思维链(Chain-of-thoughts)作为提示

拖了一辈子没更新,不过chain-of-thought确实是越来越火了,今年iclr搜cot据说能搜出来3页结果哈哈哈哈哈。
现在更现在更。
研究背景
故事发生在2022年1月份,逐渐被大家意识到是在2022年的2月到3月之间。2021年一年中,提示学习(prompt learning)浪潮兴起,以离散式提示学习(提示词的组合)为起点,连续化提示学习(冻结大模型权重+微调较小参数达到等价性能)为复兴,几乎是在年末达到了研究的一个巅峰。
但在2022年开始,逐渐有很多人意识到连续化提示学习其中的一些好处伴随的一些局限性,比如伪资源节约,不稳定等等。很多研究者拒绝陪玩,虽认同提示学习将会带来下一代NLP界的革命,但是认为拒绝做他人大模型的附庸,开始探索大模型的训练技术,并且训练自己的大模型;而手头上暂时没有掌握资源的研究者研究单位则开始再次将研究重心从连续化学习转移到离散式提示学习上去,将研究聚焦于特定的大模型GPT3上。
此时,距离175B的GPT3模型被发布和上下文学习被发现过去了不到2年,热度经历了高潮与低谷,经历了深度学习流派关于连接学派和符号学派的辩论和是否具有意识和推理能力的讨论,一些基础的玩法在被开发之后就被搁置了一段时间直到提示学习的兴起。2022年1月,OpenAI通过强化学习调试模型,使用强化学习调试更新了他们的模型到了第二代,LLM肉眼可见地变得更好提示,很多任务的性能也显著提升,尤其是一些之前没有办法很好进行的任务被显著地提高了起来。
思维链系列工作就是在这样一个大环境下产生的。
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
思维链概念的开山之作
这篇文章是现任谷歌大脑研究员的Jason Wei在22年1月放到arxiv上面的文章,在上文所说的大背景下提出了思维链这个概念。简单来说,思维链是一种离散式提示学习,更具体地,大模型下的上下文学习(即不进行训练,将例子添加到当前样本输入的前面,让模型一次输入这些文本进行输出完成任务),相比于之前传统的上下文学习,即通过x1,y1,x2,y2,....x_test作为输入来让大模型补全输出y_test,思维链多了中间的一些闲言碎语絮絮叨叨,以下面这张图为例子:


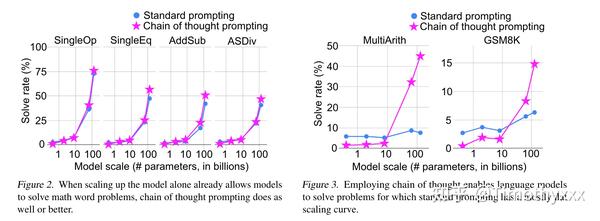
这个例子选择自一个数据集叫GSM8K,每一个样例大概就是一个小学一二年级的看几句话(基本都是三句)写算式然后算答案的难度,但是GPT3通过我们刚刚说的最简单的提示方法曾经只能在这个数据集上做到6%左右的准确度。由此可见,直接预测y是一个非常不太行输出空间。
思维链的絮絮叨叨即不直接预测y,而是将y的“思维过程”r(学术上有很多学者将这种过程统称为relationale)也要预测出来。当然最后我们不需要这些“思维过程”,这些只是用来提示获得更好的答案,只选择最后的答案即可。作者对不同的数据集的原本用于上下文学习的提示标注了这些思维链然后跑了实验,发现这么做能够显著的提升性能(左图),且这种性能的提升是具有类似于井喷性质(右图)的(后来他们发文号称这种性质叫涌现性,我们这里先按下不表)。

Self-Consistency Improves Chain of Thought Reasoning in Language Models
多数投票显著提高CoT性能
这篇文章是思维链初代文章很快的一个跟进工作,是思维链系列文章版图的重要一步,在2022年3月在arxiv上被放出来。这篇文章几乎用的和初代思维链文章完全一样的数据集和设置,主要改进是使用了对答案进行了多数投票(majority vote),并且发现其可以显著地提高思维链方法的性能。
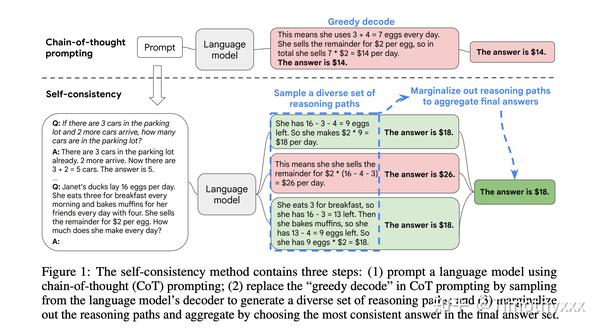
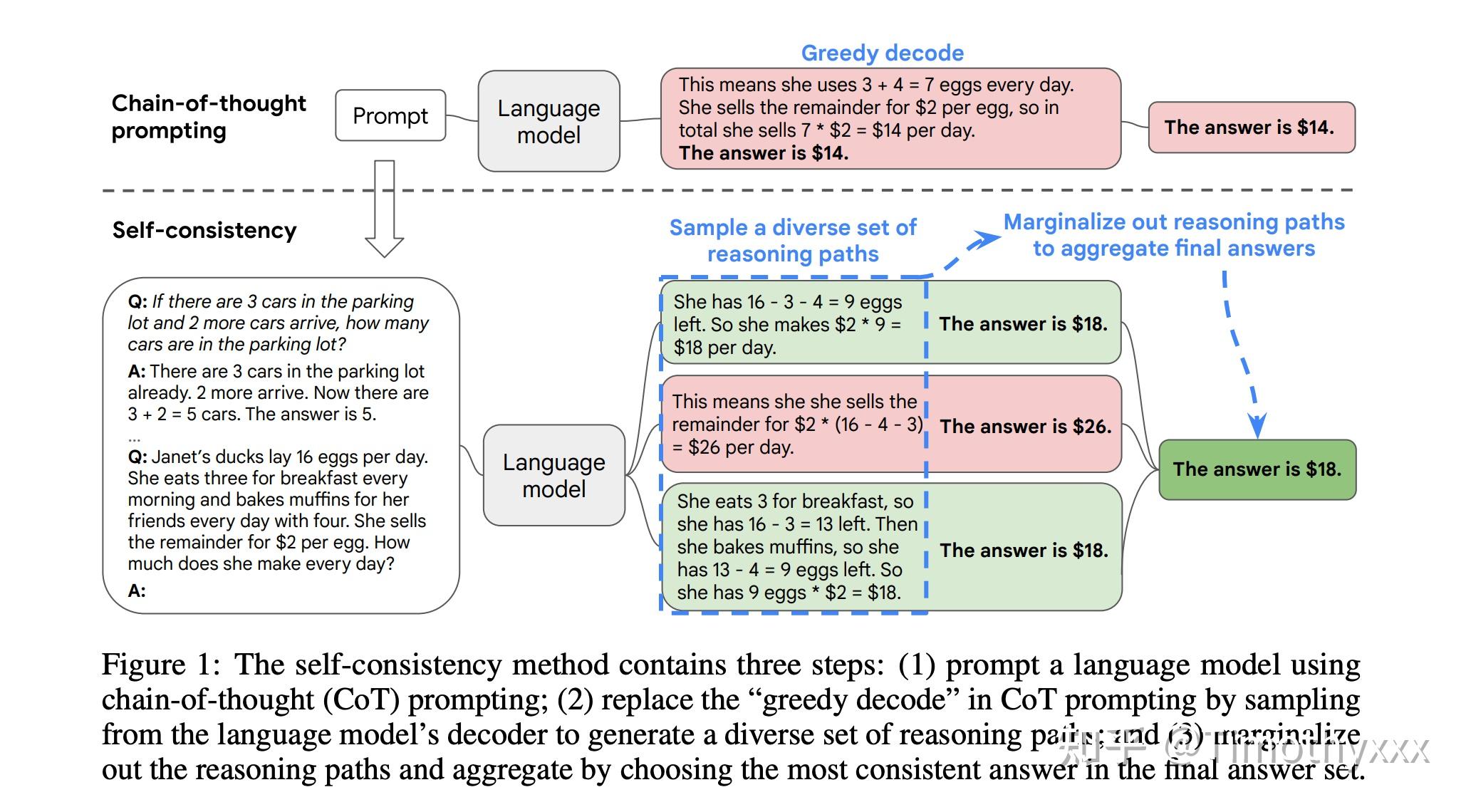
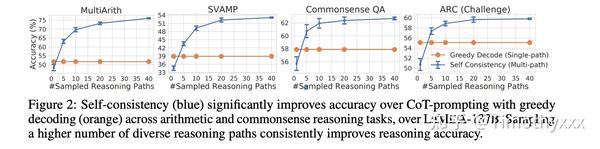

这里面的一个takeaway是:可以将贪婪搜索(greedy search),即将GPT模型的temperature从0设置为某个数值,比如说0.4,然后sample多个按照y进行投票,会显著地提升性能。
STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning
提出了一种boost方法,让中小模型也可以通过训练具有思维链能力
Large Language Models are Zero-Shot Reasoners
“Let's do it step by step“
我还记得2022年当时在西西弗书店看到公众号推送的这篇文章,确实是节目效果拉满。
提出的方法很简单,就是cot原论文原本使用few shot来让llm说出来cot然后得到答案,但是他这个是分成两部分:首先呢他要加一个“Lets think step by step”,然后第得到一个cot的murmur,然后第二步再在后面接上一句“so the anwser is”然后得到答案。性能远超原来的zero shot逼近fee shot和cot的few shot性能。
当时我对这篇文章的评论是这样的,我觉得任然适用于审视相关的所有论文:
很震撼,但是个人觉得稍微有点Fishy
1. 无论是GPT-3还是Codex的001系列和002系列的性能差距非常大。根据我的感觉002好在明显更好prompt出来。在发现这个事实之后我发过email询问过OpenAI的研究人员他们到底对002做了怎样的改进,对面的回答是“无可奉告”。可见要么是做出了超越当前所有研究一个代纪的改进(那我们之前了解到的真的就是挤的牙膏了),要么是通过收集的用户数据,通过某种强化学习手段更好地prompt。他不放出来技术报告或者论文我们是没办法确认这一点的。或者我们之前确实是低估了InstructGPT的技术。
2. 既然是Google参与的论文,并没使用谷歌自己研究的、对他们而言透明的Lambda,Palm或者完全开放式的OPT相当规模的透明model,而采用了相对不透明的OpenAI的002,这个也蛮Fishy的一点(当然我这肯定是站着说话不腰疼了,但是既然要得出这么大的结论可不能那么不严谨)。我个人觉得不应该因为垄断不公开反倒让对着黑盒子的研究成为其“神话”和“炒热”的机会。
当然直接加一句来增强OpenAI的使用是大概率可能的事情,但是归根结底我认为可能补充上在OPT上的实验可能会更让“lets think step by step”的通用性更让人信服。
事实上,当我写下这行话的时候,2022年11月6日,这方面的研究所基于的codex仍然不是透明的,阴谋论的讲是会有问题的。可能到底更多的人入场来趟这趟浑水时好时坏确实很难说清楚。
Least-to-Most Prompting Enables Complex Reasoning in Large Language Models
On the Advance of Making Language Models Better Reasoners
Rationale-Augmented Ensembles in Language Models
事件:Google I/O
谷歌在五月份的年度开发者大会上对这个研究成果进行了宣传,同步宣传的还有谷歌的540B系数大模型PaLM和Pixel系列手机手表等等。


先放一个Paper List吧
笑死