


一块RTX3050搞定DLRM训练!仅需1%Embedding参数,硬件成本降低至百分之一 | 开源

深度推荐模型(DLRMs)已经成为深度学习在互联网公司应用的最重要技术场景,如视频推荐、购物搜索、广告推送等流量变现业务,极大改善了用户体验和业务商业价值。
但海量的用户和业务数据,频繁地迭代更新需求,以及高昂的训练成本,都对DLRM训练提出了严峻挑战。
在DLRM中,需要先在嵌入表(EmbeddingBags)中进行查表(lookup),再完成下游计算。
嵌入表常常贡献DLRM中99%以上的内存需求,却只贡献1%的计算量。
借助于GPU片上高速内存(High Bandwidth Memory)和强大算力的帮助,GPU成为DLRM训练的主流硬件。
但是,随着推荐系统研究的深入,日益增长的嵌入表大小和有限的GPU显存形成显著矛盾。如何让利用GPU高效训练超大DLRM模型,同时突破GPU内存墙的限制,已成为DLRM领域亟待解决的关键问题。
Colossal-AI此前已成功利用异构策略将相同硬件上训练NLP模型的参数容量提升上百倍,近期成功将其拓展到推荐系统中,通过软件缓存(Cache)方法在CPU 和 GPU 内存中动态存储嵌入表。
基于软件Cache设计,Colossal-AI还添加流水预取,通过观察未来即将输入的训练数据,降低软件Cache检索和数据移动开销。
同时,它以同步更新方式在 GPU 上训练整个 DLRM模型,结合广泛使用的混合并行训练方法,可以扩展到多个 GPU。
实验表明, Colossal-AI仅需在 GPU 中保留 1% 的嵌入参数 ,仍能保持优秀的端到端训练速度。
相比PyTorch其他方案,显存需求 降低一个数量级 ,单块显卡即可训练 TB级 推荐模型。
成本优势显著,例如仅需5GB显存即可训练占据91GB空间 Embedding Bag的DLRM,训练硬件成本从两张约20万元的A100,降低至百分之一 仅需2000元左右 的RTX 3050等入门级显卡。
开源地址:
https://
github.com/hpcaitech/Co
lossalAI
现有的嵌入表扩展技术
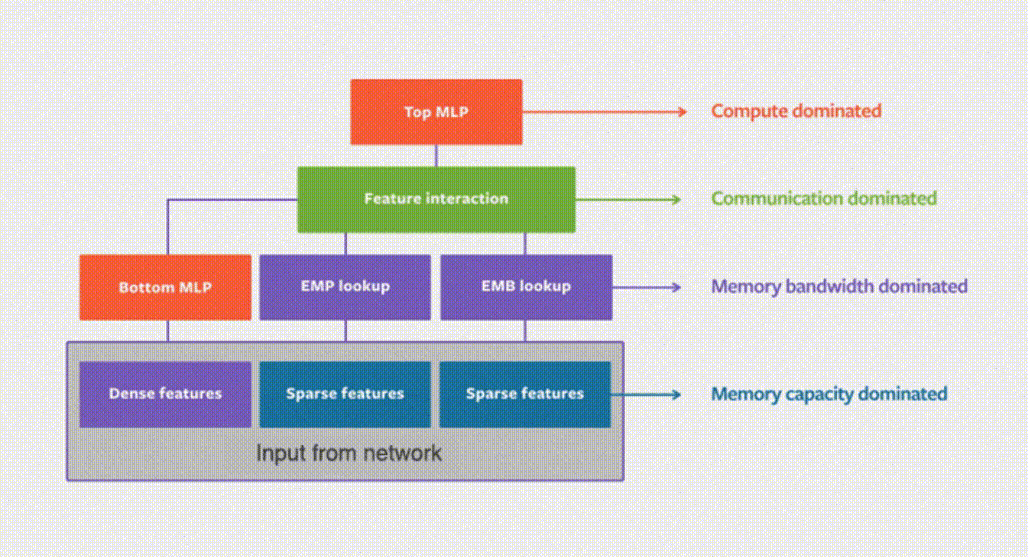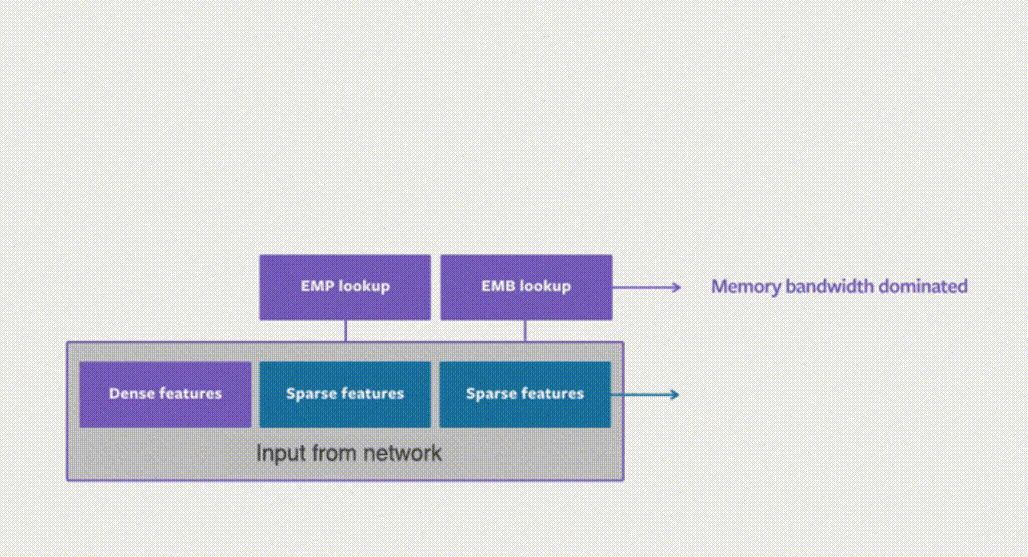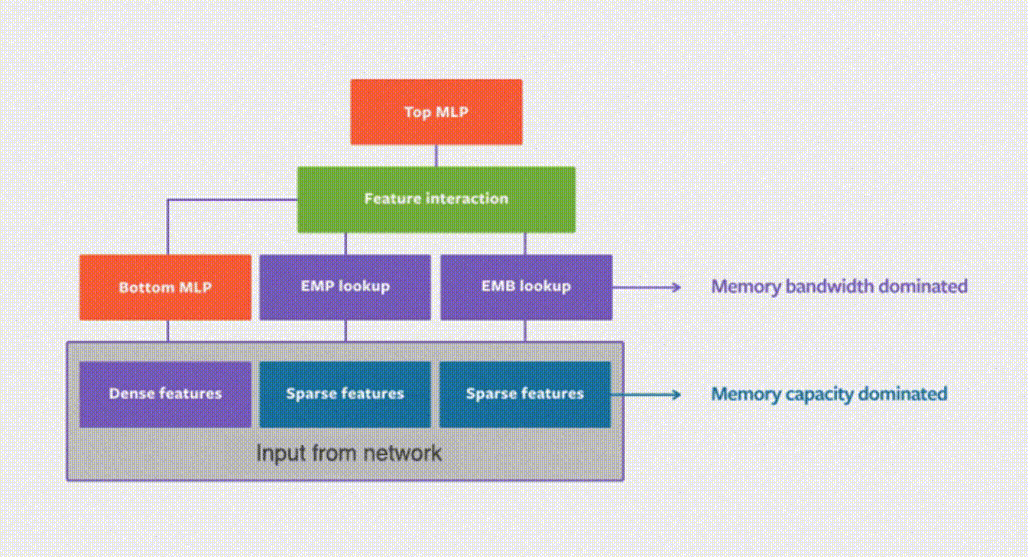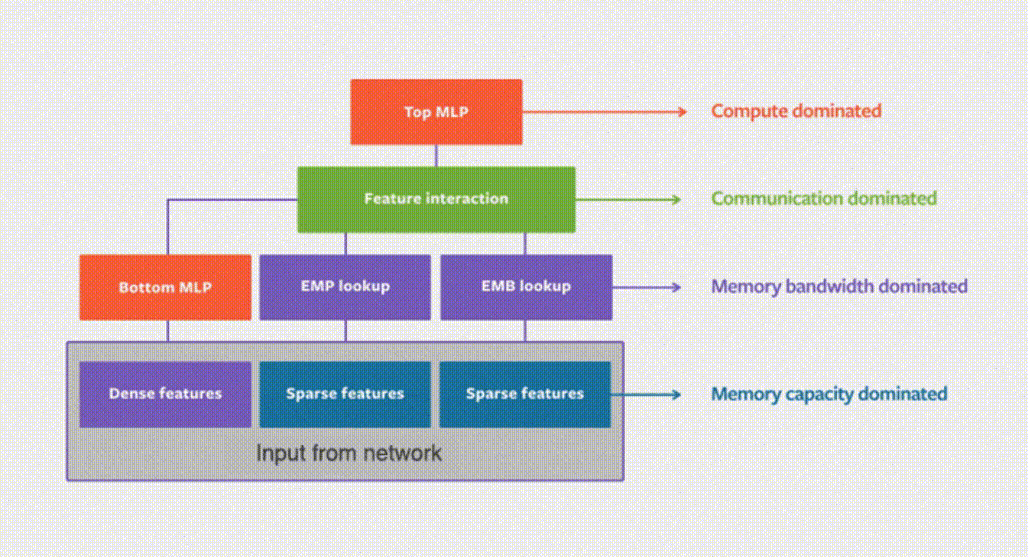
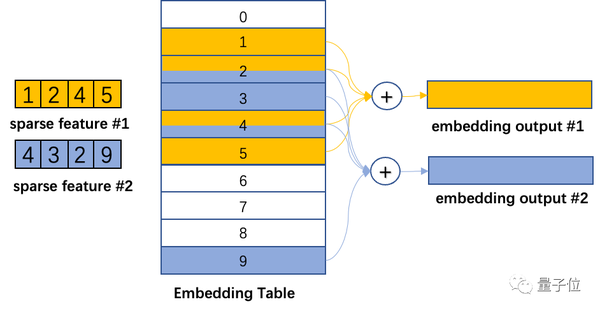
嵌入表将离散的整型特征映射成连续的浮点特征向量,下图展示了DLRM中的嵌入表训练过程。
首先,在嵌入表中对每个特征查找Embedding Table对应的行,然后通过规约操作,比如max,mean, sum操作,变成一个特征向量,传递给后续的稠密神经网络。
可见,DLRM的嵌入表训练过程主要是不规则的内存访问操作,因此严重受限于硬件访存速度。
而工业级DLRM的嵌入表可能达到数百GB甚至TB级别,远超单GPU最高数十GB的显存容量。
突破单GPU的内存墙来增大DLRM的嵌入表规模有很多方法。
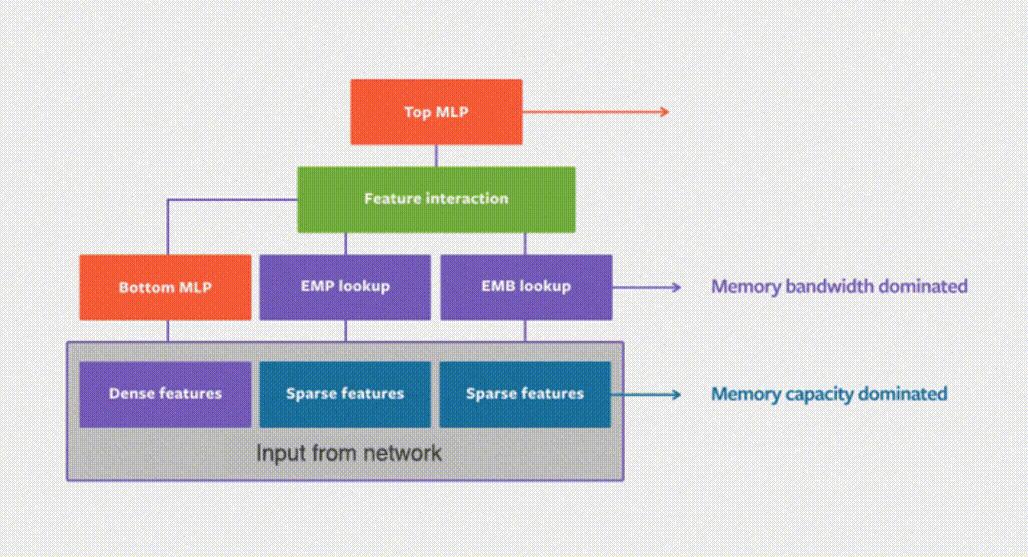
根据下图展示的GPU集群的内存层级图为例,让我们来分析几种常见方案的优劣。
GPU模型并行:
将嵌入表切分后分布在多个GPU的内存中,训练中通过GPU之间互联网络同步中间结果。
这种方式的缺点首先是嵌入表切分负载并不均匀,扩展性问题难以解决。
其次,增加GPU的前期硬件成本大,而且DLRM训练时GPU的计算能力并没有被充分利用,而是仅仅利用了它的HBM带宽优势,导致GPU使用率不高。
CPU部分训练:
将嵌入表分割成两部分,一部分在GPU上训练,另一部分在CPU上训练。
通过利用数据分布的长尾效应,我们可以让CPU计算比例尽可能少,让GPU计算比例尽可能大。但是,随着batch size增大,让mini-batch的数据全部命中CPU或者GPU很困难,如果同时命中CPU或GPU这种方法很难处理。
另外,由于DDR带宽和HBM相差一个数据量级,即使10%的输入数据在CPU上训练,整个系统也会有至少一半速度下降。
此外,CPU和GPU需要传输中间结果,这也有不小的通信开销,进一步拖慢训练速度。
因此,研究人员设计了异步更新等方式来避免这些性能缺陷,但是异步方式会造成训练结果的不确定性,在实践中并不是算法工程师的首选方案。
软件Cache:
保证训练全部在GPU上进行,嵌入表存在CPU和GPU组成的异构空间中,每次通过软件Cache方式,将需要的部分换入GPU。
这种方式可以廉价扩展存储资源,满足嵌入表不断增大的需求。
而且,相比使用CPU来计算,这种方式的整个训练过程完全在GPU上完成,充分利用HBM带宽优势。但Cache的查询、数据移动会带来额外性能损耗。
目前已经有一些针对嵌入表优秀的软件Cache方案实现,但是它们往往使用定制的EmbeddingBags Kernel实现,比如fbgemm,或者借助第三方深度学习框架。
而Colossal-AI在原生PyTorch基础上 不做任何Kernel层次改动, 提供了一套开箱用的软件Cache EmbeddingBags实现,还进一步针对DLRM训练流程进行优化,提出预取流水来进一步降低Cache开销。


Colossal-AI的嵌入表软件Cache
Colossal-AI实现了一个软件Cache并封装成nn.Module提供给用户在自己模型中使用。
DLRM的嵌入表,一般是由多个Embedding组成的EmbeddingBags,驻留在 CPU 内存中。
这部分内存空间被命名为CPU Weight。而EmbeddingBags一小部分数据存储在 GPU内存中,它包括即将被训练用到的数据。
这部分内存空间被命名为CUDA Cached Weight。
在 DLRM 训练期间,首先需要确定本次迭代输入mini-batch的数据所对应嵌入表的行,如果有的行不在GPU中,需要将它们从CPU Weight传输到 CUDA Cached Weight中。
如果GPU中没有足够的空间,它会使用LFU算法,根据访问缓存的历史频率来淘汰被使用最少数据。
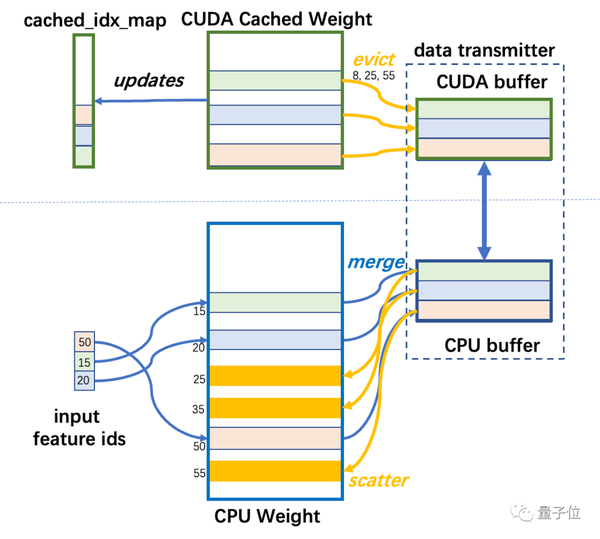
为了实现Cache的检索,需要一些辅助数据结构帮忙:cached_idx_map是一维数组,存储CPU Weight中行号和CUDA Cached Weight的行号对应关系,以及对应行在GPU被访问的频率信息。
CUDA Cached Weight 大小与 CPU Weight 大小的比值命名为 cache_ratio,默认为 1.0% 。
Cache在每个迭代forward之前运行,以调整CUDA Weight中的数据,具体来说分三个步骤。
Step1:CPU索引
检索CPU Weight中需要被Cache的行号。
它需要对输入mini-batch的input_ids和cached_idx_map取交集,找到CPU Weight中需要从CPU移动到GPU的行号。
Step2:GPU索引
根据使用频率找到CUDA Weight中可以被驱逐的行。
这需要我们根据频率以从低到高顺序,对cache_idx_map和input_ids取差集合之后的部分进行top-k(取最大值k个数)操作。
Step3:数据搬运:
将CUDA Cached Weight中的对应行移动到CPU Weight中,然后将CPU Weight中的对应行移动到CUDA Weight中。
数据传输模块负责CUDA Cached Weight和CPU Weight之间的数据双向传输。
不同于低效的逐行传输,它采用先缓存再集中传输方式来提升PCI-e的带宽利用率。
分散在内存中的嵌入行在源设备的本地内存中集中为连续的数据块,然后块在 CPU 和 GPU 之间传输,并分散到目标内存的相应位置。以块为单位移动数据可以提高 PCI-e 带宽利用率,merge和scatter操作只涉及CPU和GPU的片上内存访问,因此开销并不是很大。
Colossal-AI用一个尺寸受限的缓冲区来传输CPU和GPU之间数据。
在最坏的情况下,所有输入 id 都未命中缓存cache,那就需要需要传输大量元素。为了防止缓冲区占用过多内存,缓冲区大小被严格限制。如果传输的数据大于缓冲区,会分为多次完成传输。

软件Cache性能分析
上述Cache Step1和Step2的操作都是访存密集的。
因此为了能利用GPU的HBM的带宽,它们是在GPU上运行的,并使用深度学习框架封装好的API来实现。尽管如此,与嵌入表在GPU上的训练操作相比,Cache操作的开销尤为突出。
比如在一次总计199秒训练任务中,Cache操作的开销为99秒,占比总计算时间 接近50% 。
经过分析,Cache的主要开销主要是Step1和Step2引起。下图base位置展示了此时的Cache开销时间分解,Cache的step1,2 红色和橙色两阶段占Cache总开销的70%。
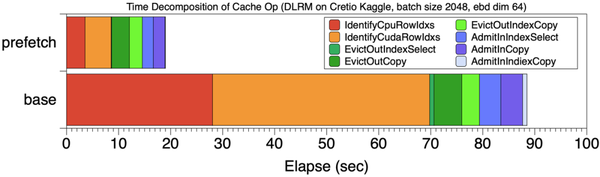
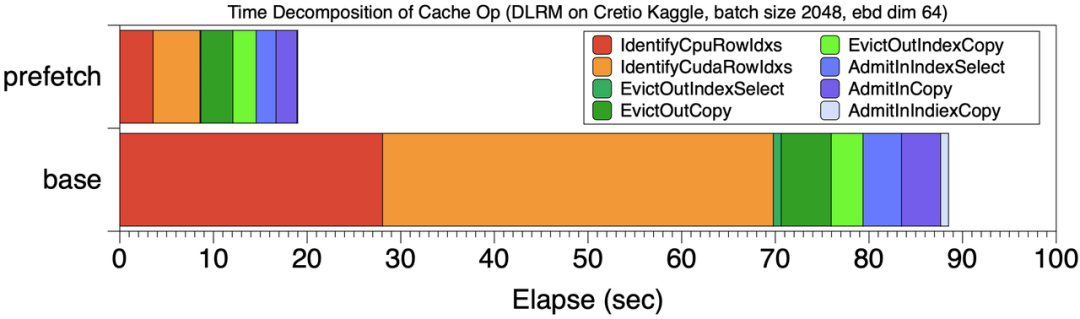
而上述问题的原因,是因为传统的Cache策略有些“短视”,只能根据当前mini-batch情况调整Cache,因此大部分时间浪费在查询操作上。
Cache流水预取
为了缩减Cache的开销,Colossal-AI设计了一套“ 高瞻远瞩 ”的Cache机制。与其只对前mini-batch进行Cache操作,Colossal-AI预取后续将会被使用的若干mini-batch,统一进行Cache查询操作。
如下图所示,Colossal-AI使用预取来合并多个mini-batch数据统一进行Cache操作,同时采用流水线方式来重叠数据读取和计算的开销。
例子中预取mini-batch数量是2。在开始训练前,先从磁盘读取mini-batch 0,1数据到GPU内存,随后开始Cache操作,然后执行这两个mini-batch的正、反向传播和参数更新。
与此同时,可以和对mini-batch 2,3的开始数据读取,这部分开销可以和计算重叠。
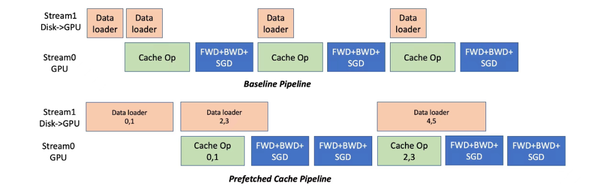
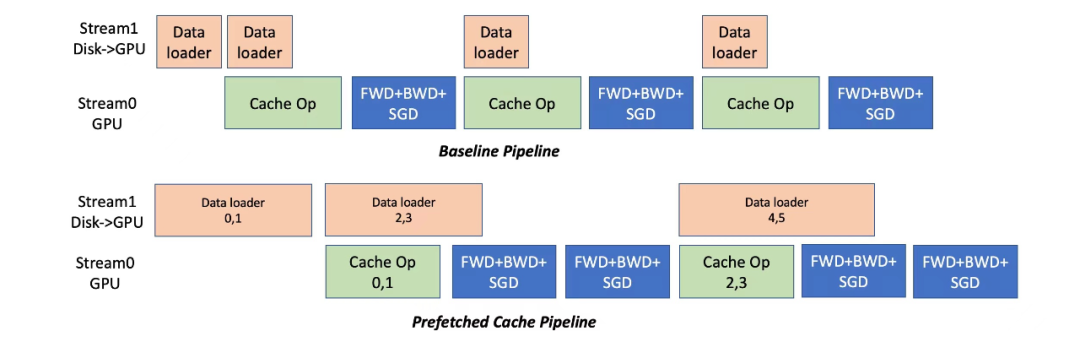
和baseline Cache执行方式相比,图【Cache操作的时间分解】对比了prefetch 8个mini-batch和baseline的Cache时间分解。
训练总时间从201秒下降到120秒,图中所示的Cache阶段操作时间占比也显著下降。可以看到和每个mini-batch独立进行Cache操作相比,各部分时间都减少了,尤其是Cache的前两步操作。
总结起来,Cache流水预取带来两个好处。
1、摊薄Cache索引开销
预取最显而易见的好处是减少了Step1和Step2的开销,使这个两步操作在总的训练过程占比小于 5% 。如【Cache操作的时间分解】所示,通过预取8个mini-batch数据,和没有预取的baseline相比,Cache查询的开销显著降低。
2、增加CPU-GPU数据移动带宽
通过集中更多数据,提升数据传输粒度,从而充分利用CPU-GPU传输带宽。对于上面例子,CUDA->CPU带宽从860MB/s提升到1477 MB/s,CPU->CUDA带宽从1257 MB/s提升到 2415 MB/s,几乎带来了近一倍的性能增益。
便捷使用
和Pytorch EmbeddingBag用法一致,在构建推荐模型时,仅需如下数行代码进行初始化,即可大幅提升嵌入表容纳量,低成本实现TB级超大推荐模型训练。
from colossalai.nn.parallel.layers.cache_embedding import CachedEmbeddingBag
emb_module = CachedEmbeddingBag(
num_embeddings=num_embeddings,
embedding_dim=embedding_dim,
mode="sum"