

Python 重采样遥感数据 Pyresample (二)

Pyresample 可以通过重采样执行刈幅数据集、栅格数据集间或同类间相互转化。可以使用的重采样算法有最近邻法、高斯权重法、自定义径向函数权重法等。
Versionchanged:
Changed in version 1.8.0:
SwathDefinition
为了提升性能不再检查输入的经纬度坐标的合法性。经度数组应该介于 -180 和 180 度,纬度介于 -90 到 90 度。这对于所有初始化需要经纬度数组的地理几何定义同样适用。
pyresample.image
ImageContainerNearest 和 ImageContanerBilinear 类可以用来重采样刈幅数据集和栅格数据集。下面是使用最近邻法示例。
>>> import numpy as np
>>> from pyresample import image, geometry
>>> area_def = geometry.AreaDefinition('areaD', 'Europe (3km, HRV, VTC)', 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (50, 10))
>>> lons = np.fromfunction(lambda y, x: 3 + x, (50, 10))
>>> lats = np.fromfunction(lambda y, x: 75 - y, (50, 10))
>>> swath_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> swath_con = image.ImageContainerNearest(data, swath_def, radius_of_influence=5000)
>>> area_con = swath_con.resample(area_def)
>>> result = area_con.image_data
对于其它重采样类型,或将重采样过程分为两步,使用 pyresample.kd_tree 包中的函数,见下。
pyresample.kd_tree
该模块包含若干用于重采样 swath 数据的函数。注意,距离计算使用笛卡尔距离估算。掩膜标注数组可以用来做数据输入。为了支持将未定义像素掩除而不是填充某个自定义值,当调用 resample_area_* 时,设置 fill_value=None 。
resample_nearest
使用最近邻算法。示例演示如何使用最近邻法重采样一个生成的 swath 数据集为栅格数据集:
>>> import numpy as np
>>> from pyresample import kd_tree, geometry
>>> area_def = geometry.AreaDefinition('areaD', 'Europe (3km, HRV, VTC)', 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (50, 10))
>>> lons = np.fromfunction(lambda y, x: 3 + x, (50, 10))
>>> lats = np.fromfunction(lambda y, x: 75 - y, (50, 10))
>>> swath_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> result = kd_tree.resample_nearest(swath_def, data,
... area_def, radius_of_influence=50000, epsilon=0.5)
如果参数 swath_def 和 area_def 互换 ( data 匹配 area_def 的维度) area_def 对应的栅格会被重采样为由 swath_def 定义的 swath。
注意以下关键字参数:
- radius_of_influence : 近邻的搜寻半径(以米为单位)。
- epsilon : The distance to a found value is guaranteed to be no further than (1 + eps) times the distance to the correct neighbour. Allowing for uncertanty decreases execution time.
如果 data 是一个掩膜标注数组,其掩膜会参与近邻像素寻找。
如果数据集有多个通道, data 参数的最后维度代表通道,前面维度与 lons 和 lat 数组一致,比如 (rows, cols, channels)。注意, pyresample < 0.7.4 的用法是将 data 以 (数据点数, 通道数channels) 的形式传入,该方式也被高版本 pyresample 支持。
>>> import numpy as np
>>> from pyresample import kd_tree, geometry
>>> area_def = geometry.AreaDefinition('areaD', 'Europe (3km, HRV, VTC)', 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> channel1 = np.fromfunction(lambda y, x: y*x, (50, 10))
>>> channel2 = np.fromfunction(lambda y, x: y*x, (50, 10)) * 2
>>> channel3 = np.fromfunction(lambda y, x: y*x, (50, 10)) * 3
>>> data = np.dstack((channel1, channel2, channel3))
>>> lons = np.fromfunction(lambda y, x: 3 + x, (50, 10))
>>> lats = np.fromfunction(lambda y, x: 75 - y, (50, 10))
>>> swath_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> result = kd_tree.resample_nearest(swath_def, data,
... area_def, radius_of_influence=50000)
对于最近邻重采样, 使用 image.ImageContainerNearest 和 kd_tree.resample_nearest 都可以。
resample_gauss
它是使用最近邻高斯权重法的重采样函数。高斯权重函数被定义为 exp(-dist^2/sigma^2)。注意, pyresample sigma 不是 高斯标准偏差。
下面示例展示了如何使用高斯权重法将一个生成的 swath 数据集重采样为一个栅格数据集:
>>> import numpy as np
>>> from pyresample import kd_tree, geometry
>>> area_def = geometry.AreaDefinition('areaD', 'Europe (3km, HRV, VTC)', 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (50, 10))
>>> lons = np.fromfunction(lambda y, x: 3 + x, (50, 10))
>>> lats = np.fromfunction(lambda y, x: 75 - y, (50, 10))
>>> swath_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> result = kd_tree.resample_gauss(swath_def, data,
... area_def, radius_of_influence=50000, sigmas=25000)
如果 data 包含多个通道,关键字参数 sigmas 必须是一个列表,为每个通道指定一个 sigma。
如果 data 是一个掩膜标记数组,目标数据集中被源数据集标记无效像素像素通过权重“污染”的像素会被标记无效。
使用 utils.fwhm2sigma 函数可以由 3 dB FOV levels 计算 sigma 参数。
resample_custom
它是使用自定义径向权重函数进行重采样的函数。
以下示例演示了如何利用自定义径向权重函数将一个生成的 swath 数据集重采样为一个栅格数据集:
>>> import numpy as np
>>> from pyresample import kd_tree, geometry
>>> area_def = geometry.AreaDefinition('areaD', 'Europe (3km, HRV, VTC)', 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (50, 10))
>>> lons = np.fromfunction(lambda y, x: 3 + x, (50, 10))
>>> lats = np.fromfunction(lambda y, x: 75 - y, (50, 10))
>>> swath_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> wf = lambda r: 1 - r/100000.0
>>> result = kd_tree.resample_custom(swath_def, data,
... area_def, radius_of_influence=50000, weight_funcs=wf)
如果 data 包含多个通道, weight_funcs 关键字参数必须是一个列表,为每个通道指定一个径向函数。
如果 data 是一个掩膜标记数组,目标数据集中被源数据集标记无效像素像素通过权重“污染”的像素会被标记无效。
不确定性估算
以标准偏差的形式表达的不确定性可以由 resample_custom 和 resample_gauss 函数获取。默认情况下,这两个函数以单一 numpy array 的形式返回重采样结果。如果函数设置关键字参数 with_uncert=True ,下列 numpy arrays 会被返回: (result, stddev, count) 。 result 是重采样结果, stddev 是重采样结果中每个像素的加权标准差, count 是重采样结果中每个像素涉及到加权的源像素数量。
重采样结果中的每个像素被视为是源数据的采样加权平均值,一个用于估计这些采样值的标准差的无偏加权估计器表达为
stddev = sqrt((V1 / (V1 ** 2 + V2)) * sum(wi * (xi - result) ** 2))
,
result
是重采样结果,
xi
是参与加权的近邻值,
wi
是对应的权重,
V1 = sum(wi)
,
V2 = sum(wi ** 2)
。标准差仅为重采样结果中涉及至少两个加权源像素的像素提供。
count
数组可以用来过滤涉及更多加权近邻的像素。
与前面 resample_gauss 和 resample_custom 用法的区别仅仅体现在返回值的区别,比如:
>>> result, stddev, count = pr.kd_tree.resample_gauss(swath_def, ice_conc, area_def,
... radius_of_influence=20000,
... sigmas=pr.utils.fwhm2sigma(35000),
... fill_value=None, with_uncert=True)
下面是一个真实数据集重采样结果的视图:

相应的标准差视图:
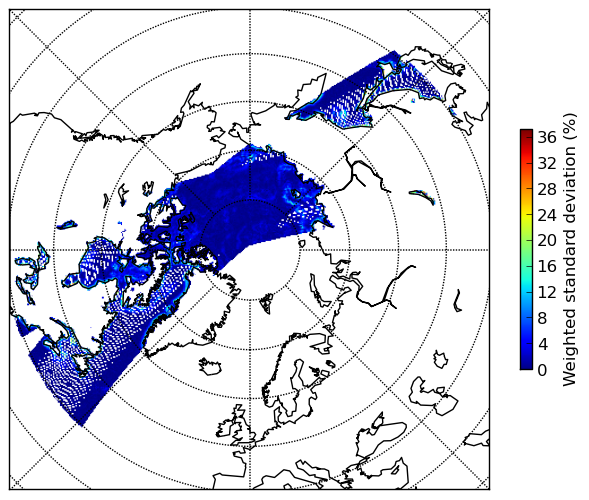
重采样结果中每个像素涉及的加权近邻数视图:
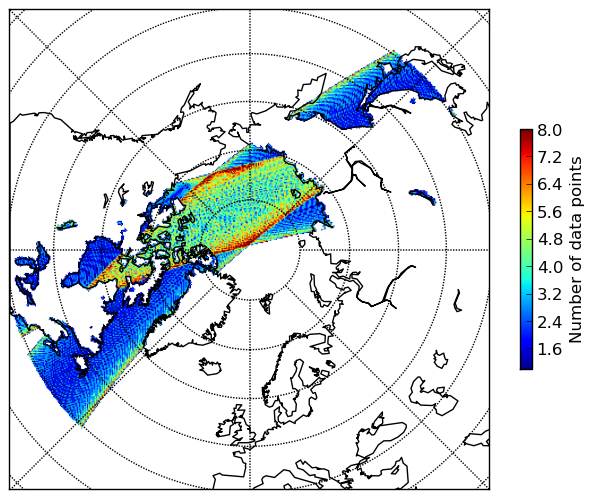
注意,标准差仅对重采样结果中涉及的加权近邻数大于 1 的像素有效。
利用近邻信息重采样
重采样过程可以分成两步:首先,计算得到包含近邻信息的数组;然后,使用这些数组计算重采样值。
当基于同样 swath 的多个数据集需要执行重采样操作时,该方法能够提高效率,因为计算任务繁重的近邻信息计算过程只需要执行一次。
>>> import numpy as np
>>> from pyresample import kd_tree, geometry
>>> area_def = geometry.AreaDefinition('areaD', 'Europe (3km, HRV, VTC)', 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (50, 10))
>>> lons = np.fromfunction(lambda y, x: 3 + x, (50, 10))
>>> lats = np.fromfunction(lambda y, x: 75 - y, (50, 10))
>>> swath_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> valid_input_index, valid_output_index, index_array, distance_array = \
... kd_tree.get_neighbour_info(swath_def,
... area_def, 50000,
... neighbours=1)
>>> res = kd_tree.get_sample_from_neighbour_info('nn', area_def.shape, data,
... valid_input_index, valid_output_index,
... index_array)
注意,关键字参数 neighbours=1 。这意味着重采样时只考虑一个近邻,即最邻近的点。同时注意到当 get_sample_from_neighbour_info 使用最近邻算法时, distance_array 不是必须参数。
Segmented resampling
当一个重采样函数接收关键字参数 segments 时,它指定了重采样过程划分的分段数。这会影响 pyresample 的内存占用量。如果该参数缺省, pyresample 会估计要使用的分段数。
pyresample.bilinear
相较于最近邻重采样,双线性插值在极轨卫星数据和地球静止轨道卫星数据的边缘产生了更平滑的结果。
该函数实现了 http://www. ahinson.com/algorithms_ general/Sections/InterpolationRegression/InterpolationIrregularBilinear.pdf 中描述的算法。
下面显示了最近邻法 (top) 和双线性插值法 (bottom) 生成的影像对比:


下图的 视觉 锐利度更低,但是呈现了更多的细节。
XArrayBilinearResampler
bilinear.XArrayBilinearResampler 是一个使用 xarray.DataArray 数组来处理双线性插值的类,并行化计算自动使用 dask 完成。
>>> import numpy as np
>>> import dask.array as da
>>> from xarray import DataArray
>>> from pyresample.bilinear import XArrayBilinearResampler
>>> from pyresample import geometry
>>> target_def = geometry.AreaDefinition('areaD',
... 'Europe (3km, HRV, VTC)',
... 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = DataArray(da.from_array(np.fromfunction(lambda y, x: y*x, (500, 100))), dims=('y', 'x'))
>>> lons = da.from_array(np.fromfunction(lambda y, x: 3 + x * 0.1, (500, 100)))
>>> lats = da.from_array(np.fromfunction(lambda y, x: 75 - y * 0.1, (500, 100)))
>>> source_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> resampler = XArrayBilinearResampler(source_def, target_def, 30e3)
>>> result = resampler.resample(data)
重采样信息可以保存起来以供日后复用,为同样的区域提供更快的插值速度。
数据会被保存为 ZARR 结构,所以需要事先安装 zarr Python 包。
>>> import os
>>> from tempfile import gettempdir
>>> cache_file = os.path.join(gettempdir(), "bilinear_resampling_luts.zarr")
>>> resampler.save_resampling_info(cache_file)
>>> new_resampler = XArrayBilinearResampler(source_def, target_def, 30e3)
>>> new_resampler.load_resampling_info(cache_file)
>>> result = new_resampler.resample(data)
NumpyBilinearResampler
bilinear.NumpyBilinearResampler 是一个简约的 Numpy 版本的 XArrayBilinearResampler 。
>>> import numpy as np
>>> from pyresample.bilinear import NumpyBilinearResampler
>>> from pyresample import geometry
>>> target_def = geometry.AreaDefinition('areaD',
... 'Europe (3km, HRV, VTC)',
... 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (500, 100))
>>> lons = np.fromfunction(lambda y, x: 3 + x * 0.1, (500, 100))
>>> lats = np.fromfunction(lambda y, x: 75 - y * 0.1, (500, 100))
>>> source_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> resampler = NumpyBilinearResampler(source_def, target_def, 30e3)
>>> result = resampler.resample(data)
resample_bilinear
使用双线性插值法处理非规则状栅格数据的便捷函数。
NOTE : 本函数已经废弃。请根据输入数据格式,直接使用上文所用 bilinear.NumpyBilinearResampler 或 bilinear.XArrayBilinearResampler 类和它们的 .resample() 方法。
>>> import numpy as np
>>> from pyresample import bilinear, geometry
>>> target_def = geometry.AreaDefinition('areaD',
... 'Europe (3km, HRV, VTC)',
... 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (500, 100))
>>> lons = np.fromfunction(lambda y, x: 3 + x * 0.1, (500, 100))
>>> lats = np.fromfunction(lambda y, x: 75 - y * 0.1, (500, 100))
>>> source_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> result = bilinear.resample_bilinear(data, source_def, target_def,
... radius=50e3, neighbours=32,
... nprocs=1, fill_value=0,
... reduce_data=True, segments=None,
... epsilon=0)
target_area 须是一个带有 proj_str 属性的地理区域对象。
传递给 kd_tree 的关键字参数:
- radius : 近邻的搜索半径,以米为单位。
- neighbours : 近邻像素搜索数量。注意,该值应该足够大,以确保所搜索到的近邻像素可以 “包围” 目标插值像素!
- nprocs : 寻找近邻像素的处理器核数。
- fill_value : 无效像素的填充值。当设置 fill_value=None 时,重采样结果是一个掩膜标注数组。
- reduce_data : 在计算近邻信息时,是否执行数据预压缩。
- epsilon : 在搜索近邻中所允许的最大不确定性。
上示例展示了每个关键字参数的默认值。
使用双线性系数执行重采样
..note:
该用法已废弃。请根据输入数据格式直接使用 **bilinear.NumpyBilinearResampler** 或
**bilinear.XArrayBilinearResampler** 类。
如同最近邻法重采样一样,双线性插值法也可以分成两步。
- 计算插值系数,输入数据压缩矩阵和制图矩阵
- 利用上述信息执行若干数据集在地理区域对象和刈幅对象间重采样。
仅仅第一步是计算密集型操作,如果其计算结果可以复用,那么整体处理时间就可以显著压缩。
resample_bilinear
函数在内部也是分这两步执行重采样操作的,但是将它们分开就有可能将第一步计算的系数缓存起来,为需要执行同样变换的重采样过程所复用。这对于地球静止轨道卫星数据处理非常有用。注意,输出尺寸可以在第二步设置,
resample_bilinear
会在内部完成相应转换操作。
>>> import numpy as np
>>> from pyresample import bilinear, geometry
>>> target_def = geometry.AreaDefinition('areaD', 'Europe (3km, HRV, VTC)',
... 'areaD',
... {'a': '6378144.0', 'b': '6356759.0',
... 'lat_0': '50.00', 'lat_ts': '50.00',
... 'lon_0': '8.00', 'proj': 'stere'},
... 800, 800,
... [-1370912.72, -909968.64,
... 1029087.28, 1490031.36])
>>> data = np.fromfunction(lambda y, x: y*x, (50, 10))
>>> lons = np.fromfunction(lambda y, x: 3 + x, (50, 10))
>>> lats = np.fromfunction(lambda y, x: 75 - y, (50, 10))
>>> source_def = geometry.SwathDefinition(lons=lons, lats=lats)
>>> t_params, s_params, input_idxs, idx_ref = \
... bilinear.get_bil_info(source_def, target_def, radius=50e3, nprocs=1)
>>> res = bilinear.get_sample_from_bil_info(data.ravel(), t_params, s_params,
... input_idxs, idx_ref,
... output_shape=target_def.shape)
pyresample.ewa
Pyresample 支持使用椭圆权重均值算法 (Elliptical Weighted Averaging, EWA) 重采样一个刈幅数据集至一个规则栅格数据集。该算法与 pyresample 提供的基于 KDTree 的重采样算法不同。后者从目标端出发,在处理一个目标插值点时,会在源数据中搜索所有近邻像素,并执行某种特定插值操作 (最近邻法、高斯法,等等)。而 EWA 算法从输入端出发,将每一个源数据点投射至 1 个或多个目标插值点上;当所有输入端像素处理完后,将中间插值结果取平均得到最终重采样结果。
相较于常规的 KDTree 算法,应用 EWA 算法时对输入数据的结构有一些限制。
EWA 假定输入数组的数据是按地理组织的,即输入数组中的毗邻点在地理上也是毗邻的。该算法基于刈幅数据集像素的尺寸和位置利用上述假设来配置参数。它也假设输入数据是由在轨卫星扫描生成的,并且用户必须使用
rows_per_scan
参数提供扫描尺寸。
EWA 算法由两步组成: ll2cr (将刈幅经度和纬度转换成栅格的列和行) 和 fornav (将刈幅数据重采样至栅格)。该算法起初是由 NASA National Snow & Ice Data Center (NSIDC)
开发的 MODIS Swath to Grid Toolbox (ms2gt) 工具箱的一部分。它的默认参数在处理 MODIS L1B 数据时工作得最好,在处理 VIIRS 和 AVHRR 数据时使用其他合适的参数会取得更好的效果。
Resampler
DaskEWAResampler
类是使用 EWA 重采样方法的最简单方式。在内部,该重采样器使用了
dask
库来并行执行所有操作。这样会提供更好的性能,但需要安装
dask
库。下面代码假设你有一个
swath_def
对象 (
SwathDefinition
),一个
area_def
对象 (
AreaDefinition
),和数组数据
data
, Data 可以是一个 numpy array, dask array, 或
xarray DataArray 对象。
from pyresample.ewa import DaskEWAResampler