

自定义的pytorch模型如何导出为onnx?
关注者
17
被浏览
22,050
登录后你可以
不限量看优质回答
私信答主深度交流
精彩内容一键收藏

Pytorch导出ONNX
在工程部署中,基本不会采用ONNX自带的API去搭建网络,通常都是采用其他深度网络学习框架训练模型,然后将训练好的模型直接导出成ONNX模型,这里以Pytorch为例(其它框架大同小异),将Pytorch训练好的模型直接导出成ONNX模型。
采用Pytorch导出ONNX模型只需要调用一个函数,这里用Pytorch任意的搭建了一个网络,并调用相关接口将模型导出。
import torch
import torch.nn as nn
import numpy as np
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, stride=2, padding=1)
self.conv2 = nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1)
self.bn1 = nn.BatchNorm2d(16)
self.bn2 = nn.BatchNorm2d(32)
self.relu1 = nn.ReLU(inplace=True)
self.relu2 = nn.ReLU(inplace=True)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu1(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.relu2(x)
return x
model=Model()
model.eval()
x=torch.randn((1,3,12,12))
torch.onnx.export(model, # 搭建的网络
x, # 输入张量
'model.onnx', # 输出模型名称
input_names=["input"], # 输入命名
output_names=["output"], # 输出命名
dynamic_axes={'input':{0:'batch'}, 'output':{0:'batch'}} # 动态轴
)关注代码中的最后一段torch.onnx.export(),这里的第一个参数model表示搭建的网络。x表示输入的张量,如果不设置动态轴,输入的尺寸将被固化下来作为图的一部分,在做推理时输入的尺寸将和导出时采用的张量尺寸一致,也就是说整个模型输入尺寸是定长的。动态轴的设置可以实现模型的变长输入,很多情况下,为了提升计算的效率,可以将数据进行拼接后送入网络,但是拼接的batch值是不知道的,可以用dynamic_axes的参数进行设置,达到动态设置batch的目的。在图像处理领域,往往输入图片的尺寸不是固定大小的,采用动态轴的方式,可以实现尺寸的变长输入。
除了示例中的参数,还可以设置一些参数对导出的模型做一些优化,如设置do_constant_folding参数进行常量折叠,设置verbose参数进行调试信息的打印,设置opset_version参数进行导出opset的版本。
模型导出注意事项
Pytorch模型在执行时是动态推导的,在运行之前并不知道整个推理的流程,ONNX模型是静态的,在推理时整个图已经构建完成。动态的模型是数据边走边计算,静态的模型是在推理时先构建了一个图,然后数据从输入节点开始,按照拓扑关系一直流向输出节点。这就导致在采用jit.trace(jit.script模式不讨论)方法进行模型导出时,遇到分支语句,Pytorch只会记录走过的路径,其他的路径将会直接被丢弃,遇到while循环语句,Pytorch只会记录当前转模型的固定循环次数。换句话说,如果构成网络结构的某个循环次数是依赖与输入变量的,则循环的次数不可预期。比如RNN网络,输入序列是不一样的,在解码的过程中,不知道要经过多少次循环,这时只能将RNN拆成一个个的小的单元,在外部根据实际情况对单元模块进行循环调用。】
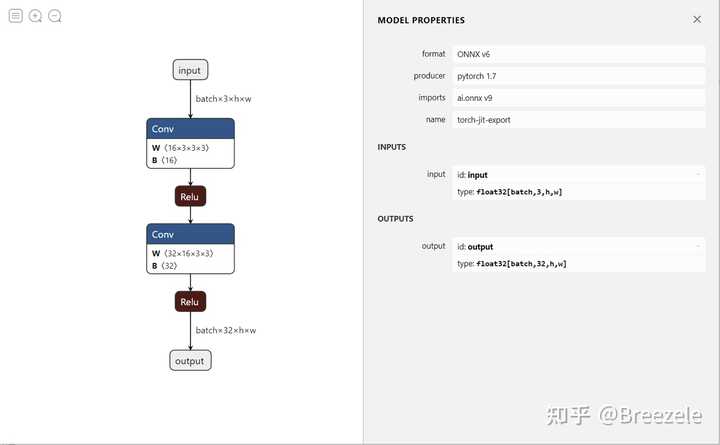
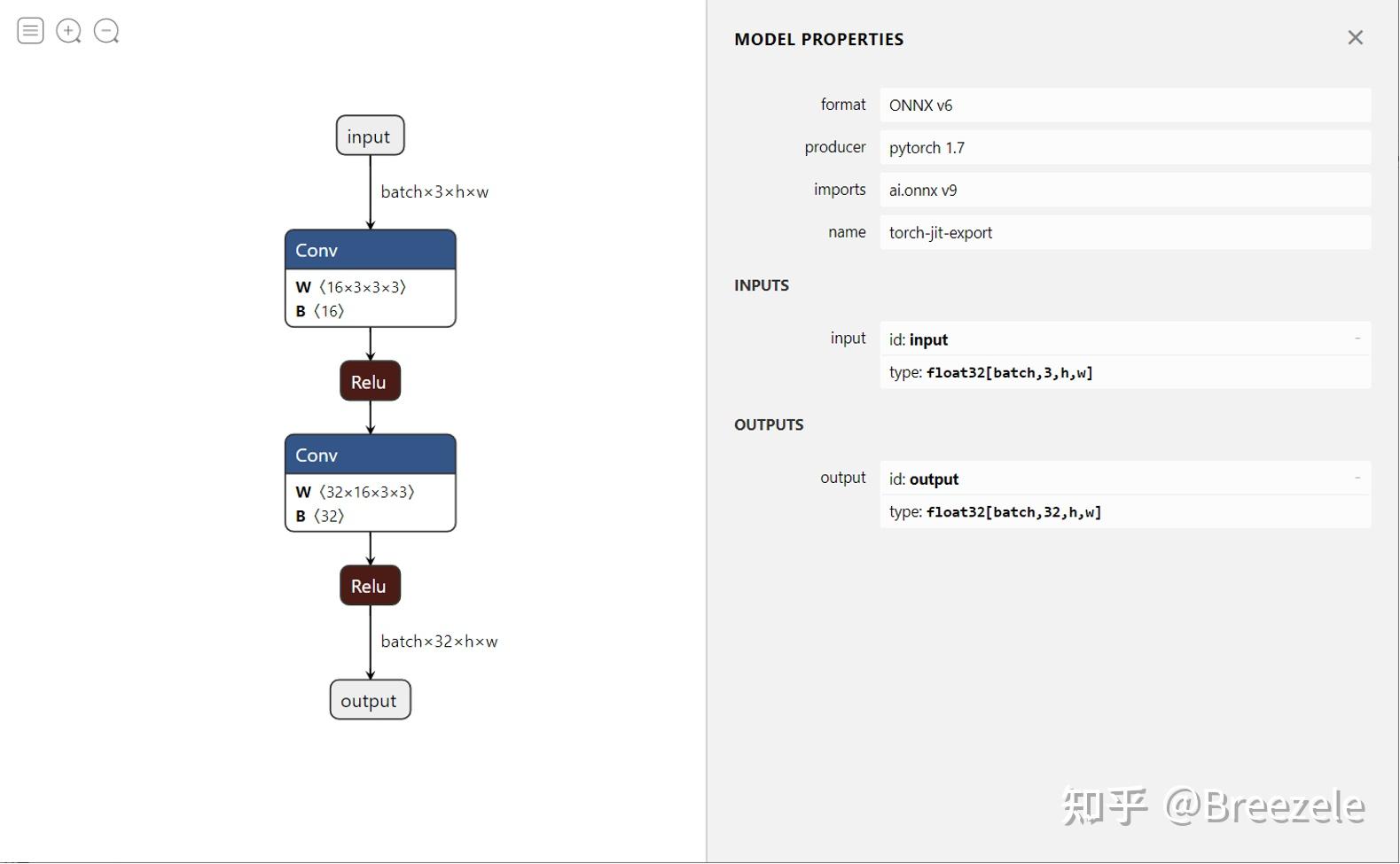
自定义OP
通过Netron打开导出的模型,可以看到整个模型由两个CBR(Conv->Bn->Relu)结构拼接而成。值得注意的是,Conv算子和Bn算子作为一个整体合并到了一起,这是Pytorch在导出模型时做的自动优化。在右侧的属性面板,输入中的batch数和长宽都是可变的。
在工程实践中,有时候需要应用部署的卷积网络模型全部都是由上述的CBR的单元构成,针对这三个算子进行定制优化会使得模型推理的效率有明显的提升。在底层,可以将三个算子的算法用一个算子实现,并且命名成一个新的算子类型。在前端构建图时,可以采用如下的方法去自定义一个算子:
import torch
import torch.nn as nn
import numpy as np
class _Cbr(torch.autograd.Function):
@staticmethod
def forward(self, input):
return input
@staticmethod
def symbolic(g, input):
return g.op("onnx_test::cbr", *[input], **{})
def Cbr(input):
return _Cbr.apply(input)
class Model(nn.Module):
def __init__(self):
super(Model,self).__init__()
def forward(self, x):
x = Cbr(x)
x = Cbr(x)
return x
model=Model()
model.eval()
x=torch.randn((1,3,12,12))
torch.onnx.export(model,