

Pandas手册自用

读取数据
1、pd.read_csv:读取csv文件或者txt
ratings = pd.read_csv(fpath)2、pd.read_csv:读取txt文件,自己指定分隔符、列名
pvuv = pd.read_csv(
fpath,
sep="\t", #设置的分隔符
header=None, #说明txt文件没有列索引,
names=['pdate', 'pv', 'uv'] #自己设置索引
)在遇到以"::"为分隔符
需要指明引擎engine = 'python'
pvuv = pd.read_csv(
fpath,
sep="::", #设置的分隔符
engine='python',
header=None, #说明txt文件没有列索引,
names=['pdate', 'pv', 'uv'] #自己设置索引
)3、pd.read_excel:读取excel
read_excel(io, sheetname=0,skiprows=None)常用参数sheetname:填入整形,从0开始选取工作表
skiprows 忽视前几行 :一般前几行有无用数据才会用到
4、pd.read_sql:读取数据库
import pymysql
conn = pymysql.connect(
host='127.0.0.1',
user='root',
password='12345678',
database='test',
charset='utf8'
mysql_page = pd.read_sql("select * from crazyant_pvuv", con=conn)
5、df.to_csv(index=False)
一般写入dataframe时要设置index=False否则自动写入一行索引
数据的常用操作(如查看缺失值信息等)
1、dataframe.head() :读取前五行
写入整形可以显示前N行
2、dataframe.shape : 去读数据的行数和列数
返回一个元组,(行数,列数)
3、dataframe.columns :获取列索引值
返回的是Index(['userId', 'movieId', 'rating', 'timestamp'], dtype='object')4、ratings.dtypes: 获取数据的格式类型
比如:字串数据用str_
userId int64
movieId int64
rating float64
timestamp int64
dtype: object5、dataframe['列名'].value_counts() :查询每个数据的次数
获取的series对象可以通过.index获取索引,用.value获取值
温差正常 187
温差大 178
Name: wencha_type, dtype: int646、dataframe.describe() :统计所有数据列的一些信息比如最大值最小值

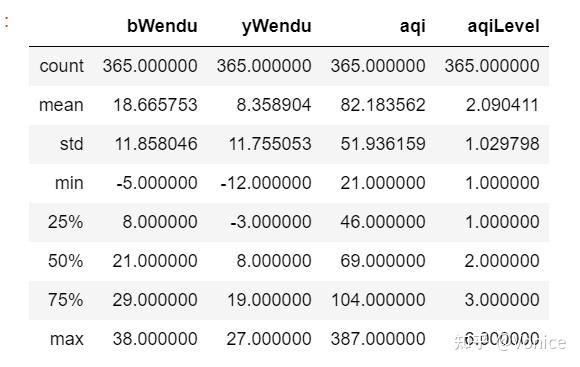
其中std是标准差
7、dataframe["列名"].mean() :查找指定列的平均数
8、dataframe['列'].max() .min: 查询最大最小
9、dataframe['列'].unique() :用于给字符串列进行分类
df["fengxiang"].unique()
array(['东北风', '北风', '西北风', '西南风', '南风', '东南风', '东风', '西风'], dtype=object)10、df.cov() :获取协方差
1. 协方差:***衡量同向反向程度***,如果协方差为正,说明X,Y同向变化,协方差越大说明同向程度越高;如果协方差为负,说明X,Y反向运动,协方差越小说明反向程度越高。

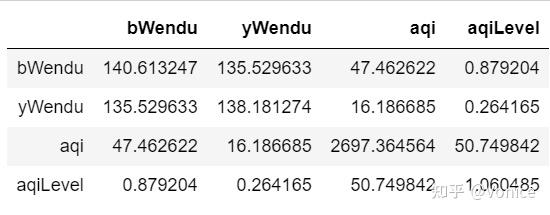
11、df.corr() 获取相关系数
相关系数:***衡量相似度程度***,当他们的相关系数为1时,说明两个变量变化时的正向相似度最大,当相关系数为-1时,说明两个变量变化的反向相似度最大

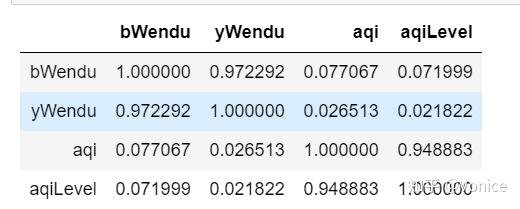
12、df["aqi"].corr(df["bWendu"]) 单独查看某两列的相关系数
创建数据结构
1、 pd.Series([数据集],index=[设置的索引],name='')
第一个参数可以传一个列表数据集
index是设置索引值,默认是0,1,2,3。。。
name是设置series的列名,在后面数据合并concat,合并列会用到
2、创建空Series
se = pd.Series(dtype='float64')3、Series的查询方法
series[索引] :用于查询某一个数据
series.values :获取所有的数据
series.index : 获取索引
4、pd.DataFrame(字典) :通过字典来创建 ,其中,字典的键会作为列的索引
data={
'state':['Ohio','Ohio','Ohio','Nevada','Nevada'],
'year':[2000,2001,2002,2001,2002],
'pop':[1.5,1.7,3.6,2.4,2.9]
df = pd.DataFrame(data)5、创建空dataframe
df_empty = pd.DataFrame(columns=['A', 'B', 'C', 'D'])6、条件查询的注意事项
df.loc[(df["bWendu"]<=30) & (df["yWendu"]>=15) & (df["tianqi"]=='晴') & (df["aqiLevel"]==1), :]如果是或 就用| 如果是且就用&
另外自己用的少的是,可以编写函数查询:
def fun(d):
return d['ymd'].str.startswith('2018-09')
data.loc[fun,:]记住 dataframe.loc[,]
如果有逗号隔开,逗号后面是要显示的列,比如我写
dataframe.loc[查询条件,'ymd']是只查ymd 返回series
如果是列表或者: 这是返回dataframe
查询方法很多,推荐用loc
其实直接用df[df[条件]] 的格式也可以查
7、按多条件查询修改!!!
def get_wendu_type(x):
if 60>= x["time_len"] >= 90:
return "潜水用户"
if x["time_len"] > 90:
return "流失用户"
else:
return "活跃用户"
user.loc[:,"type"] = user.apply(get_wendu_type,axis=1)传入df对象,然后选定df对象中修改的片段,然后return返回出来
当如果是想要增加一列,则user.loc[:, '新字段' ] = 。。。。
新增数据列
1、直接赋值法

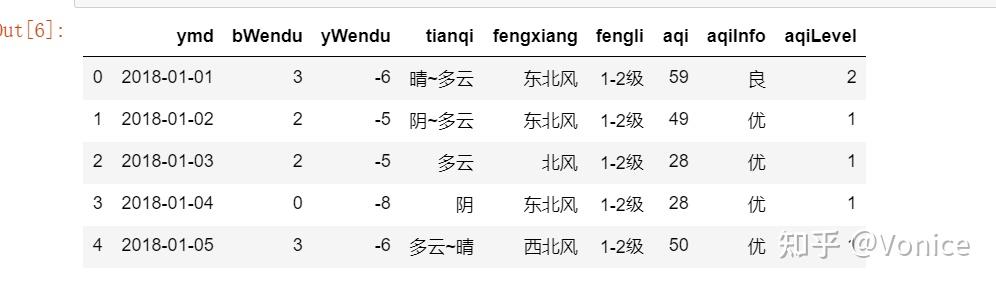
比如拿到这个数据,我想添加一列温差
通过直接赋值
df.loc[:,'wencha'] = df['bWendu']-df['yWendu'] 就会自动添加一列温差了
缺失值处理(isnull和notnull,dropna,fillna)
大纲:isnull和notnull,dropna,fillna
Pandas使用这些函数处理缺失值:
- isnull和notnull:检测是否是空值,可用于df和series
- dropna:丢弃、删除缺失值
- axis : 删除行还是列,{0 or ‘index’, 1 or ‘columns’}, default 0
- how : 如果等于any则任何值为空都删除,如果等于all则所有值都为空才删除
- inplace : 如果为True则修改当前df,否则返回新的df
- subset:指定的字段,如果有空才删
- fillna:填充空值
- value:用于填充的值,可以是单个值,或者字典(key是列名,value是值)
- method : 等于ffill使用前一个不为空的值填充forword fill;等于bfill使用后一个不为空的值填充backword fill
- axis : 按行还是列填充,{0 or ‘index’, 1 or ‘columns’}
- inplace : 如果为True则修改当前df,否则返回新的df
以下以一个案例讲解过程:

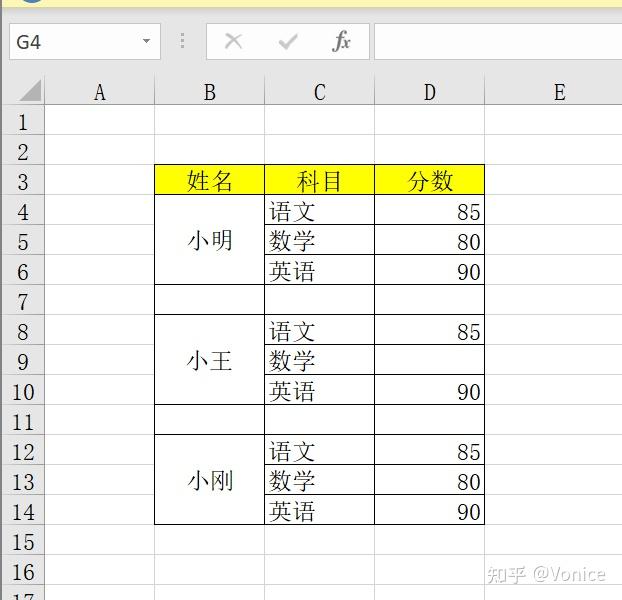
这是最开始没有处理的数据
我们把他处理成

步骤1:先找出所有空值
import pandas as pd
df = pd.read_excel(r'C:\Users\zero\Desktop\l_env\Scripts\jupyter\learnpandas\datas\student_excel\student_excel.xlsx',skiprows=2)
df
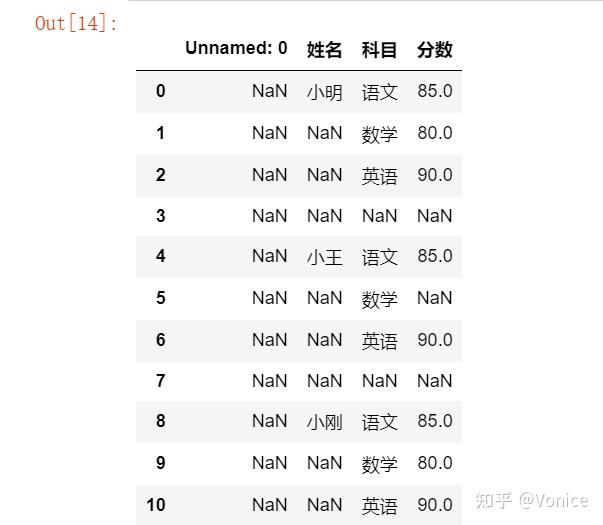
其中NaN就是空的意思
步骤2:删除空行
2.1 删除空白行
看前面大纲,axis参数是设置删除行还是列,行是0,列是1
,inplace参数是要不要在原来的数据上修改的意思
how代表删除的模式:其中用all的话,如果一整行或者一整列都是NaN,才会被删除,而如果是any,只要在某行或某列中,出现了一个NaN,就会被删除,
比如我先删除空白行 ,参数用all
df2 = df.dropna(axis=0,how='all',inplace=False)
df2 
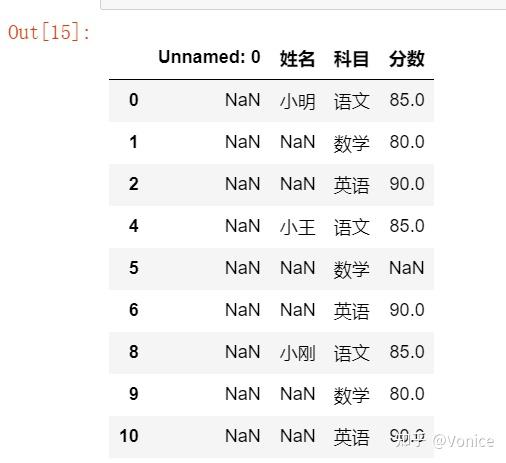
如果用any

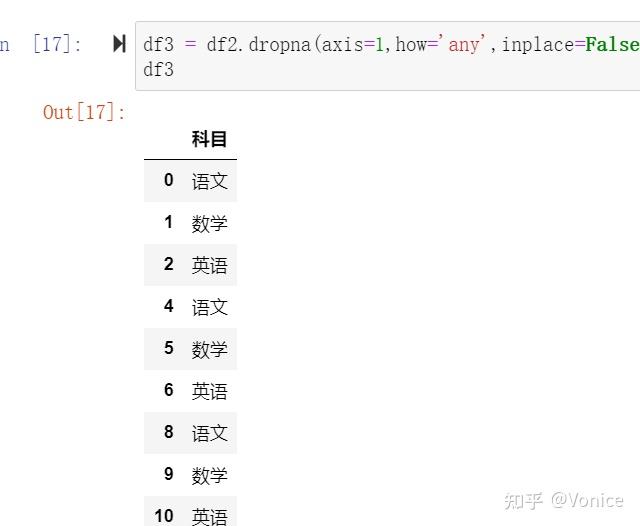
2.2 删除空白列:
df3 = df2.dropna(axis=1,how='all',inplace=False)
df3
第三步:填充数据
3.1 分数中有NaN,我希望填充0
df4 = df3.copy()
df4.loc[:,'分数'] = df4['分数'].fillna(0)
df4这里有个小问题,就是要用copy函数,不然会有一个报错
3.2 用fillna中的method参数
method参数,可以选ffill和bfill
其中ffill是指,填充的值,会按上一个值填充
而bfill是按下面一个值填充
df4.loc[:,'姓名'] = df4['姓名'].fillna(method='ffill')
df4
步骤四:
dataframe.to_excel()写入excel即可
数据排序(.sort_values(ascending=True, inplace=False))
1、Series.sort_values(ascending=True, inplace=False)
ascending如果是true,说明是升序
inplace是指是否在原数据修改
2、DataFrame.sort_values(by, ascending=True, inplace=False)
by指按排序的列
其中可以分别设置不同列的升降序
# 分别指定升序和降序
df.sort_values(by=["aqiLevel", "bWendu"], ascending=[True, False])
Merge主键的连接 merge连接用how
大纲
merge的语法:
pd.merge(left, right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=True, suffixes=('_x', '_y'), copy=True, indicator=False, validate=None)
- left,right:要merge的dataframe或者有name的Series
- how:join类型,'left', 'right', 'outer', 'inner'
- on:join的key,left和right都需要有这个key
- left_on:left的df或者series的key
- right_on:right的df或者seires的key
- left_index,right_index:使用index而不是普通的column做join
- suffixes:两个元素的后缀,如果列有重名,自动添加后缀,默认是('_x', '_y')

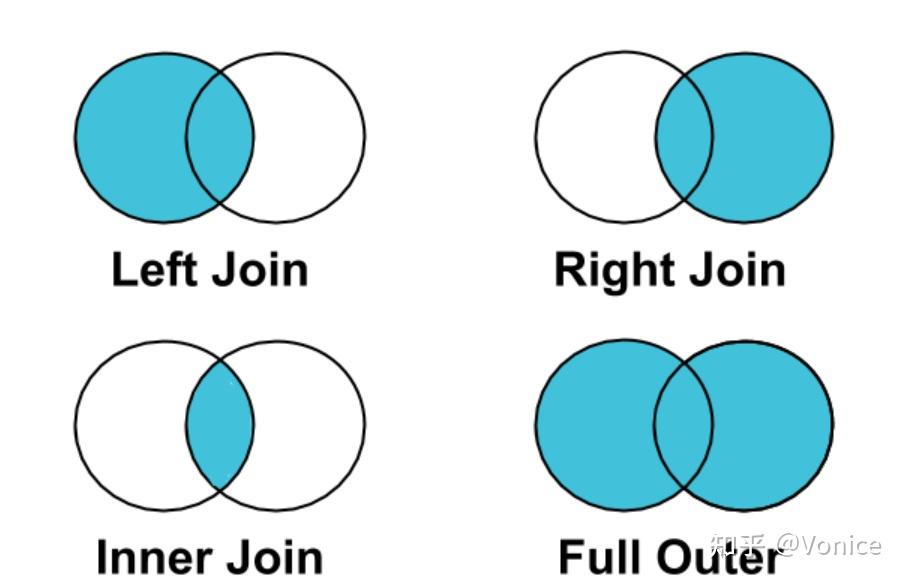
关于merge可以用来补充不连续的数据
比如对于日期,有一段日期是不连续的,需要自己创建一个连续的日期,然后去关联
数据合并 连接用join模式
pandas.concat(objs, axis=0, join='outer', ignore_index=False)
- objs:传入合并的列表,内容可以是DataFrame或者Series,可以混合
- axis:默认是0代表按行合并,如果等于1代表按列合并
- join:合并的时候索引的对齐方式,默认是outer join,也可以是inner join
- ignore_index:是否忽略掉原来的数据索引
添加行
示例:
有两个dataframe按行合并
表1

表2

这里需要说明join参数,join如果选了inner,则因为没有F列,表2没有E列,合并会自动去除这两列
concat_df1 = pd.concat([df1,df2],join='inner',axis=0,ignore_index=True)
concat_df1
如果join参数用outer

添加列
se = pd.Series(list(range(8)),name='G')
pd.concat([concat_df2,se],axis=1,join='outer',ignore_index=True)
关键是理解axis的参数
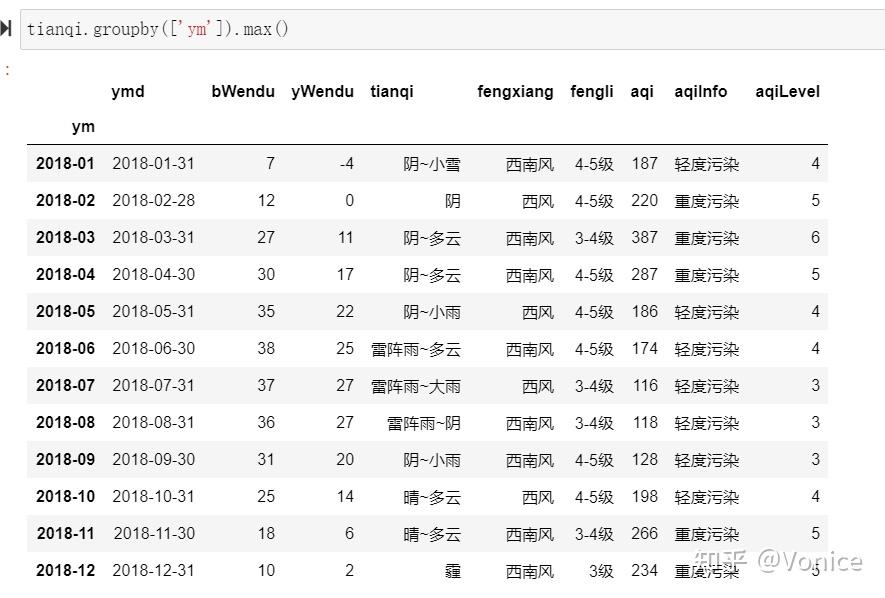
数据分组聚合 df.groupby()
比如根据月份,找出每月bWendu的最大值等

最简单用法:
tianqi.groupby(['ym']).max()根据'ym'列的指,算出每一个数据列的最大值、

其中groupby可以传入列表,会变成二维分组






分层索引
【 重要知识 】在选择数据时:
元组(key1,key2)代表筛选多层索引,其中key1是索引第一级,key2是第二级,比如key1=JD, key2=2019-10-02
列表[key1,key2]代表同一层的多个KEY,其中key1和key2是并列的同级索引,比如key1=JD, key2=BIDU


记住,()是分级,【】是同级
slice(None)是指把同一级所有所有合并
重复值
df.drop_duplicated(subset=None,keep=“first”,inplace=False)
subset:指明需要去重的列名,默认识别所有列
keep:有first,last两个取值 ,分别代表保留哪一个
日期格式的处理
pd.to_datetime(obj)
一般配合df,loc[:,''] = pd.to_datetime()来使用,修改某列为日期结构
当用to_datetime处理后
可以通过以下几个参数获取日期的其他信息

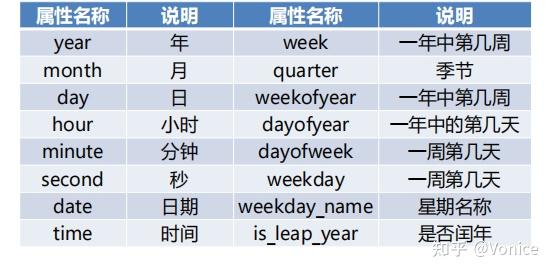
其中,现在weekday_name 使用会报错,需要用day_name() 要加括号
另外当用to_datetime处理后,还可以做时间差的计算
直接相减即可
new = Ruser['recently_logged'] - Ruser['register_time']
0 0 days 00:00:00
1 0 days 00:01:00
2 0 days 00:00:00
3 0 days 00:00:00
4 0 days 00:34:00