

R 数据可视化 —— ggplot2 分面

前言
分面的作用是在一个页面上自动放置多幅图像,它先将数据划分为多个不同的子集,然后分别将每个子数据集绘制到页面的小图形面板中。
ggplot2
有两种分面类型:
-
网格型 ——
facet_grid:
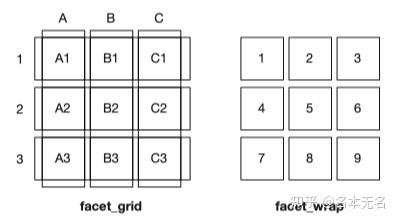
生成一个2维面板网格,通过行列对应变量的不同level
-
封装型 ——
facet_wrap:
生成一个1维面板,然后按行或按列顺序添加子图进去,形成2维布局
二者之间的区别,可以从下图中看出
1. 网格分面
facet_grid(
rows = NULL,
cols = NULL,
scales = "fixed",
space = "fixed",
shrink = TRUE,
labeller = "label_value",
as.table = TRUE,
switch = NULL,
drop = TRUE,
margins = FALSE,
facets = NULL
网格分面会根据分面表达式,自动设置哪些变量作为行,哪些变量作为列,具体规则如下:
- 不分面
不使用
facet_grid
或加上
facet_null()
ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_null()
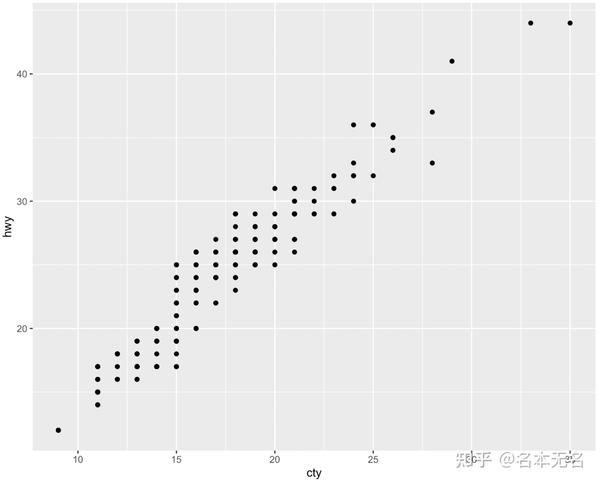
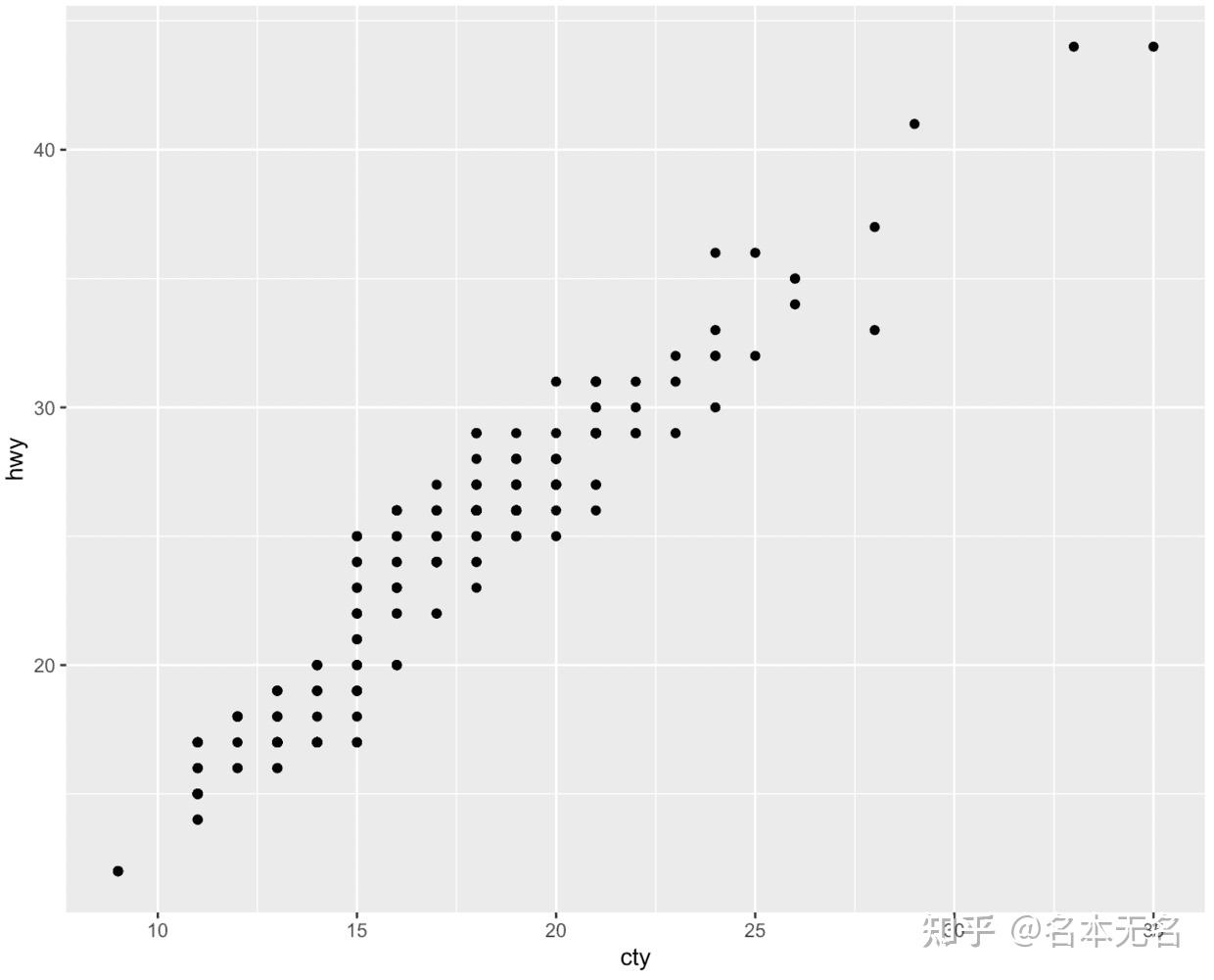
-
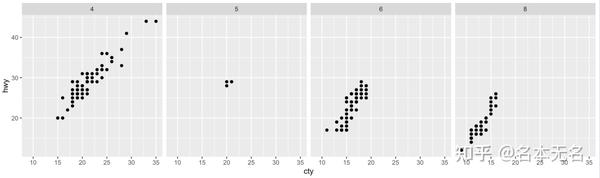
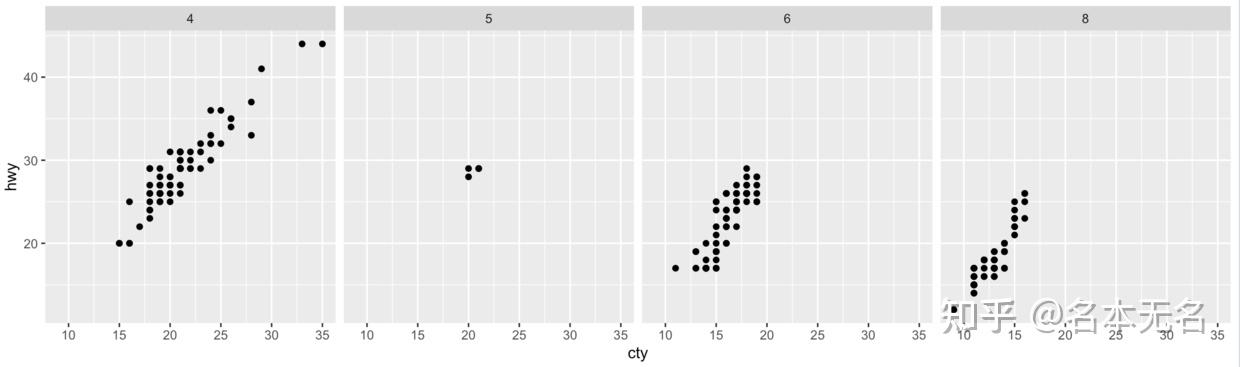
一行多列:
. ~ var
宽屏显示,所有图绘制在同一行,方便比较不同图之间的
y
轴位置。
ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_grid(. ~ cyl)
-
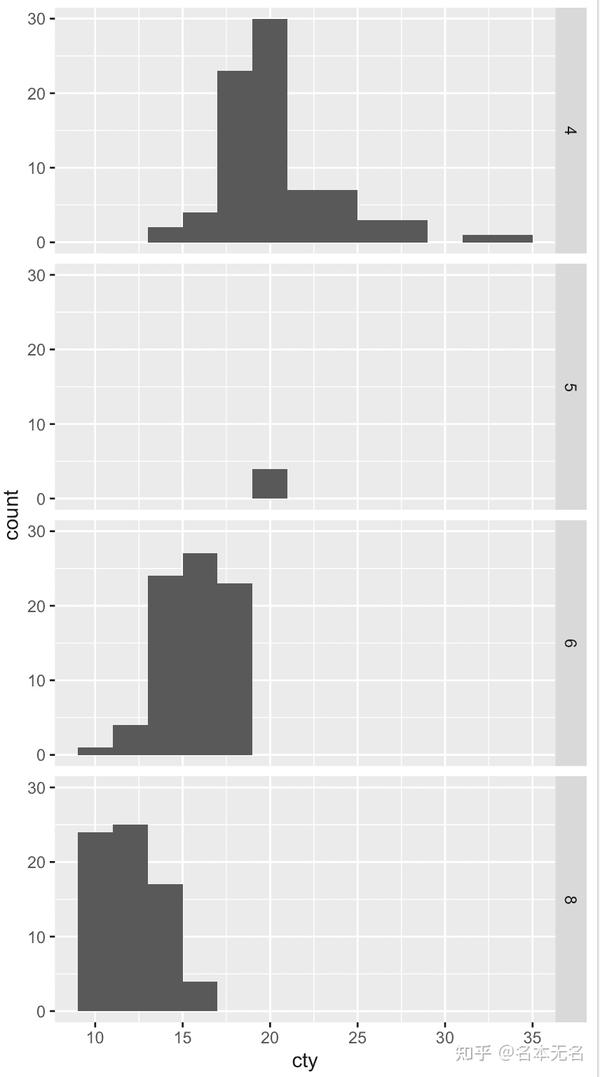
多行一列:
var ~ .
竖直排列,具有相同的横坐标,方便比较
x
轴的位置,尤其适用于不同数据分布的比较。
ggplot(mpg, aes(cty)) +
geom_histogram(binwidth = 2) +
facet_grid(cyl ~ .)

-
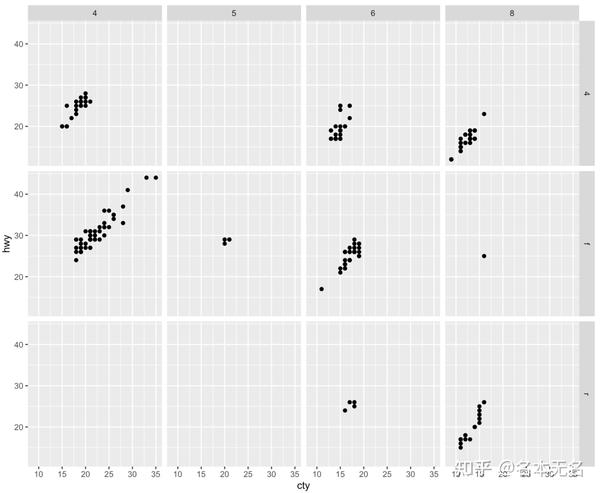
多行多列:
var1 ~ var2
通常将
level
最多的变量按列放置,充分利用屏幕的宽高比
ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_grid(drv ~ cyl)
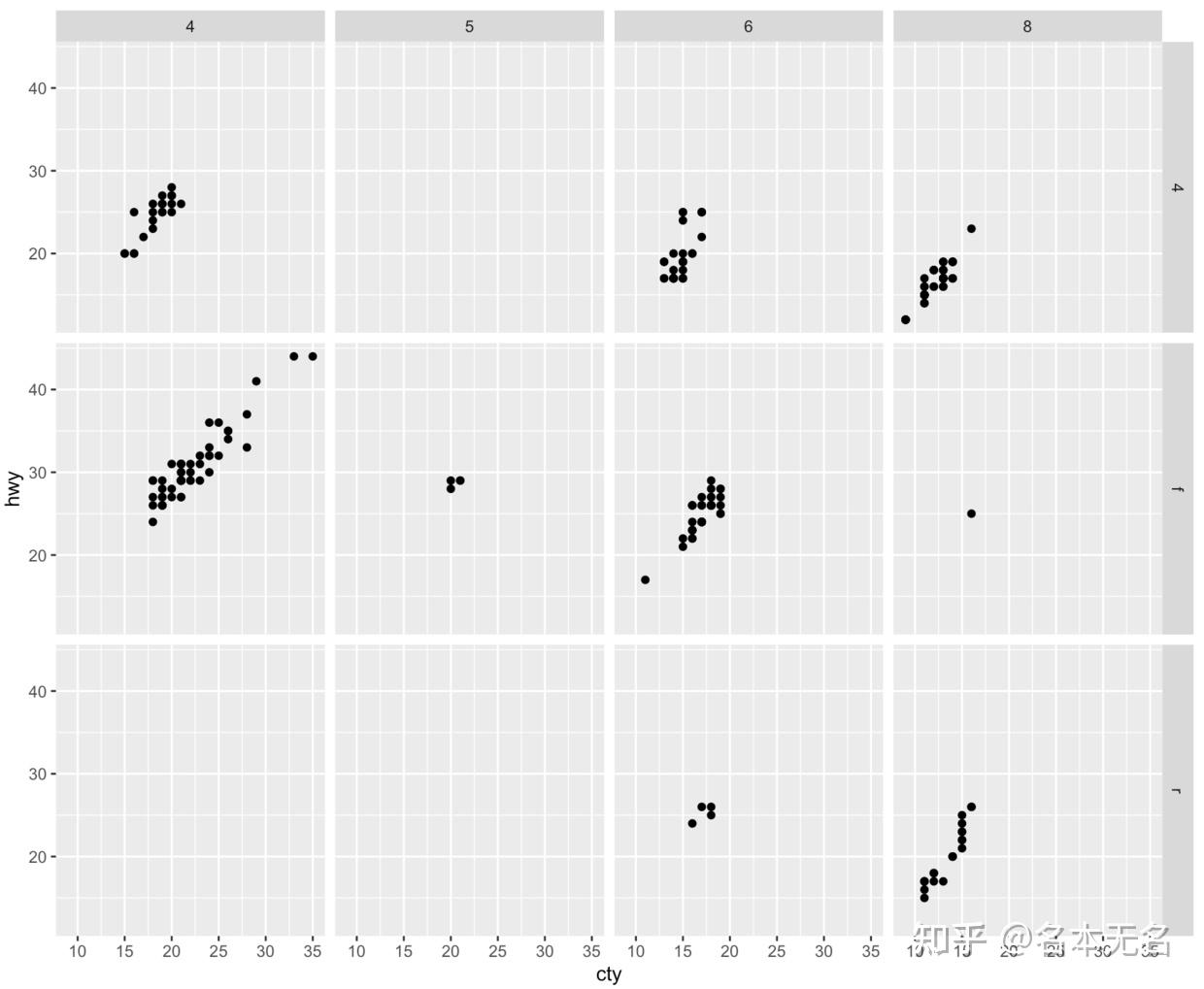
注意
:在上面的图形中,我们可以看到三个空白的面板,这是由于行列变量的不同
level
会两两组合,每种组合绘制一张图片,而没有在数据中出现的组合会产生空白图。
-
多个变量组合在同一行或同一列:
. ~ var1 + var2(一行) 或var1 + var2 ~ .(一列)
ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_grid(cyl + drv ~ .)
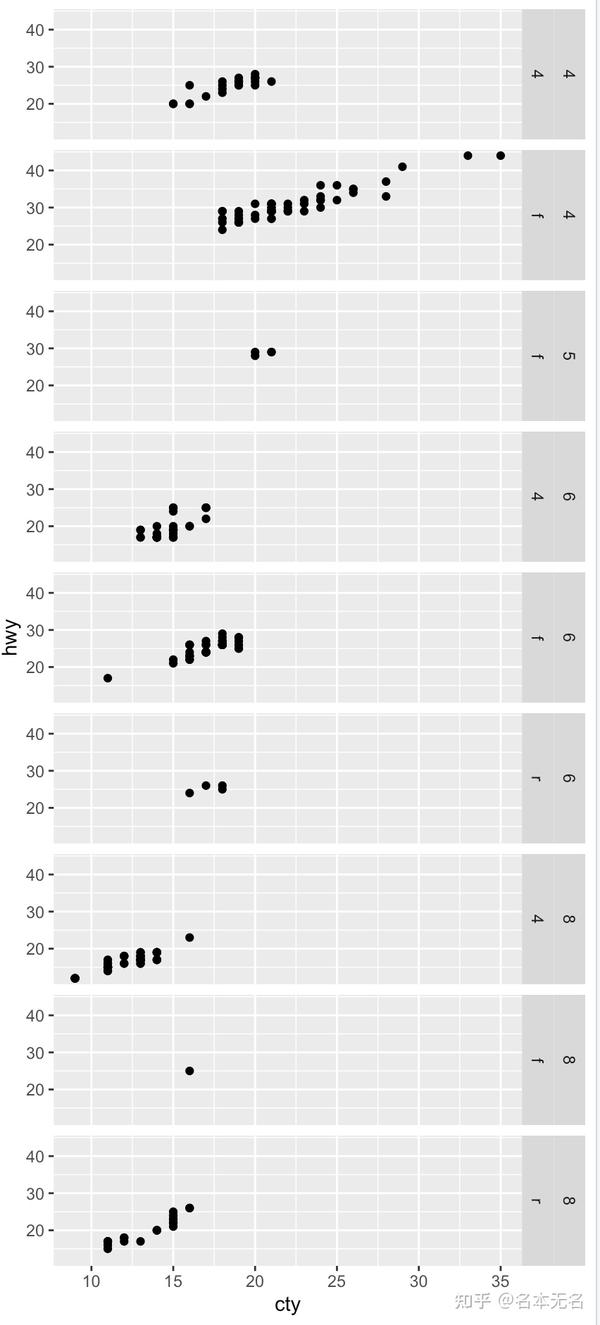
与多行多列图形不同,只有出现的组合才会被绘制,所以不会出现空白图片。
注意
上面的表达式也可以转换为用 vars 函数引用的变量,例如
. ~ var => cols = vars(var)
var ~ . => rows = vars(var)
var1 ~ var2 => rows = vars(var1), cols = vars(var2)
. ~ var1 + var2 => cols = vars(var1, var2)
对于facet_grid和facet_wrap均适用
边际图
对于多行多列的网格状图,我们可能希望在每行或每列的数据值进行一个汇总,添加一个汇总图。
我们可以设置
margins = TRUE
来展示所有的边际汇总图,或者指定一个字符串或字符串向量如
margins = c("", "")
,来展示某一个变量的边际汇总图
例如
smpg <- mpg %>% subset(drv != 'r' & cyl != 5)
p1 <- ggplot(smpg, aes(cty, hwy)) +
geom_point() +
facet_grid(rows = vars(drv), cols = vars(cyl))
p2 <- ggplot(smpg, aes(cty, hwy)) +
geom_point() +
facet_grid(rows = vars(drv), cols = vars(cyl),
margins = TRUE)
p3 <- ggplot(smpg, aes(cty, hwy)) +
geom_point() +
facet_grid(rows = vars(drv), cols = vars(cyl),
margins = "drv")
p4 <- ggplot(smpg, aes(cty, hwy)) +
geom_point() +
facet_grid(rows = vars(drv), cols = vars(cyl),
margins = "cyl")
plot_grid(p1, p2, p3, p4, labels = LETTERS[1:4], nrow = 2)
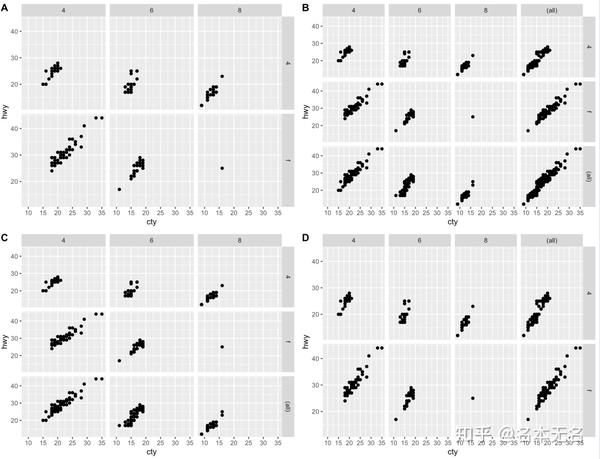
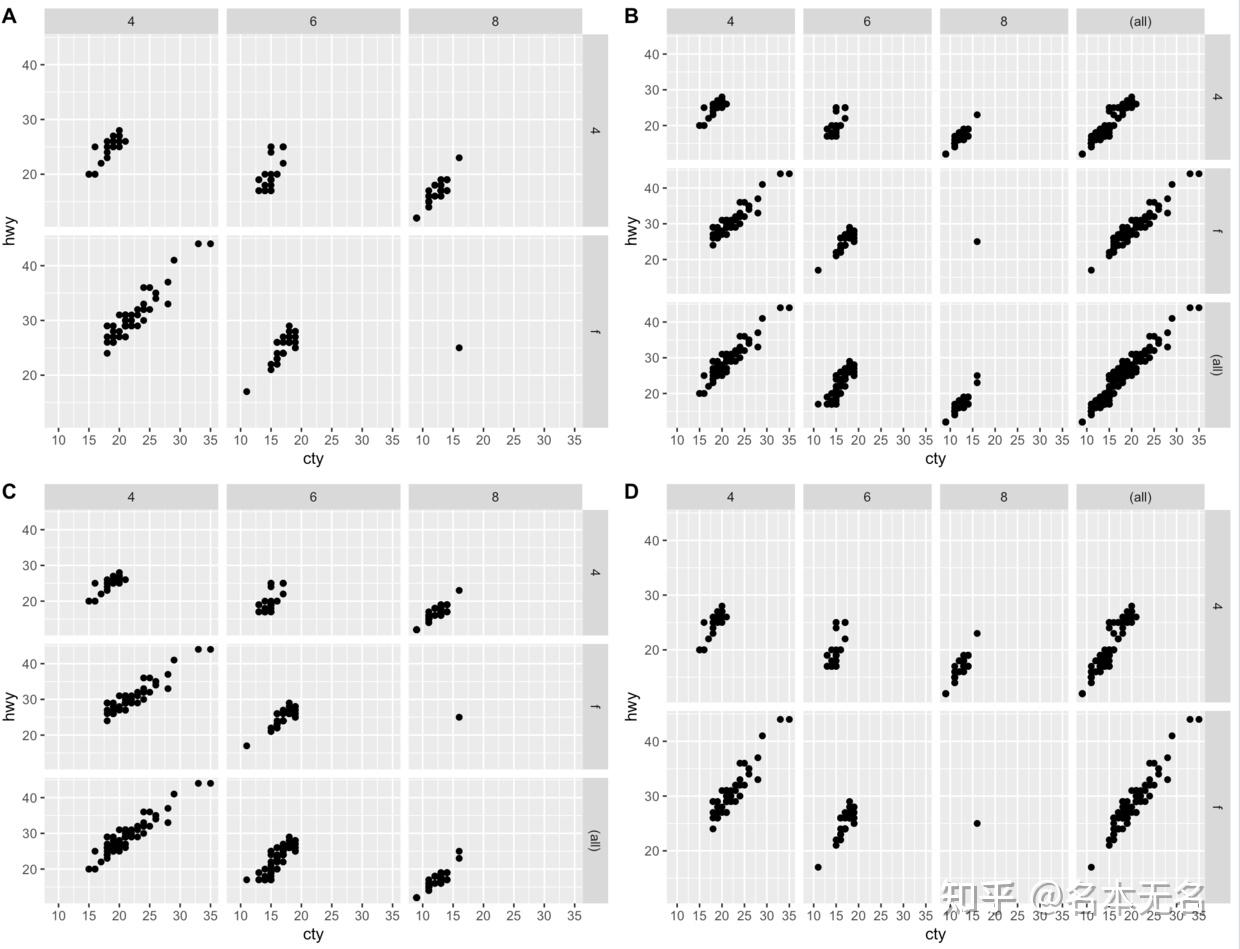
2. 封装分面
facet_wrap(
facets,
nrow = NULL,
ncol = NULL,
scales = "fixed",
shrink = TRUE,
labeller = "label_value",
as.table = TRUE,
switch = NULL,
drop = TRUE,
dir = "h",
strip.position = "top"
不同于网格分面,封装分面可以这样理解,它首先生成一个长的绘图面板,然后将图形一个个添加进去,填充完一行后另起一行开始填充,这样看起来也是二维的面板。
示例
p <- ggplot(mpg, aes(displ, hwy)) + geom_point()
p1 <- p + facet_wrap(vars(class))
# 控制行列数
p2 <- p + facet_wrap(vars(class), nrow = 4)
# 组合多变量
p3 <- ggplot(mpg, aes(displ, hwy)) +
geom_point() +
facet_wrap(vars(cyl, drv))
# 控制显示的标签
p4 <- ggplot(mpg, aes(displ, hwy)) +
geom_point() +
facet_wrap(vars(cyl, drv), labeller = "label_both")
plot_grid(p1, p2, p3, p4, labels = LETTERS[1:4], nrow = 2)
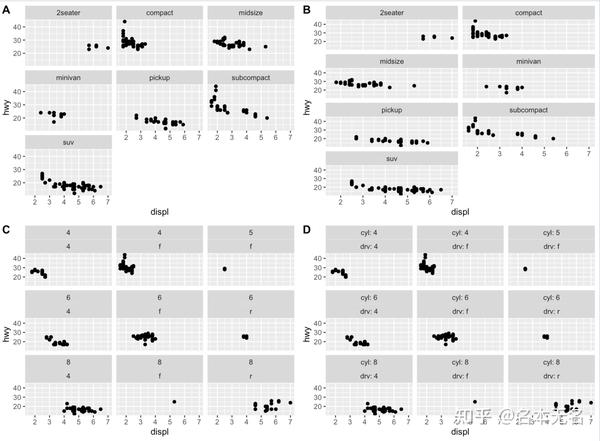
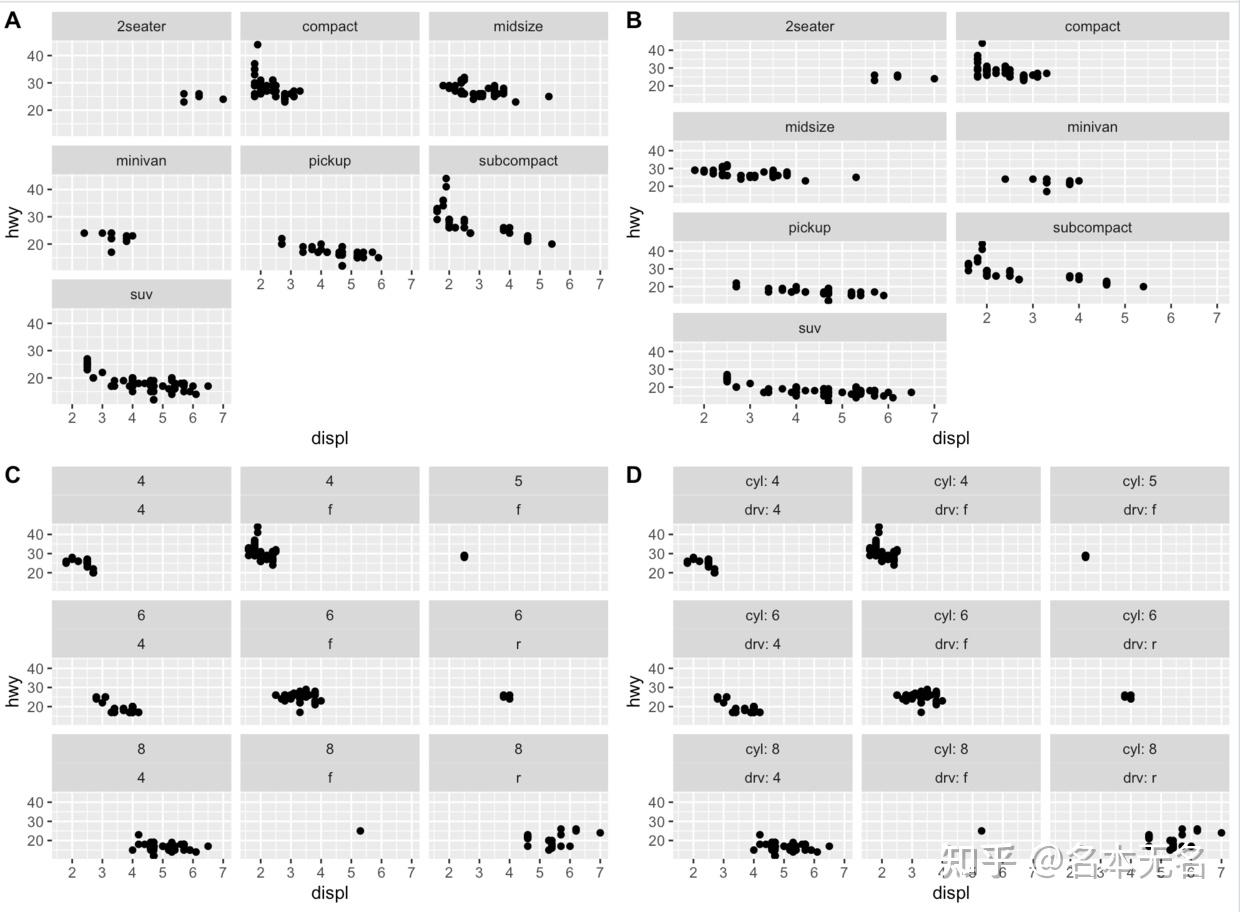
想要更改面板图形的显示顺序,需要修改对应因子变量的
level
顺序
mpg$class2 <- reorder(mpg$class, mpg$displ)
p5 <- ggplot(mpg, aes(displ, hwy)) +
geom_point() +
facet_wrap(vars(class2))
plot_grid(p1, p5, labels = LETTERS[1:2], nrow = 2)
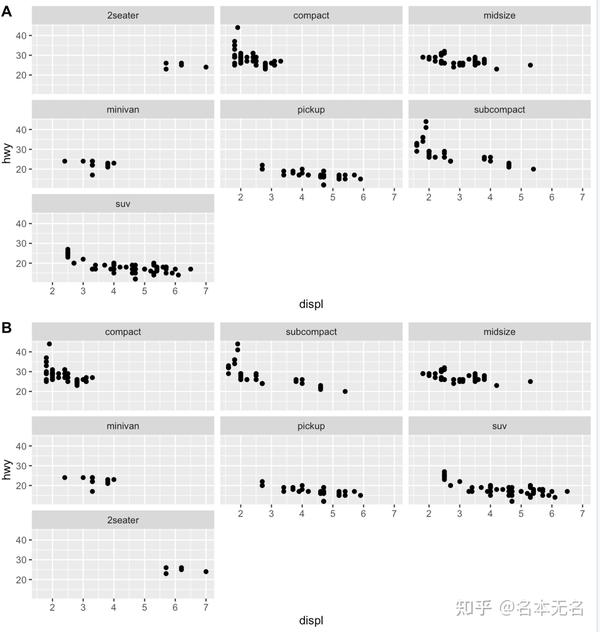
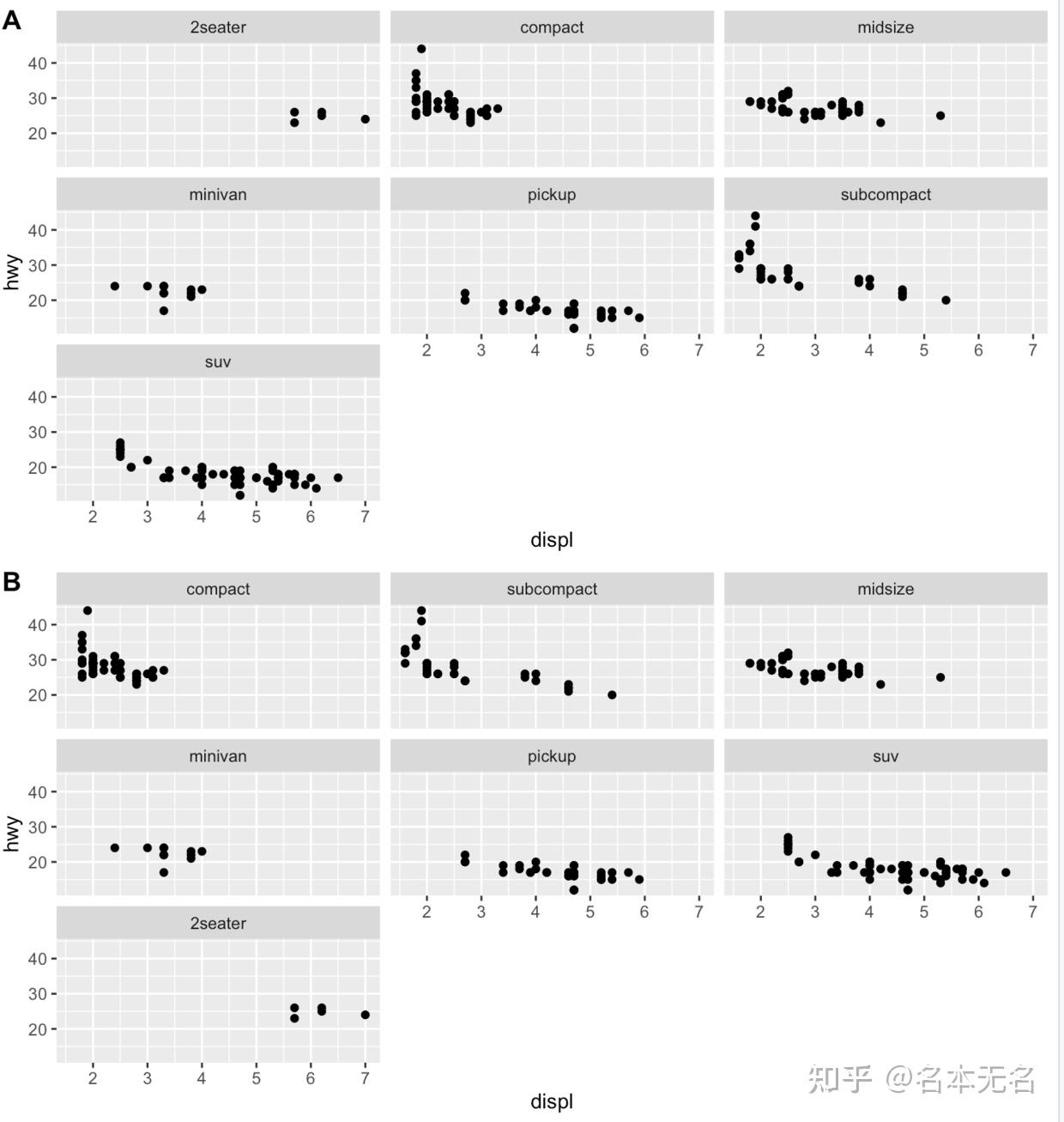
通过将数据的分面变量设置为
NULL
,可以在所有的子图中绘制一个相同的图像
例如,我们通过将分面变量设置为空,在所有子图中绘制了一个包含所有数据点的浅色点图,这样可以更清晰的看出各部分占总体的情况
ggplot(mpg, aes(displ, hwy)) +
geom_point(data = transform(mpg, class = NULL), colour = "grey85") +
geom_point() +
facet_wrap(vars(class))
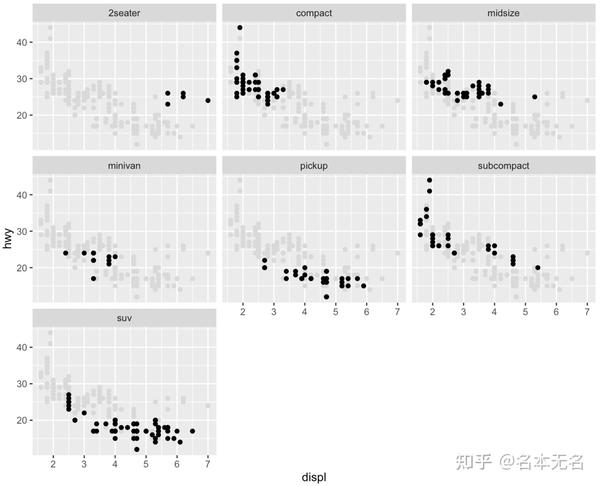

这也相当于为所有面板添加了一个背景图
3. 标度控制
两种分面都可以使用
scales
来控制面板的位置标度是否固定,可以取以下值:
-
fixed:所有面板的x和y都是一样的,默认值 -
free:所有面板的x和y都是自由变化的 -
free_x:x轴可变,y轴固定 -
free_y:x轴固定,y轴可变
p1 <- ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_wrap(vars(cyl), scales = "fixed")
p2 <- ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_wrap(vars(cyl), scales = "free")
p3 <- ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_wrap(vars(cyl), scales = "free_x")
p4 <- ggplot(mpg, aes(cty, hwy)) +
geom_point() +
facet_wrap(vars(cyl), scales = "free_y")
plot_grid(p1, p2, p3, p4, labels = LETTERS[1:4], nrow = 2)
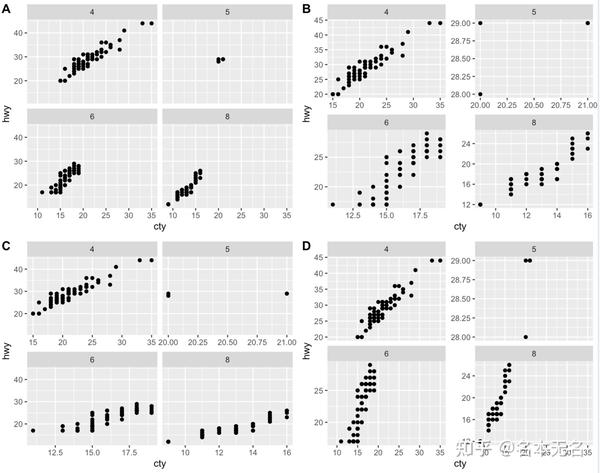
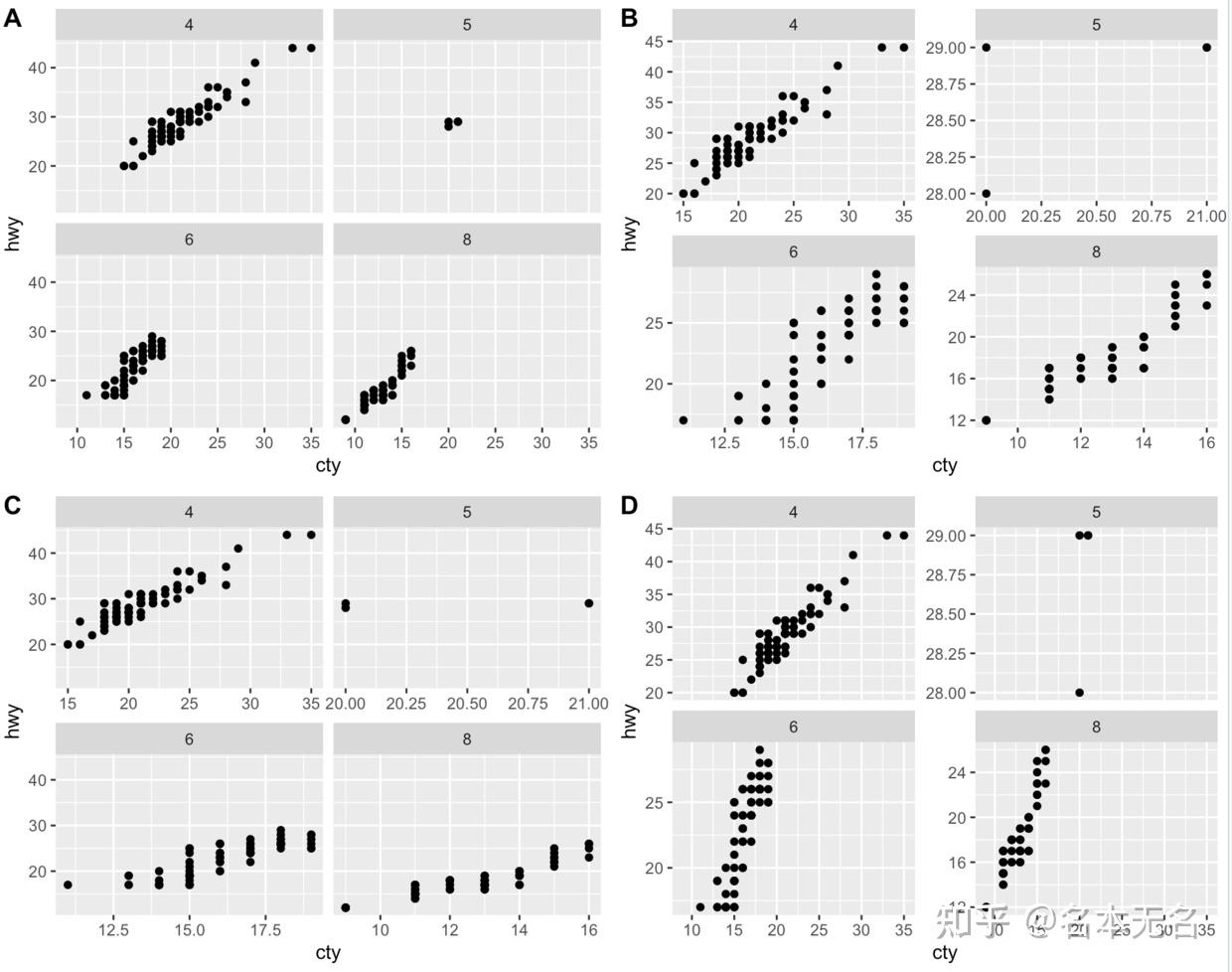
对于
facet_grid
还有一个
space
参数,可接受的值同
scales
一样
-
fixed:所有面板的大小一样,默认值 -
free:它们的高度和宽度与标度范围成比例 -
free_x:它们的宽度与x标度的长度成比例 -
free_y:它们的高度与y标度的长度成比例
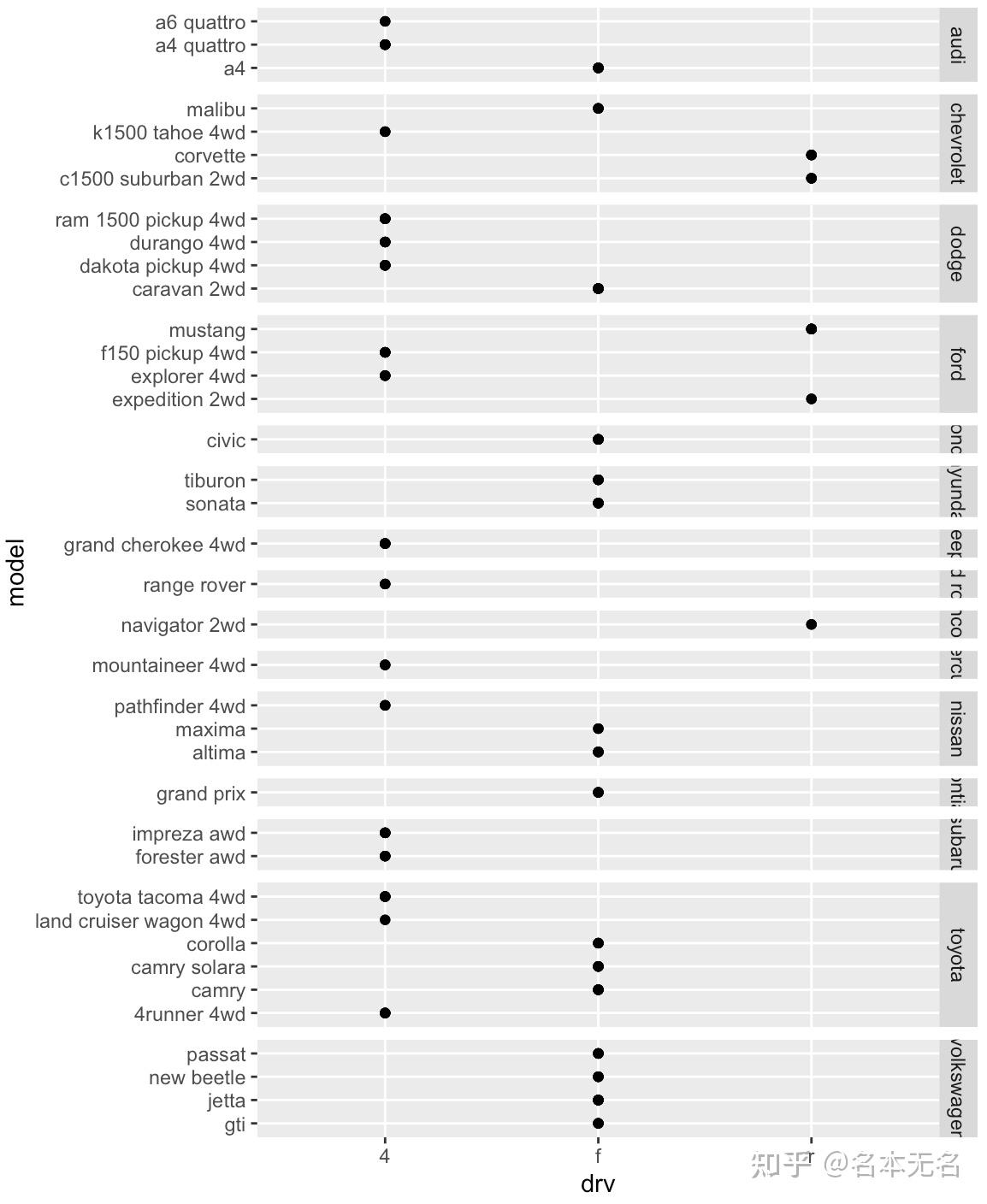
ggplot(mpg, aes(drv, model)) +
geom_point() +
facet_grid(manufacturer ~ ., scales = "free", space = "free")
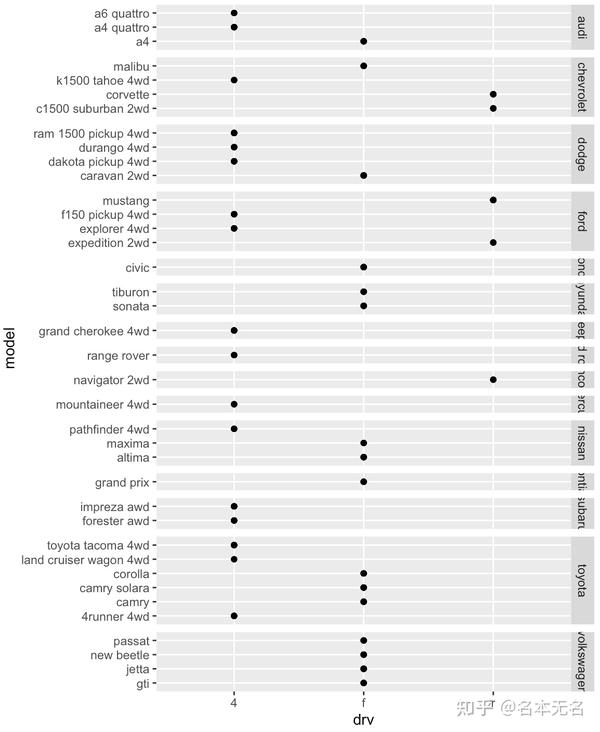
4. 分组与分面
我们可以将分组和分面放在一起进行比较。在之前的示例中,我们可以为数据设置不同的图像属性,如颜色、大小等,来区分不同的分组
而分面是根据变量的
level
绘制不同的子图。这两种方式都有各自的优缺点。
在分面中,不同组别拥有不同的面板,相隔较远,难以看出组间的关系;但是不存在组间数据的重叠,能够很好的分隔数据。
而分组则与分面互补,组间容易重叠,但是能够较容易可以看出组间的关系。
例如
xmaj <- c(0.3, 0.5, 1,3, 5)
xmin <- as.vector(outer(1:10, 10^c(-1, 0)))
ymaj <- c(500, 1000, 5000, 10000)
ymin <- as.vector(outer(1:10, 10^c(2,3,4)))
dsub <- subset(diamonds, color %in% c("D","E","G","J"))
p <- ggplot(dsub, aes(carat, price, colour = color)) +
scale_x_log10(breaks = xmaj, labels = xmaj, minor = xmin) +
scale_y_log10(breaks = ymaj, labels = ymaj, minor = ymin) +
scale_colour_hue(limits = levels(diamonds$color)) +
theme(legend.position = "none")
p1 <- p + geom_point()
p2 <- p + geom_point() + facet_grid(. ~ color)
plot_grid(p1, p2, labels = LETTERS[1:2], nrow = 2)
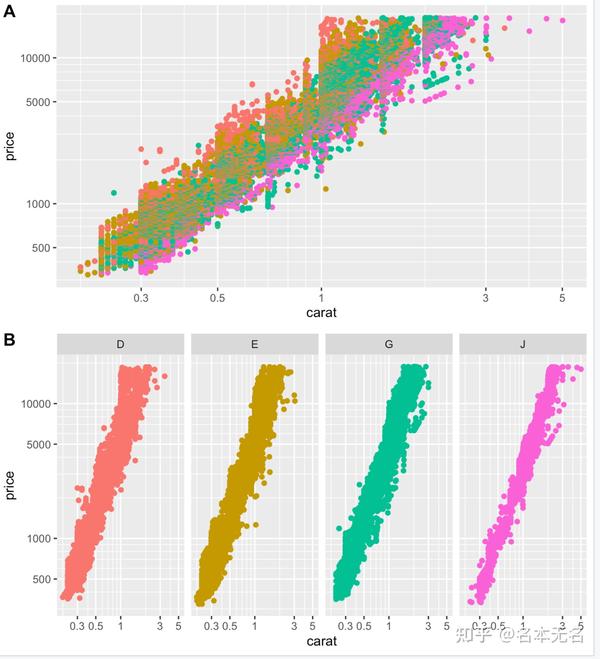
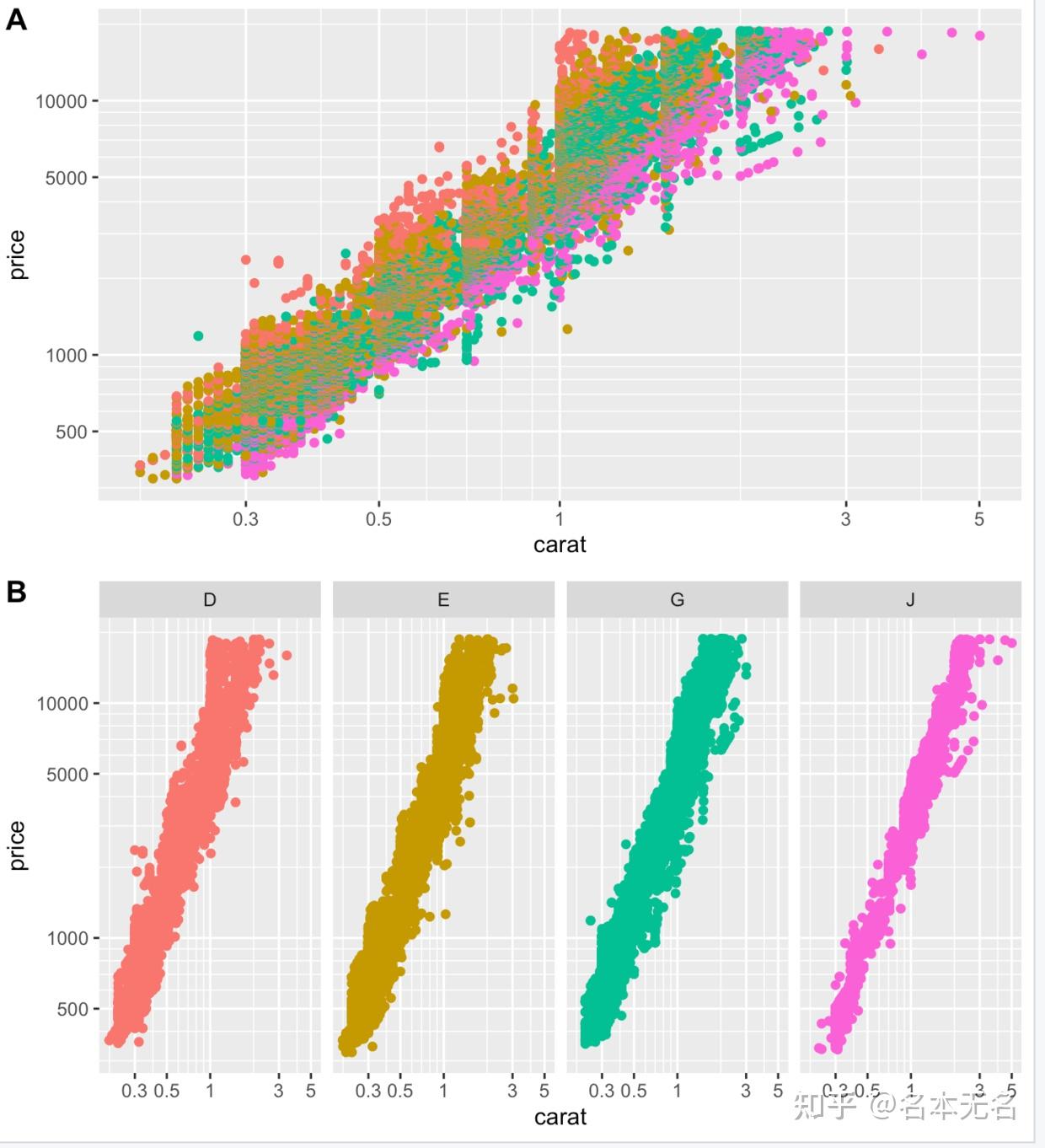
在图
A
中,各分组之间都交叠在一起了,很难区分谁是谁,而使用分面,可以将每组都区分开,每组的趋势也很明显
但是,当我们使用回归线时,情况又有些不同了
p3 <- p + geom_smooth(method = lm, se = F, fullrange = T)
p4 <- p + geom_smooth(method = lm, se = F, fullrange = T) + facet_grid(. ~ color)
plot_grid(p3, p4, labels = LETTERS[3:4], nrow = 2)
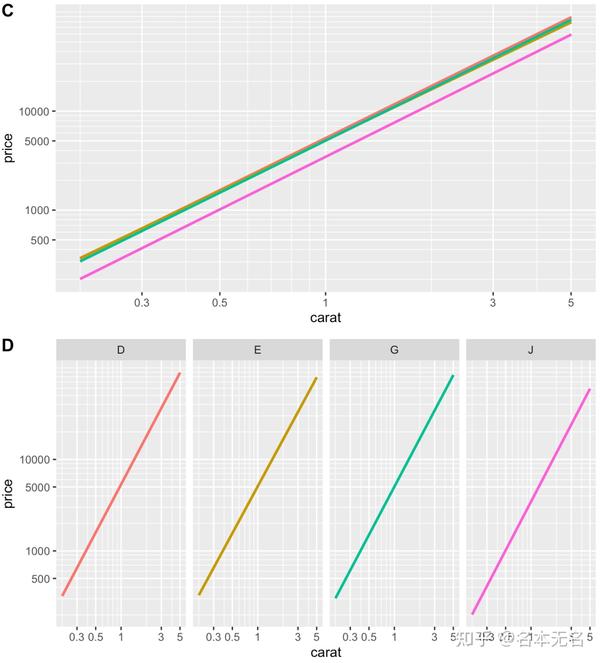
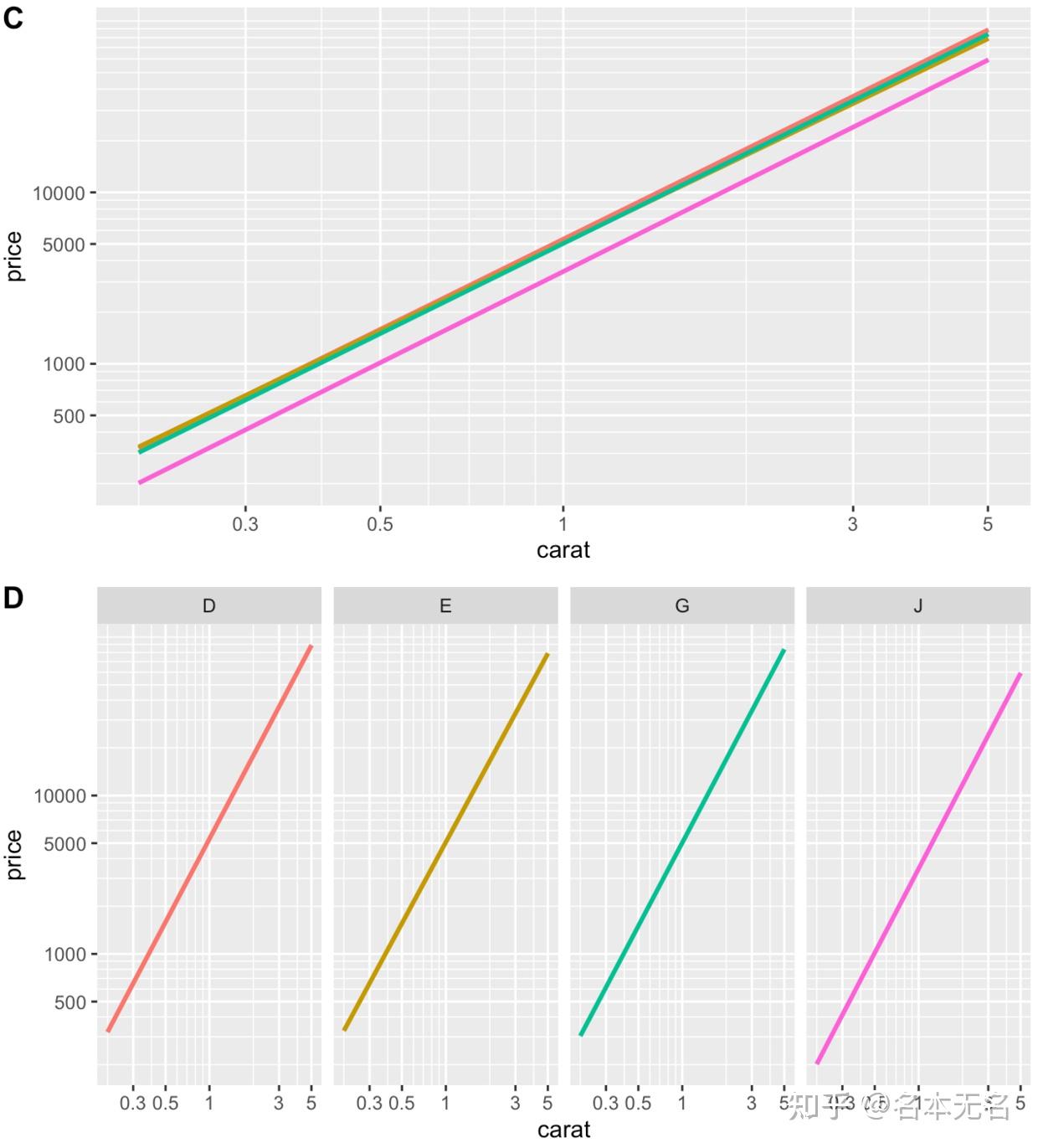
在图
C
中,我们可以看到
D
、
E
和
G
几乎完全重叠,而
J
则与它们相隔更远
分面还有其他优点,比如,能够很好的设置分组的图形属性和标度等。
5. 并列与分面
可以使用分面绘制出与并列图形类似的效果,但是分面的标注方式会更多一些。
例如
p1 <- ggplot(diamonds, aes(color, fill = cut)) +
geom_bar(position = "dodge")
p2 <- ggplot(diamonds, aes(cut, fill = cut)) +
geom_bar() +
facet_grid(. ~ color) +
theme(axis.text.x = element_text(angle = 90, hjust = 1, size = 8,
colour = "grey50"))
plot_grid(p1, p2, labels = LETTERS[1:2], nrow = 2)
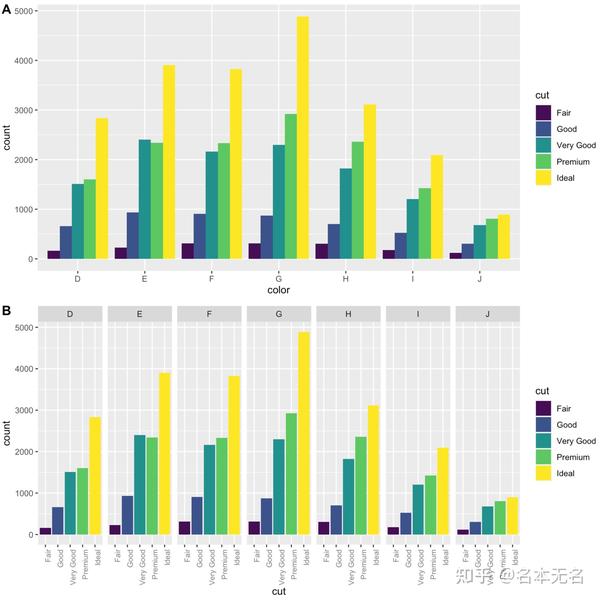

6. 连续型变量的分面
在本章前面的示例中,都是对离散型变量进行分面,对于连续型数据,需要先将其转换为离散型。
有三种转换方式:
- 按区间划分:
-
cut_interval(x, n = 10): 划分为10个区间 -
cut_interval(x, length = 10):每个区间长度为10 - 等数量划分:
-
cut_number(x, n=10): 划分为10个区间,每个区间数量相同
例如
df <- subset(mpg, year == 1999)
df$disp_ww <- cut_interval(df$displ, length = 1)
df$disp_wn <- cut_interval(df$displ, n = 6)
df$disp_nn <- cut_number(df$displ, n = 6)
p <- ggplot(df, aes(cty, hwy)) +
geom_point() +
labs(x = NULL, y = NULL)