

新手小白 做python爬虫 爬什么网站比较简单?
关注者
35
被浏览
152,354
17 个回答


求求各位别再说爬豆瓣、知乎、妹子图了,别人都给爬得受不了了,改反爬机制改页面结构改了一次又一次还要被搞。
建议爬一些比较老的、曾经热门的新闻资讯网站(新浪网易腾讯新闻什么的),结构简单、反爬较少或破解难度低、可以碰上各种奇奇怪怪的编码问题或结构不一致问题,解决以上问题时还可能了解到爬APP或者手机网页版的操作,最重要的是网站背后的企业有足够的钱支撑着,不至于给爬的生活不能自理。
这种新闻资讯网站要简单就很简单,要数据量大一点也有些难度。可以让你从页面解析到高并发请求再到应对简单的反爬策略、JS逆向或Android逆向都了解一遍,爬完之后的数据还能让你做个分析、词云什么的发朋友圈装逼,可以说是非常好的选择了。
然后可以搞一搞bilibili( 别去折磨穷困潦倒的acfun了 ),难度不高,而且也是有金主罩着不差钱的那种,爬它的人再多它也不疼不痒,毕竟钱还没视频流量上烧的多。能了解一波websocket、JS逆向/Android逆向、视频流获取/处理、模拟登陆什么的,爬下来的数据再做个播放量分析、弹幕密度分析,又能装一波逼。

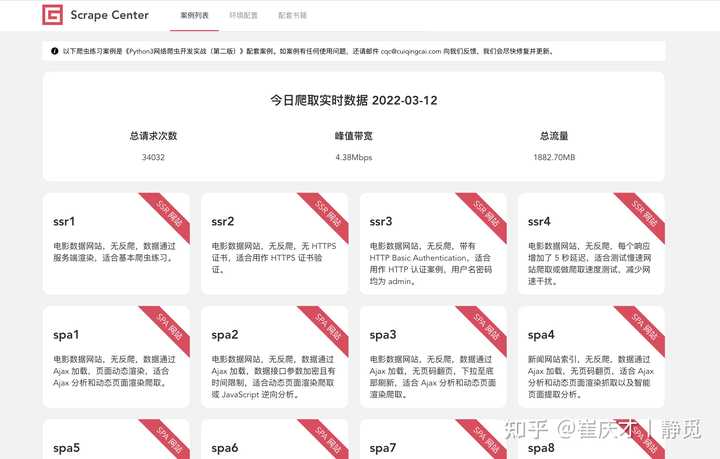
Scrape Center 是我做的一个爬虫练习平台。
之前也写过不少关于爬虫的博客了,比如我拿一个案例来写了一篇博客,当时写的时候好好的,结果过了一段时间这个页面改版了,甚至直接下线了,那这篇案例就废掉了。
另外如果拿别人的站或者 App 来做案例的话,比较容易触犯到对方的利益,风险比较高,比如把某个站的 JavaScript 逆向方案公布出来,比如把某个 App 的逆向方案公布出来。如果此时此刻没有对方联系你的话,一个很大原因可能是规模太小了别人没注意到,但不代表以后不会。我还是选择爱护自己的羽毛,关于逆向实际网站和 App 的案例我都不会发的。在这种情况下比较理想的方案是自建案例,只用这个案例讲明白对应的知识点就可以了。
所以,为此,这段时间我也在写一些爬虫相关的案例,比如:
- 无反爬的服务端渲染网站
- 带有参数加密的 SPA 网站
- 各类形式验证码网站
- 反 WebDriver 网站
- 字体反爬等网站
- 模拟登录网站
- App 案例,如代理检测,SSL Pining 等
如图所示:

配套讲解书籍:
