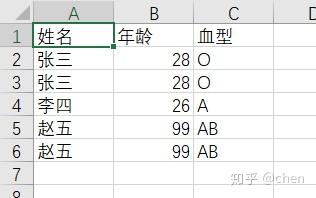
解决办法:


1:导入CSV文件,取名为test0318,header=T表示保留第一行。
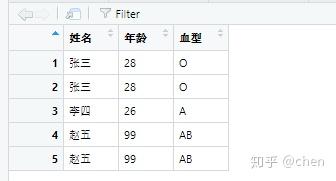
2:按照姓名进行重复值的删选(如果存在重复,默认保留前面的行),并保存在outcome数据框中。
3:导出outcome数据框为一CSV文件。
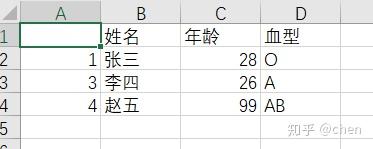
这样就可以解决上述问题。
但会存在一个问题,名字并不是唯一的,存在着名字重复的问题。所以不能只用名字来进行删除,应该选择一些其他的变量来进行筛选(这就体现了一个唯一码的重要性,例如身份证号等)。
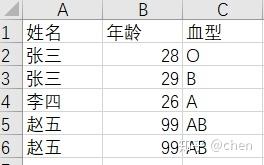
解决代码:
#将处理数据导入R中,名字取为test0318(处理文件为CSV格式,header=T的意思是保留列名)
test0318<-read.csv("C:/Users/陈文松/Desktop/test.csv",header = TRUE)
#调用dplyr包(如果第一次用R,则需安装这个包,语句为“install.packages("dplyr")”)
library(dplyr)
#按照姓名,年龄,血型进行删选重复行,并且将结果储存至outcome数据框中