

dataframe一列分多列,多个分隔符分割字符串等等,还有交换列顺序

分割成一个包含两个元素列表的列
对于一个已知分隔符的简单分割(例如,用破折号分割或用空格分割)
.str.split()
方法
就足够了 。 它在字符串的列(系列)上运行,并返回列表(系列)。
>>> import pandas as pd
>>> df = pd.DataFrame({'AB': ['A1-B1', 'A2-B2']})
0 A1-B1
1 A2-B2
>>> df['AB_split'] = df['AB'].str.split('-')
AB AB_split
0 A1-B1 [A1, B1]
1 A2-B2 [A2, B2]
分割成两列,每列包含列表的相应元素
下面来看下如何从:
分割成一个包含两个元素列表的列
至
分割成两列,每列包含列表的相应元素?
。
>>> df['AB'].str.split('-', 1).str[0]
0 A1
1 A2
Name: AB, dtype: object
>>> df['AB'].str.split('-', 1).str[1]
0 B1
1 B2
Name: AB, dtype: object
可以通过如下代码将pandas的一列分成两列:
>>> df['A'], df['B'] = df['AB'].str.split('-', 1).str
AB AB_split A B
0 A1-B1 [A1, B1] A1 B1
1 A2-B2 [A2, B2] A2 B2
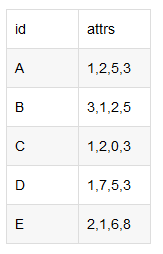
我们想把他拆分成多列,做法如下:
首先进行拆分 data_df = data_df['attrs'].str.split(',', expand=True)
然后用pd.concat把多列加回data_df,pd.concat([], axis=1, names=new_names)
合起来就是
pd.concat([data_df, data_df['attrs'].str.split(',', expand=True)], axis=1,names=new_names)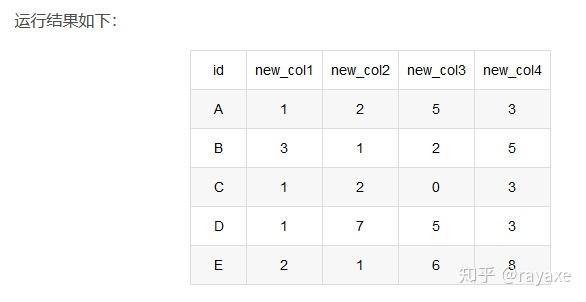
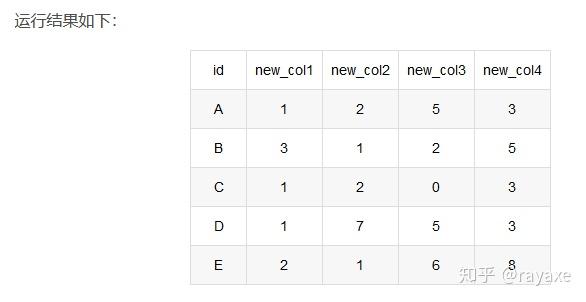
新生成的列怎么改列名参考如下:
data.rename(columns={0:'a',1:'b'},inplace=True)#注意这里0和1都不是字符串
print(data)
多个分隔符分割字符串。。。。。。。。。。。。。。。
一种类型的分隔符进行分割:
a = 'name-age-hobby'
b1 = a.split('-')
b2 = a.split('-',1)
b3 = a.rsplit('-',1)
print(b1) >>>['name', 'age', 'hobby']
print(b2) >>>['name', 'age-hobby']
print(b3) >>>['name-age', 'hobby']
多种类型的分隔符进行分割:
import re
a = 'name-age-work/habby?salary'
b= re.split('[-/?]',a)
print(b) >>>['name', 'age', 'work', 'habby', 'salary']Python Pandas list(列表)数据列拆分成多行的方法
Python Pandas list(列表)数据列拆分成多行的方法
本文主要介绍Python pandas中列的数据是df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]}),多个列表的情况,将列的数据拆分成多行的几种方法。
1、实现的效果
示例代码:
df=pd.DataFrame({'A':[1,2],'B':[[1,2],[1,2]]})
Out[458]:
A B
0 1 [1, 2]
1 2 [1, 2]
拆分成多行的效果:
0 1 1
1 1 2
3 2 1
4 2 2
2、拆分成多行的方法
1)通过apply和pd.Series实现
容易理解,但在性能方面不推荐。
df.set_index('A').B.apply(pd.Series).stack().reset_index(level=0).rename(columns={0:'B'})
Out[463]:
0 1 1
1 1 2
0 2 1
1 2 2
2)使用repeat和DataFrame构造函数
性能可以,但不太适合多列
df=pd.DataFrame({'A':df.A.repeat(df.B.str.len()),'B':np.concatenate(df.B.values)})
Out[465]:
0 1 1
0 1 2
1 2 1
1 2 2
s=pd.DataFrame({'B':np.concatenate(df.B.values)},index=df.index.repeat(df.B.str.len()))
s.join(df.drop('B',1),how='left')
Out[477]:
0 1 1
0 2 1
1 1 2
1 2 2
3)创建新的列表
pd.DataFrame([[x] + [z] for x, y in df.values for z in y],columns=df.columns)
Out[488]:
0 1 1
1 1 2
2 2 1
3 2 2
#拆成多于两列的情况
s=pd.DataFrame([[x] + [z] for x, y in zip(df.index,df.B) for z in y])
s.merge(df,left_on=0,right_index=True)
Out[491]:
0 1 A B
0 0 1 1 [1, 2]
1 0 2 1 [1, 2]
2 1 1 2 [1, 2]
3 1 2 2 [1, 2]
4)使用reindex和loc实现
df.reindex(df.index.repeat(df.B.str.len())).assign(B=np.concatenate(df.B.values))
Out[554]:
0 1 1
0 1 2
1 2 1
1 2 2
#df.loc[df.index.repeat(df.B.str.len())].assign(B=np.concatenate(df.B.values)
5)使用numpy高性能实现
newvalues=np.dstack((np.repeat(df.A.values,list(map(len,df.B.values))),np.concatenate(df.B.values)))
pd.DataFrame(data=newvalues[0],columns=df.columns)
0 1 1
1 1 2
2 2 1
3 2 2在pandas中,del、drop和pop方法都可以用来删除数据,insert可以在指定位置插入数据。
import pandas as pd
from pandas import DataFrame, Series
data = DataFrame({'name':['yang', 'jian', 'yj'], 'age':[23, 34, 22], 'gender':['male', 'male', 'female']})
#data数据
In[182]: data
Out[182]:
age gender name
0 23 male yang
1 34 male jian
2 22 female yj
#删除gender列,不改变原来的data数据,返回删除后的新表data_2。axis为1表示删除列,0表示删除行。inplace为True表示直接对原表修改。
data_2 = data.drop('gender', axis=1, inplace=False)
In[184]: data_2
Out[184]:
age name
0 23 yang
1 34 jian
2 22 yj
#改变某一列的位置。如:先删除gender列,然后在原表data中第0列插入被删掉的列。
data.insert(0, '性别', data.pop('gender'))#pop返回删除的列,插入到第0列,并取新名为'性别'
In[185]: data
Out[186]:
性别 age name
0 male 23 yang
1 male 34 jian
2 female 22 yj
#直接在原数据上删除列
del data['性别']
In[188]: data
Out[188]:
age name
0 23 yang
1 34 jian
2 22 yj
'''
不用函数实现对dataframe某几列的交换,在某一位置插入列等等
看下面的语句就清楚了:
data.columns = ["aa","game_name","timestamp"]
data["duration"] = 1
data2 = data[["timestamp","duration","game_name"]]
使用[[columns]]对原始dataframe进行重组即可DataFrame添加一列为Series
例一
df[i[1]] = b.values # b是Series
#我们从一个dataframe中选取一列series1.
series1=data.pop('day')
#为df1添加一个列,第一个0我们可以改变选择你想插入的位置,第二个可以选择你想要的名字
df.insert(0,'series1',series1)
#对这一列赋值
#df['series1']=series1新增列,插入列,新增行的例子看下面的。
import pandas as pd
df1 = pd.DataFrame([['Snow','M',22],['Tyrion','M',32],['Sansa','F',18],['Arya','F',14]], columns=['name','gender','age'])
print("----------在最后新增一列---------------")
print("-------案例1----------")
# 在数据框最后加上score一列,元素值分别为:80,98,67,90
df1['score']=[80,98,67,90] # 增加列的元素个数要跟原数据列的个数一样
print(df1)
print("-------案例2----------")
print("---------在指定位置新增列:用insert()--------")
# 在gender后面加一列城市
# 在具体某个位置插入一列可以用insert的方法
# 语法格式:列表.insert(index, obj)
# index --->对象 obj 需要插入的索引位置。
# obj ---> 要插入列表中的对象(列名)
col_name=df1.columns.tolist() # 将数据框的列名全部提取出来存放在列表里
print(col_name)
col_name.insert(2,'city') # 在列索引为2的位置插入一列,列名为:city,刚插入时不会有值,整列都是NaN
df1=df1.reindex(columns=col_name) # DataFrame.reindex() 对原行/列索引重新构建索引值
df1['city']=['北京','山西','湖北','澳门'] # 给city列赋值
print(df1)
print("----------新增行---------------")
# 重要!!先创建一个DataFrame,用来增加进数据框的最后一行
new=pd.DataFrame({'name':'lisa',
'gender':'F',
'city':'北京',
'age':19,
'score':100},