jsonDF6.filter(x=>x.getAs("en")=="notification").select($"en",get_json_object($"kv","$.ap_time").alias("ap_time"),get_json_object($"kv","$.action").alias("action"),get_json_object($"kv","$.type").alias("type"),get_json_object($"kv","$.content").alias("content")).show

其他情况类似,可仿照写
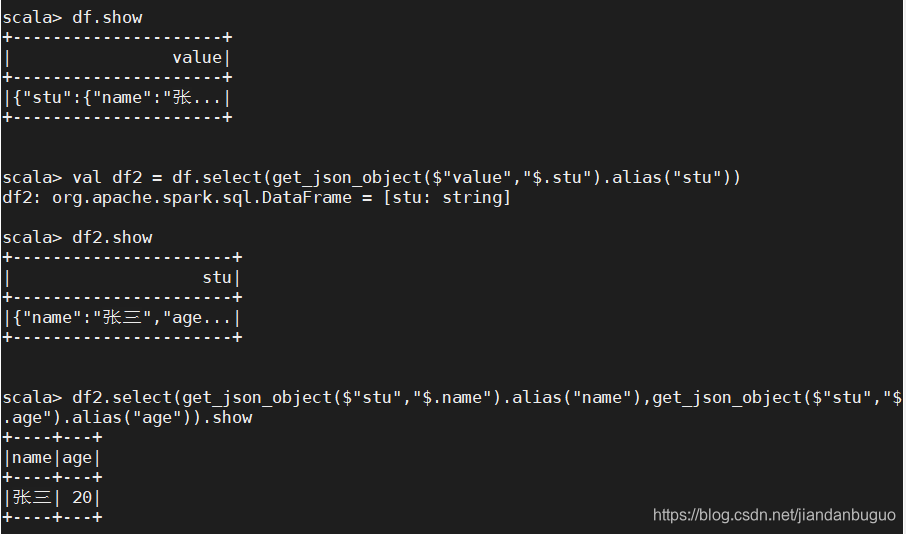
Spark SQL解析json文件一、get_json_object二、from_json三、explode四、案例:解析json格式日志数据数据处理先介绍一下会用到的三个函数:get_json_object、from_json、explode一、get_json_object从一个json 字符串中根据指定的json 路径抽取一个json 对象def get_json_object(e: org.apache.spark.sql.Column,path: String): org.apache.s
步骤一,上传一篇json文件到hdfs,文件内容可以用百度搜素:json文件在线解析 如下:
hdfs dfs -put /opt/kb09file/op.log /kb09file
步骤二:,分析json文件,按照“|”切割,分成两部分
步骤三:对jsonStrRDD的第二部分进行截取(substring)操作
val jsonRDD=jsonStrRDD.map(x=>{var jsonStr=x._2;jsonStr=
jsonStr.substring(0,jsonStr.length-
SparkJava的杰森
在执行以下命令之前,请在sparkjob.conf文件中更改spark.driver.extraClassPath属性。
./bin/spark-submit --class org.sparketl.etljobs.SparkEtl --properties-file sparkjob.conf /sparketl/target/sparketl-0.0.1-SNAPSHOT.jar {spark master url} {使用存在的city_list.json在此项目中} {输出文件(用于配对RDD){单个RDD的输出文件}} {国家(地区):美国}
对于Spark初学者,请转到
Hive和Spark SQL都可以解析JSON对象和JSON数组。
在Hive中,可以使用get_json_object函数来解析JSON对象和JSON数组。例如,假设有一个名为json_data的表,其中包含一个名为json_column的JSON列,可以使用以下语句来获取JSON对象中的特定字段:
SELECT get_json_object(json_column, '$.field_name') FROM json_data;
其中,$.field_name是JSON对象中要获取的字段的路径。
要获取JSON数组中的特定元素,可以使用json_tuple函数。例如,假设JSON数组包含名为field1和field2的两个字段,可以使用以下语句来获取第一个元素中的这两个字段的值:
SELECT json_tuple(json_column[0], 'field1', 'field2') FROM json_data;
在Spark SQL中,可以使用from_json函数来解析JSON对象和JSON数组。例如,假设有一个名为json_data的DataFrame,其中包含一个名为json_column的JSON列,可以使用以下语句来获取JSON对象中的特定字段:
SELECT from_json(json_column, '$.field_name') FROM json_data;
要获取JSON数组中的特定元素,可以使用explode函数。例如,假设JSON数组包含名为field1和field2的两个字段,可以使用以下语句来获取所有元素中的这两个字段的值:
SELECT explode(from_json(json_column, 'array<struct<field1:string,field2:string>>')).* FROM json_data;
其中,'array<struct<field1:string,field2:string>>'指定JSON数组的结构。
HBase简介及HBase Shell操作