继上一章apriori关联分析算法
https://blog.csdn.net/weixin_37825814/article/details/113801865
本文讲解FP-Growth(Frequent Pattern Growth)算法
根据上一章的 Apriori 计算过程,我们可以知道 Apriori 计算的过程中,会使用排列组合的方式列举出所有可能的项集,每一次计算都需要重新读取整个数据集,从而计算本轮次的项集支持度。所以 Apriori 会耗费大量的计算资源,FP-Growth 算法是一个更高效的算法。
Apriori 算法一开始需要对所有的规则进行枚举,然后再进行计算,而 FP-Growth 则是首先使用数据生成一棵 FP-Growth 树,然后再根据这棵树来生成频繁项集。下面我们来看一下如何构建 FP 树。
还是以购物举例
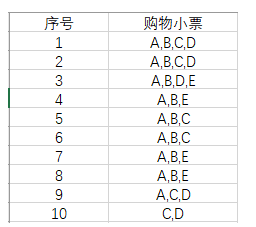
设置一个空集作为根节点。我们把第一条数据录入这个树中,每一个单项作为上一个节点的叶子节点,旁边的数据代表该路径访问的次数。下图就是我们录入第一条数据后的结果:
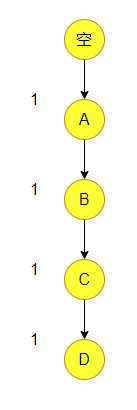
第二条数据与第一条一样,所以只有数字的变化,节点不会发生变化。
接着输入第三条数据。
输入完第二、三条数据之后的结果如下,其中由第一个D和第二个D直接画了一条虚线,标识它们是同一项。
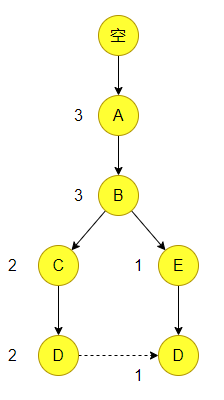
接下来我们把所有的数据都插入到这棵树上。

这个时候我们得到的是完整的 FP 树,接下来我们要从这里面去寻找频繁项集。当然首先也要设定一个最小频度的阈值,然后从叶子节点开始,也就是最低频的节点。如果频度高于阈值那么就收录所有以该项结尾的项集,否则就向上继续检索。
至于后面的计算关联规则的方法跟上面就没有什么区别了,这里不再赘述。下面我们尝试使用代码来实现关联规则的发现。
还是以杂货铺购物为例,
import pyfpgrowth
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
#读取数据
data = pd.read_csv('Groceries_dataset.csv')
data.head()
data['Date'] =pd.to_datetime(data.Date)
data.sort_values(by=["Member_number","Date","itemDescription"],ascending=[True,True,True]).head(10)
#去重, 合并itemDescription
data= data.drop_duplicates(keep="first")
new_data = data.groupby(['Member_number','Date'])['itemDescription'].apply(','.join).reset_index()
new_data.head(10)
#格式化itemDescription, 列表和元组都可以
new_data = new_data['itemDescription'].apply(lambda x: tuple(x.split(",")))
len(new_data)
这些部分与apriori算法前面读取数据, 处理数据都一样, 参考https://blog.csdn.net/weixin_37825814/article/details/113801865
# 使用pyfpgrowth模块
from fpgrowth_py import fpgrowth
# 两个参数, minSupRatio 支持度, minConf置信度
freqItemSet, rules = fpgrowth(order_list,minSupRatio=0.01, minConf=0.1)
print(rules)

后面的数字为置信度. 与apriori算法结果一致.
另外, 由于FP-growth的包的挺多的, 这里引用的fpgrowth_py, 但如果有用过pyfpgrowth包的朋友们请注意, 可能是我没理解透该包的原理, 反正我用的时候结果与apriori不太一致.
import pyfpgrowth
patterns = pyfpgrowth.find_frequent_patterns(order_list,150)#这个位置的参数代表支持度,也就是说出现数量150次以上
rules = pyfpgrowth.generate_association_rules(patterns, 0.1) #0.1 这个位置的参数代表置信度
print(rules)

发现里面没有(‘rolls/buns’, ‘whole milk’)这个项集, 但我把置信度调到200, 也就是出现次数在200的时候,
import pyfpgrowth
patterns = pyfpgrowth.find_frequent_patterns(order_list,200)#这个位置的参数代表支持度,也就是说出现数量200次以上
rules = pyfpgrowth.generate_association_rules(patterns, 0.1) #0.1 这个位置的参数代表置信度
print(rules)
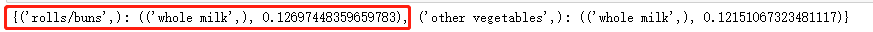
发现 (‘rolls/buns’, ‘whole milk’) 这个项集出现了
我们再次看一下 (‘rolls/buns’, ‘whole milk’) 的出限次数

确实大于200, 但我置信度设置成150的时候, 反而没有这个结果, 这个置信度应该是至少150, 也就是 大于等于150的时候满足条件, 但我不知道为何设置为200的时候会出现, 这个广大朋友可以探讨一下.
为此我使用的是fpgrowth_py这个包, 这个包的结果与apriori算法的结果相同.
在 Python 中使用 FP-growth 算法可以使用第三方库 PyFIM。PyFIM 是一个 Python 的实现频繁项集挖掘算法库,它提供了多种频繁项集挖掘算法,其中包括 FP-growth。
首先,需要安装 PyFIM 库。可以使用 pip 安装,在命令行中输入:
pipinstall pyfim
安装完成后,就可以在 Python 中使用了。下面是一个使用 FP-growth 算法挖...
在上篇文章频繁项集挖掘实战和关联规则产生.中我们实现了Apriori的购物篮实战和由频繁项集产生关联规则, 本文沿《数据挖掘概念与技术》的主线继续学习FP-growth。因《数据挖掘概念与技术》中FP-growth内容过于琐碎且不易理解,我们的内容主要参考了《机器学习实战》第12章的内容。本文是对书中内容的通俗理解和代码实现,更详细的理论知识请参考书中内容, 本文涉及的完整jupyter代码和《机器学习实战》全书配套代码包, 可以在我们的 “数据臭皮匠” 中输入"第六章3" 拿到
Apriori算法是经典算
本文为博主原创文章,转载请注明出处,并附上原文链接。
原文链接:
FpGrowth算法,全称:Frequent Pattern Growth—-频繁模式增长,该算法是Apriori算法的改进版本(若是不会这个算法或是有点遗忘了,可以移步到我的这篇博客),我们知道Apriori算法为了产生频繁模式项集,需要对数据库多次扫描,当数据库内容太大,那么算法运行的时间是难以忍受的,因此有人提出了FpGrowth算法,只须扫描数据库两次即可求出频繁项集,大
关联规则学习概述
在大型数据库中发现变量之间有趣关系的方法,目的是利用一些有趣的度量识别数据库中的强规则。基于强规则的概念,Rakesh Agrawal等人引入了关联规则以发现由超市的POS系统记录的大批交易数据中产品之间的规律性。例如,从销售数据中发现的规则{薄饼,鸡蛋}->{火腿肠},表明如果顾客一起买薄饼和鸡蛋,他们也有可能买火腿肠(这些顾客是想早饭吃手抓饼吧,哈哈),此类信息可以为大卖场商品组合促销或电商网站产品推荐等相关商业决策提供依据。除了上述的购物篮分析外,关联规则还被应用在许多领域中,
何为关联规则学习
关联规则学习是一种基于规则的机器学习方法,用于发现大型数据库中变量之间的有趣关系。它旨在使用一些有趣的度量来识别在数据库中发现的强规则。这种基于规则的方法在分析更多数据时也会生成新规则。假设数据集足够大,最终目标是帮助机器模拟人类大脑的特征提取和新未分类数据的抽象关联能力。
基于强有力规则的概念,Rakesh Agrawal,TomaszImieliński和Arun Swami...
def __init__(self,nodeName,parentNode,count):
self.nodeName=nodeName
self.parentNode=parentNode
self.childNodes={} #有很多个
FP-Growth是最常见的关联分析算法之一,其基本步骤是:
(1)对事务数据采用一棵FP树进行压缩存储
(2)FP树被构造出来,再使用一种递归的分而治之的方法来挖掘频繁项集

