

@Scheduled注解的坑,我替你踩了

问题背景
在一些业务场景中,我们需要执行定时操作来完成一些周期性的任务,比如每隔一周删除一周前的某些历史数据以及定时进行某项检测任务等等。在日常开发中比较简单的实现方式就是使用
Spring
的
@Scheduled
(具体使用方法不再赘述)注解。但是这个
Spring
框架自带的注解其实是有坑的。在修改服务器时间时会导致定时任务不执行情况的发生,粗暴解决办法是当修改服务器时间后,将服务进行重启就可以避免此现象的发生。本文将主要探讨服务器时间修改导致
@Scheduled
注解失效的原因,同时找到在修改服务器时间后不重启服务的情况下,定时任务仍然正常执行的方法。
@Scheduled失效原因分析
在分析
@Scheduled
失效的原因之前,我们得先搞清楚它到底是怎样运行的,才能抽丝剥茧找到真正的根本原因。在
SpringBoot
启动之后,关于
@Scheduled
部分主要做了两件事情,一个是扫描所有
@Scheduled
注解修饰的方法,将对应的定时任务加到全局的任务队列中。另一个是启动定时任务线程池,开始时间计算与周期的定时任务。

1、@Scheduled解析
首先看下
Spring
是如何解析
@Scheduled
注解的。这里说下看源码的一个小技巧,
一
般情况下,注解以及注解的解析类都在一个包下面,如下所示:
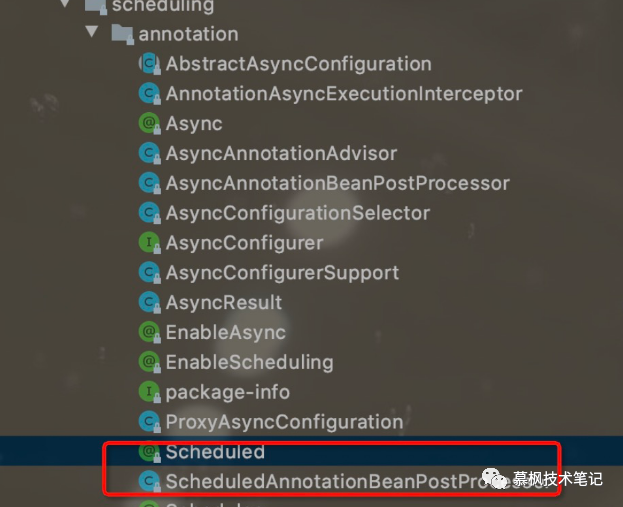
由上图可知,
ScheduledAnnotationBeanPostProcessor
便是解析
@Scheduled
注解的类。我们都知道以
BeanPostProcessor
结尾的类都是对于
Spring
框架能力的一种扩展方式,在
bean
初始化阶段分别调用其实现的
before
以及
after
方法,对
bean
能力进行增强。
Spring
框架会将所有的
BeanPostProcessor
,对其中涉及到的前后增强方法进行调用。
postProcessAfterInitialization
便是在
bean
初始化之后进行调用。下图所示为
SpringBoot
启动后,
ScheduledAnnotationBeanPostProcessor
调用的大致流程。
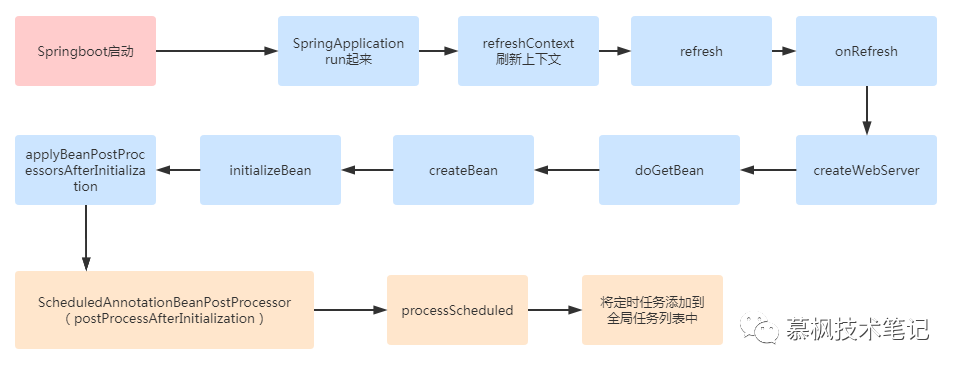
ScheduledAnnotationBeanPostProcessor
对应的源码如下所示:
public class ScheduledAnnotationBeanPostProcessor implements MergedBeanDefinitionPostProcessor, DestructionAwareBeanPostProcessor, Ordered, EmbeddedValueResolverAware, BeanNameAware, BeanFactoryAware, ApplicationContextAware, SmartInitializingSingleton, ApplicationListener<ContextRefreshedEvent>, DisposableBean {
public Object postProcessAfterInitialization(Object bean, String beanName) {
if (bean instanceof AopInfrastructureBean) {
return bean;
} else {
//(key-1)解析所有Scheduled注解的类
Class<?> targetClass = AopProxyUtils.ultimateTargetClass(bean);
if (!this.nonAnnotatedClasses.contains(targetClass)) {
Map<Method, Set<Scheduled>> annotatedMethods = MethodIntrospector.selectMethods(targetClass, new MetadataLookup<Set<Scheduled>>() {
public Set<Scheduled> inspect(Method method) {
Set<Scheduled> scheduledMethods = AnnotatedElementUtils.getMergedRepeatableAnnotations(method, Scheduled.class, Schedules.class);
return !scheduledMethods.isEmpty() ? scheduledMethods : null;
if (annotatedMethods.isEmpty()) {
this.nonAnnotatedClasses.add(targetClass);
if (this.logger.isTraceEnabled()) {
this.logger.trace("No @Scheduled annotations found on bean class: " + targetClass);
} else {
Iterator var5 = annotatedMethods.entrySet().iterator();
while(var5.hasNext()) {
Entry<Method, Set<Scheduled>> entry = (Entry)var5.next();
Method method = (Method)entry.getKey();
Iterator var8 = ((Set)entry.getValue()).iterator();
while(var8.hasNext()) {
Scheduled scheduled = (Scheduled)var8.next();
//(key-2)处理被注解修饰的类
this.processScheduled(scheduled, method, bean);
if (this.logger.isDebugEnabled()) {
this.logger.debug(annotatedMethods.size() + " @Scheduled methods processed on bean '" + beanName + "': " + annotatedMethods);
return bean;
它主要做了两件事情:
key-1:
解析所有以
@Scheduled
以及
@Schedules
注解修饰的方法,将方法以及对应的注解集合存入一个
map
中,这里注意方法作为
key
对应的value是一个集合,说明一个方法可以被多个
@Scheduled
以及
@Schedules
进行修饰。
key-2:
将
key-1``map
的方法取出后进行处理,即调用
processScheduled
方法。如下所示:
protected void processScheduled(Scheduled scheduled, Method method, Object bean) {
try {
Runnable runnable = this.createRunnable(bean, method);
boolean processedSchedule = false;
String errorMessage = "Exactly one of the 'cron', 'fixedDelay(String)', or 'fixedRate(String)' attributes is required";
Set<ScheduledTask> tasks = new LinkedHashSet(4);
long initialDelay = scheduled.initialDelay();
//(key-1)获取注解中对应的scron参数
String cron = scheduled.cron();
if (StringUtils.hasText(cron)) {
String zone = scheduled.zone();
if (this.embeddedValueResolver != null) {
cron = this.embeddedValueResolver.resolveStringValue(cron);
zone = this.embeddedValueResolver.resolveStringValue(zone);
if (StringUtils.hasLength(cron)) {
Assert.isTrue(initialDelay == -1L, "'initialDelay' not supported for cron triggers");
processedSchedule = true;
if (!"-".equals(cron)) {
TimeZone timeZone;
if (StringUtils.hasText(zone)) {
timeZone = StringUtils.parseTimeZoneString(zone);
} else {
timeZone = TimeZone.getDefault();
//(key-2)添加到任务列表
tasks.add(this.registrar.scheduleCronTask(new CronTask(runnable, new CronTrigger(cron, timeZone))));
Assert.isTrue(processedSchedule, errorMessage);
Map var18 = this.scheduledTasks;
synchronized(this.scheduledTasks) {
Set<ScheduledTask> regTasks = (Set)this.scheduledTasks.computeIfAbsent(bean, (key) -> {
return new LinkedHashSet(4);
regTasks.addAll(tasks);
} catch (IllegalArgumentException var25) {
throw new IllegalStateException("Encountered invalid @Scheduled method '" + method.getName() + "': " + var25.getMessage());
说明:本文主要阐述scron定时任务解析。
key-1:
将注解中的时间参数进行获取与解析。
key-2:
将任务包装为
CronTask
添加到全局计划任务中。
2、定时任务启动
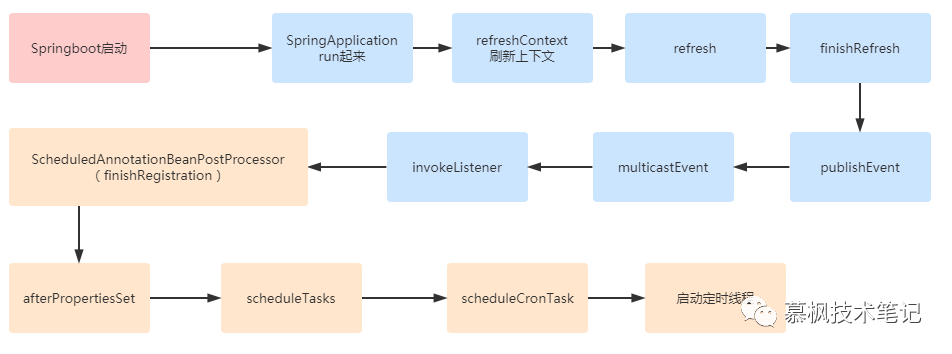
在
springboot
启动后,通过监听事件完成定时任务启动。
public ScheduledTask scheduleCronTask(CronTask task) {
ScheduledTask scheduledTask = this.unresolvedTasks.remove(task);
boolean newTask = false;
if (scheduledTask == null) {
scheduledTask = new ScheduledTask();
newTask = true;
if (this.taskScheduler != null) {
scheduledTask.future = this.taskScheduler.schedule(task.getRunnable(), task.getTrigger());
else {
addCronTask(task);
this.unresolvedTasks.put(task, scheduledTask);
return (newTask ? scheduledTask : null);
}
根本原因,
JVM
启动之后会记录系统时间,然后
JVM
根据
CPU ticks
自己来算时间,此时获取的是定时任务的基准时间。如果此时将系统时间进行了修改,当
Spring
将之前获取的基准时间与当下获取的系统时间进行比对时,就会造成
Spring
内部定时任务失效。因为此时系统时间发生变化了,不会触发定时任务。
public ScheduledFuture<?> schedule() {
synchronized (this.triggerContextMonitor) {
this.scheduledExecutionTime = this.trigger.nextExecutionTime(this.triggerContext);
if (this.scheduledExecutionTime == null) {
return null;
//获取时间差
long initialDelay = this.scheduledExecutionTime.getTime() - System.currentTimeMillis();
this.currentFuture = this.executor.schedule(this, initialDelay, TimeUnit.MILLISECONDS);