


【Protobuf专题】(三)Protobuf的数据类型解析及使用总结


0 前言
Protobuf(Protocol Buffer)是Google出品的一种轻量且高效的结构化数据存储格式,性能比Json、XML更强,被广泛应用于数据传输中。然Protobuf中的数据类型众多,什么场景应用什么数据类型最合理、最省空间,成为了每个使用者该考虑的问题。为了能更充分的理解和使用Protobuf,本文将聚焦Protobuf的基本数据类型,分析其不同数据类型的使用场景和注意事项。
注意:在阅读本文之前最好对Protobuf的语法和序列化原理有一定的了解。
推荐文献:
[1] 序列化:这是一份很有诚意的 Protocol Buffer 语法详解
[2] Protocol Buffer 序列化原理大揭秘 - 为什么Protocol Buffer性能这么好?
1 基本数据类型的范围
数据类型的数值范围:


java中:


浮点数范围
-
Float(32bit) = 1bit(符号位)+ 8bits(指数位)+ 23bits(尾数位)
指数位的范围为-2^128 ~ +2^128
尾数位的范围为2^23 = 8388608,一共七位,这意味着最多能有7位有效数字,但绝对能保证的为6位,也即float的精度为6~7位有效数字; -
Double(64bit)= 1bit(符号位)+ 11bits(指数位)+ 52bits(尾数位)
指数位的范围为-2^1024 ~ +2^1024
尾数位的范围为2^52 = 4503599627370496,一共16位,同理,double的精度为15~16位。
浮点数的存储方式详见: 浮点类型(float、double)在内存中如何存储?
如果对二进制等基本概念不熟悉可以看看:
2 Protobuf的数据类型
Protobuf的基本数据类型与JAVA的数据类型映射关系表如下:
映射表来源于Protobuf官网, Language Guide (proto3)
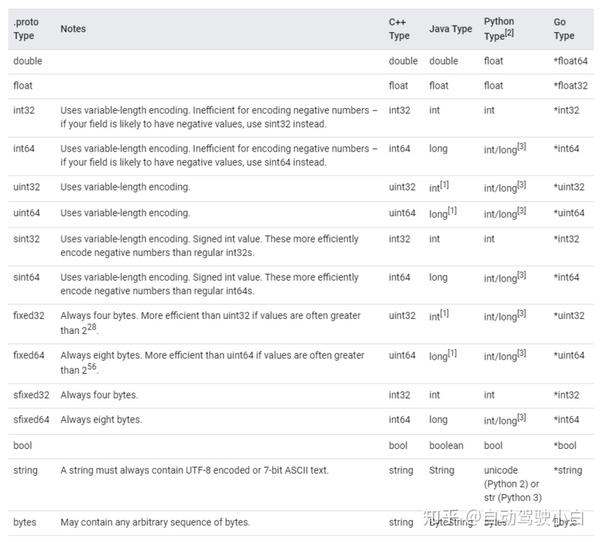
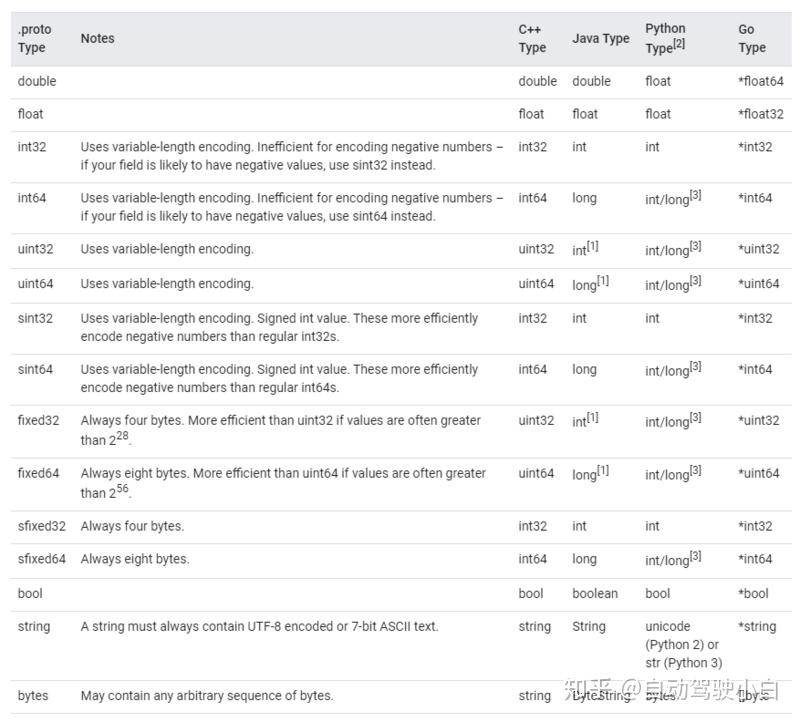
注意到JAVA中没有区分无符整型和有符整型,Protobuf的int和uint统一映射到JAVA的int/long数据类型。
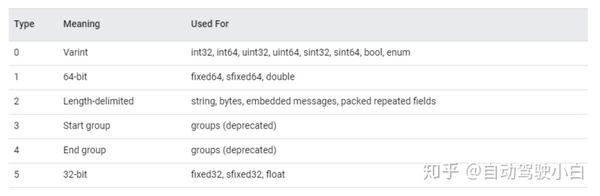
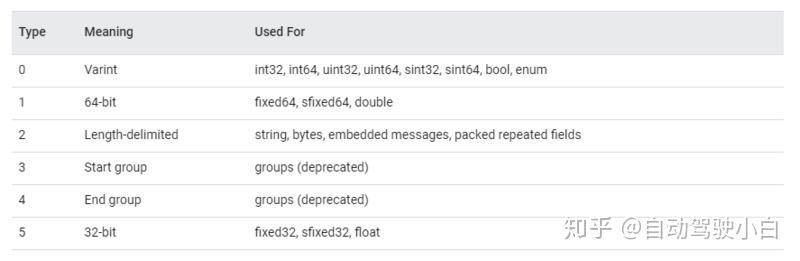
Protobuf数据类型的序列化方法粗略可以分为两种,一种是可变长编码(如Varint),Protobuf会合理分配空间存储数据,在保证不损失精度的情况下用尽量小的空间节省内存(比如整数1,若数据定义的类型为int32,本来需要8个字节表达的,Protobuf只需要一个字节表达。注意,Protobuf只能节省到字节的单位(8个字节省到1个字节),而不能节省到位的单位(1个字节内还可以进一步省二进制位),这个后续开专题再聊);另一种是固定长度编码(如64-bit、32-bit),数据定义的什么类型就占用多大空间,不管是否有浪费;其实,还有一种比较特别的方法(Length-delimited),这种方法主要针对类似于数组的数据,添加了一个字段记录数组的长度,然后将数组内容顺序组合,详细原理不在赘述,可见前文推荐的文献。
3 数据实验
为验证Protobuf各数据类型的序列化效果,遂设计以下数据实验。
1、首先,自定义了proto文件,使其中包含基本数据类型,并将proto生成java类(如何基于IDEA一站式编辑及编译proto文件,详见上一篇专题文章:
proto文件内容如下:
// Google Protocol Buffers Version 3.
syntax = "proto3";
option java_package = "learnProto.selfTest";
option java_outer_classname = "MyTest";
import "google/protobuf/timestamp.proto";
message Data{
uint32 uint32 = 1;
uint64 uint64 = 2;
int32 int32 = 3;
int64 int64 = 4;
sint32 sint32 = 5;
sint64 sint64 = 6;
fixed32 fixed32 = 7;
fixed64 fixed64 = 8;
bool bool=9;
string str = 10;
float float=11;
double double=12;
google.protobuf.Timestamp time = 13;
}
2、其次,分别对每个数据类进行赋不同的值并序列化,观察不同数据序列化后占用的字节数。
3、最后,总结归纳,形成使用建议。
3.1 整数型数据实验
测试代码如下:
public class demoTest {
public void convertUint32(int value) {
//1.通过build创建消息构造器
MyTest.Data.Builder dataBuilder = MyTest.Data.newBuilder();
//2.设置字段值
dataBuilder.setUint32(value);
//3.通过消息构造器构造消息对象
MyTest.Data data = dataBuilder.build();
//4.序列化
byte[] bytes = data.toByteArray();
System.out.println(value+"序列化后的数据:" + Arrays.toString(bytes)+",字节个数:"+bytes.length);
... // 此处省略其他数据类型的convert方法,如convertInt32与convertUint32方法代码类似,只需要修改set方法即可。
@Test
public void test32(){
System.out.println("=================uint32================");
convertUint32(1);
convertUint32(1000);
convertUint32(Integer.MAX_VALUE);
convertUint32(-1);
convertUint32(-1000);
convertUint32(Integer.MIN_VALUE);
System.out.println("=================int32================");
convertInt32(1);
convertInt32(1000);
convertInt32(2147483647);
convertInt32(-1);
convertInt32(-1000);
convertInt32(-2147483648);
System.out.println("=================sint32================");
convertSint32(1);
convertSint32(1000);
convertSint32(2147483647);
convertSint32(-1);
convertSint32(-1000);
convertSint32(-2147483648);
System.out.println("=================fix32================");
convertFixed32(1);
convertFixed32(1000);
convertFixed32(2147483647);
convertFixed32(-1);
convertFixed32(-1000);
convertFixed32(-2147483648);
}运行结果如下:
=================uint32================
1序列化后的数据:[8, 1],字节个数:2
1000序列化后的数据:[8, -24, 7],字节个数:3
2147483647序列化后的数据:[8, -1, -1, -1, -1, 7],字节个数:6
-1序列化后的数据:[8, -1, -1, -1, -1, 15],字节个数:6
-1000序列化后的数据:[8, -104, -8, -1, -1, 15],字节个数:6
-2147483648序列化后的数据:[8, -128, -128, -128, -128, 8],字节个数:6
=================int32================
1序列化后的数据:[24, 1],字节个数:2
1000序列化后的数据:[24, -24, 7],字节个数:3
2147483647序列化后的数据:[24, -1, -1, -1, -1, 7],字节个数:6
-1序列化后的数据:[24, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1],字节个数:11
-1000序列化后的数据:[24, -104, -8, -1, -1, -1, -1, -1, -1, -1, 1],字节个数:11
-2147483648序列化后的数据:[24, -128, -128, -128, -128, -8, -1, -1, -1, -1, 1],字节个数:11
=================sint32================
1序列化后的数据:[40, 2],字节个数:2
1000序列化后的数据:[40, -48, 15],字节个数:3
2147483647序列化后的数据:[40, -2, -1, -1, -1, 15],字节个数:6
-1序列化后的数据:[40, 1],字节个数:2
-1000序列化后的数据:[40, -49, 15],字节个数:3
-2147483648序列化后的数据:[40, -1, -1, -1, -1, 15],字节个数:6
=================fix32================
1序列化后的数据:[61, 1, 0, 0, 0],字节个数:5
1000序列化后的数据:[61, -24, 3, 0, 0],字节个数:5
2147483647序列化后的数据:[61, -1, -1, -1, 127],字节个数:5
-1序列化后的数据:[61, -1, -1, -1, -1],字节个数:5
-1000序列化后的数据:[61, 24, -4, -1, -1],字节个数:5
-2147483648序列化后的数据:[61, 0, 0, 0, -128],字节个数:5
【小结】
1、
uint32类型
:数值范围等价于int32的范围(可以存负数,因为proto没有对负数进行判断及限制)。
正数最多占用5个字节,负数必占用5个字节。
(第一个字节存储的是数据类型和字段在proto中的编号,即原理篇里讲的tag。之所以32位的数据最多要用5个字节来存储,是因为每个字节的最高位需要记录该数据是否衍生到下个字节(为实现可变长存储),1表示衍生,0表示不衍生。所以每个字节的实际存储数据的位数为7,则4*7<32,因此需要5个字节)
2、 int32类型:存正数时最多需要5个字节,存负数时必定需要10个字节。 (因为存负数时,32位被扩展成了64位,具体原因暂时不明,知道的朋友请赐教)
3、 sint32类型 :存数据时引入zigzag编码(Zigzag(n) = (n << 1) ^ (n >> 31), n 为 sint32 时,去掉了符号转为正数),目的是解决负数太占空间的问题。 正负数最多占用5个字节,内存高效 。
4、 fixed32类型 :固定使用4个字节, 即正负数必定占用4个字节 。因为抛弃了可变长存储的策略。 适合用于存储数据大值占比多的字段 。
64位的规律与32类似,不再赘述。
3.2 字符串类型数据实验
测试代码如下:
@Test
public void testStr() {
System.out.println("=================string================");
convertStr("");
convertStr("a");
convertStr("abc");
convertStr("啊");
convertStr("啊啊");
}运行结果如下:
=================string================
序列化后的数据:[],字节个数:0
a序列化后的数据:[82, 1, 97],字节个数:3
abc序列化后的数据:[82, 3, 97, 98, 99],字节个数:5
啊序列化后的数据:[82, 3, -27, -107, -118],字节个数:5
啊啊序列化后的数据:[82, 6, -27, -107, -118, -27, -107, -118],字节个数:8
【小结】
string类型
:proto3中字符串默认为值为空字符串,序列化后不占用内存空间;单个英文字符占1个字节,单个中文字符占3个字节(proto采用utf-8编码)。
3.3 布尔值类型数据实验
测试代码如下:
@Test
public void testbool() {
System.out.println("=================bool================");
convertBool(false);
convertBool(true);
}运行结果如下:
=================bool================
false序列化后的数据:[],字节个数:0
true序列化后的数据:[72, 1],字节个数:2
【小结】
bool类型
:proto3中布尔值默认为值为fasle,因此当值为false时,序列化后不占用内存空间;当布尔值为true时,占用1个字节。
3.4 浮点型数据实验
浮点型数据都采用的定长编码,其本身没有测试的必要,但在实际应用中,很多浮点型数据(比如经纬度坐标)其实可以转化为一定精度的整数的(允许一定的精度损失),在该场景下,是使用整数型好还是继续使用浮点型好呢?
测试代码如下:
public void convertAndValiddInt(long value) { //test中其他类似方法定义与其相似,只需要改变set和get方法
//1.通过build创建消息构造器
MyTest.Data.Builder dataBuilder = MyTest.Data.newBuilder();
//2.设置字段值
dataBuilder.setInt64(value);
//3.通过消息构造器构造消息对象
MyTest.Data data = dataBuilder.build();
//4.序列化
byte[] bytes = data.toByteArray();
System.out.println(value+"序列化后的数据:" + Arrays.toString(bytes)+",字节个数:"+bytes.length);
//5.反序列化
try {
MyTest.Data parseFrom = MyTest.Data.parseFrom(bytes);
System.out.println("反序列化后的数据="+parseFrom.getInt64());
} catch (InvalidProtocolBufferException e) {
e.printStackTrace();
@Test
public void test(){
System.out.println("================若保留7位小数(精确到厘米)===============");
System.out.println("--> 转为整数,用int64编码:");
convertAndValiddInt(1700000001);
System.out.println("--> 仍用小数,用float编码:");
convertAndValiddFloat(170.0000001f);
System.out.println("--> 仍用小数,用double编码:");
convertAndValiddDouble(170.0000001);
System.out.println("================若保留8位小数(精确到毫米)===============");
System.out.println("--> 转为整数,用int64编码:");
convertAndValiddInt(Long.valueOf("17000000001"));
System.out.println("--> 仍用小数,用float编码:");
convertAndValiddFloat(170.00000001f);
System.out.println("--> 仍用小数,用double编码:");
convertAndValiddDouble(170.00000001);
}运行结果如下:
================若保留7位小数(精确到厘米)===============
--> 转为整数,用int64编码:
1700000001序列化后的数据:[32, -127, -30, -49, -86, 6],字节个数:6
反序列化后的数据=1700000001
--> 仍用小数,用float编码:
170.0序列化后的数据:[93, 0, 0, 42, 67],字节个数:5
反序列化后的数据=170.0
--> 仍用小数,用double编码:
170.0000001序列化后的数据:[97, -27, -81, 53, 0, 0, 64, 101, 64],字节个数:9
反序列化后的数据=170.0000001
================若保留8位小数(精确到毫米)===============
--> 转为整数,用int64编码:
17000000001序列化后的数据:[32, -127, -44, -99, -86, 63],字节个数:6
反序列化后的数据=17000000001
--> 仍用小数,用float编码:
170.0序列化后的数据:[93, 0, 0, 42, 67],字节个数:5
反序列化后的数据=170.0
--> 仍用小数,用double编码:
170.00000001序列化后的数据:[97, 100, 94, 5, 0, 0, 64, 101, 64],字节个数:9
反序列化后的数据=170.00000001
【小结】
1、Float表达经纬度有损失(至少保留7位小数的情况下)。
2、
对于经纬度等浮点数,将其转为整型数据,用int64编码更省空间。
3.5 时间戳数据实验
很多场景会用到时间戳,选用什么类型呢?
测试代码如下:
@Test
public void testTime(){
System.out.println("================测试时间戳(精确到秒)===============");
System.out.println("--> 用int64编码:");
convertInt64(Long.valueOf("1600229610283"));
System.out.println("--> 用uint64编码:");
convertUint64(Long.valueOf("1600229610283"));
System.out.println("--> 用fixed64编码:");
convertFixed64(Long.valueOf("1600229610283"));
System.out.println("--> 用timeStamp编码:");
convertTimeNanos(Long.valueOf("1600229610283"));
System.out.println("================测试时间戳(精确到毫秒)===============");
System.out.println("--> 用int64编码:");
convertInt64(Long.valueOf("1600229610283000"));
System.out.println("--> 用uint64编码:");
convertUint64(Long.valueOf("1600229610283000"));
System.out.println("--> 用fixed64编码:");
convertFixed64(Long.valueOf("1600229610283000"));
System.out.println("--> 用timeStamp编码:");
convertTimeNanos(Long.valueOf("1600229610283000"));
}运行结果如下:
================测试时间戳(精确到秒)===============
--> 用int64编码:
1600229610283序列化后的数据:[32, -85, -90, -8, -88, -55, 46],字节个数:7
--> 用uint64编码:
1600229610283序列化后的数据:[16, -85, -90, -8, -88, -55, 46],字节个数:7
--> 用fixed64编码:
1600229610283序列化后的数据:[65, 43, 19, 30, -107, 116, 1, 0, 0],字节个数:9
--> 用timeStamp编码:
1600229610283序列化后的数据:[106, 8, 8, -64, 12, 16, -85, -90, -66, 109],字节个数:10
================测试时间戳(精确到毫秒)===============
--> 用int64编码:
1600229610283000序列化后的数据:[32, -8, -65, -21, -21, -25, -20, -21, 2],字节个数:9