


刷新图像分割新记录!OneFormer:规则通用图像分割的Transformer

一句话总结
刷新ADE20K全景/实例分割新记录!本文提出OneFormer:一个新的多任务通用图像分割框架,以统一语义、实例和全景分割,性能优于Mask2Former、UPerNet等网络,代码刚刚开源!
点击关注 @CVer计算机视觉 ,第一时间看到最优质、最前沿的CV、AI工作~
点击进入—> 图像分割和Transformer微信技术交流群
OneFormer
OneFormer: One Transformer to Rule Universal Image Segmentation


单位:俄勒冈大学, UIUC, IIT, PAIR
主页: https:// praeclarumjj3.github.io /oneformer/
代码: https:// github.com/SHI-Labs/One Former
论文: https:// arxiv.org/abs/2211.0622 0
主要贡献


通用图像分割并不是一个新概念。过去几十年中统一图像分割的尝试包括场景句法分析、全景分割,以及最近的新全景架构。然而,这样的全景架构并没有真正统一图像分割,因为它们需要在语义、实例或全景分割上单独训练以达到最佳性能。理想情况下,一个真正通用的框架应该只训练一次,并在所有三个图像分割任务中实现SOTA性能。
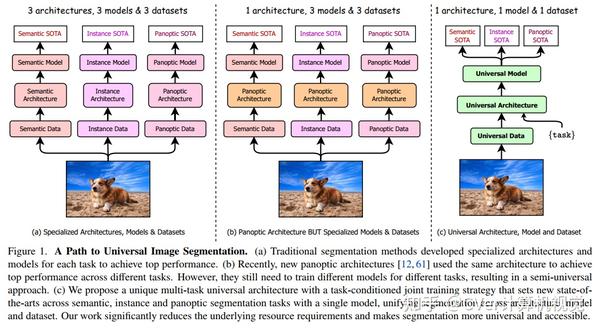
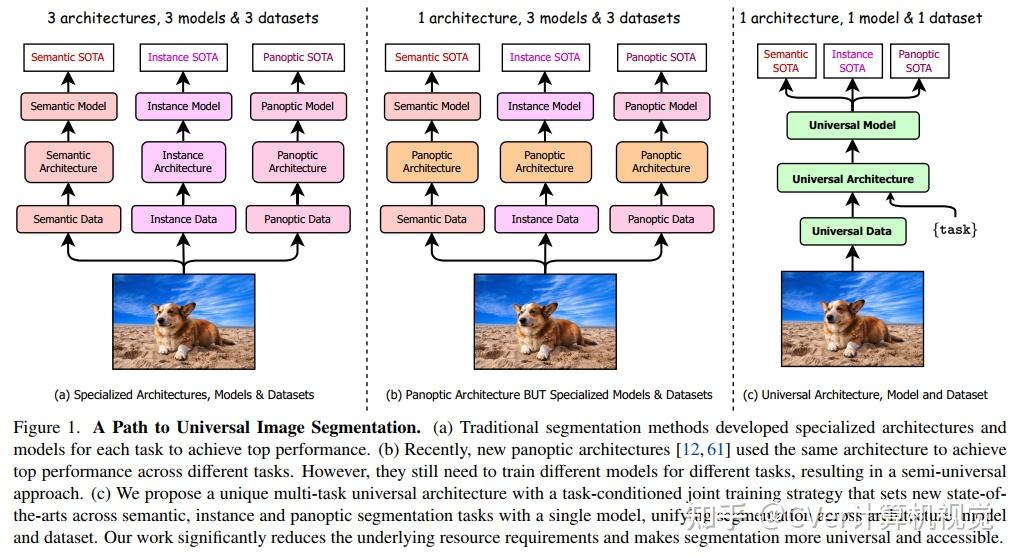
为此,我们提出了OneFormer,我们首先提出了一种任务条件联合训练策略,该策略允许在单个多任务训练过程中对每个领域的ground truths(语义、实例和全景分割)进行训练。
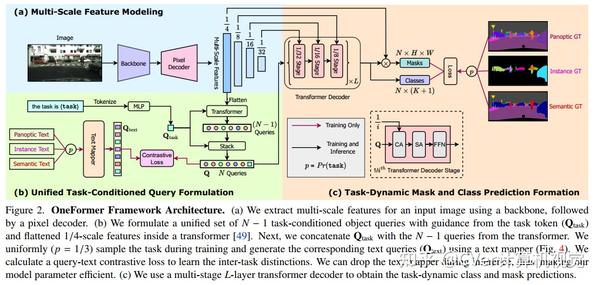
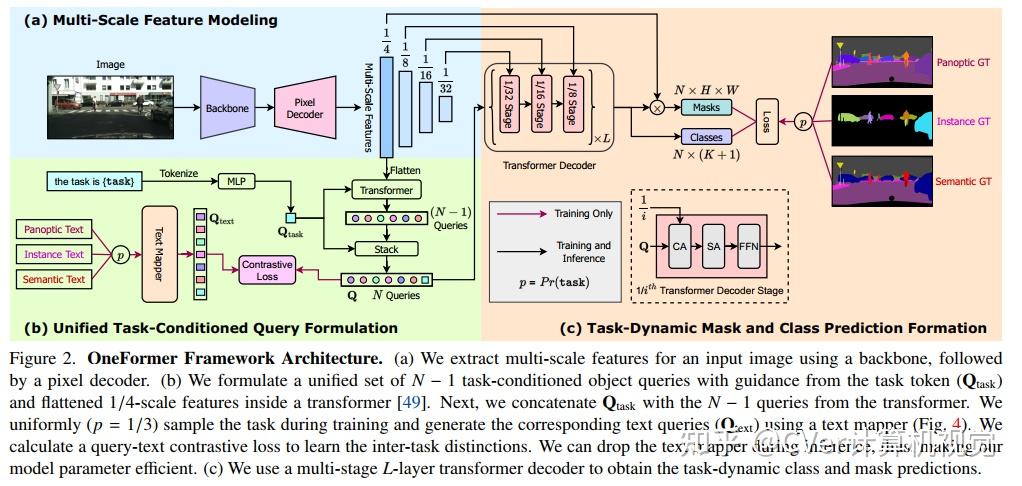
其次,我们引入了一个任务token,以手头的任务为条件来约束我们的模型,使我们的模型任务动态,以支持多任务训练和推理。
第三,我们提出在训练期间使用查询-文本对比损失来建立更好的任务间和类间区别。
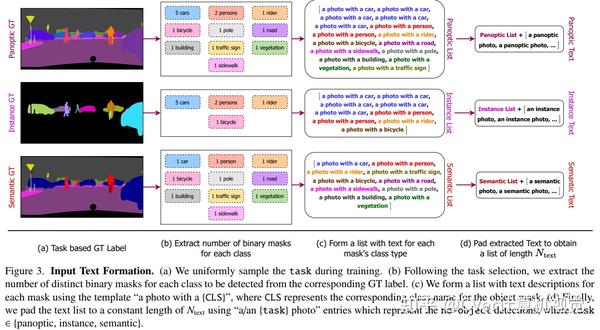
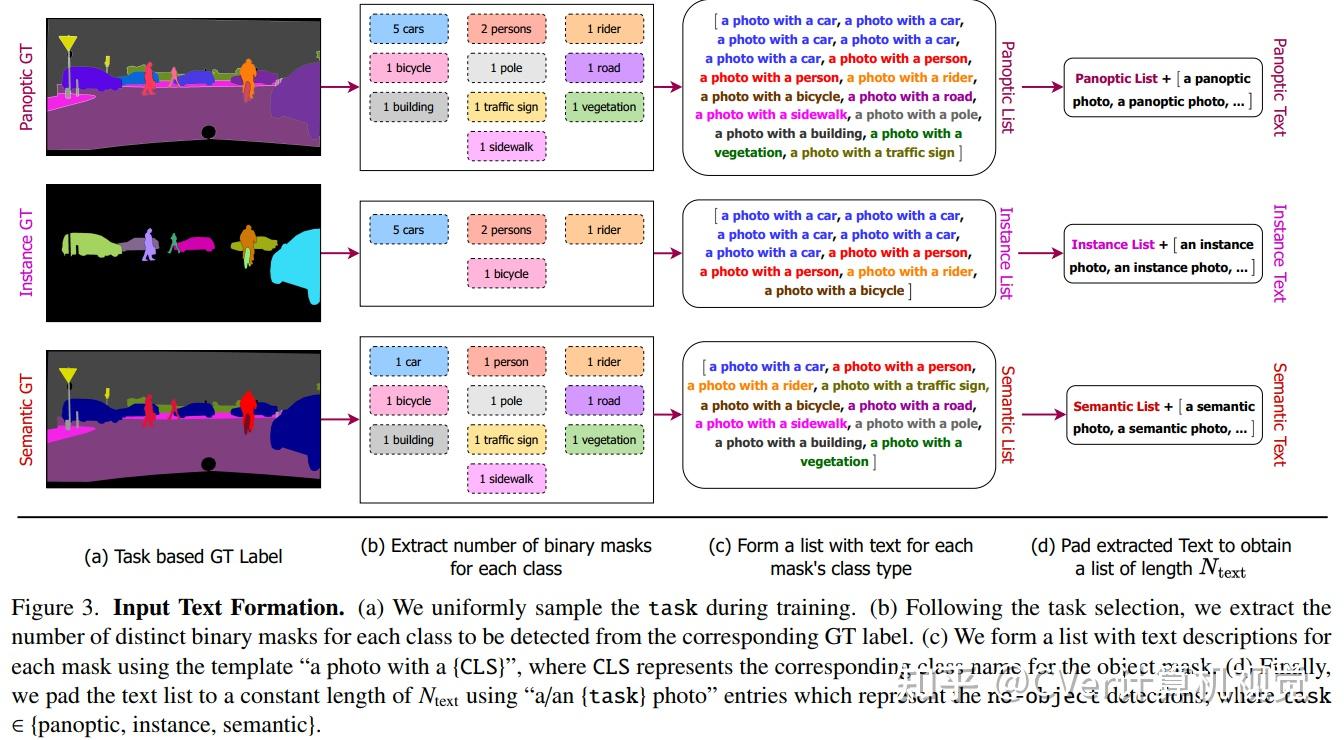
实验结果
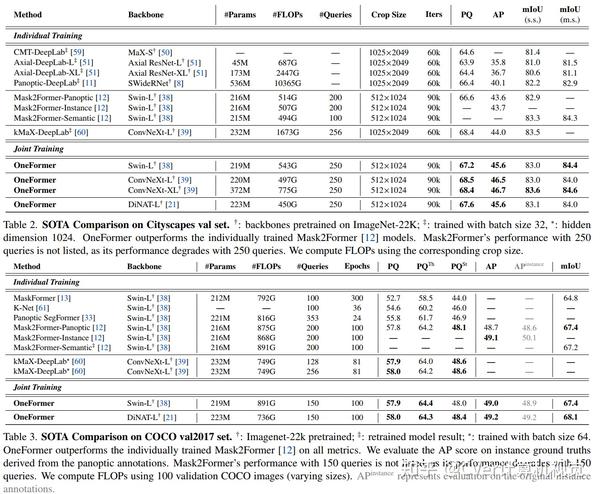
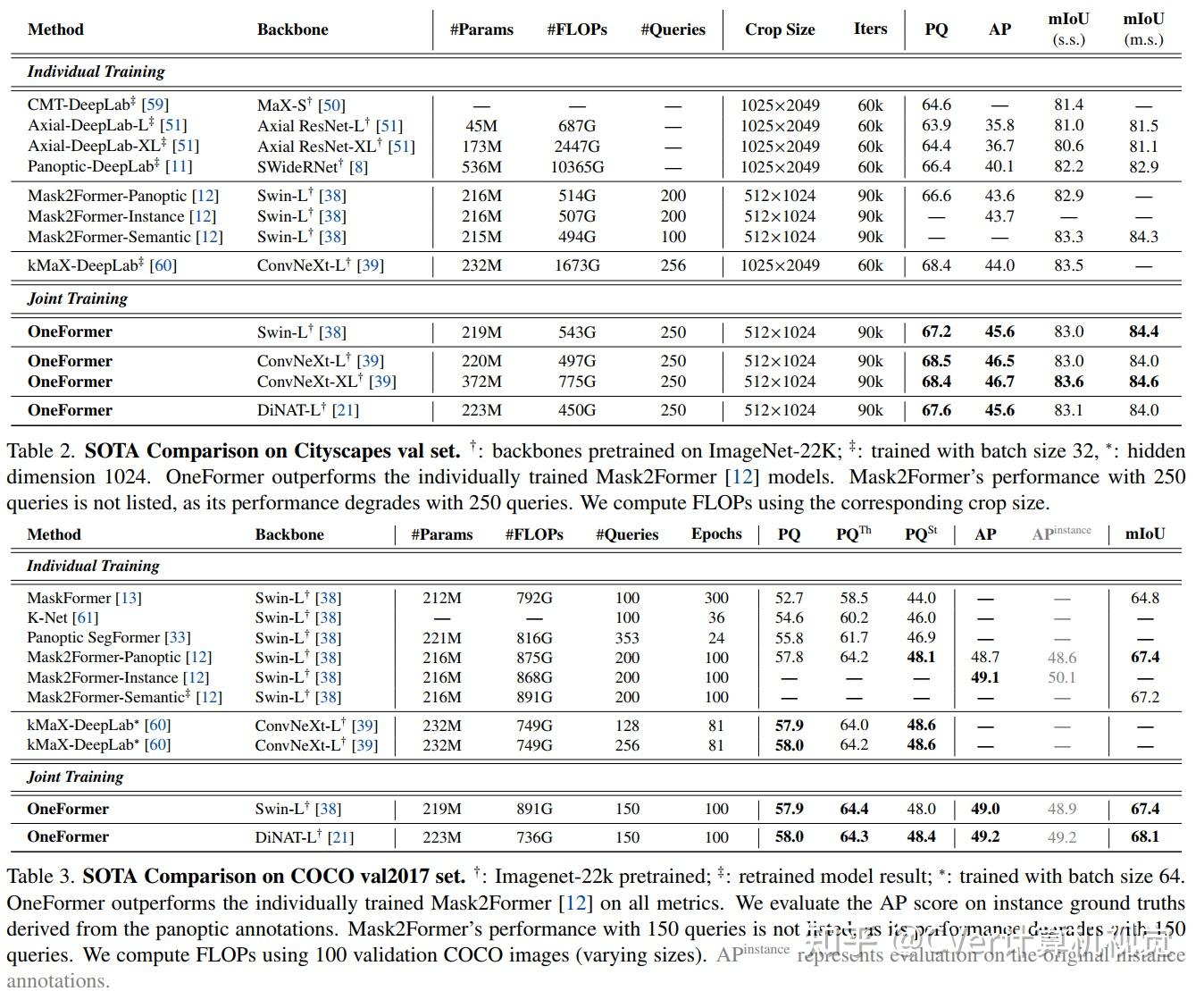
值得注意的是,我们的单一OneFormer模型在 ADE20k, CityScapes, and COCO上的所有三个分割任务中都优于专门的Mask2Former模型,尽管后者以三倍的资源分别针对三个任务中的每一个进行训练。使用新的ConvNeXt和DiNAT主干,我们观察到更多的性能改进。我们相信OneFormer是朝着使图像分割更加普遍和可访问迈出的重要一步。
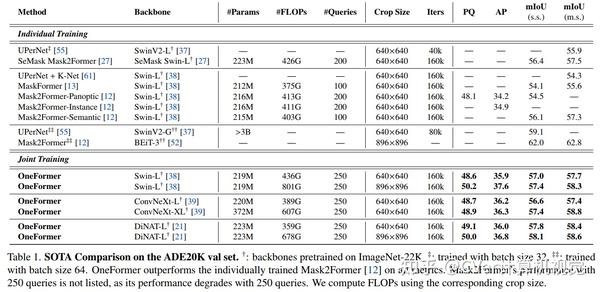
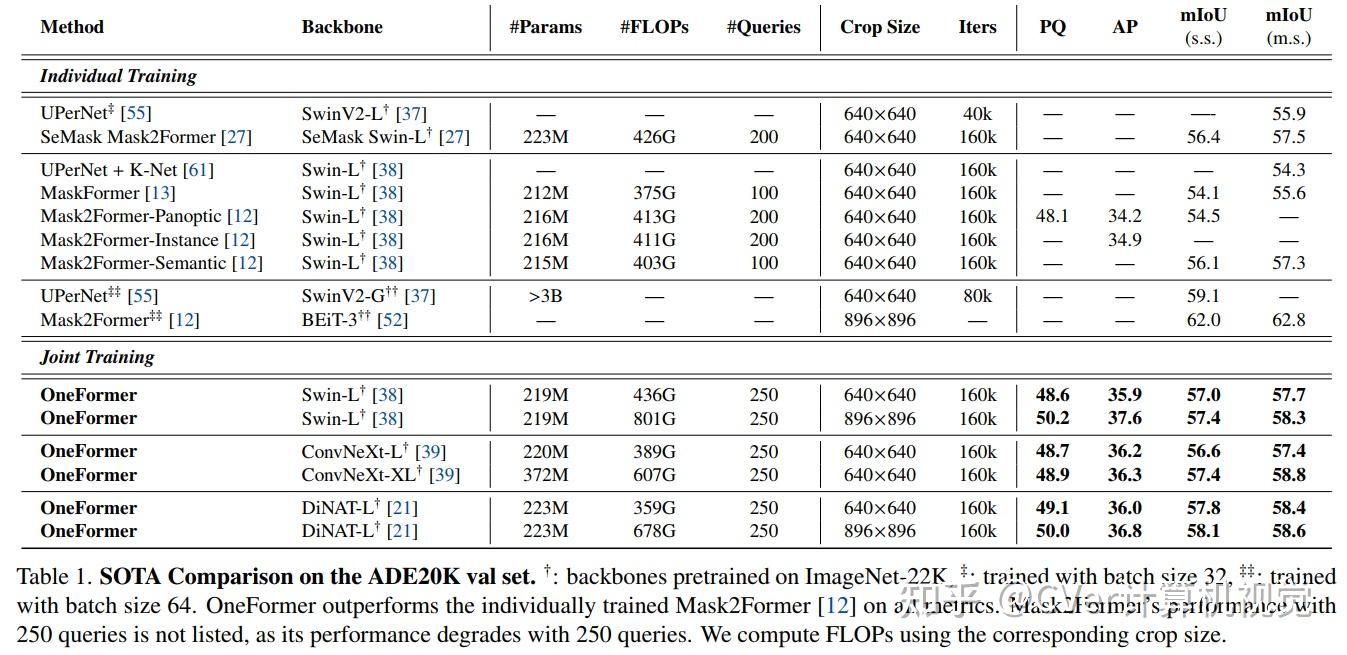




点击进入—> 图像分割和Transformer微信技术交流群
CVer-Transformer交流群
建了CVer-Transformer交流群!想要进Transformer学习交流群的同学,可以直接加微信号: CVer222 。加的时候备注一下: Transformer+学校/公司+昵称+知乎 ,即可。然后就可以拉你进群了。
CVer-图像分割交流群
建了CVer-图像分割交流群!想要进图像分割学习交流群的同学,可以直接加微信号: CVer222 。加的时候备注一下: 图像分割+学校/公司+昵称+知乎 ,即可。然后就可以拉你进群了。
推荐阅读
65.4 AP刷新COCO目标检测新记录!InternImage:探索具有可变形卷积的大规模视觉基础模型
64.5 AP!Group DETR v2:编-解码器预训练的强大目标检测器
NeurIPS 2022 | 香港理工提出OGC:首个无监督3D点云物体实例分割算法
Sea和北大提出新优化器Adan:深度模型都能用!训练ViT和MAE减少一半计算量!
NVIDIA提出eDiffi:具有专家去噪器的文本到图像扩散模型
CVer计算机视觉:ECCV 2022 | 北大提出PTQ4ViT:双统一量化的视觉Transformer的训练后量
CVer计算机视觉:UNET-2022 医学图像分割新网络!探索非同构架构中的动
BMVC 2022 | 如何在小规模数据集上训练视觉Transformer?
NeurIPS 2022 | 清华&南开提出SegNeXt:重新思考语义分割的卷积注意力设计
NeurIPS 2022 | 北大&阿里提出BEVFusion:一个简单而强大的激光雷达-相机融合框架
YOLOv4团队打造YOLOv7!最先进的实时目标检测网络来了!
COCO上高达62.4 AP!GLIPv2来了!统一定位和视觉-语言理解
