

【Python爬虫】正则表达式详解

正则表达式
为什么使用正则表达式?
典型的搜索和替换操作要求您提供与预期的搜索结果匹配的确切文本。 而通过使用正则表达式,可以:
- 测试字符串内的模式。 例如,可以测试输入字符串,以查看字符串内是否出现电话号码模式或信用卡号码模式。这称为数据验证。
- 替换文本。 可以使用正则表达式来识别文档中的特定文本,完全删除该文本或者用其他文本替换它。
- 基于模式匹配从字符串中提取子字符串。 可以查找文档内或输入域内特定的文本。
语法
正则表达式语法由字符和操作符构成, 字母和数字表示他们自身。标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。 常用的操作符模式如下:
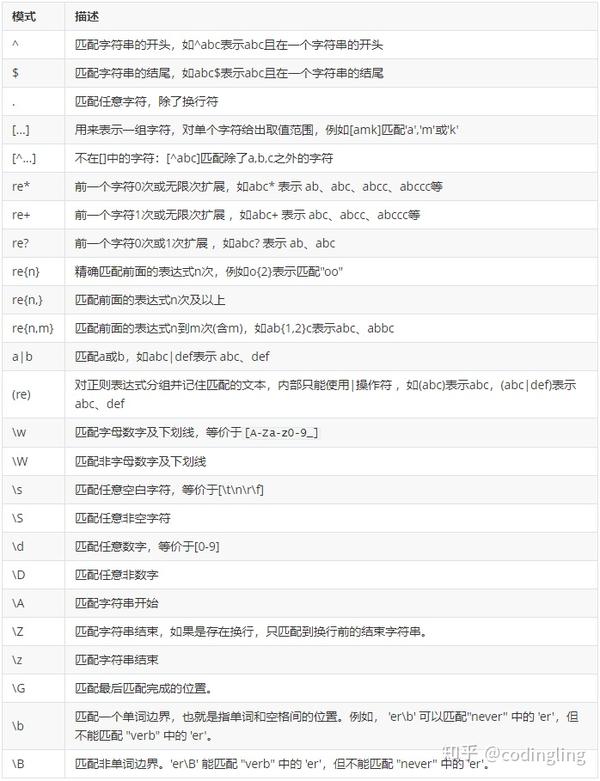
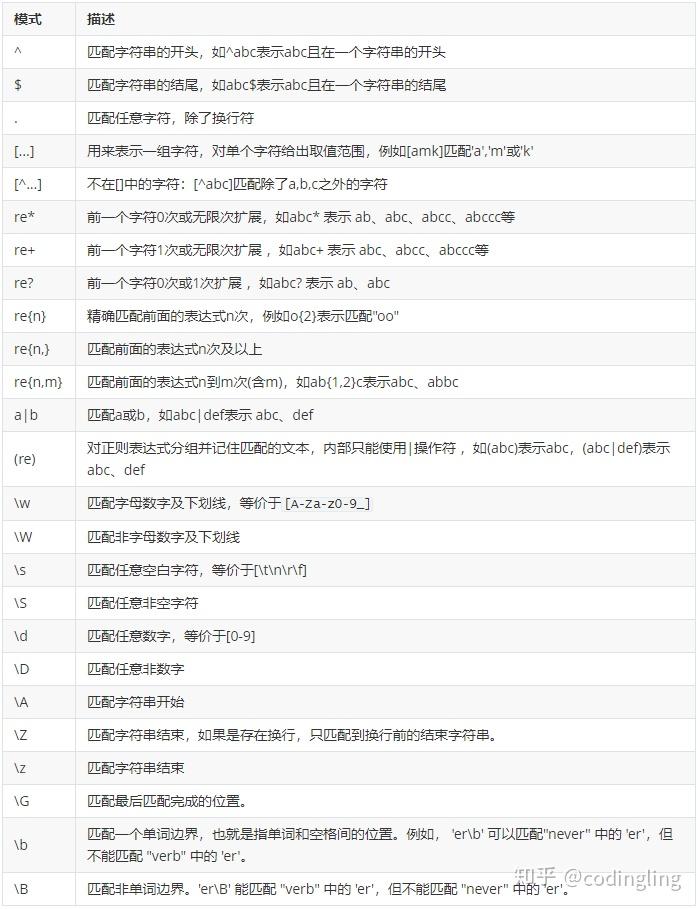
正则表达式re库的使用
常用函数说明
- 调用方式:import re
- re库采用raw string类型表示正则表达式,表示为:r'text',raw string是不包含对转义符再次转义的字符串;
re库的主要功能函数 :
-
re.search()在一个字符串中 搜索匹配正则表达式的第一个位置 ,返回match对象 - re.search(pattern, string, flags=0)
- 使用group(num) 或 groups() 匹配对象函数来获取匹配表达式
-
re.match()从一个字符串的 开始位置 起匹配正则表达式,返回match对象 - re.match(pattern, string, flags=0)
- 使用group(num) 或 groups() 匹配对象函数来获取匹配表达式
-
re.findall()搜索 字符串,以列表类型返回全部能匹配的子串 - re.findall(pattern, string, flags=0)
-
re.split()将一个字符串按照正则表达式匹配结果进行 分割 ,返回列表类型 - re.split(pattern, string, maxsplit=0, flags=0)
- maxsplit是分隔次数,maxsplit=1 分隔一次,默认为 0,不限制次数。
-
re.finditer()搜索 字符串,返回一个匹配结果的迭代类型,每个迭代元素是match对象 - re.finditer(pattern, string, flags=0)
-
re.sub()在一个字符串中 替换 所有匹配正则表达式的子串,返回替换后的字符串 - re.sub(pattern, repl, string, count=0, flags=0)
- repl : 替换的字符串,也可为一个函数。
- count : 模式匹配后替换的最大次数,默认 0 表示替换所有的匹配。
- 参数说明
- pattern是匹配的正则表达式
- string是要匹配的字符串
- flags : 正则表达式使用时的控制标记:
-
re.I --> re.IGNORECASE : 忽略正则表达式的大小写,
[A‐Z]能够匹配小写字符 - re.M --> re.MULTILINE : 正则表达式中的^操作符能够将给定字符串的每行当作匹配开始
- re.S --> re.DOTALL : 正则表达式中的.操作符能够匹配所有字符,默认匹配除换行外的所有字符
re库的另一种等价用法(编译)
- regex = re.compile(pattern, flags=0):将正则表达式的字符串形式编译成正则表达式对象, 供 match() 和 search() 等函数使用。
re 库的贪婪匹配和最小匹配
-
.*Re库默认采用贪婪匹配,即输出匹配最长的子串 -
*?只要长度输出可能不同的,都可以通过在操作符后增加?变成最小匹配
实用小例子
1.删除文本中的特殊符号
def filter_str(sentence):
remove_nota = u'[’·°–!"#$%&\'()*+,-./:;<=>?@,。?★、…【】()《》?“”‘’![\\]^_`{|}~]+'
sentence = re.sub(remove_nota, '', sentence)
remove_punctuation_map = dict((ord(char), None) for char in string.punctuation)
sentence = sentence.translate(remove_punctuation_map)
return sentence.strip()
remove_nota列举了一些特殊符号,主要是中文的。接着用re.sub函数替换文本中的特殊符号为空值。
string.punctuation是英文的标点符号,remove_punctuation_map将这些标点符号转换成一个字典,key是符号,value是None。而translate()方法是根据参数给出的表转换字符串的字符,也就是说把文本中和key相同的字符替换成value。因为这里的value是None,也就是空值了。
给个例子:
>>> filter_str('今天心情很好!@#$%^~*&')
'今天心情很好'
另外,附加福利,如果只想 去掉文本末尾的括号 要怎么做呢?非常简单:
re.sub(r'([(].*?[)])$', '', name)
正则表达式前面的r表示原始字符串,比如r'\t'等价于'\t'。
先来看这个表达式的开头和结尾:'()$',还记得吗?
'(re)'表示对正则表达式分组并记住匹配的文本。'$'表示匹配字符串的末尾。小括号里面有两个分隔的中括号,分别是'[(]'和'[)]',也就是表示匹配左括号和右括号,这里换成'('和')'也是一样的。中间还有一个'.*?',表示匹配任意字符0次或多次,但是在能使整个匹配成功的前提下使用最少的重复(非贪婪匹配)。
关于贪婪和非贪婪可以看看这个例子:
>>> s="This is a number 234-235-22-423"
>>> r=re.match(".+(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'4-235-22-423'
>>> r=re.match(".+?(\d+-\d+-\d+-\d+)",s)
>>> r.group(1)
'234-235-22-423'
正则表达式模式中使用到通配字,那它在从左到右的顺序求值时,会尽量“抓取”满足匹配最长字符串,在我们上面的例子里面,“.+”会从字符串的起始处抓取满足模式的最长字符,其中包括我们想得到的第一个整型字段中的大部分,“\d+”只需一位字符就可以匹配,所以它匹配了数字“4”,而“.+”则匹配了从字符串起始到这个第一位数字4之前的所有字符。
解决方式:非贪婪操作符“?”,这个操作符可以用在"*","+","?"的后面,要求正则匹配的越少越好。
去掉文本首尾的特殊符号以及指定字符 :
def REstrip(text, param=' '):
# 去掉首尾的param
text0 = ''
i = 0
remove_nota = u'[’·!"#$%&\'()*+,-./:;<=>?@,。?★、…【】()《》?“”‘’![\\]^_`{|}~]+'
while text0 != text or i == 0:
i += 1
text0 = text
text = text.strip().strip(string.punctuation)
text = text.strip(remove_nota)
mo = re.compile(r'^([' + str(param) + r']*)(.*?)([' + str(param) + ']*)$')
result = mo.search(text)
text = result.group(2)
return text
这里用了一个循环,是为了保证去掉首尾的所有特殊字符,防止遗漏。
2.匹配文本中是否有某个特殊文本
寻找文本中出现的所有英文字母:
name = "abc 123 def 456"
re.findall(re.compile("[a-zA-Z]"), name)
# ['a', 'b', 'c', 'd', 'e', 'f']
找到文本中出现的第一个英文字母:
re.search("[a-zA-Z]", name)
# <re.Match object; span=(0, 1), match='a'>
re.search("[a-zA-Z]", name).start()
re.search("[a-zA-Z]", name).span()
# (0, 1)
寻找关键词在文本中出现的所有起始位置:
name = "123123"
keyword = "123"
start_list = [m.start() for m in re.finditer(keyword, name)]
start_list
# [0, 3]
如果只想要第一个起始位置,可以用:
name.find(keyword)
3.在中英文字符之间加上空格 :
name = "今天真开心happy快乐"
name = re.sub('([A-Za-z]+)([\u4e00-\u9fa5]+)', r'\1 \2', name)
name = re.sub('([\u4e00-\u9fa5]+)([A-Za-z]+)', r'\1 \2', name)
# '今天真开心 happy 快乐'
两个表达式是类似地,只不过第一个表达式是在英文和中文字符之间加上空格,第二个表达式是在中文和英文字符之间加上空格。我们来看第一个表达式。第一个()是匹配1个或多个英文,第二个()是匹配1个或多个中文字符,r'\1 \2'是匹配第1个分组和第2个分组,且中间加了空格。
4.自定义分隔符
比如,以数字作为分隔符:
name = "我有2只眼睛1个鼻子"
re.split('\d', name)
# ['我有', '只眼睛', '个鼻子']
re.split('(\d)', name)
# ['我有', '2', '只眼睛', '1', '个鼻子']
加上()会使得分割后的列表保留数字,不加的话就不会保留。
以数字和空格作为分隔符:
name = "我有1只松鼠 2条狗 66只猫 还有鱼7 信不信"
re.split('(?<=\d)\s+|\s+(?=\d)', name)
# ['我有1只松鼠', '2条狗', '66只猫 还有鱼7', '信不信']
看到结果是:有空格+数字,或者数字+空格的地方都被分隔开了。且分隔后将空格去掉,数字保留。
要理解这个表达式,首先需要理解几个概念:
# 前瞻:
exp1(?=exp2) 查找exp2前面的exp1
# 后顾:
(?<=exp2)exp1 查找exp2后面的exp1
# 负前瞻:
exp1(?!exp2) 查找后面不是exp2的exp1
# 负后顾:
(?<!exp2)exp1 查找前面不是exp2的exp1
例如:
re.sub('(?<=中国)人', 'rr', '中国人') # 匹配中国人中的人,将其替换为rr,结果为 中国rr
re.sub('(?<=中国)人', 'rr', '法国人') # 结果为 法国人,因为人前面不是中国,所以无法匹配到
所以
(?<=\d)\s+
是查找数字后面的空格(可以是多个),
\s+(?=\d)
是查找数字前面的空格(可以是多个)。
再看看另一个类似的语法
?:
()表示捕获分组,()会把每个分组里的匹配的值保存起来,使用$n(n是一个数字,表示第n个捕获组的内容)
(?:)表示非捕获分组,和捕获分组唯一的区别在于,非捕获分组匹配的值不会保存起来
举例1
re.findall('industr(?:y|ies)', 'industriesy')
# 等价于re.findall('industry|industries', 'industriesy')
# ['industries']
re.findall('industr(y|ies)', 'industriesy')
# ['ies']
举例2:数字格式化
# 数字格式化例如 1,123,000
re.sub('\B(?=(?:\d{3})+(?!\d))', ',', '1234567890')
# 结果:1,234,567,890,匹配的是后面是3*n个数字的非单词边界(\B)
实战:淘宝商品比价定向爬虫
- 爬取网址: https:// s.taobao.com/search? q= 书包&js=1&stats_click=search_radio_all%25
- 爬取思路:
- 提交商品搜索请求,循环获取页面
- 对于每个页面,提取商品名称和价格信息
- 将信息输出到屏幕上
# 导入包
import requests
import re
1.提交商品搜索请求,循环获取页面
因为淘宝有反爬虫机制,直接用requests.get方法获取url的话会爬取不到商品信息,只是登录界面。要想绕过登录界面就得利用自己登录后的cookie信息。
首先我们需要先在浏览器中登录我们的个人淘宝,然后搜索以 书包 为例的商品,打开开发者模式或者按F12
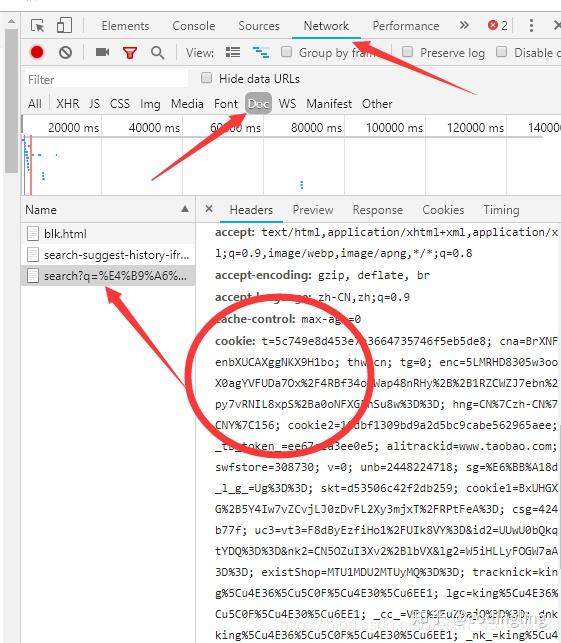
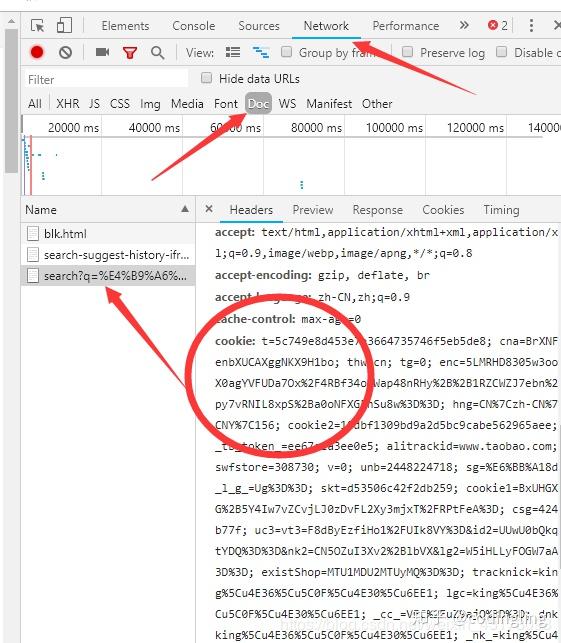
这里我们可以看到我们当前的cookie和user-agent(一般是Mozilla/5.0) (注意:如果没有出现这几个name,点击浏览器刷新就会出现了) 然后在代码中增加我们的cookie和user-agent
def getHTMLText(url):
请求获取html,(字符串)
:param url: 爬取网址
:return: 字符串
# 添加头信息,
kv = {
'cookie': '你的cookie信息',
'user-agent': 'Mozilla/5.0'
r = requests.get(url, timeout=30, headers=kv)
# r = requests.get(url, timeout=30)
# print(r.status_code)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取失败"
2.对于每个页面,提取商品名称和价格信息
找到我们想要的信息:


用正则表达式去匹配这两个字段,注意匹配标点符号时养成习惯,在前面加一个"\"符号,表示转义,因为像".", "*", "?"等标点符号同时也是操作符,在前面加转义符号才会被认为是标点符号。
以商品价格【"view_price":"138.00"】为例,需要匹配的是固定不变的字符串加上数字价格,因此正则表达式就是:
r'\"view_price\"\:\"[\d.]*\"'
前面的很好理解,就是字符串的文本内容,只不过在标点符号前加了转义,后面匹配数字价格是怎么做的呢?[\d.]*是指数字和"."出现0次或多次。
而匹配商品名称的正则表达式:
r'\"raw_title\"\:\".*?\"'
前面还是一样,后面的.*?是指匹配单个字符0次或多次,但是在能使整个匹配成功的前提下使用最少的重复(非贪婪匹配) 。
def parsePage(glist, html):
解析网页,搜索需要的信息
:param glist: 列表作为存储容器
:param html: 由getHTMLText()得到的
:return: 商品信息的列表
# 使用正则表达式提取信息
#商品价格
price_list = re.findall(r'\"view_price\"\:\"[\d.]*\"', html)
#商品名称
name_list = re.findall(r'\"raw_title\"\:\".*?\"', html)
for i in range(len(price_list)):
price = eval(price_list[i].split(":")[1]) #eval()在此可以去掉""
name = eval(name_list[i].split(":")[1])
glist.append([price, name])
except:
print("解析失败")
3.将信息输出到屏幕上
def printGoodList(glist):
tplt = "{0:^4}\t{1:^6}\t{2:^10}"
print(tplt.format("序号", "商品价格", "商品名称"))
count = 0
for g in glist:
count = count + 1
print(tplt.format(count, g[0], g[1]))
# 根据页面url的变化寻找规律,构建爬取url
goods_name = "书包" # 搜索商品类型
start_url = "https://s.taobao.com/search?q=" + goods_name
info_list = []
page = 3 # 爬取页面数量
count = 0
for i in range(page):
count += 1
url = start_url + "&s=" + str(44 * i)
html = getHTMLText(url) # 爬取url
parsePage(info_list, html) #解析HTML和爬取内容