


tensorflow 模型导出总结


tensorflow 1.0 以及2.0 提供了多种不同的模型导出格式,例如说有checkpoint,SavedModel,Frozen GraphDef,Keras model(HDF5) 以及用于移动端,嵌入式的TFLite。 本文主要讲解了前4中导出格式,分别介绍了四种的导出的各种方式,以及加载,涉及了python以及java的实现。TFLite由于项目中没有涉及,之后会补充。
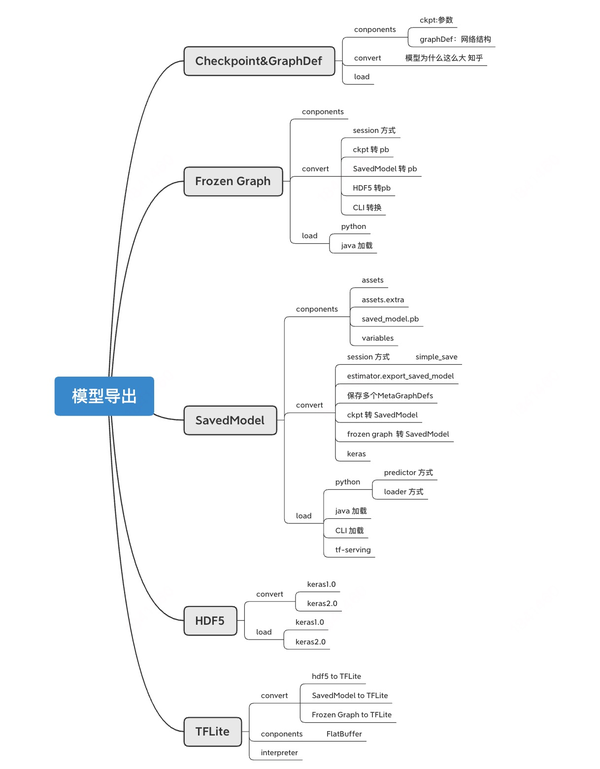
模型导出主要包含了:参数以及网络结构的导出,不同的导出格式可能是分别导出,或者是整合成一个独立的文件。
- 参数和网络结构分开保存:checkpoint, SavedModel
- 只保存权重:HDF5(可选)
- 参数和网络结构保存在一个文件:Frozen GraphDef,HDF5(可选)
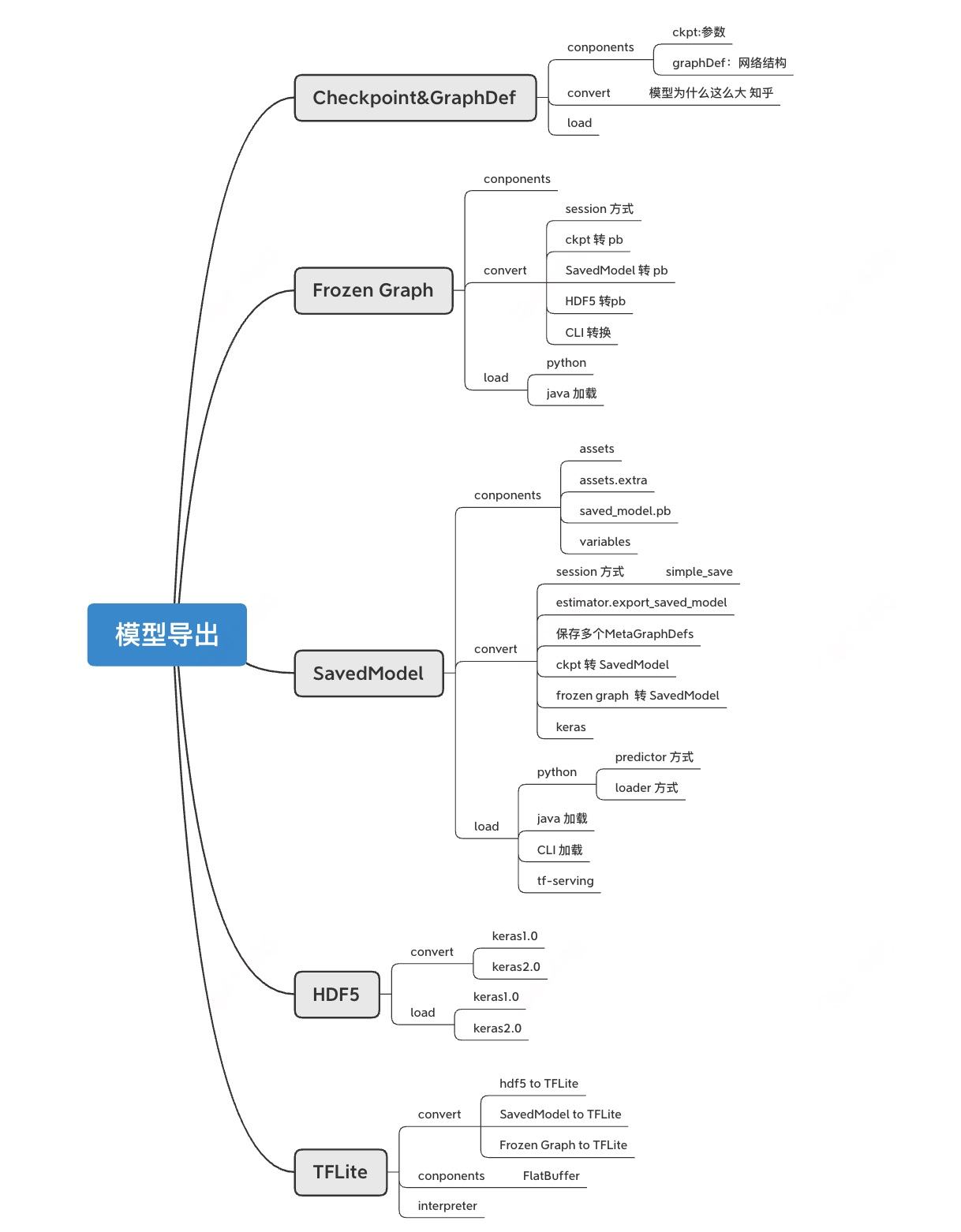
在tensorflow 1.0中,可以见下图,主要有三种主要的API,Keras,Estimator,以及Legacy即最初的session模型,其中tf.Keras主要保存为HDF5,Estimator保存为SavedModel,而Lagacy主要保存的是Checkpoint,并且可以通过freeze_graph,将模型变量冻结,得到Frozen GradhDef的文件。这三种格式的模型,都可以通过TFLite Converter导出为
.tflite
的模型文件,用于安卓/ios/嵌入式设备的serving。
在tensorflow 2.0中,推荐使用SavedModel进行模型的保存,所以keras默认导出格式是SavedModel,也可以通过显性使用
.h5
后缀,使得保存的模型格式为HDF5 。 此外其他low level API,都支持导出为SavedModel格式,以及Concrete Functions。Concrete Function是一个签名函数,有固定格式的输入和输出。 最终转化成Flatbuffer,服务端运行结束。
checkpint 的导出是网络结构和参数权重分开保存的。
其组成:
checkpoint # 列出该目录下,保存的所有的checkpoint列表,下面有具体的例子
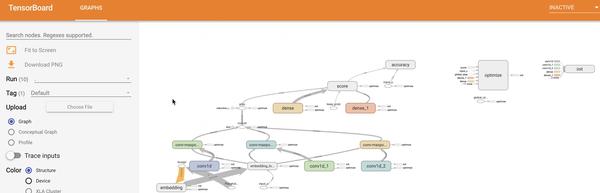
events.out.tfevents.1583930869.prod-cloudserver-gpu169 # tensorboad可视化所需文件,可以直观看出模型的结构
model.ckpt-13000表示前缀,代表第13000 global steps时的保存结果,我们在指定checkpoint加载时,也只需要说明前缀即可。
model.ckpt-13000.index # 代表了参数名
model.ckpt-13000.data-00000-of-00001 # 代表了参数值
model.ckpt-13000.meta # 代表了网络结构所以一个checkpoint 组成是由两个部分,三个文件组成,其中网络结构部分(meta文件),以及参数部分(参数名:index,参数值:data)
其中
checkpoint
文件中
model_checkpoint_path: "model.ckpt-16329"
all_model_checkpoint_paths: "model.ckpt-13000"
all_model_checkpoint_paths: "model.ckpt-14000"
all_model_checkpoint_paths: "model.ckpt-15000"
all_model_checkpoint_paths: "model.ckpt-16000"
all_model_checkpoint_paths: "model.ckpt-16329"
使用
tensorboard --logdir PATH_TO_CHECKPOINT
: tensorboard 会调用events.out.tfevents.*
文件,并生成tensorboard,例如下图
导出成CKPT
- tensorflow 1.0
# in tensorflow 1.0
saver = tf.train.Saver()
saver.save(sess=session, save_path=args.save_path)
- estimator
# estimator
通过 RunConfig 配置多少时间或者多少个steps 保存一次模型,默认600s 保存一次。
具体参考 https://zhuanlan.zhihu.com/p/112062303
run_config = tf.estimator.RunConfig(
model_dir=FLAGS.output_dir, # 模型保存路径
session_config=config,
save_checkpoints_steps=FLAGS.save_checkpoints_steps, # 多少steps保存一次ckpt
keep_checkpoint_max=1)
estimator = tf.estimator.Estimator(
model_fn=model_fn,
config=run_config,
params=None
关于estimator的介绍可以参考
加载CKPT
-
tf1.0
ckpt加载的脚本如下,加载完后,session就会是保存的ckpt了。
# tf1.0
session = tf.Session()
session.run(tf.global_variables_initializer())
saver = tf.train.Saver()
saver.restore(sess=session, save_path=args.save_path) # 读取保存的模型
- 对于estimator 会自动load output_dir 中的最新的ckpt。
-
我们常用的
model_file = tf.train.latest_checkpoint(FLAGS.output_dir)获取最新的ckpt
SavedModel
SavedModel 格式是tensorflow 2.0 推荐的格式,他很好地支持了tf-serving等部署,并且可以简单被python,java等调用。
一个 SavedModel 包含了一个完整的 TensorFlow program, 包含了 weights 以及 计算图 computation. 它不需要原本的模型代码就可以加载所以很容易在 TFLite, TensorFlow.js, TensorFlow Serving, or TensorFlow Hub 上部署。
通常SavedModel由以下几个部分组成
├── assets/ # 所需的外部文件,例如说初始化的词汇表文件,一般无
├── assets.extra/ # TensorFlow graph 不需要的文件, 例如说给用户知晓的如何使用SavedModel的信息. Tensorflow 不使用这个目录下的文件。
├── saved_model.pb # 保存的是MetaGraph的网络结构
├── variables # 参数权重,包含了所有模型的变量(tf.Variable objects)参数
├── variables.data-00000-of-00001
└── variables.index导出为SavedModel
- tf 1.0 方式
"""tf1.0"""
x = tf.placeholder(tf.float32, [None, 784], name="myInput")
y = tf.nn.softmax(tf.matmul(x, W) + b, name="myOutput")
tf.saved_model.simple_save(
sess,
export_dir,
inputs={"myInput": x},
outputs={"myOutput": y})
simple_save
是对于普通的tf 模型导出的最简单的方式,只需要补充简单的必要参数,有很多参数被省略,其中最重要的参数是
tag
:
tag
是用来区别不同的
MetaGraphDef
,这是在加载模型所需要的参数。其默认值是tag_constants.SERVING (“serve”).
对于某些节点,如果没有办法直接加name,那么可以采用
tf.identity
, 为节点加名字,例如说CRF的输出,以及使用dataset后,无法直接加input的name,都可以采用这个方式:
def addNameToTensor(someTensor, theName):
return tf.identity(someTensor, name=theName)
- estimator 方式
"""estimator"""
def serving_input_fn():
label_ids = tf.placeholder(tf.int32, [None], name='label_ids')
input_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_ids')
input_mask = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_mask')
segment_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='segment_ids')
input_fn = tf.estimator.export.build_raw_serving_input_receiver_fn({
'label_ids': label_ids,
'input_ids': input_ids,
'input_mask': input_mask,
'segment_ids': segment_ids,
return input_fn
if do_export:
estimator._export_to_tpu = False
estimator.export_saved_model(Flags.export_dir, serving_input_fn
)
-
保存多个
MetaGraphDef's
import tensorflow.python.saved_model
from tensorflow.python.saved_model import tag_constants
from tensorflow.python.saved_model.signature_def_utils_impl import predict_signature_def
builder = saved_model.builder.SavedModelBuilder(export_path)
signature = predict_signature_def(inputs={'myInput': x},
outputs={'myOutput': y})
""" using custom tag instead of: tags=[tag_constants.SERVING] """
builder.add_meta_graph_and_variables(sess=sess,
tags=["myTag"],
signature_def_map={'predict': signature})
builder.save()
- ckpt转SavedModel
def get_saved_model(bert_config, num_labels, use_one_hot_embeddings):
tf_config = tf.compat.v1.ConfigProto()
tf_config.gpu_options.allow_growth = True
model_file = tf.train.latest_checkpoint(FLAGS.output_dir)
with tf.Graph().as_default(), tf.Session(config=tf_config) as tf_sess:
label_ids = tf.placeholder(tf.int32, [None], name='label_ids')
input_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_ids')
input_mask = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_mask')
segment_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='segment_ids')
loss, per_example_loss, probabilities, predictions = \
create_model(bert_config, False, input_ids, input_mask, segment_ids, label_ids,
num_labels, use_one_hot_embeddings)
saver = tf.train.Saver()
print("restore;{}".format(model_file))
saver.restore(tf_sess, model_file)
tf.saved_model.simple_save(tf_sess,
FLAGS.output_dir,
inputs={
'label_ids': label_ids,
'input_ids': input_ids,
'input_mask': input_mask,
'segment_ids': segment_ids,
outputs={"probabilities": probabilities})
- frozen graph to savedModel
import tensorflow as tf
from tensorflow.python.saved_model import signature_constants
from tensorflow.python.saved_model import tag_constants
export_dir = 'inference/pb2saved'
graph_pb = 'inference/robert_tiny_clue/frozen_model.pb'
builder = tf.saved_model.builder.SavedModelBuilder(export_dir)
with tf.gfile.GFile(graph_pb, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
sigs = {}
with tf.Session(graph=tf.Graph()) as sess:
# name="" is important to ensure we don't get spurious prefixing
tf.import_graph_def(graph_def, name="")
g = tf.get_default_graph()
input_ids = sess.graph.get_tensor_by_name(
"input_ids:0")
input_mask = sess.graph.get_tensor_by_name(
"input_mask:0")
segment_ids = sess.graph.get_tensor_by_name(
"segment_ids:0")
probabilities = g.get_tensor_by_name("loss/pred_prob:0")
sigs[signature_constants.DEFAULT_SERVING_SIGNATURE_DEF_KEY] = \
tf.saved_model.signature_def_utils.predict_signature_def(
"input_ids": input_ids,
"input_mask": input_mask,
"segment_ids": segment_ids
}, {
"probabilities": probabilities
builder.add_meta_graph_and_variables(sess,
[tag_constants.SERVING],
signature_def_map=sigs)
builder.save()
- tf.keras 2.0
model.save('saved_model/my_model')
"""saved as SavedModel by default"""
加载SavedModel
对于在java中加载SavedModel,我们首先需要知道我们模型输入和输出,可以通过以下的脚本在terminal中运行
saved_model_cli show --dir SavedModel路径 --all
得到类似以下的结果
MetaGraphDef with tag-set: 'serve' contains the following SignatureDefs:
signature_def['serving_default']:
The given SavedModel SignatureDef contains the following input(s):
inputs['input_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, 128)
name: input_ids:0
inputs['input_mask'] tensor_info:
dtype: DT_INT32
shape: (-1, 128)
name: input_mask:0
inputs['label_ids'] tensor_info:
dtype: DT_INT32
shape: (-1)
name: label_ids:0
inputs['segment_ids'] tensor_info:
dtype: DT_INT32
shape: (-1, 128)
name: segment_ids:0
The given SavedModel SignatureDef contains the following output(s):
outputs['probabilities'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 7)
name: loss/pred_prob:0
Method name is: tensorflow/serving/predict首先我们可以看到有inputs,以及outputs,分别是一个key为string,value为tensor的字典,每个tensor都有各自的名字。
Python 加载
所有我们有常见两种方式可以加载savedModel,一种是采用
tf.contrib.predictor.from_saved_model
传入predictor模型的inputs dict,然后得到 outputs dict。 一种是直接类似tf1.0的方式,采用
tf.saved_model.loader.load
, feed tensor然后fetch tensor。
-
采用predictor
采用predictor时, 需要传入的字典名字用的是 inputs的key,而不是tensor的names
predict_fn = tf.contrib.predictor.from_saved_model(args_in_use.model)
prediction = predict_fn({
"input_ids": [feature.input_ids],
"input_mask": [feature.input_mask],
"segment_ids": [feature.segment_ids],
probabilities = prediction["probabilities"]
-
tf 1.0 采用 loader
采用loader的方式是采用 session 的feed_dict 方式,该方式feed的是tenor的names,fetch的同样也是tensor 的names。
其中feed_dict的key 可以直接是tensor的name,或者是采用sess.graph.get_tensor_by_name(TENSOR_NAME)得到的tensor。
with tf.Session(graph=tf.Graph()) as sess:
tf.saved_model.loader.load(sess, ["serve"], export_path)
graph = tf.get_default_graph()
feed_dict = {"input_ids_1:0": [feature.input_ids],
"input_mask_1:0": [feature.input_mask],
"segment_ids_1:0": [feature.segment_ids]}
# alternative way
feed_dict = {sess.graph.get_tensor_by_name("input_ids_1:0"):
[feature.input_ids],
sess.graph.get_tensor_by_name("input_mask_1:0"):
[feature.input_mask],
sess.graph.get_tensor_by_name("segment_ids_1:0"):
[feature.segment_ids]}
sess.run('loss/pred_prob:0',
feed_dict=feed_dict
-
tf.keras 2.0
new_model = tf.keras.models.load_model('saved_model/my_model')
JAVA 加载
注意 java加载的时候,如果遇到Op not defined 的错误,是需要匹配模型训练python的tensorflow版本以及java的tensorflow版本的。
所以我们知道我们在tag-set 为serve的tag下,有4个inputs tensors,name分别为
input_ids:0
,
input_mask:0
,
label_ids:0
,
segment_ids:0
, 输出为1个,name是
loss/pred_prob:0
。
并且我们知道这些tensor的类型。
所以我们可以通过下面的java代码,进行加载,获得结果。注意我们需要传入的name中不需要传入
:0
。
import org.tensorflow.*
SavedModelBundle savedModelBundle = SavedModelBundle.load("./export_path", "serve");
Graph graph = savedModelBundle.graph();
Tensor tensor = this.savedModelBundle.session().runner()
.feed("input_ids", inputIdTensor)
.feed("input_mask", inputMaskTensor)
.feed("segment_ids", inputSegmentTensor)
.fetch("loss/pred_prob")
.run().get(0);CLI 加载
$ saved_model_cli show --dir export/1524906774 \
--tag_set serve --signature_def serving_default
The given SavedModel SignatureDef contains the following input(s):
inputs['inputs'] tensor_info:
dtype: DT_STRING
shape: (-1)
The given SavedModel SignatureDef contains the following output(s):
outputs['classes'] tensor_info:
dtype: DT_STRING
shape: (-1, 3)
outputs['scores'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 3)
Method name is: tensorflow/serving/classify
$ saved_model_cli run --dir export/1524906774 \
--tag_set serve --signature_def serving_default \
--input_examples 'inputs=[{"SepalLength":[5.1],"SepalWidth":[3.3],"PetalLength":[1.7],"PetalWidth":[0.5]}]'
Result for output key classes:
[[b'0' b'1' b'2']]
Result for output key scores:
[[9.9919027e-01 8.0969761e-04 1.2872645e-09]]Frozen Graph
frozen Graphdef 将tensorflow导出的模型的权重都freeze住,使得其都变为常量。并且模型参数和网络结构保存在同一个文件中,可以在python以及java中自由调用。
导出为pb
python
- 采用session方式保存frozen graph
"""tf1.0"""
from tensorflow.python.framework.graph_util import convert_variables_to_constants
output_graph_def = convert_variables_to_constants(
session,
session.graph_def,
output_node_names=['loss/pred_prob'])
tf.train.write_graph(output_graph_def, args.export_dir, args.model_name, as_text=False)
-
采用ckpt 转换成frozen graph
以下采用bert tensorflow模型做演示
"""
NB:首先我们要在create_model() 函数中,为我们需要的输出节点取个名字,
比如说我们要: probabilities = tf.nn.softmax(logits, axis=-1, name='pred_prob')
def get_frozen_model(bert_config, num_labels, use_one_hot_embeddings):
tf_config = tf.compat.v1.ConfigProto()
tf_config.gpu_options.allow_growth = True
output_node_names = ['loss/pred_prob']
model_file = tf.train.latest_checkpoint(FLAGS.output_dir)
with tf.Graph().as_default(), tf.Session(config=tf_config) as tf_sess:
label_ids = tf.placeholder(tf.int32, [
None], name='label_ids')
input_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_ids')
input_mask = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='input_mask')
segment_ids = tf.placeholder(tf.int32, [None, FLAGS.max_seq_length], name='segment_ids')
create_model(bert_config, False, input_ids, input_mask, segment_ids, label_ids,
num_labels, use_one_hot_embeddings)
saver = tf.train.Saver()
print("restore;{}".format(model_file))
saver.restore(tf_sess, model_file)
tmp_g = tf_sess.graph.as_graph_def()
if FLAGS.use_opt:
input_tensors = [input_ids, input_mask, segment_ids]
dtypes = [n.dtype for n in input_tensors]
print('optimize...')
tmp_g = optimize_for_inference(tmp_g,
[n.name[:-2] for n in input_tensors],
output_node_names,
[dtype.as_datatype_enum for dtype in dtypes],
False)
print('freeze...')
frozen_graph = tf.graph_util.convert_variables_to_constants(tf_sess,
tmp_g, output_node_names)
out_graph_path = os.path.join(FLAGS.output_dir, "frozen_model.pb")
with tf.io.gfile.GFile(out_graph_path, "wb") as f:
f.write(frozen_graph.SerializeToString())
print(f'pb file saved in {out_graph_path}')
- 采用savedModel 转换成 frozen graph
from tensorflow.python.tools import freeze_graph
from tensorflow.python.saved_model import tag_constants
input_saved_model_dir = "./1583934987/"
output_node_names = "loss/pred_prob"
input_binary = False
input_saver_def_path = False
restore_op_name = None
filename_tensor_name = None
clear_devices = False
input_meta_graph = False
checkpoint_path = None
input_graph_filename = None
saved_model_tags = tag_constants.SERVING
output_graph_filename='frozen_graph.pb'
freeze_graph.freeze_graph(input_graph_filename,
input_saver_def_path,
input_binary,
checkpoint_path,
output_node_names,
restore_op_name,
filename_tensor_name,
output_graph_filename,
clear_devices,
"", "", "",
input_meta_graph,
input_saved_model_dir,
saved_model_tags)
- HDF5 to pb
from keras import backend as K
def freeze_session(session, keep_var_names=None, output_names=None, clear_devices=True):
Freezes the state of a session into a pruned computation graph.
Creates a new computation graph where variable nodes are replaced by
constants taking their current value in the session. The new graph will be
pruned so subgraphs that are not necessary to compute the requested
outputs are removed.
@param session The TensorFlow session to be frozen.
@param keep_var_names A list of variable names that should not be frozen,
or None to freeze all the variables in the graph.
@param output_names Names of the relevant graph outputs.
@param clear_devices Remove the device directives from the graph for better portability.
@return The frozen graph definition.
graph = session.graph
with graph.as_default():
freeze_var_names = list(set(v.op.name for v in tf.global_variables()).difference(keep_var_names or []))
output_names = output_names or []
output_names += [v.op.name for v in tf.global_variables()]
input_graph_def = graph.as_graph_def()
if clear_devices:
for node in input_graph_def.node:
node.device = ""
frozen_graph = tf.graph_util.convert_variables_to_constants(
session, input_graph_def, output_names, freeze_var_names)
return frozen_graph
frozen_graph = freeze_session(K.get_session(),
output_names=[out.op.name for out in model.outputs])
tf.train.write_graph(frozen_graph, "some_directory", "my_model.pb", as_text=False)
CLI转换工具
以下的工具可以快速进行ckpt到pb的转换,但是不能再原本的基础上增加tensor 的名字。
freeze_graph --input_checkpoint model.ckpt-16329 \
--output_graph 0316_roberta.pb \
--output_node_names loss/pred_prob \
--checkpoint_version 1 \
--input_meta_graph model.ckpt-16329.meta \
--input_binary true模型加载
获取frozen graph 中节点名字的脚本如下,但是一般来说,我们的inputs都是我们定义好的placeholders。
import tensorflow as tf
def printTensors(pb_file):
"""read pb into graph_def"""
with tf.gfile.GFile(pb_file, "rb") as f:
graph_def = tf.GraphDef()
graph_def.ParseFromString(f.read())
"""import graph_def"""
with tf.Graph().as_default() as graph:
tf.
import_graph_def(graph_def)
"""print operations"""
for op in graph.get_operations():
print(op.name)
printTensors("path-to-my-pbfile.pb")得到类似如下的结果
import/input_ids:0
import/input_mask:0
import/segment_ids:0
import/loss/pred_prob:0
当我们知道我们要feed以及fetch的节点名称之后,我们就可以通过python/java加载了。
跟savedModel一样,对于某些节点,如果没有办法直接加name,那么可以采用
tf.identity
, 为节点加名字,例如说CRF的输出,以及使用dataset后,无法直接加input的name,都可以采用这个方式
def addNameToTensor(someTensor, theName):
return tf.identity(someTensor, name=theName)Python 加载
我们保存完frozen graph 模型后,假设我们的模型包含以下的tensors:
那么我们通过python加载的代码如下, 采用的是session feed和fetch的方式。
with tf.Graph().as_default():
output_graph_def = tf.GraphDef()
load pb model
with open(args_in_use.model, 'rb') as f:
output_graph_def.ParseFromString(f.read())
tf.import_graph_def(output_graph_def, name='') #name是必须的
enter a text and predict
with tf.Session() as sess:
tf.global_variables_initializer().run()
input_ids = sess.graph.get_tensor_by_name(
"input_ids:0")
input_mask = sess.graph.get_tensor_by_name(
"input_mask:0")
segment_ids = sess.graph.get_tensor_by_name(
"segment_ids:0")
output = "loss/pred_prob:0"
feed_dict = {
input_ids: [feature.input_ids],
input_mask: [feature.input_mask],
segment_ids: [feature.segment_ids],
# 也可以直接使用
# feed_dict = {
# "input_ids:0": [feature.input_ids],
# "input_mask:0": [feature.input_mask],
# "segment_ids:0": [feature.segment_ids],
y_pred_cls = sess.run(output, feed_dict=feed_dict)Java 加载
对于frozen graph,我们加载的方式和savedModel很类似,首先我们需要先启动一个session,然后在启动一个
runner()
,然后再feed模型的输入,以及fetch模型的输出。
注意 java加载的时候,如果遇到Op not defined 的错误,是需要匹配模型训练python的tensorflow版本以及java的tensorflow版本的。
// TensorUtil.class
public static Session generateSession(String modelPath) throws IOException {
Preconditions.checkNotNull(modelPath);
byte[] graphDef = ByteStreams.toByteArray(TensorUtil.class.getResourceAsStream(modelPath));
LOGGER.info("Graph Def Length: {}", graphDef.length);
Graph graph = new Graph();
graph.importGraphDef(graphDef);
return new Session(graph);
// model.class
this.session = TensorUtil.generateSession(modelPath);
Tensor tensor = this.session.runner()
.feed("input_ids", inputIdTensor)
.feed("input_mask", inputMaskTensor)
.feed("segment_ids", inputSegmentTensor)
.fetch("loss/pred_prob")
.run().get(0);HDF5
HDF5 是keras or tf.keras 特有的存储格式。
HDF5导出
- 导出整个模型
"""默认1.0 是HDF5,但是2.0中,是SavedModel,所以需要显性地指定`.h5`后缀"""
model.save('my_model.h5')
- 导出模型weights
"""keras 1.0"""
model.save_weights('my_model_weights.h5')
HDF5加载
- 加载整个模型(无自定义部分)
- keras1.0
"""keras 1.0"""
from keras.models import load_model
model = load_model(model_path)
- keras2.0
"""keras 2.0"""
new_model = tf.keras.models.load_model('my_model.h5')
-
加载整个模型(含自定义部分)
对于有自定义layers的或者实现的模型加载,需要增加dependencies 的映射字典,例如下面的例子: - keras1.0
dependencies = {'MyLayer': MyLayer(), 'auc': auc, 'log_loss': log_loss}
model = load_model(model_path, custom_objects=dependencies, compile=False)
- keras 2.0
"""
To save custom objects to HDF5, you must do the following:
1. Define a get_config method in your object, and optionally a from_config classmethod.
get_config(self) returns a JSON-serializable dictionary of parameters needed to recreate the object.
from_config(cls, config) uses the returned config from get_config to create a new object. By default, this function will use the config as initialization kwargs (return cls(**config)).
2. Pass the object to the custom_objects argument when loading the model. The argument must be a dictionary mapping the string class name to the Python class. E.g. tf.keras.models.load_model(path, custom_objects={'CustomLayer': CustomLayer})
-
加载模型权重
假设你有了相同的模型构建了,那么直接运行下面的代码,加载模型
model.load_weights('my_model_weights.h5')
如果你想要做transfer learning,即从其他的已保存的模型中加载部分的模型参数权重,自己目前的模型结构与保存的模型不同,可以通过参数的名字进行加载,加上
by_name=True
model.load_weights('my_model_weights.h5', by_name=True)
tfLite
TFlite转换
- savedModel to TFLite
"""
--saved_model_dir: Type: string. Specifies the full path to the directory containing the SavedModel generated in 1.X or 2.X.
--output_file: Type: string. Specifies the full path of the output file.
tflite_convert \
--saved_model_dir=1583934987 \
--output_file=rbt.tflite
- frozen graph to TFLite
tflite_convert --graph_def_file albert_tiny_zh.pb \
--input_arrays 'input_ids,input_masks,segment_ids' \
--output_arrays 'finetune_mrc/add, finetune_mrc/add_1'\
--input_shapes 1,512:1,512:1,512 \
--output_file saved_model.tflite \
--enable_v1_converter \
--experimental_new_converter