

ICCV2019-FSGAN:实现任意两张人脸图片换脸的GAN方法
Face Swap Gan是ICCV19的一篇文章,模型看起来比较复杂,总体结构由三个生成器和一个语义分割网络组成,能够实现任意两张人脸图片较好的换脸效果,在视频人脸重建中效果也比较好。
论文地址
工程地址
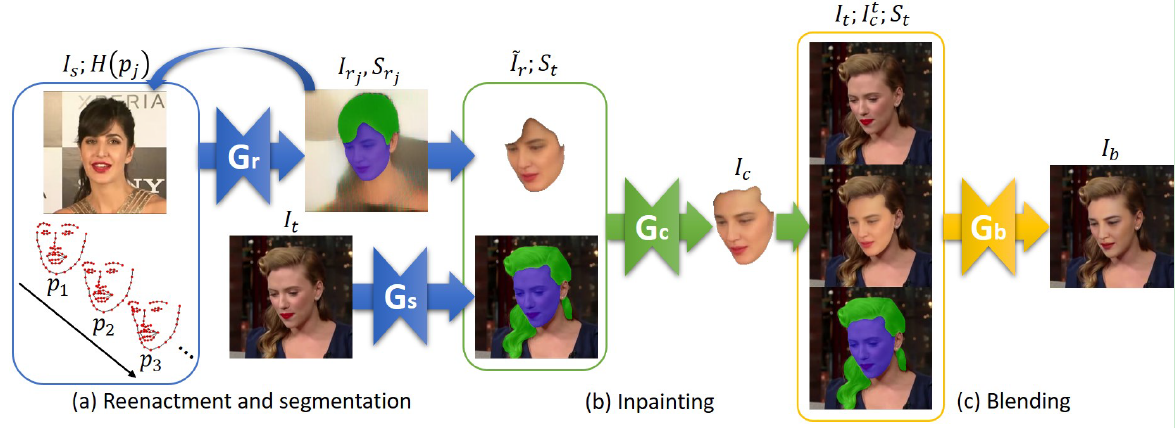
将一个换脸任务简单表述为给定两张任意的图片A和B,将图片A中的人脸换到图片B中的人脸上,方法整体的大致流程如下:输入图片A和B,首先调用第三方模型得到人脸B的欧拉角及关键点,然后利用生成模型Gr根据这个角度和人脸A,生成姿态角度与人脸B一致但保存A脸特征的人脸A',接着利用分割模型S得到人脸B的脸部区域掩码
,随后根据A'和
,利用生成模型Gc对A'进行残缺区域补全或者多余部分擦除得到A'',最后一步,根据A''、
以及脸B,利用生成模型Gb,对A''中人脸的光照肤色等进行渲染,使结果更加自然,最终输出换脸结果。很明显,整个方法需要训练四个模型,根据以往经验,训练GAN必然是一个既吃资源又难以得到好效果的过程,何况还有三个功能各异的GAN,(摊手),但是模型的最终的效果以及各个模型拆分开来,可能也对许多子任务具有参考意义。
总的来看,论文有三处贡献:
- 任意图片人脸互换。FSGAN能够实现任意两张图片的换脸。(之前方法比如FSNet,每个模型只能将固定的人脸换到对应的图片上)
- 多视角人脸插值。重点是,针对视频中的换脸任务,论文提出的方法利用Gr的生成结果以及德洛夫三角剖分以及质心坐标,能够实现多视角人脸插值而无需针对每一帧都训练一个模型。
- 两个新型损失函数。用于训练脸部生成模型的逐级一致性损失与用于训练渲染模型的泊松损失。
FSGAN模块组成与流程上文已经介绍,其中分割模型论文使用Unet架构,三个生成器均使用了pix2pixHD的架构,方法流程,如下图所示:
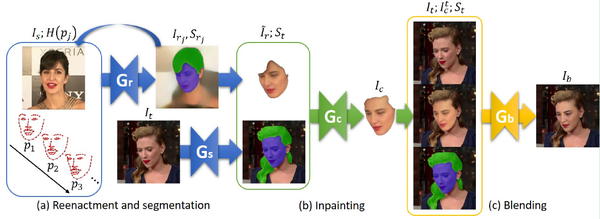

也可以更直观地看到模型各个阶段的结果如下图所示:


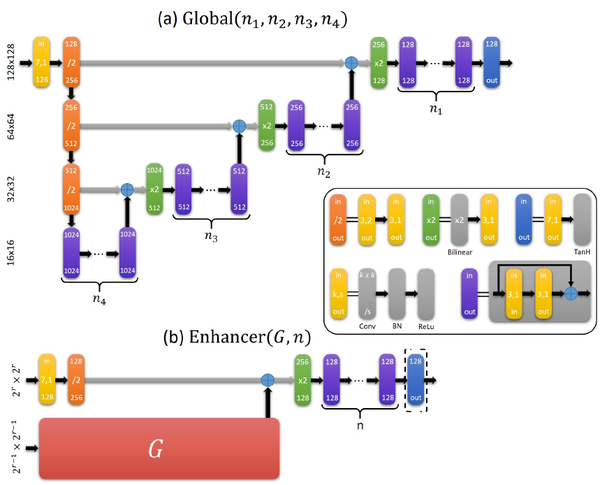
更具体地,三个生成器模型架构类似,如下图所示,基本结构是一个类UNet+增强结构:

接下来,分不同部分来看论文。
1. 基础损失函数
1.1 特定领域感知损失
常用感知损失使用预训练好的VGG网络得到的特征图,并利用欧几里得距离结合高频细节。但是使用一个针对ImageNet的预训练模型很难完全捕获脸部细节。 因此论文针对脸部识别与分类任务重新训练了多个VGG-19网络,令
表示模型第
层的输出,感知损失定义为:
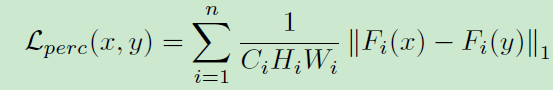

1.2 重建损失
但是仅使用上面的感知损失训练GAN,很容易产生有奇怪颜色并且与目标图像相关度较小的结果。因此论文使用了一个逐像素的
损失:
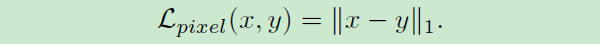

这个两个损失的结合,将参与所有生成器的训练:
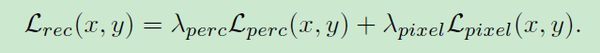

1.3 对抗损失
论文使用了一个由多个判别器组成的多尺度判别器,其中每一个部分负责相应分辨率的特征图的判定,对抗损失定义为:
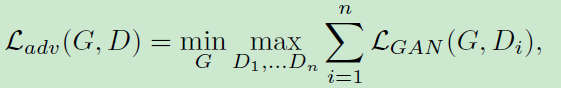

其中:
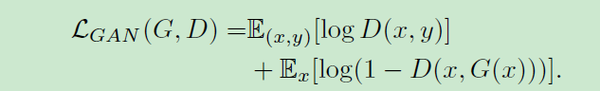

2. 脸部重建与分割
脸部重建生成器Gr,输入源图像与其脸部关键点的heatmap,利用源图像与目标图像的形心与欧拉角,利用形心之间以及欧拉之间的对应关系进行插值,生成具有目标图像人脸欧拉角度的和源图像人脸特征的图像。
Gr的输出部分被分为两部分,一个负责产生重建的图像,一个负责产生该重建的人脸图像的分割掩码(主要是头发和人脸两部分掩码)。而分割网络S则直接产生这种三类的分割掩码。
训练过程中,给定图像对
,令
表示n次迭代之后的重建结果,而
表示对应的去除背景区域的结果,
逐步一致性损失定义为:
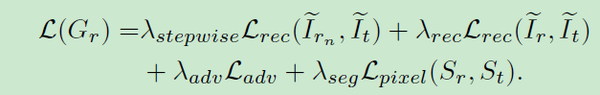

而分割网络的损失则为标准的交叉熵再加上
的指导:
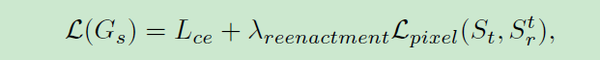

训练过程,可以将Gr和S分开训练,也可以合在一起交替训练,论文说后者对于噪声过滤有很好的效果,但对于特定目标图像的换脸任务,S的训练甚至可以省略。
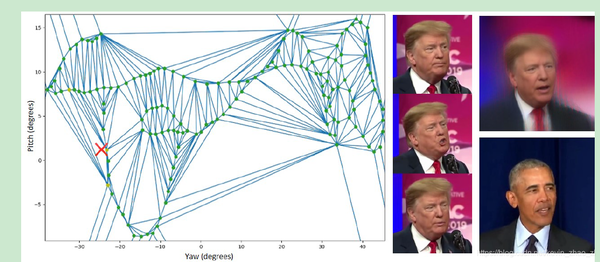
3. 脸部(多)视角插值
这个方法是视频人脸重建的核心,因为避免了逐帧训练无数个模型。给定源原目标图像序列、其中的人脸图像序列及其对应的欧拉角序列,首先将映射欧拉角至平面从而抛弃roll方向的角度,使用k-d树移除欧拉角度相近的人脸,进一步移除模糊的图像。使用剩下的点和脸部区域矩形,使用德洛夫三角剖分建立一个mesh。对于一个特定的目标图像,比如人脸
、欧拉角
及其对应的序列坐标
,找到包含该坐标的一个德洛夫三角,从而得到三角形的三个顶点己去对应的源图像人脸视角,计算重心从而得到插值结果:
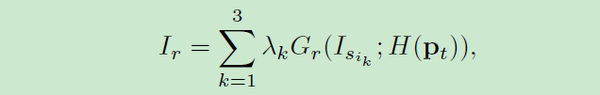


4. 脸部插值
对于两张图像的换脸任务,我们只需要训练一个生成器,对于Gr的生成结果相对目标图像人脸,进行残缺部分的补全或者多余部分的擦除即可,损失函数定义为:
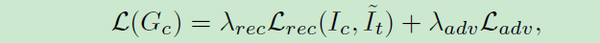

5. 脸部渲染
最后一步是根据插值补全/擦除的人脸根据目标人脸进行肤色光照等的渲染,收到泊松无缝融合的启发,论文提出了一个新型的泊松渲染损失:令
作为目标图像表示目标图像,
表示根据目标图像进行重建的图像,
为目标图像的人脸分割掩码,泊松渲染优化过程可以抽象为:
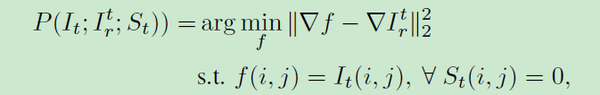

将上面的优化过程与感知损失结合,新型泊松渲染损失定义为:
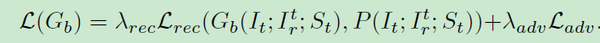

6. 不足与展望
不足在于过多次数的迭代会使得Gr生成模糊的人脸效果,而且如果选用的脸部关键点效果较差,可能无法精确的捕获目标脸表情,从而影响生成效果。但是总的来看,论文三个生成器以及一个多视角人脸插值方法的提出,以及以任意两张人脸图像换脸的出发点和优秀的效果,还是能够给很多类似的(子)任务带来启发。
欢迎关注 深度学习与数学 [每天获取免费的大数据、AI等相关的学习资源、经典和最新的深度学习相关的论文研读,算法和其他互联网技能的学习,概率论、线性代数等高等数学知识的回顾]
