


华泰金融工程研究组研报学习笔记——Boosting模型


Boosting模型(分类器:个股下期上涨概率)
本篇笔记重点分析括 AdaBoost、 GBDT、XGBoost 这三种模型Boosting集成学习模型应用于多因子选股的异同
1. 集成学习算法
为了解决单个偌分类器预测能力有限的问题,我们希望能够通过一些方式将多个弱分类器合成为一个强分类器,也就是业界常说的 集成学习算法 。集成学习算法有两大类:Bagging(并行方法)和Boosting(串行方法)。
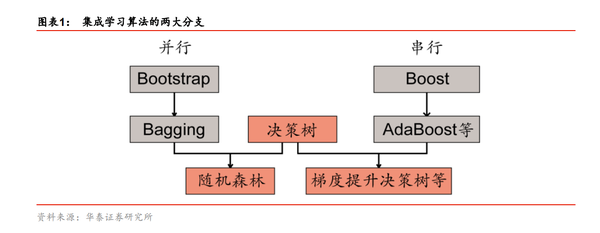
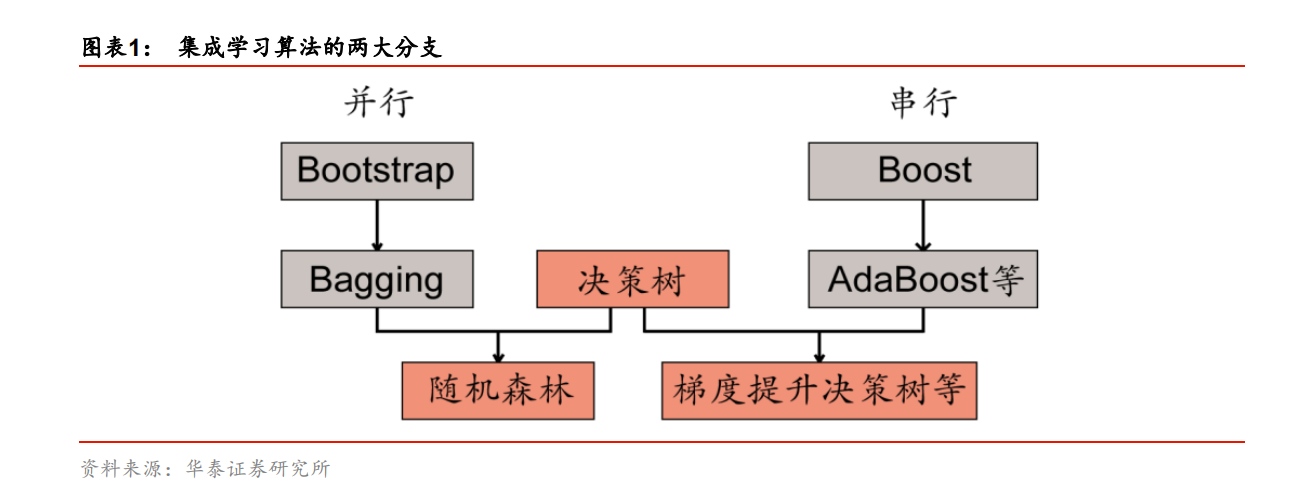
2. 决策树要点提炼
弱分类器,基于多个特征进行分类。在树的每个节点处,根据特征信息增益的表现选择使得信息增益最大的特征分裂出下一层的叶子节点。终端的叶子节点即分类结果,随着逐层划分, 决策树分支的节点所包含的样本类别会趋于一致 。本篇笔记讨论的弱分类器是CART决策树(CART决策树的 每个节点只分裂成两个子节点 , 支持特征的组合 , 可用于分类和回归问题)。
串行:训练完一个决策树再训练下一个
3. 提升算法AdaBoost 即adaptive boosting原理介绍(指数损失函数)
在训练之前,我们赋予全部样本相等的权重。第一步以原始数据为训练集,训练一个弱分类器 C1,如图表 3 左图所示。对于分类错误的样本,提高其权重。第二步以更新样本权值后的数据为训练集,再次训练一个弱分类器C2,如图表 3 中间图所示。随后重复上述过程,每次自适应地改变样本权重并训练弱分类器,如图表 3 右图所示。最终,每个弱分类器都可以计算出它的加权训练样本分类错误率,将全部弱分类器按一定权值进行组合得到强分类器,错误率越低的弱分类器所占权重越高。
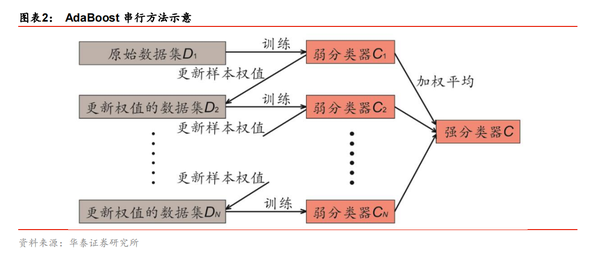
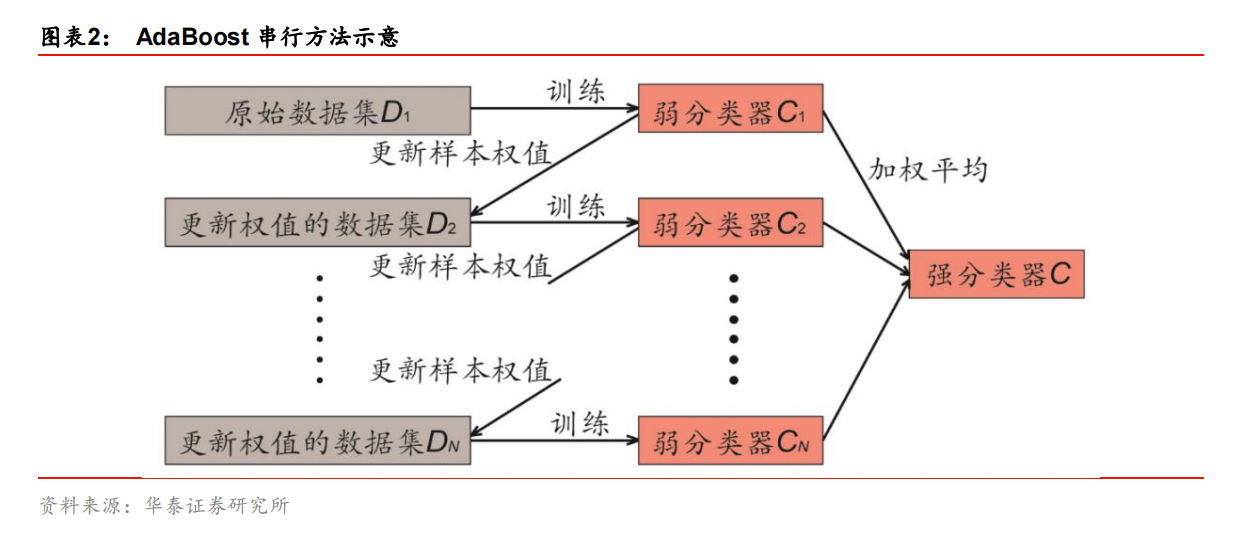
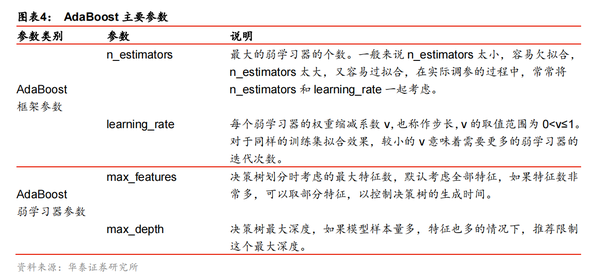
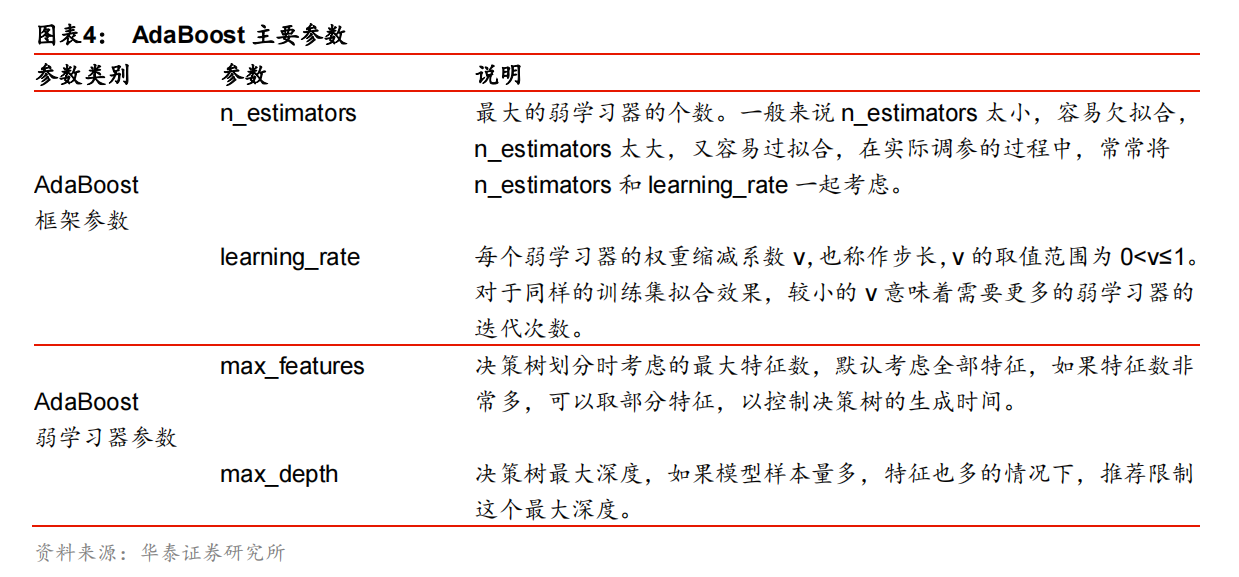
4. Adaboost主要参数选择
5.梯度提升决策树GBDT原理介绍
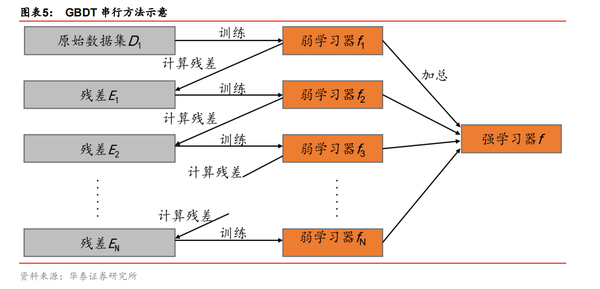
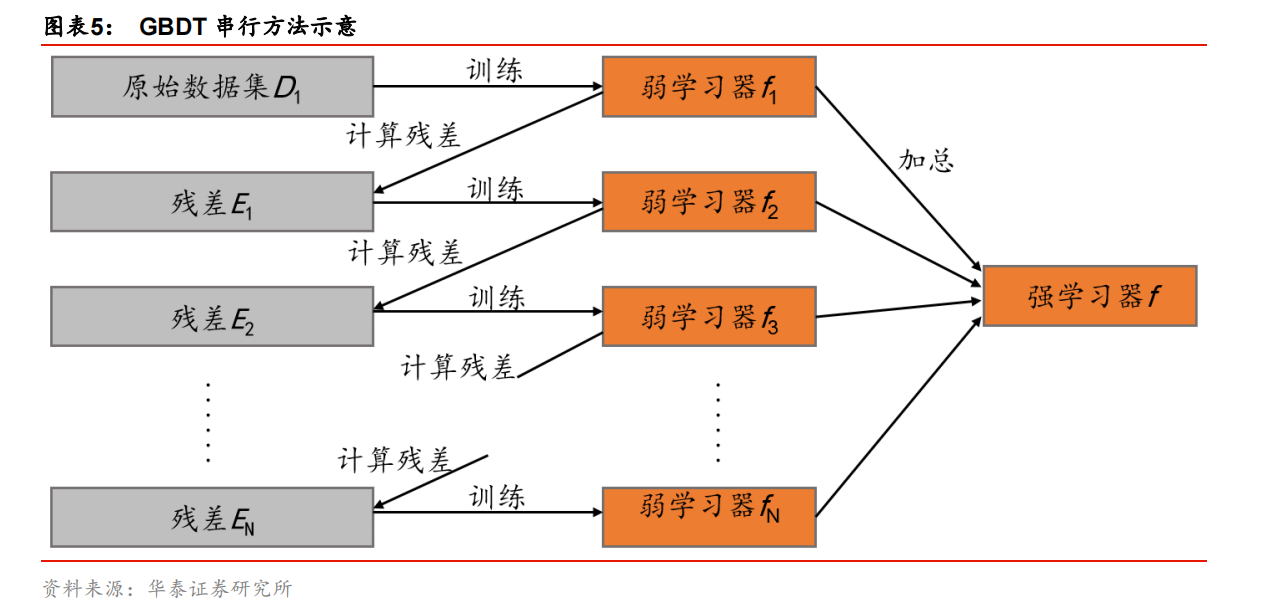
GBDT 的思想可以用一个通俗的例子解释,假如某人有 170 厘米身高,我们首先用 160厘米去拟合,发现残差有 10 厘米,这时我们用 6 厘米去拟合剩下的残差,发现残差还有4 厘米,第三轮我们用 3 厘米拟合剩下的残差,残差就只有 1 厘米了。如果迭代轮数还没有完,可以继续迭代下去,每一轮迭代,拟合的身高残差都会减小。图表 5 显示了 GBDT算法的流程。
6. GBDT常用损失函数
Huber 损失函数,它是均方差损失函数和绝对损失函数的折中产物,对于远离中心的异常点,采用绝对损失函数,而中心附近的点采用均方差损失函数。这个界限一般用分位数点度量。损失函数如下


对于 Huber 损失和分位数损失,主要用于健壮回归,也就是减少异常点对损失函数的影响。
7. GBDT主要参数


8.XGBoost极端梯度提升算法
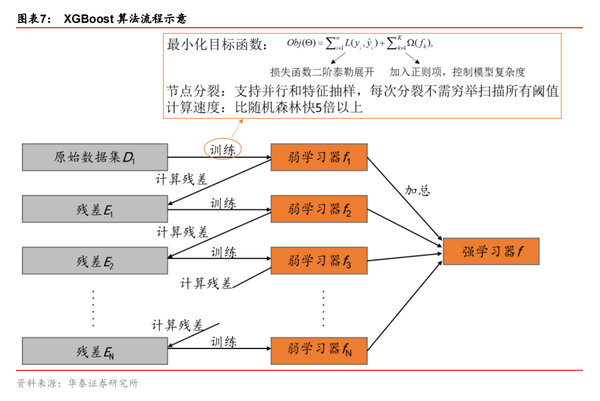
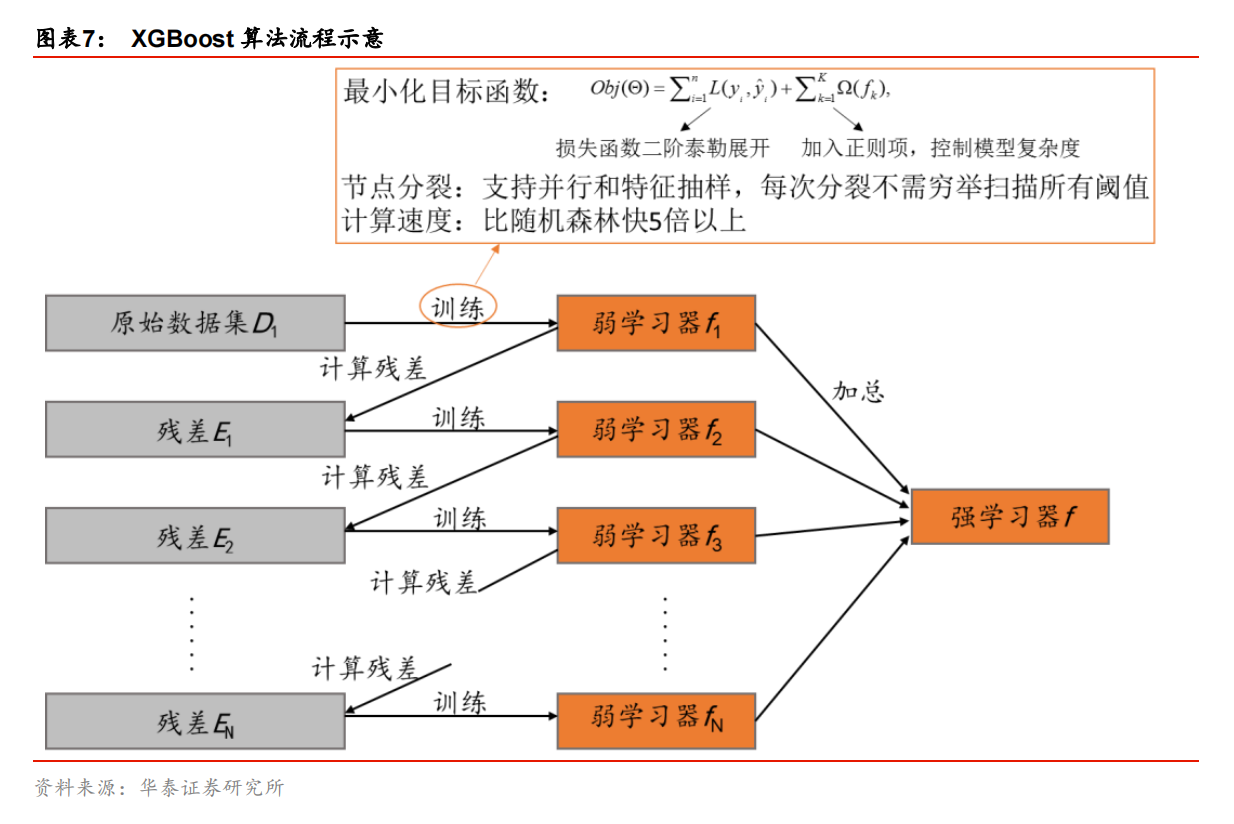
XGBoost 是 Gradient Boosting 方法的一种高效实现,也是 GBDT 算法的改进和提高。相比于传统的 GBDT 算法,XGBoost 在损失函数、正则化(控制模型的复杂度)、切分点查找和并行化设计等方面进行了改进,使得其在计算速度上比常见工具包快 5 倍以上。例如,GBDT 算法在训练第 n 棵树时需要用到第 n-1 棵树的残差,从而导致算法较难实现并行;而 XGBoost 通过 对目标函数做二阶泰勒展开 ,XGBoost的特别之处就在于用损失函数的二阶泰勒展开来近似原来的损失函数,使得最终的目标函数只依赖每个数据点上损失函数的一阶导和二阶导,进而容易实现并行。图表 7 显示了 XGBoost 算法的流程,它与 GBDT 在数学上的不同之处在于训练每个弱学习器时的目标函数。
9. 模型训练
为了让模型即时学习到市场特征的变化,采用 7阶段滚动回测方法 ,并采用年化收益率、信息比率( IR=α ∕ ω,α为组合的超额收益,ω为主动风险,用于衡量承担单位主动风险带来的超额收益 )、最大回撤( 指的是基金净值从最高到最低的下降幅度,用于衡量风险)等。
模型表现:
- XGBoost模型超额收益和信息比率的表现优于线性回归,最大回撤无明显优势
- XGBoost模型预测能力与其他集成学习模型持平,但运算速度有明显优势
- Boosting模型比Bagging模型(随机森林)更简单,在决策树的深度上远小于随机森林模型
