


MySQL基本查询语言--DQL数据查询语言大揭秘!

1、数据集准备
CREATE TABLE product
pid INT PRIMARY KEY,
pname VARCHAR(20),
price DOUBLE,
category_id VARCHAR(32)
) DEFAULT CHARSET=utf8;插入数据:
INSERT INTO product VALUES (1,'联想',5000,'c001');
INSERT INTO product VALUES (2,'海尔',3000,'c001');
INSERT INTO product VALUES (3,'雷神',5000,'c001');
INSERT INTO product VALUES (4,'杰克琼斯',800,'c002');
INSERT INTO product VALUES (5,'真维斯',200,'c002');
INSERT INTO product VALUES (6,'花花公子',440,'c002');
INSERT INTO product VALUES (7,'劲霸',2000,'c002');
INSERT INTO product VALUES (8,'香奈儿',800,'c003');
INSERT INTO product VALUES (9,'相宜本草',200,'c003');
INSERT INTO product VALUES (10,'面霸',5,'c003');
INSERT INTO product VALUES (11,'好想你枣',56,'c004');
INSERT INTO product VALUES (12,'香飘飘奶茶',1,'c005');
INSERT INTO product VALUES (13,'海澜之家',1,'c002');DataGrip软件关键字替换,可以使用Ctrl + R快捷键
2、select查询
# 根据某些条件从某个表中查询指定字段的内容
格式:select [distinct]*| 列名,列名 from 表where 条件3、简单查询
# 1.查询所有的商品.
select * from product;
# 2.查询商品名和商品价格.
select pname,price from product;
# 3.查询结果是表达式(运算查询):将所有商品的价格+10元进行显示.
select pname,price+10 from product;4、条件查询(where子句)
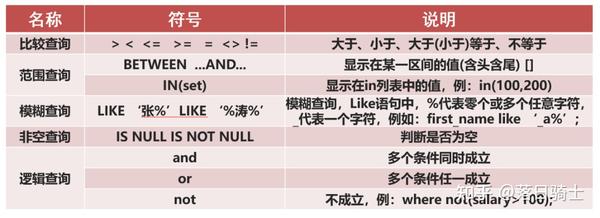

☆ 比较查询
# 查询商品名称为“花花公子”的商品所有信息:
SELECT * FROM product WHERE pname = '花花公子';
# 查询价格为800商品
SELECT * FROM product WHERE price = 800;
# 查询价格不是800的所有商品
SELECT * FROM product WHERE price != 800;
SELECT * FROM product WHERE price <> 800;
# 查询商品价格大于60元的所有商品信息
SELECT * FROM product WHERE price > 60;
# 查询商品价格小于等于800元的所有商品信息
SELECT * FROM product WHERE price <= 800;☆ 范围查询
# 查询商品价格在200到1000之间所有商品
SELECT * FROM product WHERE price BETWEEN 200 AND 1000;
# 查询商品价格是200或800的所有商品
SELECT * FROM product WHERE price IN (200,800);☆ 逻辑查询
# 查询商品价格在200到1000之间所有商品
SELECT * FROM product WHERE price >= 200 AND price <=1000;
# 查询商品价格是200或800的所有商品
SELECT * FROM product WHERE price = 200 OR price = 800;
# 查询价格不是800的所有商品
SELECT * FROM product WHERE NOT(price = 800);☆ 模糊查询
# 查询以'香'开头的所有商品
SELECT * FROM product WHERE pname LIKE '香%';
# 查询第二个字为'想'的所有商品
SELECT * FROM product WHERE pname LIKE '_想%';☆ 非空查询
# 查询没有分类的商品
SELECT * FROM product WHERE category_id IS NULL;
# 查询有分类的商品
SELECT * FROM product WHERE category_id IS NOT NULL;5、排序查询(order by子句)
# 通过order by语句,可以将查询出的结果进行排序。暂时放置在select语句的最后。
格式:SELECT * FROM 表名 ORDER BY 排序字段 ASC|DESC;
ASC 升序 (默认)
DESC 降序
# 1.使用价格排序(降序)
SELECT * FROM product ORDER BY price DESC;
# 2.在价格排序(降序)的基础上,以分类排序(降序)
SELECT * FROM product ORDER BY price DESC,category_id DESC;6、聚合查询
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
今天我们学习如下五个聚合函数:
| 聚合函数 | 作用 |
|---|---|
| count() | 统计指定列不为NULL的记录行数; |
| sum() | 计算指定列的数值和,如果指定列类型不是数值类型,则计算结果为0 |
| max() | 计算指定列的最大值,如果指定列是字符串类型,使用字符串排序运算; |
| min() | 计算指定列的最小值,如果指定列是字符串类型,使用字符串排序运算; |
| avg() | 计算指定列的平均值,如果指定列类型不是数值类型,则计算结果为0 |
案例演示:
# 1、查询商品的总条数
SELECT COUNT(*) FROM product;
# 2、查询价格大于200商品的总条数
SELECT COUNT(*) FROM product WHERE price > 200;
# 3、查询分类为'c001'的所有商品的总和
SELECT SUM(price) FROM product WHERE category_id = 'c001';
# 4、查询分类为'c002'所有商品的平均价格
SELECT AVG(price) FROM product WHERE categ ory_id = 'c002';
# 5、查询商品的最大价格和最小价格
SELECT MAX(price),MIN(price) FROM product;7、分组查询与having子句
☆ 分组查询介绍
分组查询就是将查询结果按照指定字段进行分组,字段中数据相等的分为一组。
分组查询基本的语法格式如下:
GROUP BY 列名 [HAVING 条件表达式] [WITH ROLLUP]
说明:
- 列名: 是指按照指定字段的值进行分组。
- HAVING 条件表达式: 用来过滤分组后的数据。
- WITH ROLLUP:在所有记录的最后加上一条记录,显示select查询时聚合函数的统计和计算结果
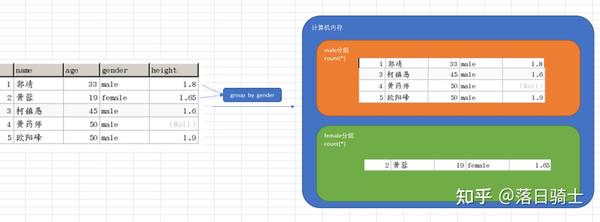
☆ group by的使用
group by可用于单个字段分组,也可用于多个字段分组
-- 根据gender字段来分组
select gender from students group by gender;
-- 根据name和gender字段进行分组
select name, gender from students group by name, gender;
① group by可以实现去重操作
② group by的作用是为了实现分组统计(group by + 聚合函数)
☆ group by + 聚合函数的使用
-- 统计不同性别的人的平均年龄
select gender,avg(age) from students group by gender;
-- 统计不同性别的人的个数
select gender,count(*) from students group by gender;

☆ group_concat()函数
group_concat()是MySQL中自带的一个函数,这个函数主要用于分组查询中。其主要功能可以某个分组中的数据中的某列(字段)值进行concat拼接操作。

案例:统计男分组中,一共有哪些人,字段值与字段值之间使用逗号隔开。


select gender,group_concat(name) from tb_student group by gender;☆ with rollup回溯统计
with rollup主要应用于group by分组中,代表对所有分组数据进行回溯统计。
select gender,count(*) from tb_student group by gender;但是我们希望在以上分组的基础上,在添加==一行==,没有分组,只有一个具体的值。这个值是以上两个分组的总记录数。
select gender,count(*) from tb_student group by gender with rollup;8、having的使用
having作用和where类似都是过滤数据的,但是两者之间的执行顺序不同
① where子句 ② group by子句 ③ having子句
第一种情况:如果只是简单的查询操作(没有group by的情况),大部分时间having是可以直接替代where子句
select * from product where price > 800;以上语句等价于
select * from product having price > 800;第二种情况:
-- 根据gender字段进行分组,统计分组条数大于2的
select gender,count(*) from students group by gender having count(*)>2;
案例演示:
#1 统计各个分类商品的个数
SELECT category_id ,COUNT(*) FROM product GROUP BY category_id ;
#2 统计各个分类商品的个数,且只显示个数大于1的信息
SELECT category_id ,COUNT(*) FROM product GROUP BY category_id HAVING COUNT(*) > 1;9、limit分页查询
分页查询在项目开发中常见,由于数据量很大,显示屏长度有限,因此对数据需要采取分页显示方式。例如数据共有30条,每页显示5条,第一页显示1-5条,第二页显示6-10条。
格式:
SELECT 字段1,字段2... FROM 表名 LIMIT M,N
M: 整数,表示从第几条索引开始,计算方式 (当前页-1)*每页显示条数
N: 整数,表示查询多少条数据
SELECT 字段1,字段2... FROM 表明 LIMIT 0,5
SELECT 字段1,字段2... FROM 表明 LIMIT 5,510、小结
条件查询:select *|字段名 form 表名 where 条件;
排序查询:SELECT * FROM 表名 ORDER BY 排序字段 ASC|DESC;