1.2欧几里德距离评价
欧几里德距离评价是一个较为简单的用户关系评价方法。原理是通过计算两个用户在散点图中的距离来判断不同的用户是否有相同的偏好。以下是欧几里德距离评价的计算公式。
通过公式我们获得了5个用户相互间的欧几里德系数,也就是用户间的距离。系数越小表示两个用户间的距离越近,偏好也越是接近。不过这里有个问题,太小的数值可能无法准确的表现出不同用户间距离的差异,因此我们对求得的系数取倒数,使用户间的距离约接近,数值越大。在下面的表格中,可以发现,用户A&C用户A&D和用户C&D距离较近。同时用户B&E的距离也较为接近。与我们前面在散点图中看到的情况一致。
1.3皮尔逊相关度评价
皮尔逊相关度评价是另一种计算用户间关系的方法。他比欧几里德距离评价的计算要复杂一些,但对于评分数据不规范时皮尔逊相关度评价能够给出更好的结果。以下是一个多用户对多个商品进行评分的示例。这个示例比之前的两个商品的情况要复杂一些,但也更接近真实的情况。我们通过皮尔逊相关度评价对用户进行分组,并推荐商品。
1.4皮尔逊相关系数
皮尔逊相关系数的计算公式如下,结果是一个在-1与1之间的系数。该系数用来说明两个用户间联系的强弱程度。
相关系数的分类
-
0.8-1.0 极强相关
-
0.6-0.8 强相关
-
0.4-0.6 中等程度相关
-
0.2-0.4 弱相关
-
0.0-0.2 极弱相关或无相关
通过计算5个用户对5件商品的评分我们获得了用户间的相似度数据。这里可以看到用户A&B,C&D,C&E和D&E之间相似度较高。下一步,我们可以依照相似度对用户进行商品推荐。
2,为相似的用户提供推荐物品
为用户C推荐商品
当我们需要对用户C推荐商品时,首先我们检查之前的相似度列表,发现用户C和用户D和E的相似度较高。换句话说这三个用户是一个群体,拥有相同的偏好。因此,我们可以对用户C推荐D和E的商品。但这里有一个问题。我们不能直接推荐前面商品1-商品5的商品。因为这这些商品用户C以及浏览或者购买过了。不能重复推荐。因此我们要推荐用户C还没有浏览或购买过的商品。
加权排序推荐
我们提取了用户D和用户E评价过的另外5件商品A—商品F的商品。并对不同商品的评分进行相似度加权。按加权后的结果对5件商品进行排序,然后推荐给用户C。这样,用户C就获得了与他偏好相似的用户D和E评价的商品。而在具体的推荐顺序和展示上我们依照用户D和用户E与用户C的相似度进行排序。
以上是基于用户的协同过滤算法。这个算法依靠用户的历史行为数据来计算相关度。也就是说必须要有一定的数据积累(冷启动问题)。对于新网站或数据量较少的网站,还有一种方法是基于物品的协同过滤算法。
基于物品的协同过滤算法(item-based collaborative filtering)
基于物品的协同过滤算法与基于用户的协同过滤算法很像,将商品和用户互换。通过计算不同用户对不同物品的评分获得物品间的关系。基于物品间的关系对用户进行相似物品的推荐。这里的评分代表用户对商品的态度和偏好。简单来说就是如果用户A同时购买了商品1和商品2,那么说明商品1和商品2的相关度较高。当用户B也购买了商品1时,可以推断他也有购买商品2的需求。
1.寻找相似的物品
表格中是两个用户对5件商品的评分。在这个表格中我们用户和商品的位置进行了互换,通过两个用户的评分来获得5件商品之间的相似度情况。单从表格中我们依然很难发现其中的联系,因此我们选择通过散点图进行展示。
在散点图中,X轴和Y轴分别是两个用户的评分。5件商品按照所获的评分值分布在散点图中。我们可以发现,商品1,3,4在用户A和B中有着近似的评分,说明这三件商品的相关度较高。而商品5和2则在另一个群体中。
欧几里德距离评价
在基于物品的协同过滤算法中,我们依然可以使用欧几里德距离评价来计算不同商品间的距离和关系。以下是计算公式。
通过欧几里德系数可以发现,商品间的距离和关系与前面散点图中的表现一致,商品1,3,4距离较近关系密切。商品2和商品5距离较近。
皮尔逊相关度评价
我们选择使用皮尔逊相关度评价来计算多用户与多商品的关系计算。下面是5个用户对5件商品的评分表。我们通过这些评分计算出商品间的相关度。
皮尔逊相关度计算公式
通过计算可以发现,商品1&2,商品3&4,商品3&5和商品4&5相似度较高。下一步我们可以依据这些商品间的相关度对用户进行商品推荐。
2,为用户提供基于相似物品的推荐
这里我们遇到了和基于用户进行商品推荐相同的问题,当需要对用户C基于商品3推荐商品时,需要一张新的商品与已有商品间的相似度列表。在前面的相似度计算中,商品3与商品4和商品5相似度较高,因此我们计算并获得了商品4,5与其他商品的相似度列表。
以下是通过计算获得的新商品与已有商品间的相似度数据。
加权排序推荐
这里是用户C已经购买过的商品4,5与新商品A,B,C直接的相似程度。我们将用户C对商品4,5的评分作为权重。对商品A,B,C进行加权排序。用户C评分较高并且与之相似度较高的商品被优先推荐。
二、基于物品的协同过滤算法详解
最近参加KDD Cup 2012比赛,选了track1,做微博推荐的,找了推荐相关的论文学习。“Item-Based Collaborative Filtering Recommendation Algorithms”这篇是推荐领域比较经典的论文,现在很多流行的推荐
算法
都是在这篇论文提出的算法的基础上进行改进的。
一、协同过滤算法描述
推荐系统应用数据分析技术,找出
用户
最可能喜欢的东西推荐给用户,现在很多电子商务网站都有这个应用。目前用的比较多、比较成熟的推荐算法是
协同过滤
(
Collaborative
Filtering,简称
CF
)
推荐
算法,CF的基本思想是根据用户之前的喜好以及其他兴趣相近的用户的选择来给用户推荐物品。
如图1所示,在CF中,用m×n的矩阵表示用户对物品的喜好情况,一般用打分表示用户对物品的喜好程度,分数越高表示越喜欢这个物品,0表示没有买过该物品。图中行表示一个用户,列表示一个物品,Uij表示用户i对物品j的打分情况。CF分为两个过程,一个为
预测
过程,另一个为
推荐
过程。预测过程是预测用户对没有购买过的物品的可能打分值,推荐是根据预测阶段的结果推荐用户最可能喜欢的一个或Top-N个物品。
二、User-based算法与Item-based算法对比
CF算法分为两大类,一类为基于memory的(
Memory-based
),另一类为基于Model的(
Model-based
),User-based和Item-based算法均属于Memory-based类型,具体细分类可以参考
wikipedia
的说明。
User-based的基本思想是如果用户A喜欢物品a,用户B喜欢物品a、b、c,用户C喜欢a和c,那么认为用户A与用户B和C相似,因为他们都喜欢a,而喜欢a的用户同时也喜欢c,所以把c推荐给用户A。该算法用最近邻居(nearest-neighbor)算法找出一个用户的邻居集合,该集合的用户和该用户有相似的喜好,算法根据邻居的偏好对该用户进行预测。
User-based算法存在两个重大问题:
1. 数据稀疏性。一个大型的电子商务推荐系统一般有非常多的物品,用户可能买的其中不到1%的物品,不同用户之间买的物品重叠性较低,导致算法无法找到一个用户的邻居,即偏好相似的用户。
2. 算法扩展性。最近邻居算法的计算量随着用户和物品数量的增加而增加,不适合数据量大的情况使用。
Iterm-based的基本思想是预先根据所有用户的历史偏好数据计算物品之间的相似性,然后把与用户喜欢的物品相类似的物品推荐给用户。还是以之前的例子为例,可以知道物品a和c非常相似,因为喜欢a的用户同时也喜欢c,而用户A喜欢a,所以把c推荐给用户A。
因为物品直接的相似性相对比较固定,所以可以预先在线下计算好不同物品之间的相似度,把结果存在表中,当推荐时进行查表,计算用户可能的打分值,可以同时解决上面两个问题。
三、
Item-based算法详细过程
(1)相似度计算
Item-based算法首选计算物品之间的相似度,计算相似度的方法有以下几种:
1. 基于余弦(Cosine-based)的相似度计算,通过计算两个向量之间的夹角余弦值来计算物品之间的相似性,公式如下:
其中分子为两个向量的内积,即两个向量相同位置的数字相乘。
2. 基于关联(Correlation-based)的相似度计算,计算两个向量之间的Pearson-r关联度,公式如下:
其中
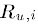 表示用户u对物品i的打分,
表示用户u对物品i的打分,
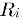 表示第i个物品打分的平均值。
表示第i个物品打分的平均值。
3. 调整的余弦(Adjusted Cosine)相似度计算,由于基于余弦的相似度计算没有考虑不同用户的打分情况,可能有的用户偏向于给高分,而有的用户偏向于给低分,该方法通过减去用户打分的平均值消除不同用户打分习惯的影响,公式如下:
其中
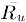 表示用户u打分的平均值。
表示用户u打分的平均值。
(2)预测值计算
根据之前算好的物品之间的相似度,接下来对用户未打分的物品进行预测,有两种预测方法:
1. 加权求和。
用过对用户u已打分的物品的分数进行加权求和,权值为各个物品与物品i的相似度,然后对所有物品相似度的和求平均,计算得到用户u对物品i打分,公式如下:
其中
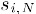 为物品i与物品N的相似度,
为物品i与物品N的相似度,
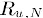 为用户u对物品N的打分。
为用户u对物品N的打分。
2. 回归。
和上面加权求和的方法类似,但回归的方法不直接使用相似物品N的打分值
,因为用余弦法或Pearson关联法计算相似度时存在一个误区,即两个打分向量可能相距比较远(欧氏距离),但有可能有很高的相似度。因为不同用户的打分习惯不同,有的偏向打高分,有的偏向打低分。如果两个用户都喜欢一样的物品,因为打分习惯不同,他们的欧式距离可能比较远,但他们应该有较高的相似度。在这种情况下用户原始的相似物品的打分值进行计算会造成糟糕的预测结果。通过用线性回归的方式重新估算一个新的
值,运用上面同样的方法进行预测。重新计算
的方法如下:
其中物品N是物品i的相似物品,
 和
和
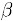 通过对物品N和i的打分向量进行线性回归计算得到,
通过对物品N和i的打分向量进行线性回归计算得到,
 为回归模型的误差。具体怎么进行线性回归文章里面没有说明,需要查阅另外的相关文献。
为回归模型的误差。具体怎么进行线性回归文章里面没有说明,需要查阅另外的相关文献。
作者通过实验对比结果得出结论:1. Item-based算法的预测结果比User-based算法的质量要高一点。2. 由于Item-based算法可以预先计算好物品的相似度,所以在线的预测性能要比User-based算法的高。3. 用物品的一个小部分子集也可以得到高质量的预测结果。
转载请注明出处,原文地址:
http://blog.csdn.net/huagong_adu/article/details/7362908
协同过滤推荐系统在我们的日常生活之中无处不在,例如,在电子商城购物,系统会根据用户的记录或者其他的信息来推荐相应的产品给客户,是一种智能的生活方式。之所以交协同过滤,是因为在实现过滤推荐的时候是根据其...
来自:
从前慢
一、背景关于推荐算法的相关背景介绍,已经在上一个姊妹篇(三)协同过滤算法之基于物品的推荐算法python实现中有所介绍。在此,便不在赘述,本文主要介绍基于用户的协同过滤算法,而对推荐算法不太清楚的朋友...
来自:
wickedvalley
推荐算法具有非常多的应用场景和商业价值,因此对推荐算法值得好好研究。推荐算法种类很多,但是目前应用最广泛的应该是协同过滤类别的推荐算法,本文就对协同过滤类别的推荐算法做一个概括总结,后续也会对...
来自:
weixin_33816300的博客
总体思路:1.利用余弦相似度对两两用户计算相似度 1.1 建立物品-用户倒排表 左半部分为训练数据格式,ABCD等是用户,abc等是对应用户喜欢的物品 右半部分物品...
来自:
m0_37917271的博客
1、推荐算法推荐系统的出现 随着互联网的发展,人们正处于一个信息爆炸的时代。相比于过去的信息匮乏,面对现阶段海量的信息数据,对信息的筛选和过滤成为了衡量一个系统好坏的重要指标。一个具有良好用户体验的...
来自:
William Zhao's notes
在推荐系统众多方法中,基于用户的协同过滤推荐算法是最早诞生的,原理也较为简单。该算法1992年提出并用于邮件过滤系统,两年后1994年被 GroupLens 用于新闻过滤。一直到2000年,该算法都是...
来自:
开心妙妙屋
三四月份投了字节跳动的实习(图形图像岗位),然后hr打电话过来问了一下会不会opengl,c++,shador,当时只会一点c++,其他两个都不会,也就直接被拒了。七月初内推了字节跳动的提前批,因为内...
来自:
ljh_shuai的博客
起因又到深夜了,我按照以往在csdn和公众号写着数据结构!这占用了我大量的时间!我的超越妹妹严重缺乏陪伴而 怨气满满!而女朋友时常埋怨,认为数据结构这么抽象难懂的东西没啥作用,常会问道:天天写这玩意,...
来自:
bigsai
目录1、个人申请2、团队申请3、企业/组织申请3.1、个人/企业/组织和企业/组织联合申请4、补充最近和团队做一个项目:基于NB-IoT技术的城市道路智慧路灯监控系统,决定申请计算机软件著作权便于保护...
来自:
不脱发的程序猿
我本科学校是渣渣二本,研究生学校是985,现在毕业五年,校招笔试、面试,社招面试参加了两年了,就我个人的经历来说下这个问题。这篇文章很长,但绝对是精华,相信我,读完以后,你会知道学历不好的解决方案,记...
来自:
启舰
一、准备工作u盘,电脑一台,win10原版镜像(msdn官网)二、下载wepe工具箱极力推荐微pe(微pe官方下载)下载64位的win10 pe,使用工具箱制作启动U盘打开软件,选择安装到U盘(按照操...
来自:
weixin_41964258的博客
基于物品的协同过滤算法(ItemCF)给用户推荐那些和他们之前喜欢的物品相似的物品。比如:该算法会因为你购买过《数据挖掘导论》而给你推荐《机器学习》。不过ItemCF算法不利用物品的内容属性计算物品之...
来自:
m0_37917271的博客
文章目录@[toc]spring cloud 介绍spring cloud 技术组成Spring Cloud 对比 Dubbo一、service - 服务二、commons 通用项目新建 maven ...
来自:
weixin_38305440的博客
点击蓝色“五分钟学算法”关注我哟加个“星标”,天天中午 12:15,一起学算法作者 | 南之鱼来源 | 芝麻观点(chinamkt)所谓大企业病,一般都具有机构臃肿、多重......
来自:
程序员吴师兄的博客
协同过滤算法(collaborativefiltering)的目标是基于用户对物品的历史评价信息,向目标用户(activeuser)推荐其未购买的物品。协同过滤算法可分为基于物品的,基于用户的和基于矩...
来自:
slx_share的博客
小编是一个理科生,不善长说一些废话。简单介绍下原理然后直接上代码。使用的工具(Python+pycharm2019.3+selenium+xpath+chromedriver)其中要使用pycharm...
来自:
qq_43764365的博客
福利来了,给大家带来一个福利。最近想了解一下有关Spring Boot的开源项目,看了很多开源的框架,大多是一些demo或者是一个未成形的项目,基本功能都不完整,尤其是用户权限和菜单方面几乎没有完整的...
整理 | 屠敏快来收听极客头条音频版吧,智能播报由标贝科技提供技术支持。「极客头条」—— 技术人员的新闻圈!CSDN 的读者朋友们早上好哇,「极客头条」来啦,快来看今天都有哪些值得我们技术人关注的重要...
来自:
CSDN资讯
此系列包含蓝桥杯所考察的绝大部分知识点,一共有==基础语法==,==常用API==,==基础算法和数据结构==,和==往年真题==四部分,虽然语言以JAVA为主,但算法部分是相通的,C++组的小伙伴也...
来自:
GD_ONE的博客
点击“技术领导力”关注∆每天早上8:30推送作者|Mr.K 编辑| Emma来源|技术领导力(ID:jishulingdaoli)前天的推文《冯唐:职场人35岁以后,方法论比经验重要》,收到了不少读者...
来自:
技术领导力
转载自:http://hi.baidu.com/liujiekkk123/blog/item/d6c4541b06470fe6af5133fe.html什么是协同过滤协同过滤是利用集体智慧的一个典型方...
来自:
michzel的专栏
导语:腾讯计费是孵化于支撑腾讯内部业务千亿级营收的互联网计费平台,在如此庞大的业务体量下,腾讯计费要支撑业务的快速增长,同时还要保证每笔交易不错账。采用最终一致性或离线补......
来自:
腾讯技术工程
点击上面↑「爱开发」关注我们每晚10点,捕获技术思考和创业资源洞察什么是ThreadLocalThreadLocal是一个本地线程副本变量工具类,各个线程都拥有一份线程私......
来自:
爱开发
协同过滤:(1)基于内容/基于领域的协同过滤ICF计算items之间的相似度,推荐与A的已知item最相关的item步骤:1.输入item-user矩阵2.求item-item相似度 (不同相似度度量...
来自:
HouLei
最近翻到一篇知乎,上面有不少用Python(大多是turtle库)绘制的树图,感觉很漂亮,我整理了一下,挑了一些我觉得不错的代码分享给大家(这些我都测试过,确实可以生成)one 樱花树 动态生成樱花效...
来自:
碎片
作者:肖强,来自:51CTO技术栈“ 网易云音乐是音乐爱好者的集聚地,云音乐推荐系统致力于通过 AI 算法的落地,实现用户千人千面的个性化推荐,为用户带来不一样的听歌体验......
来自:
架构师小秘圈
很早就很想写这个,今天终于写完了。游戏截图:编译环境: VS2017游戏需要一些图片,如果有想要的或者对游戏有什么看法的可以加我的QQ 2985486630 讨论,如果暂时没有回应,可以在博客下方留言...
来自:
张宜强的博客
持续更新。。。。。。2.1斐波那契系列问题2.2矩阵系列问题2.3跳跃系列问题3.1 01背包3.2 完全背包3.3多重背包3.4 一些变形选讲2.1斐波那契系列问题在数学上,斐波纳契数列以如下被以递...
来自:
hebtu666
在博主认为,对于入门级学习java的最佳学习方法莫过于视频+博客+书籍+总结,前三者博主将淋漓尽致地挥毫于这篇博客文章中,至于总结在于个人,实际上越到后面你会发现学习的最好方式就是阅读参考官方文档其次...
来自:
程序员宜春的博客
由于我之前一直强调数据结构以及算法学习的重要性,所以就有一些读者经常问我,数据结构与算法应该要学习到哪个程度呢?,说实话,这个问题我不知道要怎么回答你,主要取决于你想学习到哪些程度,不过针对这个问题,...
来自:
帅地
关于SQL和ORM的争论,永远都不会终止,我也一直在思考这个问题。昨天又跟群里的小伙伴进行了一番讨论,感触还是有一些,于是就有了今天这篇文。声明:本文不会下关于Mybatis和JPA两个持久层框架哪个...
来自:
十步杀一人-千里不留行

