

【CV-instance segmentation】Mask R-CNN阅读笔记


原论文连接: Mask R-CNN
motivation
Mask R-CNN是 ICCV 2017的best paper。这篇论文是自己欠很久的债了。虽然这篇论文网上已经很多阅读笔记,但是别人思考过的,如果自己没有精度多遍,没有亲自跑代码实现,看和不看没有区别。
Faster R-CNN用于目标检测,FCN用于物体分割,概念基本深入人心。论文提出一个高效实体分割+目标检测+关键点检测框架,各任务之间并行实现,速率5fps(在单GPU运行时间是200ms/帧,使用8 GPU卡,在COCO数据集训练只需要2天时间),模型简介,没有靠trick提升性能,网络框架主体就是Faster R-CNN+FCN。作者还未开源代码,但是github已经有基于tensorflow,MXNet的代码,这么经典的算法,怎么深入研究都不为过。
实体分割需要正确检测图片所有的物体并实现像素级分割。在论文之前的实现方式是分割之后做分类,而Mask-RCNN 的检测和分割是并行出结果。
Architecture
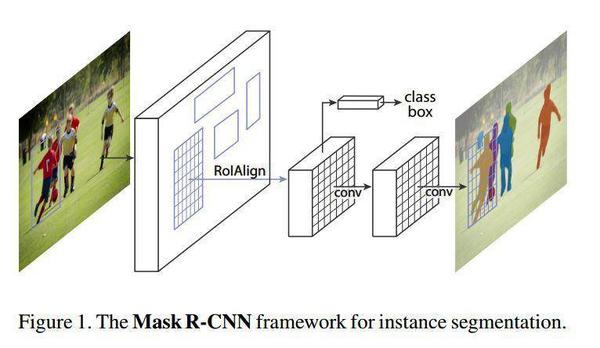

Mask R-CNN 大体框架还是 Faster R-CNN 的框架,可以说在RoI之后添加基于FCN的分割子网络,由原来的两个任务(分类+回归)变为了三个任务(分类+回归+分割),如上图所示Mask-RCNN 网络架构。 Faster R-CNN架构很容易训练,添加的FCN规模较小,所以Mask-RCNN网络架构不复杂。
Faster R-CNN架构可以参考本人之前写的阅读笔记。Faster R-CNN架构中的RoI Pooling 是抽取 RoI 区域特征的标准操作, 其将浮点数的 RoI 位置粗粒度地量化到 FeatureMap 大小, 量化后的 RoI 然后划分成若干空间 bins, 最终落入每个 bin 中的特征值进行 max pooling 操作。 从目标分类角度来说, 这不仅不会有负面影响, 而且还能够抵抗微小平移。 但是如果进行像素级的分类, RoI Pooling的量化操作会使得得到的mask与实际物体位置有一个微小偏移。RoIAlign 层的加入,改进feature map 的插值(论文使用的是双线性插值算法)。
Mask R-CNN同样采用两阶段方法。第一阶段提出RPN,第二阶段并行实现预测类别,box offset,二进制掩码( binary mask)。
在模型训练时,模型定义了一个多任务的损失函数L = Lcls + Lbox + Lmask。分类损失函数Lcls和边界框损失函数Lbox与Faster R-CNN中定义的相同。RoI有Kxmxm维度的掩码分支输出。Lmask损失函数由原来的 FCIS 的 基于单像素softmax的多项式交叉熵变为了基于单像素sigmod二值交叉熵。
Mask R-CNN网络架构有两点改进。(1)用于在整个图像上进行特征提取的卷积骨干架构,Faster R-CNN使用的是ResNets,而论文使用的是ResNeXt。(2)边界框识别(分类和回归)和分别应用于每个RoI的掩码预测,论文称为头部网络,是基于ResNet和FCN改进。
Mask R-CNN使用Fast/Faster R-CNN的超参数,并且只计算得分最高的前100个检测区域,速率提升明显。
Experiment
论文在coco数据集进行所有实验,并且与state-of-the-art算法进行性能比较。因为论文使用比较成熟的Faster R-CNN+FCN,所以没有实验步骤,只有实验对比结果。
论文在实验中简单介绍Human Pose Estimation,个人认为只是副产品,没有取得state-of-the-art效果。
Conclusion
1、instance segmentation=Semantic segmentation+object localization,做instance segmentation的论文本身都包括object localization,主要区别是之前方法分割之后做分类,而Mask-RCNN 的检测和分割是并行出结果。
2、Mask R-CNN的性能包括网络主框架采用ResNeXt,头部网络更改,多任务训练,RoIAlign层加入。
The gains of Mask R-CNN over FPN come from using RoIAlign (+1.1 APbb), multitask training (+0.9 APbb), and ResNeXt-101 (+1.6 APbb)。
速度的提升恐怕来自于只计算得分最高的前100个FPN。
