

Facts as Experts: Adaptable and Interpretable Neural Memory over Symbolic Knowledge

论文链接: https:// arxiv.org/pdf/2007.0084 9.pdf
背景
大规模语言模型如BERT、Transformer其已被证明可以编码进大量的常识和事实(Fact)信息,是许多下游任务的基础,但是这些知识只存在于模型的潜在参数中,不能进行检查和解释,而且随着时间和外部环境的变化,从训练语料库中学习到的一些事实信息可能会过时或出错。
为了解决这些问题,本文提出Facts-as-Experts (FaE)模型,FaE在神经网络语言模型和符号知识库(symbolic KB)之间建立了一个桥梁,将深度神经网络的表达能力优势和符号知识库的推理能力优势结合在一起。实验表明,FaE在知识密集型问答任务中显著提高性能,FaE也可以通过操控KB来更新模型而无需重新训练,也可以添加新的知识信息来覆盖现有的知识。
Facts-as-Experts (FaE)
-
Definitions and input
知识库K: 三元组集合
三元组(s, r, o):s为主体,o为客体,r为二者的关系
文本语料库C:由段落$$$$\begin{Bmatrix}p_1,...p|c|\end{Bmatrix} $$$$组成
entity mention的集合M,每个实体$$$$(e_m, s_m^p, t_m^p) $$$$表示在段落p中从$$$$s_m^p $$$$到$$$$t_m^p $$$$的文本中被提及的实体$$$$e_m $$$$,后边简写为$$$$s_m $$$$到$$$$t_m $$$$
对于输入的文本,被mask的mention称为答案实体,其他没有被mask的实体被称为context mentions。 如 { ‘Charles’, ‘Darwin’, ‘was’, ‘born’, ‘in’, [MASK], [MASK], ‘in’, ‘1809’, ‘.’, ‘His’, ‘proposition’, . . . }, “Charles Darwin” 是mention m1 = (‘Charles Darwin’, 1, 2)中的context entity, “United Kingdom”在masked mention (‘United Kingdom’, 6, 7)中的答案实体。
FaE模型通过实体感知的context embedding,学习从context mentions中链接实体,并使用知识增强信息预测答案实体。
-
整体架构:
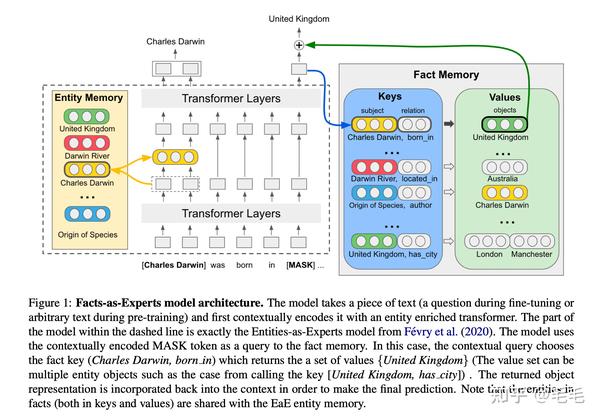
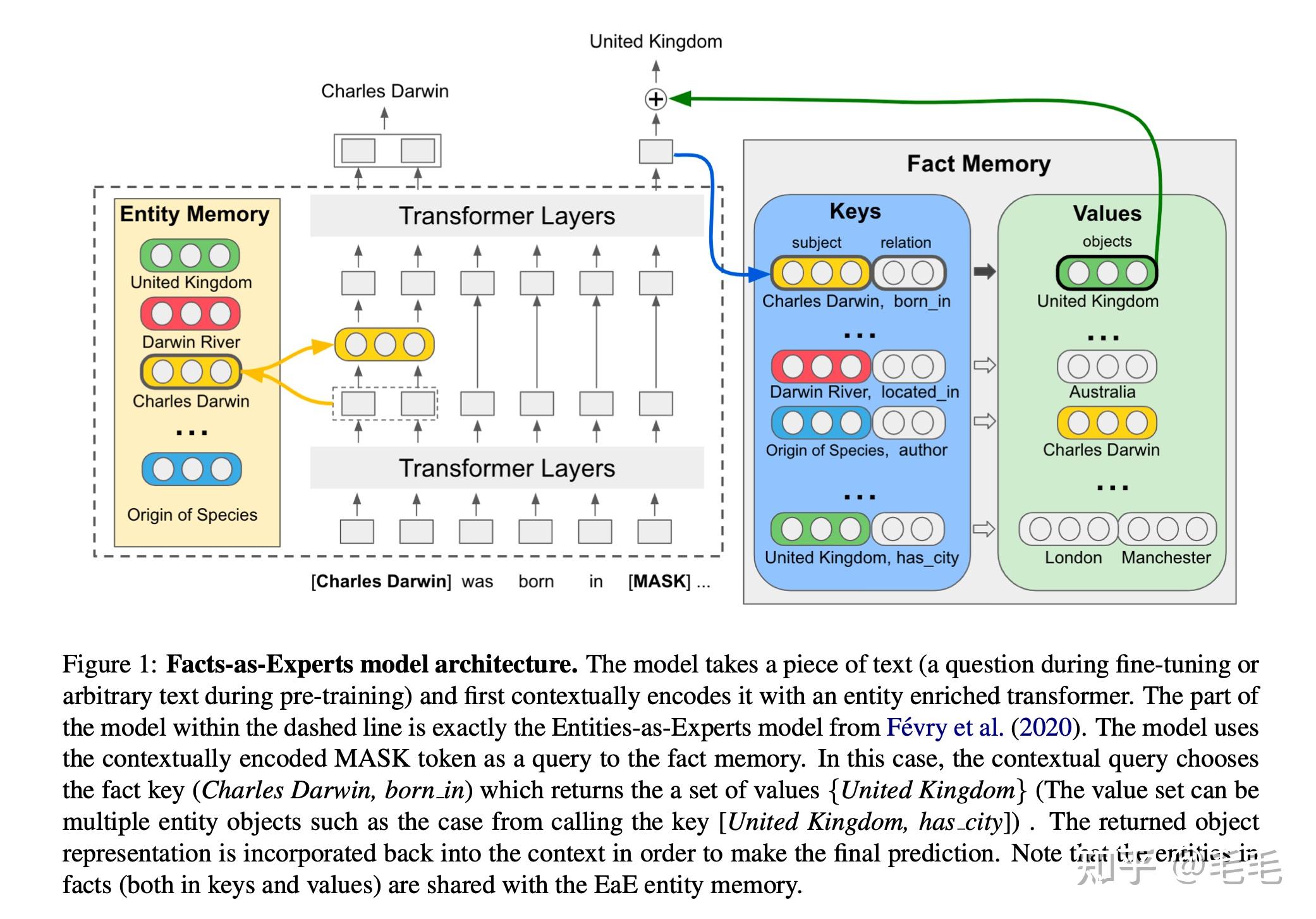
- FaE基于 EaE 模型(图1左侧提出),EaE是在Transformer 架构中增加Entity Memory模块,EaE模型可学习到实体的上下文表示以及语义信息;FaE在EaE模型中引入Fact Memory模块,Fact Memory基于知识库的三元组进行编码,每个三元组都是由组成它实体的EaE-learned embedding组成。Fact Memory用一个键值对表示,可以用来检索知识库中的信息。
- 如图1所示,左侧虚线内的模型是EaE,右侧是Fact Memory。finetune模型的训练是输入一段文本,使用[MASK]作为对Fact Memory的查询,使用Transformer层对其进行上下文编码,然后通过上下文查询得到fact memory的Key(如[Charles Darwin, born in]),以及该Key在三元组中对应的Values(如{United Kingdom}),Fact memory返回的信息会被整合到上下文的表示中来进行最终的预测。pretrain时会随机mask context mention (非答案实体),然后用mask的mention作为对entity memory的查询,并得到entity memory返回的实体向量,然后把这个向量与上下文表示整合在一起后向下一层传播。
- fact memory中的键值与 Entity Memory共享,FaE模型能够有效结合符号知识库中的信息。
Entity-aware Contextual Embeddings
- Entity Memory是单独训练的一个模型,训练方式与EaE论文中的一样,最终得到的Entity Memory为一个矩阵,每一行是一个实体的embedding。
-
输入的文本q = {w1,...,w|q|} ,q的context mentions为$$$$mi $$$$=$$$$(e_{mi}, s_{mi}, t_{mi}) $$$$,maked mention(answer)为$$$$m_{ans} $$$$=$$$$(e_{ans}, s_{ans}, t_{ans}) $$$$,contextual embedding $$$$h_i^l $$$$表示transformer 第l层中第i个token的输出,用contextual embedding来计算emtity memory的查询向量。
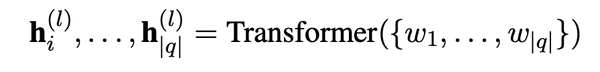
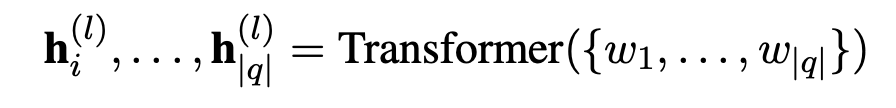
-
Entity embedding的查询向量:
- context mention $$$$m_{i} $$$$的上下文向量$$$$h_{mi}^l $$$$的获取: 拼接$$$$mi $$$$起始位置的context embedding$$$$h_{smi}^l $$$$和$$$$h_{tmi}^l $$$$,得到mention mi的上下文向量$$$$h_{mi}^l $$$$,如公式(1)
- 加权实体向量和$$$$u_{mi}^l $$$$: 通过softmax函数对整个实体矩阵计算weight,能够保证越相似的两个实体权重越大,并得到实体向量的加权和$$$$u_{mi}^l $$$$,如公式(2)
- 构造下一层每个token的输入:上一层输出+ 实体向量 如公式(3)
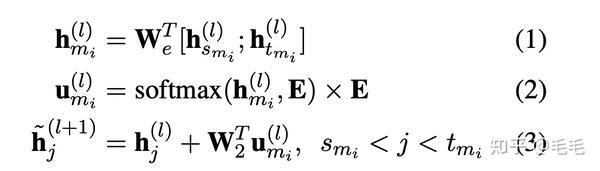
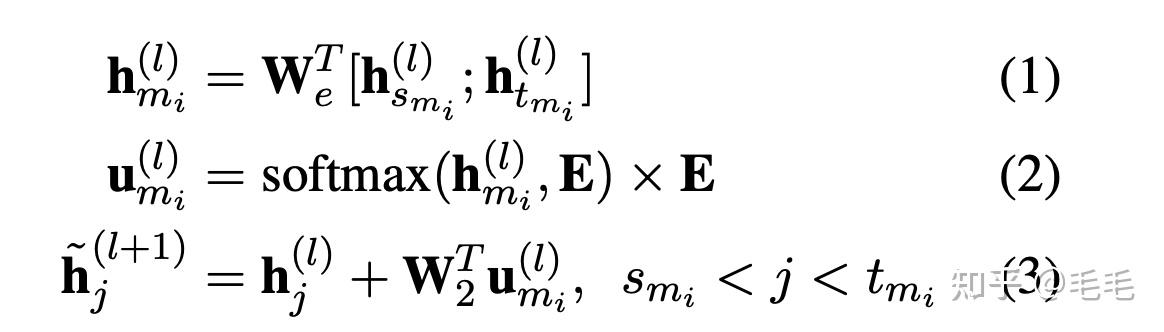
- Context query $$$$c_{m_i} $$$$:当l为transformer的最后一层时,公式2 得到的查询向量就是文中所说的实体感知的上下文查询向量,以下表示为$$$$c_{m_i} $$$$,通过argmax可以得到上下文的实体$$$$\hat e_{m_i} $$$$ 查询向量的训练loss是cross_entropy loss
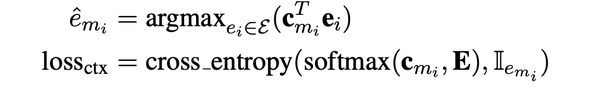
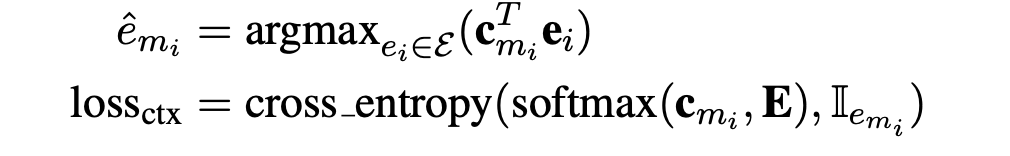
-
entity memory access loss
EaE论文中表明对中间实体的预测有助于学习实体感知的上下文向量,所以也使用中间层的输出计算entity memory的loss
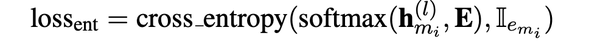
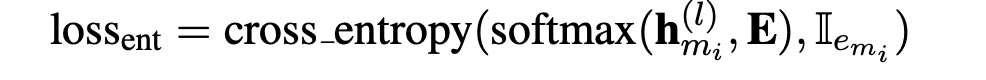
Fact Memory
- Fact memory基于KB构造,Fact memory的实体表示共享entity memory实体向量E,不同的是fact memory中的实体与三元组相关联,表示为键值对的形式 ((s,r),{o1,...,on}),其中同一个(s,r)可能对应多个客体,称(s,r)为head pair, {o1,...,on}为tail set,
- A :主体--关系对 $$$$a_j $$$$ = (s,r) ∈ A,拼接主体向量和关系向量并线性映射到新的向量空间,A表示所有head pair的向量组成的矩阵。 B : tail set,客体 list, $$$$b_j $$$$ = {o1,...,on} ∈ B 。 K也可以表示为 K′ = (A,B) ,通过A中的key(s,r)打分并返回相对应的客体list。对于A中每个元素$$$$a_j $$$$ 可以按照下边公式进行编码,其中 ∈ E ,r ∈ R
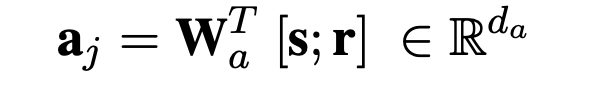
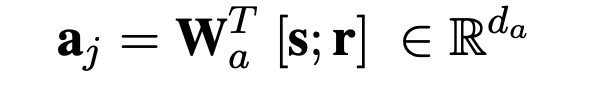
- 计算fact memory的查询向量$$$$V_{m_{ans}} $$$$:对于mask的实体$$$$m_{ans} $$$$=($$$$e_{ans} $$$$,$$$$s_{ans} $$$$,$$$$t_{ans} $$$$),通过公式(4)得到它的查询向量 query vector $$$$V_{m_{ans}} $$$$,其中$$$$h_{ans}^{(T)} $$$$表示$$$$m_{ans} $$$$第一个token在transformer最后一层输出的向量。
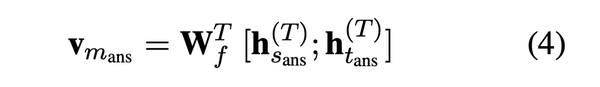
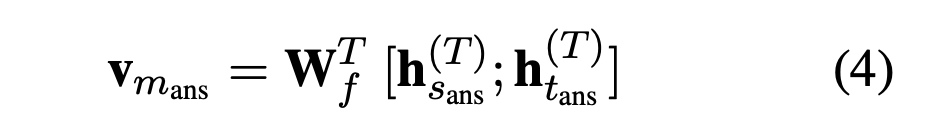
- 选择topk head pair:A中的head pair 通过$$$$V_{m_{ans}} $$$$计算得分,选择二者内积最大的top k个head pair,fact memory会返回topk个pairs对应的tail sets$$$$\begin{Bmatrix} b_j|j \in TOP_k(V,A) \end{Bmatrix} $$$$
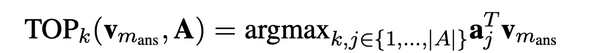
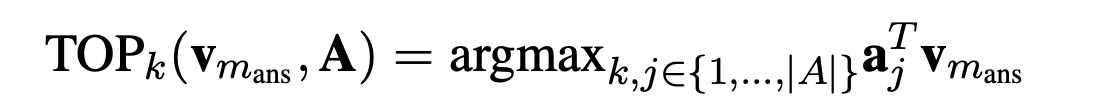
- 对于一个head pair$$$$a_{ds} $$$$=(s,r) ,如果s与文本中的某个context mention $$$$m_{i} $$$$一致,而且mask的答案实体也在(s,r)相对应tail set中,这种称为有监督的正例;如果文本中所有的mention 没有在A中找到对应的head pair,则定义一个null 的三元组,$$$$a_{ds} $$$$=$$$$(s_{null}, r_{null}) $$$$对应的tail set为空。对于上述有监督的样本计算查询fact memory的loss.
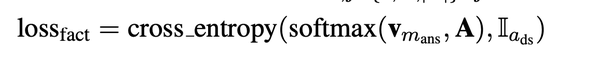
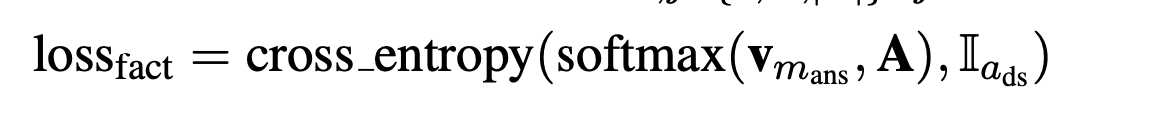
Integrating Knowledge and Context
- 从Fact memory得到的topk个tailsets 整合到contextual embedding中。
- tail sets的向量表示: 每个tail set $$$$b_{j} $$$$本质是多个实体{o1, . . . , on} 的集合,通过softmax函数计算tail set的加权和来表示它的向量,即$$$$\bf{b_j}=\sum_{o_i \in b_j}\alpha_i o_i \in R^{d_e} $$$$,$$$$\alpha_i $$$$的计算类似之前查询向量的计算,如公式(6)
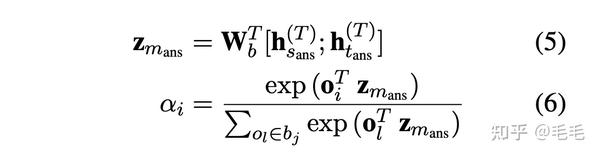
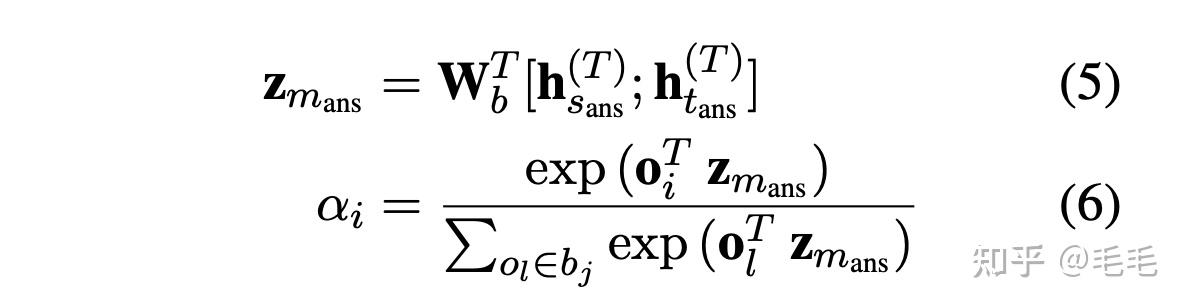
-
knowledge query
$$$$f_{m_{ans}} $$$$
,
如公式(7)所示,每个tail set所对应的head pair与查询向量的计算softmax得到这个tail set的权重,对所有tail set求加权和就是fact memory最终的向量输出。
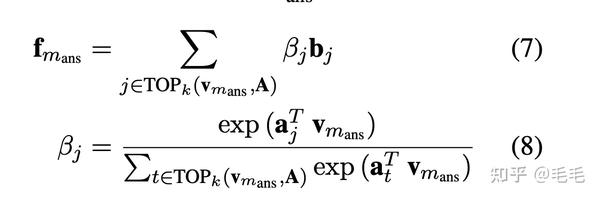
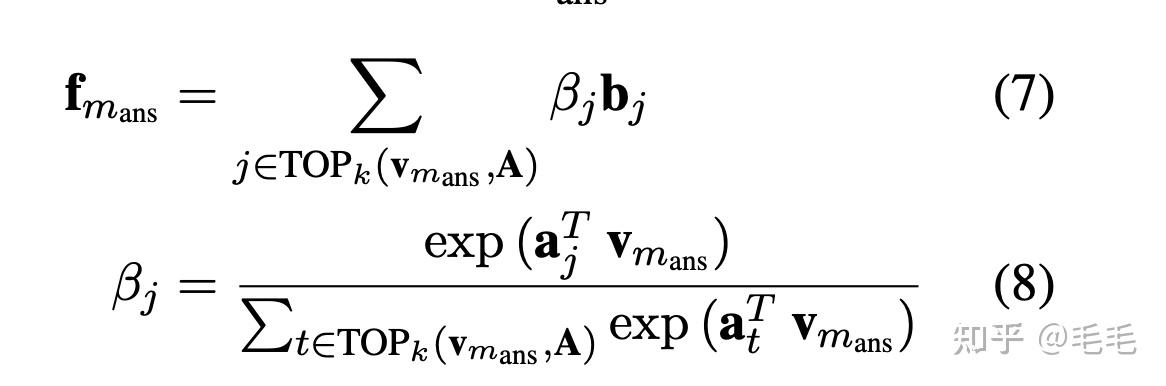
- FaE模型能够联合entity memory得到的context query $$$$c_{m_{ans}} $$$$和fact memory得到的knowledge query $$$$f_{m_{ans}} $$$$ 共同进行mask 实体的预测,用一个参数$$$$\lambda $$$$控制融合权重;也就是当文本中的某个实体没有在fact memory中没有找到相应的三元组时,就用context query,反之用knowledge query。$$$$\lambda $$$$取值为fact memory中为null的概率。
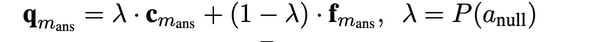
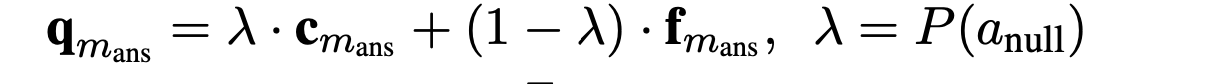
- $$$$\bf{q}_{m_{ans}} $$$$被称为知识增强的上下文查询( knowledge- enhanced contextual query )FaE模型最终用这个向量来进行mask entitty的预测,$$$$\bf{q}_{m_{ans}} $$$$对应的loss如下。
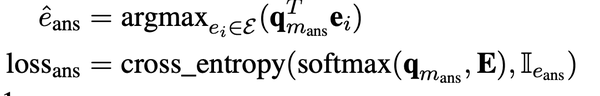
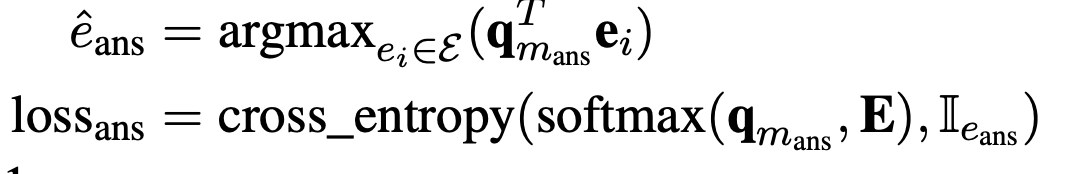
Pretraining
预训练模型是联合训练,同时预测context entities和masked entities.
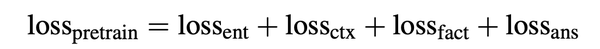
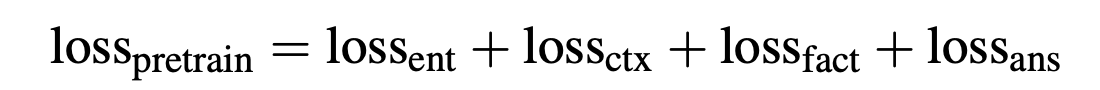
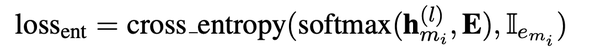
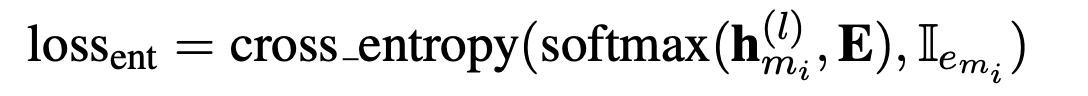
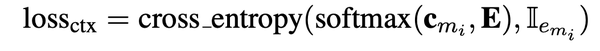
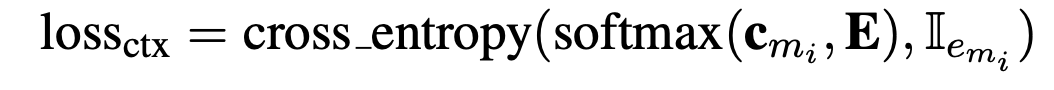
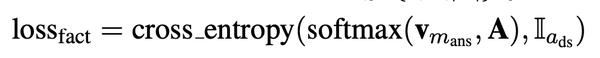
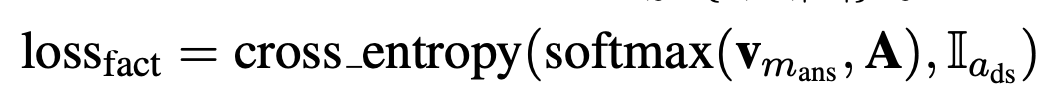
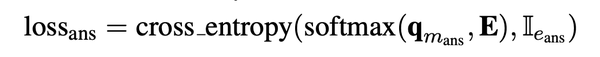
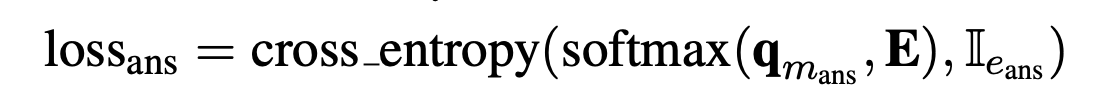
Finetuning on Question Answering
本文主要关注答案为知识库中实体的开源问答任务,finetuning任务是预测被mask的实体,在finetuning阶段entity embeddings E和relation embeddings R 都是固定的。
实验
-
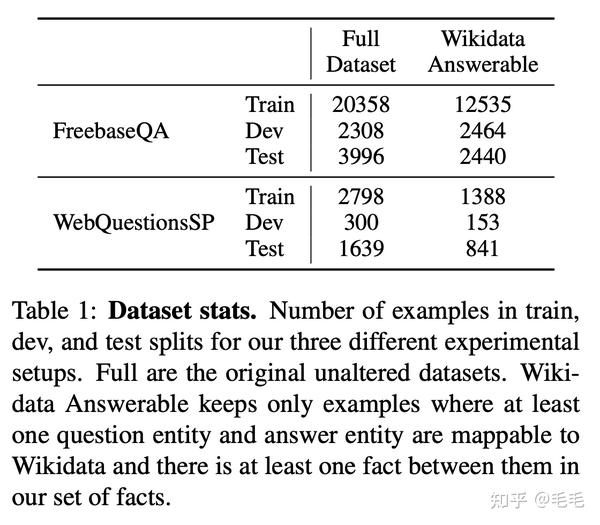
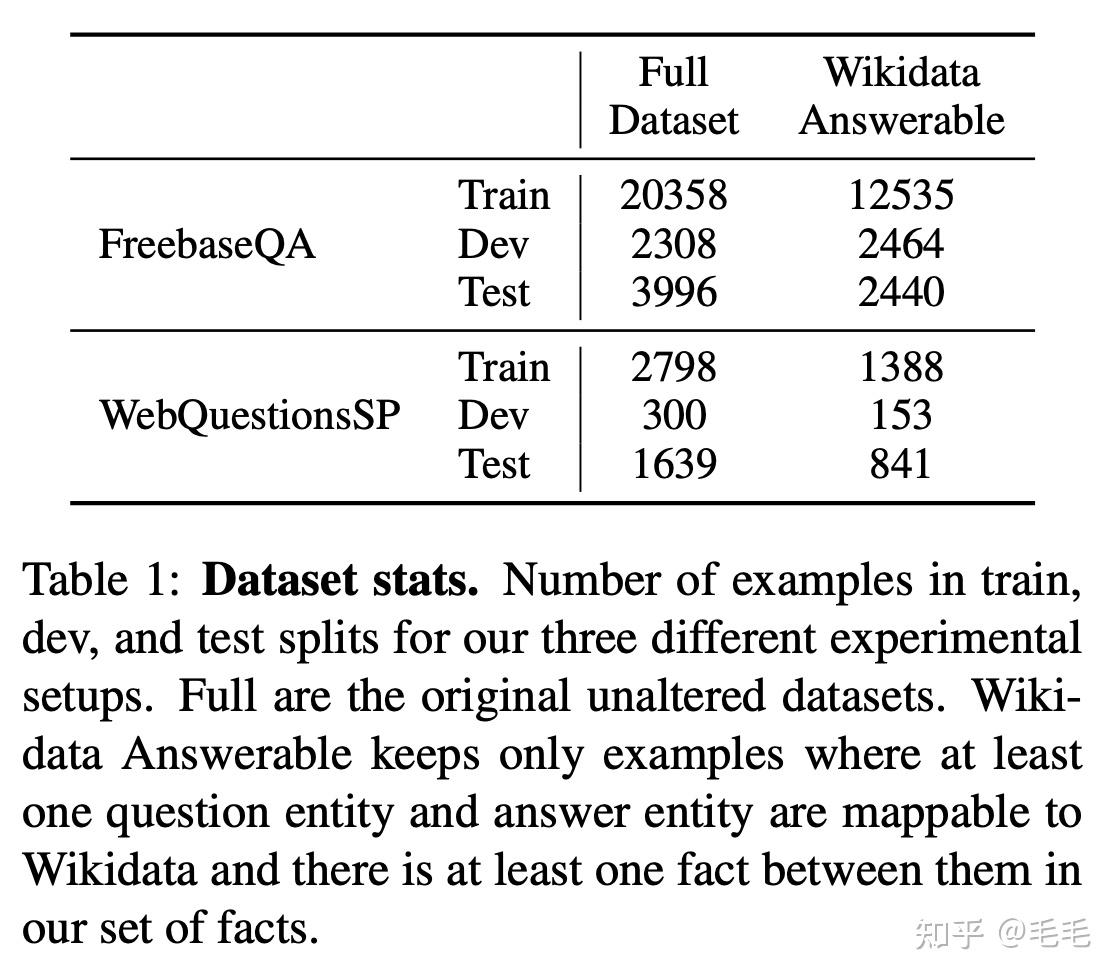
数据集&实验结果
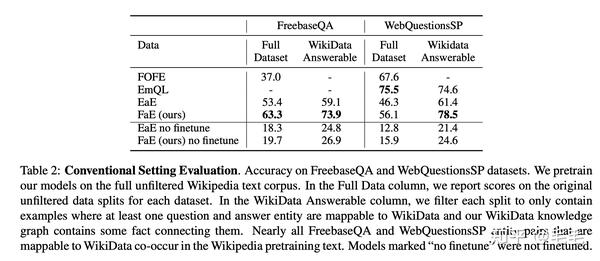
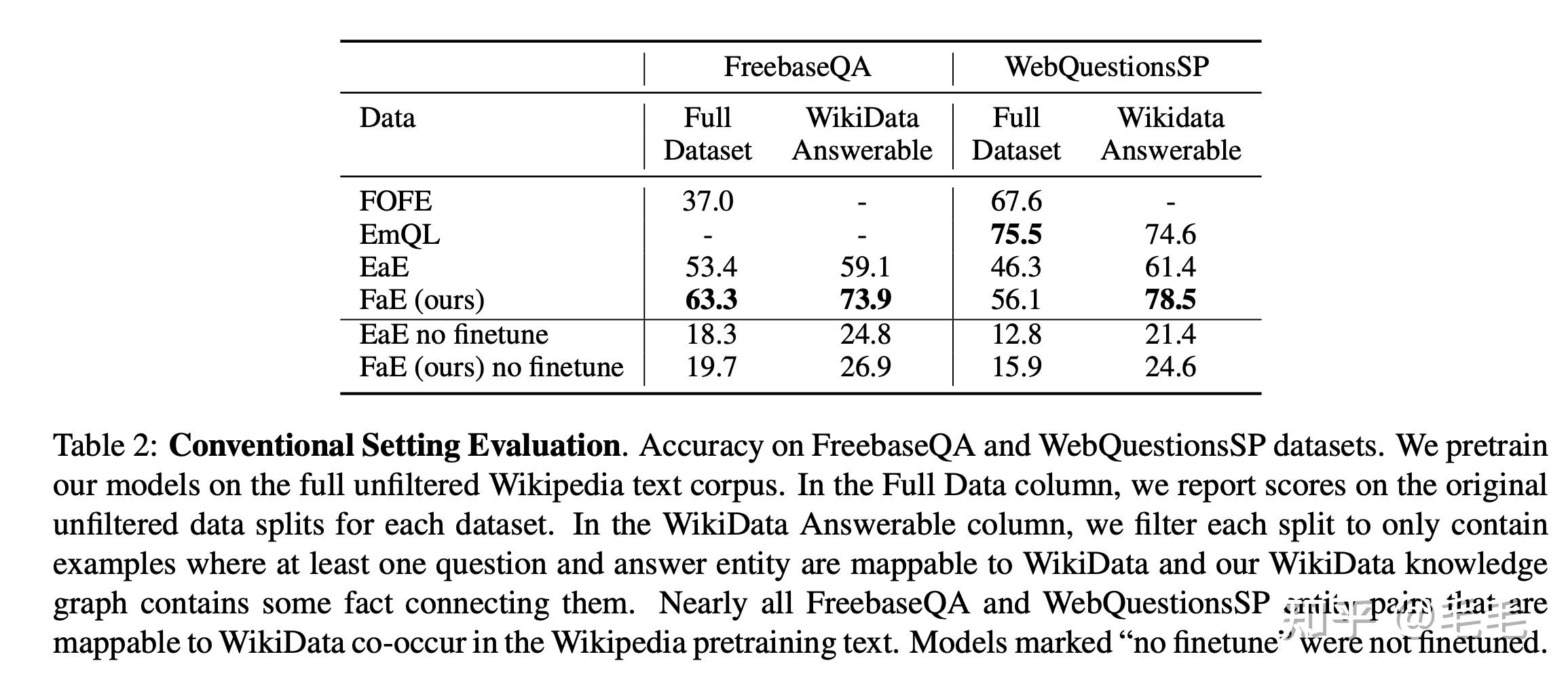
FOEF: state-of-the-art model on the Free- baseQA dataset
EmQL:state-of-the-art model on WebQuestionsSP
-
实验结果:
- FaE在FreebaseQA数据集上的准确率高于其他基线模型近10个百分点。在WebQuestionsSP完整数据集上FaE的性能相对较低,但这主要是由于知识库不完整,KB中只涵盖了WebQuestionsSP数据集中53%的问题。
- 如果只看可回答的数据,也是就是‘Wikidata Answerable ’列,可以看到FaE模型都是最优的。
讨论
-
数据重叠
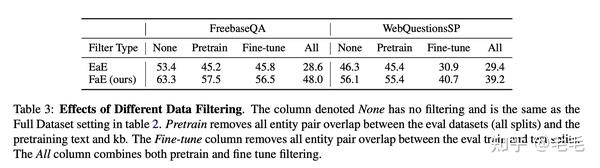
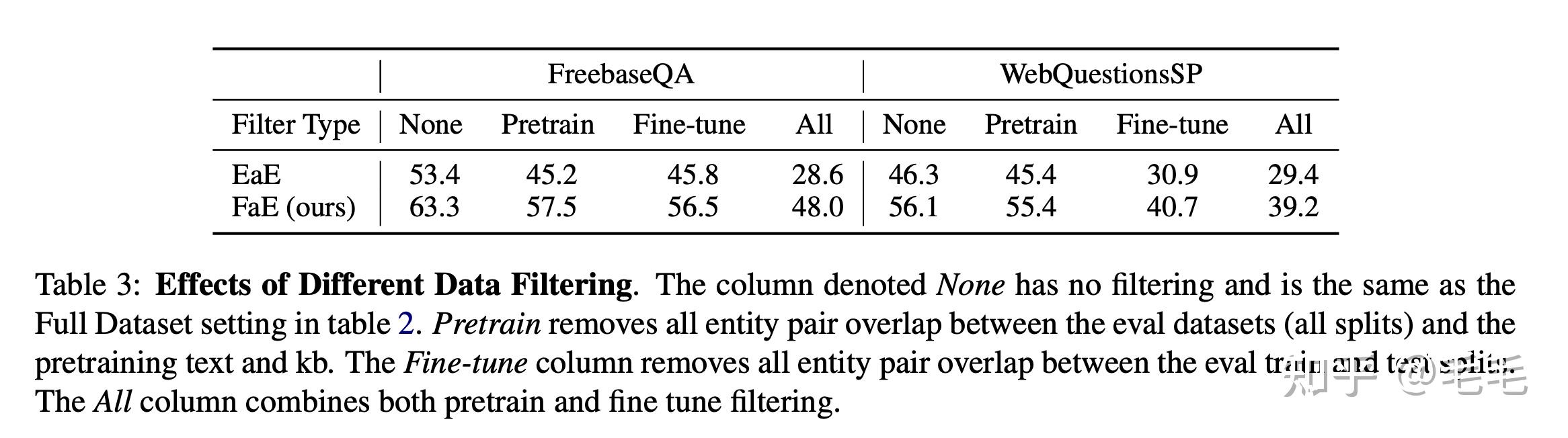
本文模型主要关注对模型使用外部知识回答问题的能力,而不是学习识别语义相同的问题。对这两个数据集的分析表明,许多测试答案也显示为某些训练集问题的答案:FreebaseQA测试数据中75.0%的答案和WebQuestionsSP中57.5%的答案都是这种情况。这表明了一种可能性,即模型的某些高性能可能归因于简单地记住特定的问题/答案对。
为了解决这个问题,本文进行了丢弃实验,去除训练集中与test&dev中重叠的case。当应用重叠过滤之后,模型的表现要差得多。
-
新事实注入
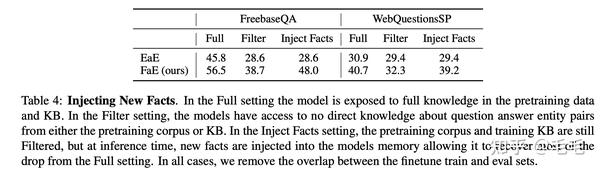
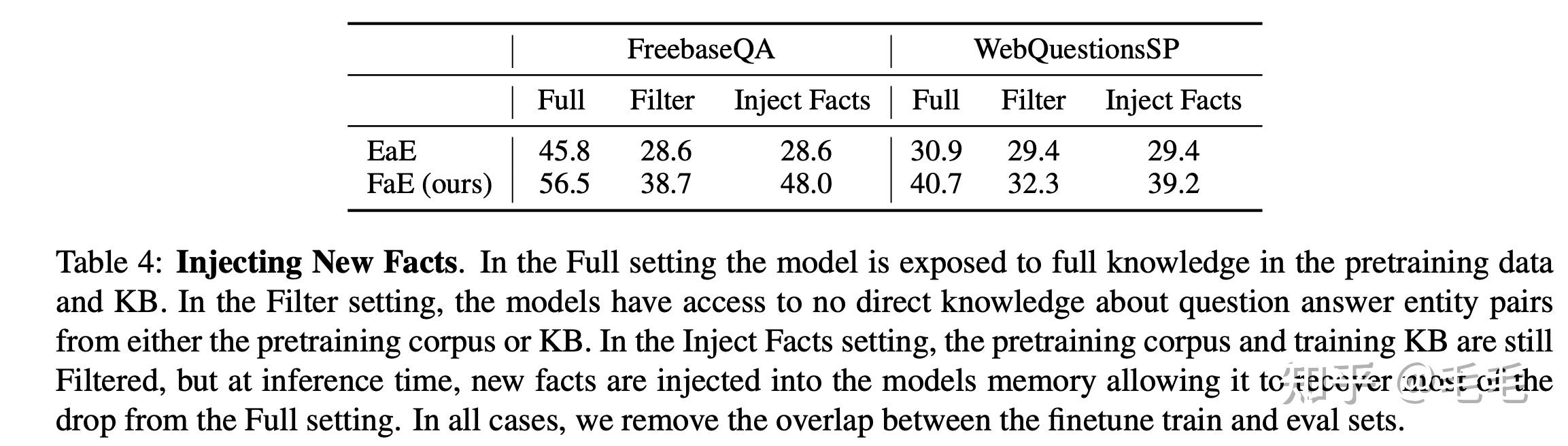
因为作者的模型只是象征性地定义了事实,原则上它可以在fact Memory中引入新的事实,而无需重新训练模型的任何参数。
为了测试模型执行此任务的能力,作者比对了模型在给定完整知识、过滤知识和注入知识的情况下的结果,如表4所示。过滤知识和注入知识的对比实验可以看出模型能够很好地利用新引入的知识。
-
更新陈旧Memory
本文希望模型能很好地对知识进行表示,并且这种知识表示可以通过随外界环境变化而增量更新来避免数据过时。为了探究这种能力,本文模拟了这个场景的一个极端版本,把FreebaseQA测试集中对问答对的所有答案都替换为词表中其他合理的值,实验结果显示FaE利用修改后的知识库对30%的问题做出正确的预测。
