


在gpu上运行Pandas和sklearn

当涉及大量数据时,Pandas 可以有效地处理数据。 但是它使用CPU 进行计算操作。该过程可以通过并行处理加快,但处理大量数据仍然效率不高。
在以前过去,GPU 主要用于渲染视频和玩游戏。但是现在随着技术的进步大多数大型项目都依赖 GPU 支持,因为它具有提升深度学习算法的潜力。
Nvidia的开源库Rapids,可以让我们完全在 GPU 上执行数据科学计算。在本文中我们将 Rapids优化的 GPU 之上的DF、与普通Pandas 的性能进行比较。
我们将在 Google Colab 中对其进行测试。因为我们只需要很少的磁盘空间但是需要大内存 GPU (15GB),而Colab 正好可以提供我们的需求。我们将从在安装开始,请根据步骤完成整个过程。
开启GPU
在菜单栏Colab 的“Runtime”选项中选择“Change runtime type”。然后选择GPU作为硬件加速器。
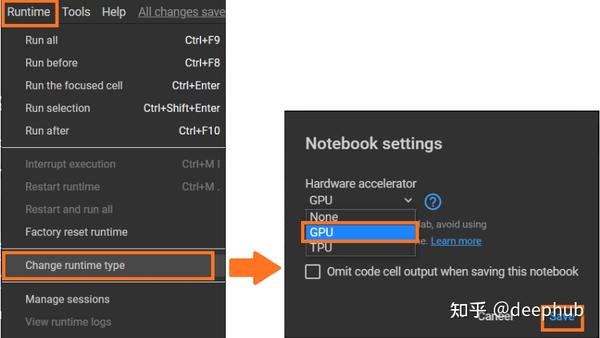
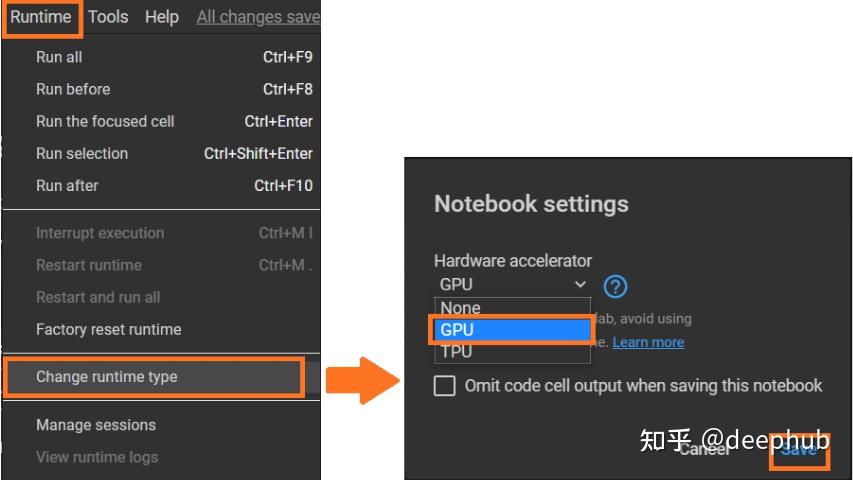
NV的显卡是唯一支持CUDA的显卡,Rapids只支持谷歌Colab中基于P4、P100、T4或V100的gpu,在分配到GPU后我们执行以下命令确认:
!nvidia-smi
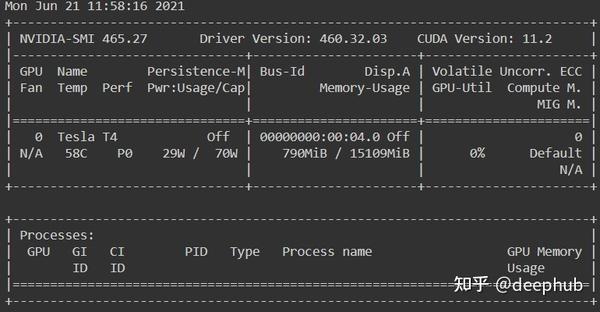
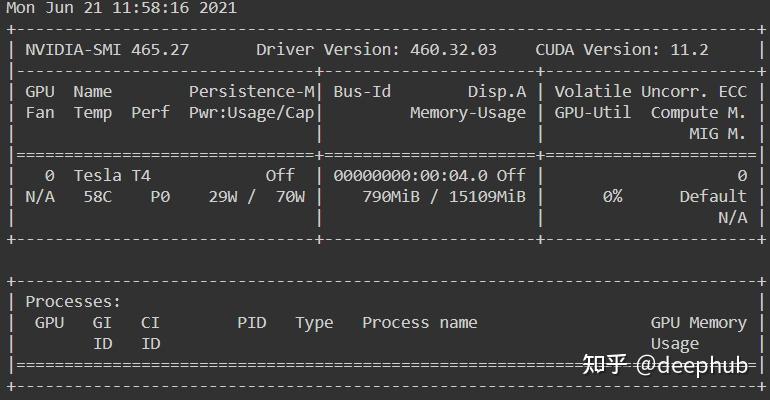
可以看到,分配到了一块T4,有15G的内存。如果分配到了其他GPU(如p4),可以在“Runtime”菜单并选择“Factory Reset Runtimes”,来重新申请。
安装 Rapids
!git clone https://github.com/rapidsai/rapidsai-csp-utils.git
!python rapidsai-csp-utils/colab/env-check.py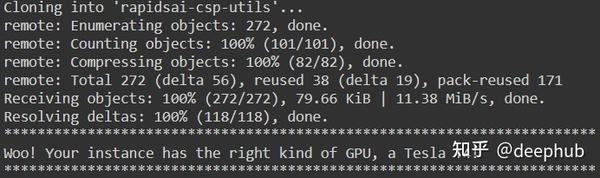
运行以下命令,会更新现有的colab文件并重新启动内核。运行此命令后,当前会话将自动重新启动。
! bash rapidsai-csp-utils/colab/update_gcc.sh
import os
os._exit(00)安装CondaColab
import condacolab
condacolab.install()这条命令会让内核再次重启。重新启动后运行下面命令,确定安装是否成功:
import condacolab
condacolab.check()下面就是在colab实例上安装Rapids了
!python rapidsai-csp-utils/colab/install_rapids.py stable完成后,就可以测试GPU的性能了!
简单对比测试
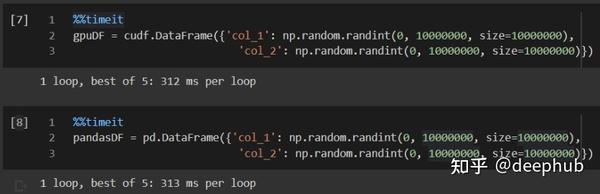
创建一个大的DF可以让测试gpu的全部潜力。我们将创建cuDF(cuda dataframe),其大小为10000000行x 2列(10M x 2),首先导入需要的库:
import cudf
import pandas as pd
import numpy as np创建DF
gpuDF = cudf.DataFrame({'col_1': np.random.randint(0, 10000000, size=10000000),
'col_2': np.random.randint(0, 10000000, size=10000000)})
pandasDF = pd.DataFrame({'col_1': np.random.randint(0, 10000000, size=10000000),
'col_2': np.random.randint(0, 10000000, size=10000000)})cuDF是在GPU之上的DataFrame。Pandas的几乎所有函数都可以在其上运行,因为它是作为Pandas的镜像进行构建的。与Pandas的函数操作一样,但是所有的操作都在GPU内存中执行。
我们看看创建时的时间对比:
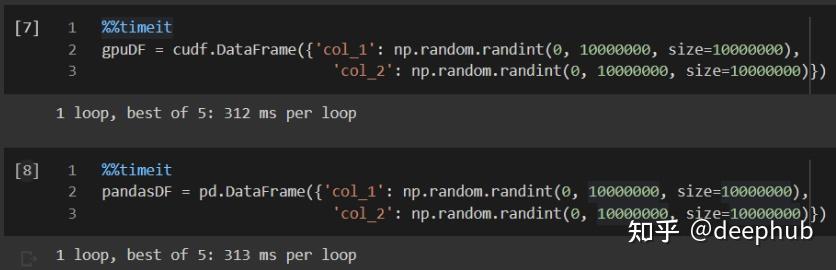
现在让我们看看GPU是否通过对这些数据帧执行一些操作来提高性能!
对数运算
为了得到最好的平均值,我们将对两个df中的一列应用np.log函数,然后运行10个循环:
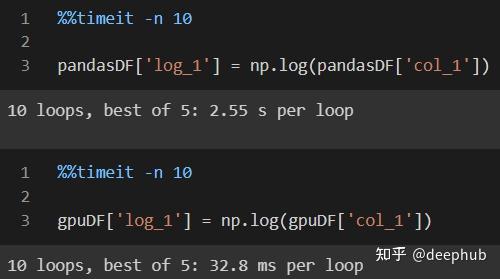

GPU的结果是32.8毫秒,而CPU(常规的pandas)则是2.55秒!基于gpu的处理快的多的多。
从" Int "到" String "的数据类型转换
通过将的“col_1”(包含从0到10M的整数值)转换为字符串值(对象)来进一步测试。
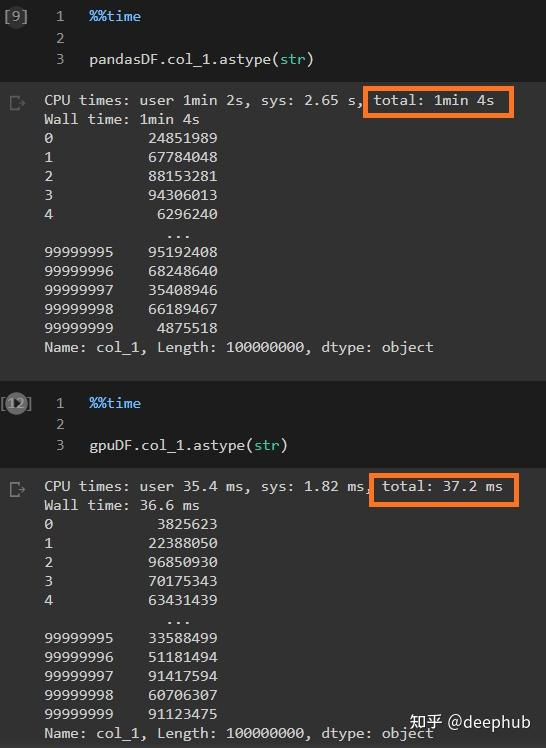
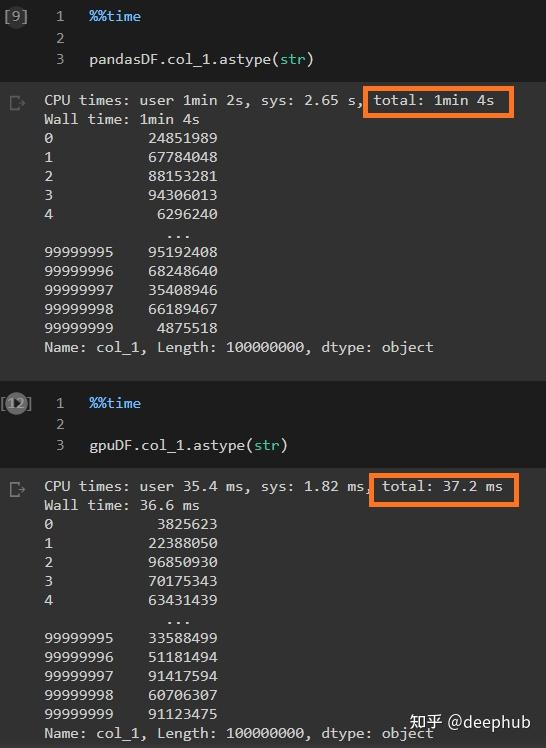
可以看到,速度差距更大了
线性回归模型测试
一个模特的训练可能要花很长时间。模型在GPU内存中的训练可能因其类型而异。我们将使用基于gpu的cuML来测试简单的建模,并将其性能与Sklearn进行比较。
import cudf
from cuml import make_regression, train_test_split
from cuml.linear_model import LinearRegression as cuLinearRegression
from cuml.metrics.regression import r2_score
from sklearn.linear_model import LinearRegression as skLinearRegression创建虚拟数据并将其拆分(训练和测试)
n_samples = 2**20
n_features = 399
random_state = 23
X, y = make_regression(n_samples=n_samples, n_features=n_features, random_state=random_state)
X = cudf.DataFrame(X)